







1.事先声明,本文章仅仅是博主学习使用,大家仅供参考,由于时间有限,很多程序没有实现自动化,在后续会更新出相关自动化的程序
2.事前准备:一套k230,具有labelme的anaconda平台,pycharm,AI_Cube(此程序在勘探k230官网上有)
3.流程:(1)拍摄照片—(2)将照片保存为JPG基本格式—(3)将照片通过labelme转化为JSON—(4)通过相关python文件将XML格式—(5)将XML的编码格式转化为UTF-8-(6)进行数据检查—(6)开始通过AI_Cube训练
3—(1)拍摄照片
选择canmv自带的程序,打开canmv中的历程,选择camera_480p.py,直接连线即可,如图所示

3—(2)将照片保存为JPG基本格式
法1:由于当前我的k230没有save一键保存到sd卡上,所以,我的是手动一个一个保存的,如图所示 ,然后就可以进行保存了,注意保存的格式后面要是JPG格式,即文件后缀格式是.jpg,一般命名为0001.jpg,以此往下。
,然后就可以进行保存了,注意保存的格式后面要是JPG格式,即文件后缀格式是.jpg,一般命名为0001.jpg,以此往下。
法2:由于没有save直接保存图像文件,但我这个版本的k230有一个
with open(filename, "wb") as f:
if f:
img_data = uctypes.bytearray_at(img.virtaddr(), img.size())
# save yuv data to sdcard.
#f.write(img_data)
这个也可以保存,但文件的后缀是rgb888,这个文件参考在k230官网文档的Camera的示例程序,通过那个文件,可以保存到sd卡里,但读出来之后就是rgb888格式的文件,这时,我们需要转化一下,通过python文件import cv2 as cv
import numpy as np
f = open("00000.rgb", "rb")
data = f.read()
f.close()
data = [int(x) for x in data]
# 图像尺寸是需要预先知道的
data = np.array(data).reshape((540, 960, 3)).astype(np.uint8)
cv.imshow("data", data)
cv.waitKey()
注意好格式以及尺寸,就可以转化出来,但是大批量的转换我还没写这个程序,到时候会补上,注意:这个转化后的图像会有很大的畸形,要注意!!!!
3—(3)将照片通过labelme转化为JSON
这个呢,其实是进行图像标注工程,我选择的是labelme标注,记得咱们前面的那些0001.jpg,咱们标注的就是它们,咱们打开界面如图 
我们选择open选项,而不是open Dir选项,因为这样的标注你还需要提前声明一下标签,然后才能使用,但是咱们open选项有个缺点就是需要一张一张打开再标注,打开图像之后,在右键选择标注类型,标注类型如下 ,咱们一般选择第二个,选择正宗的长方形,因为我试过第一个,之后转换之后,会出现很多错误数据,很影响咱们的3—(6)阶段,当然,如果你数据觉得足够多,时间很充裕,那你可以选择第一个,一定是首尾相连,之后,他会出现一个标签,如图
,咱们一般选择第二个,选择正宗的长方形,因为我试过第一个,之后转换之后,会出现很多错误数据,很影响咱们的3—(6)阶段,当然,如果你数据觉得足够多,时间很充裕,那你可以选择第一个,一定是首尾相连,之后,他会出现一个标签,如图 ,看见那个框框了么?填上,然后他就会自动生成这个标签了,以后打开文件,画完圈圈后,会出现这个选项,你可以选择它,也可以选择新建一个标签。
,看见那个框框了么?填上,然后他就会自动生成这个标签了,以后打开文件,画完圈圈后,会出现这个选项,你可以选择它,也可以选择新建一个标签。
3—(4)通过相关python文件将XML格式
上一步中,我们已经将我们的原本图片JPG转换为可标注的JSON格式,之后,咱们要开始将JSON格式转换为XML格式了,好了,这时候打开咱们的pycharm,在同一目录下,生成3个文件,3个文件的命名是read_json_anno.py 这里面的内容是
# -*- coding: utf-8 -*-
import numpy as np
import json
class ReadAnno:
def __init__(self, json_path, process_mode="rectangle"):
with open(json_path, 'r', encoding='gb18030') as fp:
self.json_data = json.load(fp)
# self.json_data = json.load(open(json_path))
self.filename = self.json_data['imagePath']
self.width = self.json_data['imageWidth']
self.height = self.json_data['imageHeight']
self.coordis = []
assert process_mode in ["rectangle", "polygon"]
if process_mode == "rectangle":
self.process_polygon_shapes()
elif process_mode == "polygon":
self.process_polygon_shapes()
def process_rectangle_shapes(self):
for single_shape in self.json_data['shapes']:
bbox_class = single_shape['label']
xmin = single_shape['points'][0][0]
ymin = single_shape['points'][0][1]
xmax = single_shape['points'][1][0]
ymax = single_shape['points'][1][1]
self.coordis.append([xmin, ymin, xmax, ymax, bbox_class])
