







一.常见目标检测网络
1.FasterRCNN (重要度★★★★★)
| 模型名称 | 记忆点 | 备注 |
| Faster-RCNN | 网络结构图 |
|
| anchor是怎样放置的? |
| |
| Extractor和Classifier是如何划分的? | 以resnet50作为backbone为例,stage3及之前的module为extractor,负责生成基础的feature map,而stage4和avgpool(7)作为classifier对ROI进行最后的预测。 | |
| 描述RPN网络? |
| |
| RPN如何调整anchor坐标生成ROI? | 1.rpn的train和test阶段,对于anchor的坐标调整并生成region proposal的过程只有nms前后两个阈值有区别。
4.rpn对所有的anchor位置进行坐标调整之后,有M(50*50*9=22500)个,并且是用原图上的绝对坐标表示的。 | |
| stage1:RPN阶段的loss如何计算的? |
| |
| stage2:classifier阶段的loss如何计算的? |
| |
| ROI pooling的两次量化精度丢失?以及ROI align的改进? | ROI Pooling
ROI放缩到feature map上,按照输出的shape通过两次量化将ROI切分成不同版块,每个版块内做max pooling。
两次量化:
ROI Align
|




2.CascadeRCNN (重要度★★★)
| 模型名称 | 记忆点 | 备注 |
| CascadeRCNN | ||
3.Mask-RCNN (重要度★★★★)
| 模型名称 | 记忆点 | 备注 |
| Mask-RCNN |
4.YoloV3 (重要度★★★★★)
| 模型名称 | 记忆点 | 备注 |
| YoloV3 | 模型结构示意图 |
|
| 快速列举YoloV3模型的特点? |
| |
| 前景背景如何判定的? |
| |
| loss计算 | loss_x = self.mse_loss(x[obj_mask], tx[obj_mask]) loss_y = self.mse_loss(y[obj_mask], ty[obj_mask]) loss_w = self.mse_loss(w[obj_mask], tw[obj_mask]) loss_h = self.mse_loss(h[obj_mask], th[obj_mask]) loss_conf_obj = self.bce_loss(pred_conf[obj_mask], tconf[obj_mask]) loss_conf_noobj = self.bce_loss(pred_conf[noobj_mask], tconf[noobj_mask]) loss_conf = self.obj_scale * loss_conf_obj + self.noobj_scale * loss_conf_noobj loss_cls = self.bce_loss(pred_cls[obj_mask], tcls[obj_mask]) total_loss = loss_x + loss_y + loss_w + loss_h + loss_conf + loss_cls |

5.YoloV4(重要度★★★★)
| 模型名称 | 记忆点 | 备注 |
| YoloV4 | ||
6.YoloV5 (重要度★★★★)
| 模型名称 | 记忆点 | 备注 |
| YoloV5 | 快速列举YoloV5模型上的创新点? |
|

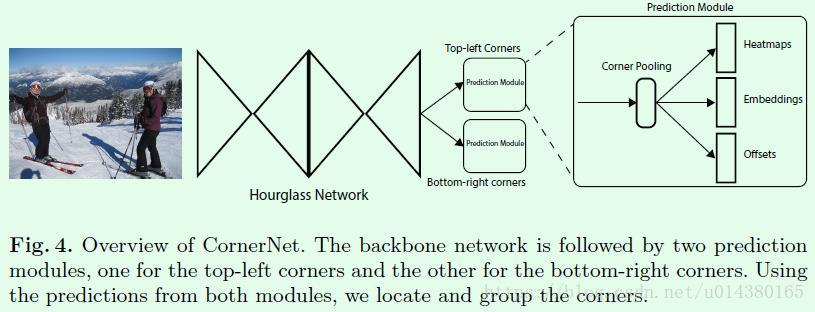
7.CornerNet (重要度★★★)
| 模型名称 | 记忆点 | 备注 |
| CornerNet | Anchor-Based目标检测算法有哪些问题? |
|
| 核心思路 |
| |
| Corner Pooling | Corner Pooling可以更好的定位边框的角点。对每个channel,从右向左,从下向上找到最大值再求和,作为该点的值。 | |
| backbone使用Hourglass | |
8.CenterNet 【论文:Object as points】 (重要度★★★★★)
| 模型名称 | 记忆点 | 备注 |
| CenterNet | 思路 | 之前的网络大部分是直接回归出中心点坐标和宽高,centernet的思路是求出概率图,然后根据概率选择中心点。 |
| CenterNet的优势/亮点 |
| |
| 架构简图 |
| |
| BackBone |
| |
| Link | Link的作用是匹配后面检测头的channel数值。
| |
| Center HeatMap | Shape是【128, 128, C】,C代表着预测类别的数量。每一层代表着一类的物体,数值代表着该类物体中心点的概率,所以整体是概率图的模式。 | |
| Offset | Shape是【128, 128, 2】,2个维度分别代表中心点误差δx和δy。预测出因为量化导致的中心点误差。原始图像是512/512,而center heatmap是128/128,这就会产生类似ROI pooling的量化,这种量化是尤其伤害小目标的预测的。为了弥补这个误差,因此需要预测出误差。 预测和真实值间的差距要和offset做L1 loss,使offset能够预测量化带来的误差。 | |
| Size | Shape是【128,128,2】,预测物体的宽高。 | |
| Other Heads | 这里充分说明了CenterNet的可扩展性,因为每个head都负责不同的功能,所以可以加入关键点检测等更多的功能,只需要设计对应的head即可。 还可以先训练某个branch,然后固定后再训练其他的branch,非常灵活。 | |
| 正负样本的划分 |
| |
| Loss的设计 | 中心点loss:
offset loss:
size loss:
total loss:
| |
| 如何inference? |
默认未使用NMS,而是使用3x3的max pooling找到8-邻域最大值,然后得到100个峰值。 |











