







 这篇博客探讨了随机森林(RF)与决策树的比较。通过实例展示了如何使用Python的scikit-learn库构建和训练模型。结果显示,随机森林的准确率通常高于决策树,尤其在大数据集上表现更优。尽管在某些特定情况下可能降低,但随机森林在多数情况下提供了更稳定的预测性能。
这篇博客探讨了随机森林(RF)与决策树的比较。通过实例展示了如何使用Python的scikit-learn库构建和训练模型。结果显示,随机森林的准确率通常高于决策树,尤其在大数据集上表现更优。尽管在某些特定情况下可能降低,但随机森林在多数情况下提供了更稳定的预测性能。
随机森林(RF)
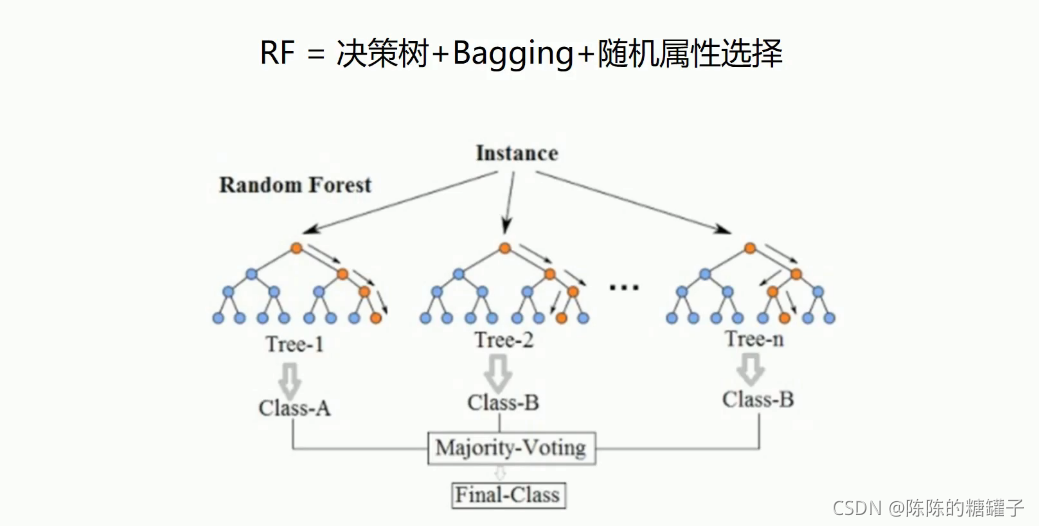
RF算法流程

from sklearn import tree
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
import numpy as np
import matplotlib.pyplot as plt
# 载入数据
data = np.genfromtxt("LR-testSet2.txt", delimiter=",")
x_data = data[:,:-1]
y_data = data[:,-1]
plt.scatter(x_data[ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 485
485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