def process_polygon_shapes(self):
for single_shape in self.json_data['shapes']:
bbox_class = single_shape['label']
temp_points = []
for couple_point in single_shape['points']:
x = float(couple_point[0])
y = float(couple_point[1])
temp_points.append([x, y])
temp_points = np.array(temp_points)
xmin, ymin = temp_points.min(axis=0)
xmax, ymax = temp_points.max(axis=0)
self.coordis.append([xmin, ymin, xmax, ymax, bbox_class])
def get_width_height(self):
return self.width, self.height
def get_filename(self):
return self.filename
def get_coordis(self):
return self.coordis
第二个文件是create_xml_anno.py,里面内容是
# -*- coding: utf-8 -*-
from xml.dom.minidom import Document
class CreateAnno:
def __init__(self, ):
self.doc = Document() # 创建DOM文档对象
self.anno = self.doc.createElement('annotation') # 创建根元素
self.doc.appendChild(self.anno)
self.add_folder()
self.add_path()
self.add_source()
self.add_segmented()
# self.add_filename()
# self.add_pic_size(width_text_str=str(width), height_text_str=str(height), depth_text_str=str(depth))
def add_folder(self, floder_text_str='JPEGImages'):
floder = self.doc.createElement('floder') ##建立自己的开头
floder_text = self.doc.createTextNode(floder_text_str) ##建立自己的文本信息
floder.appendChild(floder_text) ##自己的内容
self.anno.appendChild(floder)
def add_filename(self, filename_text_str='00000.jpg'):
filename = self.doc.createElement('filename')
filename_text = self.doc.createTextNode(filename_text_str)
filename.appendChild(filename_text)
self.anno.appendChild(filename)
def add_path(self, path_text_str="None"):
path = self.doc.createElement('path')
path_text = self.doc.createTextNode(path_text_str)
path.appendChild(path_text)
self.anno.appendChild(path)
def add_source(self, database_text_str="Unknow"):
source = self.doc.createElement('source')
database = self.doc.createElement('database')
database_text = self.doc.createTextNode(database_text_str) # 元素内容写入
database.appendChild(database_text)
source.appendChild(database)
self.anno.appendChild(source)
def add_pic_size(self, width_text_str="0", height_text_str="0", depth_text_str="3"):
size = self.doc.createElement('size')
width = self.doc.createElement('width')
width_text = self.doc.createTextNode(width_text_str) # 元素内容写入
width.appendChild(width_text)
size.appendChild(width)
height = self.doc.createElement('height')
height_text = self.doc.createTextNode(height_text_str)
height.appendChild(height_text)
size.appendChild(height)
depth = self.doc.createElement('depth')
depth_text = self.doc.createTextNode(depth_text_str)
depth.appendChild(depth_text)
size.appendChild(depth)
self.anno.appendChild(size)
def add_segmented(self, segmented_text_str="0"):
segmented = self.doc.createElement('segmented')
