







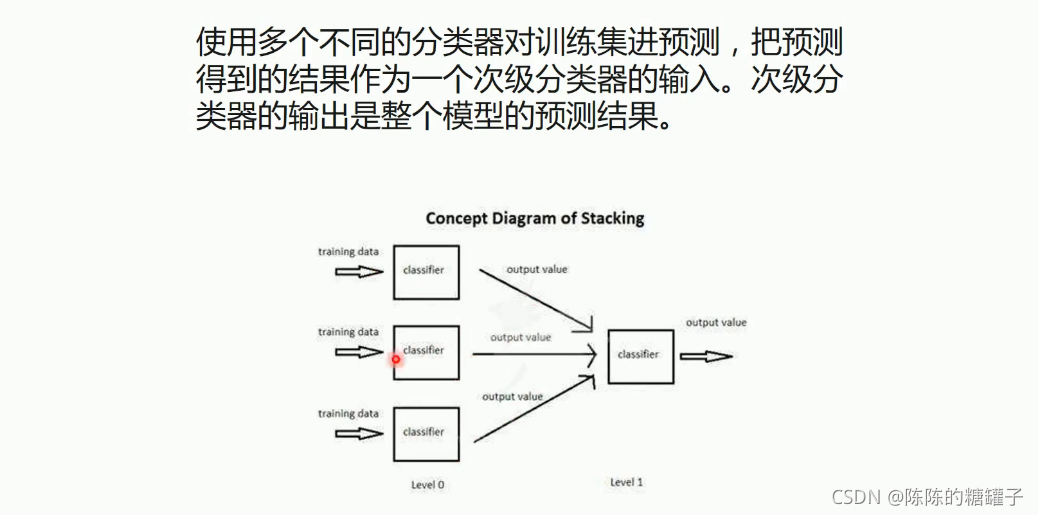
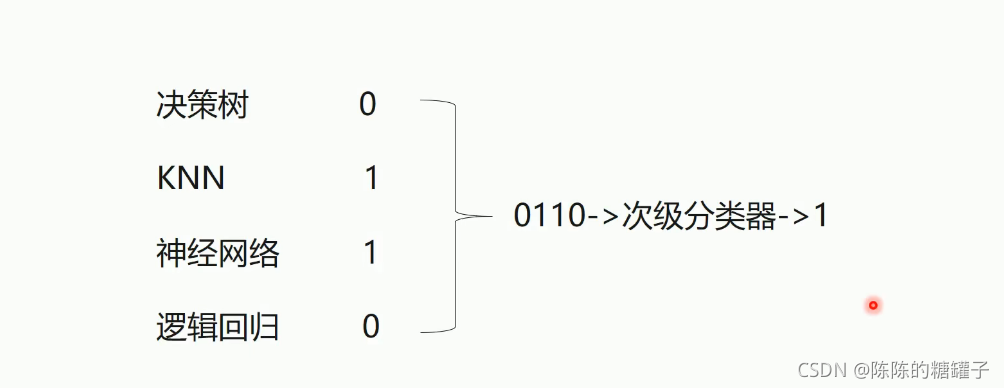
Stacking
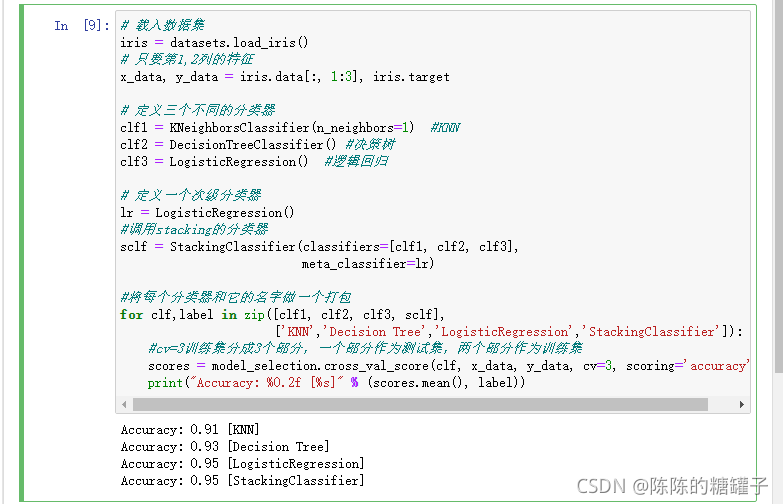
from sklearn import datasets
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from mlxtend.classifier import StackingClassifier # pip install mlxtend
import numpy as np
# 载入数据集
iris = datasets.load_iris()
# 只要第1,2列的特征
x_data, y_data = iris.data[:, 1:3], iris.target
# 定义三个不同的分类器
clf1 = KNeighborsClassifier(n_neighbors=1) #KNN
clf2 = DecisionTreeClassifier() #决策树
clf3 = LogisticRegression() #逻辑回归
# 定义一个次级分类器
lr = LogisticRegression()
#调用stacking的分类器
sclf = StackingClassifier(classifiers=[clf1, clf2, clf3],
meta_classifier=lr)
#将每个分类器和它的名字做一个打包
for clf,label in zip([clf1, clf2, clf3, sclf],
['KNN','Decision Tree','LogisticRegression','StackingClassifier']):
#cv=3训练集分成3个部分,一个部分作为测试集,两个部分作为训练集
scores = model_selection.cross_val_score(clf, x_data, y_data, cv=3, scoring='accuracy')
print("Accuracy: %0.2f [%s]" % (scores.mean(), label))
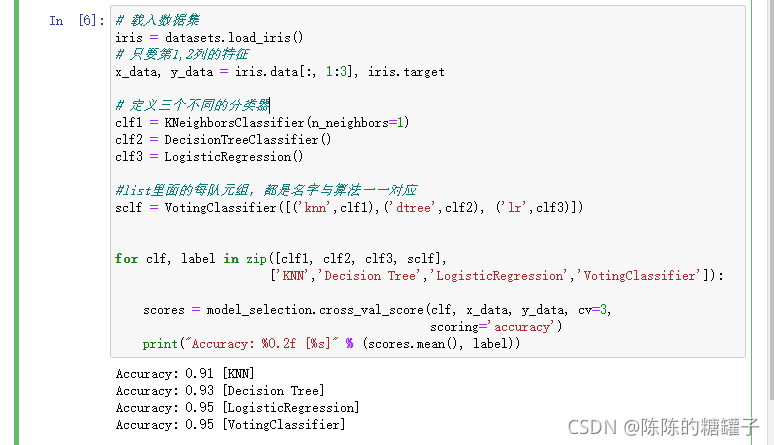
Voting
跟上面不同的是,它没有次级分类器,是进行投票,结果比较高的那个做出结果。
投票还是根据权重来取训练结果,并不是完全相信某个分类器
from sklearn import datasets
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import VotingClassifier #投票的分类器
import numpy as np
# 载入数据集
iris = datasets.load_iris()
# 只要第1,2列的特征
x_data, y_data = iris.data[:, 1:3], iris.target
# 定义三个不同的分类器
clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = DecisionTreeClassifier()
clf3 = LogisticRegression()
#list里面的每队元组,都是名字与算法一一对应
sclf = VotingClassifier([('knn',clf1),('dtree',clf2), ('lr',clf3)])
for clf, label in zip([clf1, clf2, clf3, sclf],
['KNN','Decision Tree','LogisticRegression','VotingClassifier']):
scores = model_selection.cross_val_score(clf, x_data, y_data, cv=3,
scoring='accuracy')
print("Accuracy: %0.2f [%s]" % (scores.mean(), label))














 1066
1066











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