9.FCOS (重要度★★★)
| 模型名称 | 记忆点 | 备注 |
10.EfficientDet (重要度★★★★)
| 模型名称 | 记忆点 | 备注 |
| 设计理念 |
| |
| 架构图 |  | |
| BackBone(EfficientNet) | Backbone使用了EfficietNet,通过复合缩放策略平衡模型的深度、宽度和分辨率。
最终使用了Compound Scaling的缩放策略,比单一调整分辨率和深度、宽度的效果更好,具体如上图。最后得到的compound 参数见下图:
baseline是用mobileNetV2 + SE 用NAS搜索出来的结构,然后再上面进行缩放。
α、β、γ都是网格搜索出来的基数,Φ是人工调节的,比如计算量扩大十倍,Φ=3.32。
| |
| BiFPN |
|





二.常见OCR模型
| 模型名称 | 记忆点 | 备注 |
| CRNN(2015) | 优势 |
|
| Attention-OCR | ||
| DBNet |
三.常见人脸识别模型
| 模型名称 | 记忆点 | 备注 |
| 人脸识别的流程 | 人脸识别的流程 |
|
| MTCNN(2015) | 使用了Region Proposal的思路 |
|
| LightCNN(2017) 【人脸识别】 | 不使用Relu的原因 | 主要是为了加速,减少计算量。 |
| MFM(Max Feature Map) |
将feature map分为两组,然后对应的特征图逐像素取最大值。实现通道减半的功能。Max函数本身也能提供非线性的能力。 | |
| Semantic BootStrapping for Noisy Labels | 实际上就是Presedo labeling的思路。 另外有论文研究表明,label有一点noise在数学上可以等同于图像有一点noise,所以算是一种data augmentation方法。 | |
| Dlib-alignment | ||
| FaceBoxes(2018) 【人脸检测】 | 优势 | RealTime on CPU, 100FPS+ on GPU。 |
| 整体架构图 |
| |
| CRelu的思路 |
理解:作者观察到卷积核在conv5之后是完全呈现出反向的,也就是卷积核的向量夹角余弦值接近于-1。那么使用这样的卷积核做卷积在做激活和先做relu,再取反做relu是几乎等价的,但是却省去了很多计算量。 CRelu只用在浅层,起到减少计算量的作用。 | |
| Rapidly Digested Convolutional Layers | 出于速度上的考虑,使用了快速降低resolution的方案。这个结构完全可以当成backbone换成各种其他网络,比如resnet18。
| |
| Inception |
| |
| 稠密anchor |
在32x32的尺度上摆放了21(4x4 + 4+ 1)个anchor。 下面具体来解释这个21是怎么来的: 首先模型是在3个尺度上放置anchor,尺度分别是32x32、64x64、128x128。默认放置的anchor大小是这些尺度的4倍。比如32x32就分别在每个grid放置32x4=128的anchor,64x64放置256x256的anchor,128x128放置512x512的anchor。但是在32x32上除了放置128的框还会防止64和32的,所以实际上每个位置放置16个32x32的,4个64x64的,1个128x128的共21个anchor。 | |
| BlazeFace(2019) | ||
| InsightFace(2019) |







四.常见GAN模型
| 模型名称 | 记忆点 | 备注 |
| GAN | 基本思路 |
|
| 架构简图 |
| |
| 价值函数 |
















 1325
1325

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