segmented_text = self.doc.createTextNode(segmented_text_str)
segmented.appendChild(segmented_text)
self.anno.appendChild(segmented)
def add_object(self,
name_text_str="None",
xmin_text_str="0",
ymin_text_str="0",
xmax_text_str="0",
ymax_text_str="0",
pose_text_str="Unspecified",
truncated_text_str="0",
difficult_text_str="0"):
object = self.doc.createElement('object')
name = self.doc.createElement('name')
name_text = self.doc.createTextNode(name_text_str)
name.appendChild(name_text)
object.appendChild(name)
pose = self.doc.createElement('pose')
pose_text = self.doc.createTextNode(pose_text_str)
pose.appendChild(pose_text)
object.appendChild(pose)
truncated = self.doc.createElement('truncated')
truncated_text = self.doc.createTextNode(truncated_text_str)
truncated.appendChild(truncated_text)
object.appendChild(truncated)
difficult = self.doc.createElement('Difficult')
difficult_text = self.doc.createTextNode(difficult_text_str)
difficult.appendChild(difficult_text)
object.appendChild(difficult)
bndbox = self.doc.createElement('bndbox')
xmin = self.doc.createElement('xmin')
xmin_text = self.doc.createTextNode(xmin_text_str)
xmin.appendChild(xmin_text)
bndbox.appendChild(xmin)
ymin = self.doc.createElement('ymin')
ymin_text = self.doc.createTextNode(ymin_text_str)
ymin.appendChild(ymin_text)
bndbox.appendChild(ymin)
xmax = self.doc.createElement('xmax')
xmax_text = self.doc.createTextNode(xmax_text_str)
xmax.appendChild(xmax_text)
bndbox.appendChild(xmax)
ymax = self.doc.createElement('ymax')
ymax_text = self.doc.createTextNode(ymax_text_str)
ymax.appendChild(ymax_text)
bndbox.appendChild(ymax)
object.appendChild(bndbox)
self.anno.appendChild(object)
def get_anno(self):
return self.anno
def get_doc(self):
return self.doc
def save_doc(self, save_path):
with open(save_path, "w") as f:
self.doc.writexml(f, indent='\t', newl='\n', addindent='\t', encoding='utf-8')
第三个文件是main.py,里面内容是
import os
from tqdm import tqdm
from read_json_anno import ReadAnno
from create_xml_anno import CreateAnno
def json_transform_xml(json_path, xml_path, imagePath, process_mode="rectangle"):
json_path = json_path
print(json_path)
json_anno = ReadAnno(json_path, process_mode=process_mode)
width, height = json_anno.get_width_height()
filename = json_anno.get_filename()
coordis = json_anno.get_coordis()
xml_anno = CreateAnno()
xml_anno.add_filename(imagePath)
xml_anno.add_pic_size(width_text_str=str(width), height_text_str=str(height), depth_text_str=str(3))
for xmin, ymin, xmax, ymax, label in coordis:
if ((xmax - xmin) < (width * 2 / 3)):
# xml_anno.add_object(name_text_str=str("text"),
xml_anno.add_object(name_text_str=str(label),
xmin_text_str=str(int(xmin)),
ymin_text_str=str(int(ymin)),
xmax_text_str=str(int(xmax)),
ymax_text_str=str(int(ymax)))
xml_anno.save_doc(xml_path)
if __name__ == "__main__":
root_json_dir =r"D:\桌面\xunlian\json"# json文件夹路径
root_save_xml_dir =r"D:\桌面\xunlian\xml" # 转换后保存的xml文件夹路径
for json_filename in tqdm(os.listdir(root_json_dir)):
json_path = os.path.join(root_json_dir, json_filename)
save_xml_path = os.path.join(root_save_xml_dir, json_filename.replace(".json", ".xml"))
filepath, tmpfilename = os.path.split(json_filename)
shotname, extension = os.path.splitext(tmpfilename)
img_path = shotname + ".jpg"
json_transform_xml(json_path, save_xml_path, img_path, process_mode="polygon")
# json_transform_xml(json_path, save_xml_path, process_mode="polygon")我
然后咱们只用操作第三个文件main.py,看见那个json文件了么?看见那个生成的xml文件了么?很幸运,咱们这次可以选择一键全部转换,非常棒,在这里也非常感谢那些开源的人,是你们的奉献,才能让我们站在你们的肩上,看向更远的未来,在这里由衷的感谢你们,致以崇高的敬意!!!
3—(5)将XML的编码格式转化为UTF-8
经过上一步的一键生成,大家应该很开心,终于一键生成了,非常好,但请不要开心太早,这一步,由于作者我比较菜,现在没有时间写一键转化的教程,再等个半个月,我有时间,我把我留下的那些坑都给填了,我是填坑大王,好了,继续下一步吧
由于上一步的转换,我们是成功生成了有标注的xml文件,很开心。但这个一键生成xml的文件,他是编码格式,是ANSI的编码,咱们如果要使用AI_Cube进行训练,必须选择用UTF-8的编码格式,那如何将ANSI的编码转换为UTF-8呢?很简单,使用记事本打开,然后点击另存,那下面有一个编码,如图 ,看见那个小小的编码了么?相信聪明的你,一定看见了,非常好,那就开始把你一键生成的xml,一个一个再转换为UTF-8的xml,我可以保证,你所生成的xml,每一个都是ANSI格式的,所以,我也很痛心,作者在这里狠狠的吃了两大碗米饭才平复了心情。
,看见那个小小的编码了么?相信聪明的你,一定看见了,非常好,那就开始把你一键生成的xml,一个一个再转换为UTF-8的xml,我可以保证,你所生成的xml,每一个都是ANSI格式的,所以,我也很痛心,作者在这里狠狠的吃了两大碗米饭才平复了心情。
到此为止,我们好像已经完成了,No,No,No
还记得我说过,为什么要选择长方形的框框么?对,在这个转化为UTF-8的xml文件里,会有些叛徒,他们里面是没内容的,为什么呢,因为有些时候labelme没有识别到,而单身的你手速可能有些快,就会出现,生成了xml文件没错,xml文件里面没内容,那么正常的xml文件应该是这样的,如图
 ,看看有标注的噢,在这里,提一下我董哥,是个大帅哥,单身噢,有小姐姐看上的可以私聊我,我给你联系方式噢
,看看有标注的噢,在这里,提一下我董哥,是个大帅哥,单身噢,有小姐姐看上的可以私聊我,我给你联系方式噢
非正常的xml文件长这样
 ,看看这个是没有标注信息的,是错误的。
,看看这个是没有标注信息的,是错误的。
3—(6)进行数据检查
好了,如果你经历完了以上的一切,你其实获得是一份JPG文件夹,一份编码格式为UTF-8的xml文件夹,然后,这两个文件夹的标注要一模一样,即一份0001.jpg,一份0001.xml,这样,就完成了数据的检查
3—(7)进行开始通过AI_Cube训练
要进行训练,我们首先要打开AI_Cube这个软件,这个软件需要获得申请许可才会给你噢,一般人我不告诉他,这个申请的邮箱是developersupport@canaan-creative.com,申请内容一定要说明来由,我跟你说咋说哈,大哥,行行好,给小弟我一个AI_Cube的许可证吧,小弟我已经XX天没有使用了,这样,人家会在第二天给你发一个许可证,加入你的AI_Cube的文件夹里,开始使用吧,想起来,注意哦,这个许可只有一个月,所以,下个月,记得再让大哥行行好就可以了,在这里也感谢嘉楠科技的努力,让咱们不用配置那些特别困难的环境,就可以进行一些深度学习的训练,非常棒,给你们点点赞,双击评论666。
那有许可证了,那打开吧,咱们打开之后,界面如图
点击那个新建项目,由于咱们是目标检测,就通过下拉框选择目标检测,这里呢,咱们选择的是使用Voc的数据集,还记得咱们那个JPG文件夹么,把它改改名,改为JPEGImage,那个满是UTF-8的xml文件夹改名叫Annotations,这样,就可以点击导入数据集,然后在一个空文件夹里选择项目的保存路径,可以是中文名字哦,到时候你训练的时候,起个霸气的名字,像什么闪光无敌666猪猪侠,都是可以的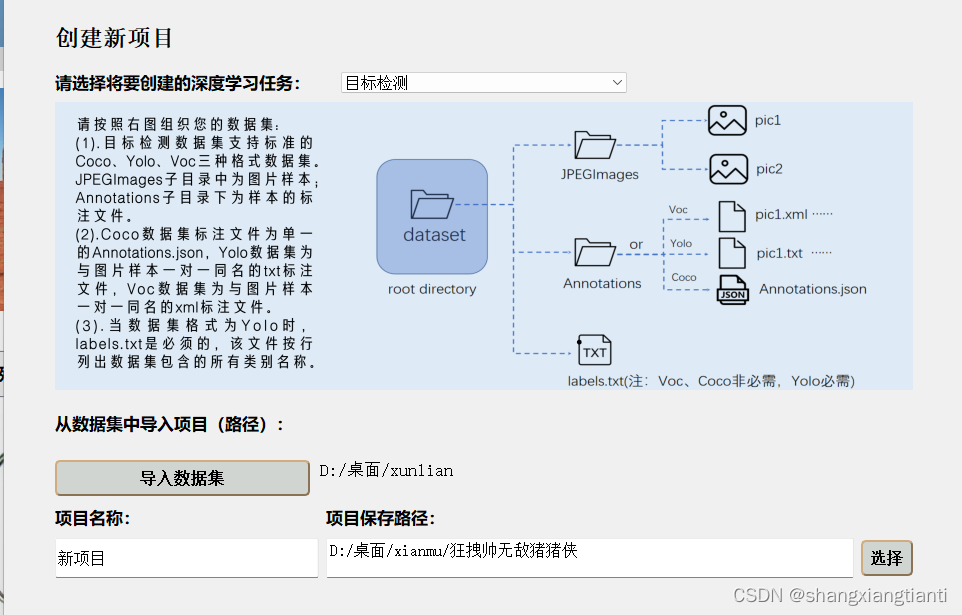 ,
,
ok,至此,咱们就可以训练的创建项目了,创建完之后,咱们就开始训练,基本参数,如果你不会,我建议你最好不要动,直接训练就可以了,很吃GPU哦,然后训练之后,点击评估,进入评估之后,先测试测试集之后,才能够部署芯片哦,心急可吃不了热豆腐哦,训练完成之后,在评估指标会有相关数据,之后,就可以进行部署了
好了,咱们的训练日记也到一段落了,留了很多的坑,等我有时间,一定把它够搞成一键生成,这样咱们就不用那么麻烦了,也谢谢你看了那么久,哈哈哈哈哈哈哈,革命尚未结束,同志,仍需努力,加油吧















 1774
1774











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









