





连续分布(Continuous Distributions)
抛硬币对应离散分布(discrete distribution)——与离散输出有关的概率。我们常常想在整个输出上模拟分布(为了这个目的,输出总是实数,虽然在现实生活中不总是这样)。例如,均匀分布(uniform distribution)在0到1之间具有相同的权重。
因为在0到1之间可以取无限个数,这个意味着分配给单个点的权重几乎是0,为了这个原因,我们使用概率密度函数(pdf)表示一个连续分布,以便于一个数值在周围某个区间的概率等于pdf在这个区间上的积分。
notice:如果你对积分不熟,你可以这样理解,如果一个分布的概率密度函数是f,那么在x和x+h之间的数值的概率接近等于h*f(x),前提是h很小。
均匀分布的密度函数是:
def uniform_pdf(x):
return 1 if x >= 0 and x < 1 else 0我们常常对累计概率分布函数(cdf)感兴趣,一个随机变量小于等于某个值的概率。对于均匀分布不难创建累计分布函数:
def uniform_cdf(x):
"returns the probability that a uniform random variable is <= x"
if x < 0: return 0 # uniform random is never less than 0
elif x < 1: return x # e.g. P(X <= 0.4) = 0.4
else: return 1 # uniform random is always less than 1
正态分布(The Normal Distribution)
正态分布是分布的国王,它是经典的钟型曲线分布,完全有2个参数确定:均值(mu)和标准差(sigma)。均值决定正态分布的中心,标准差决定其宽度。
公式如下:
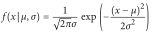
代码如下:
def normal_pdf(x, mu=0, sigma=1):
sqrt_two_pi = math.sqrt(2 * math.pi)
return (math.exp(-(x-mu) ** 2 / 2 / sigma ** 2) / (sqrt_two_pi * sigma))绘制pdf:
xs = [x / 10.0 for x in range(-50, 50)]
plt.plot(xs,[normal_pdf(x,sigma=1) for x in xs],'-',label='mu=0,sigma=1')
plt.plot(xs,[normal_pdf(x,sigma=2) for x in xs],'--',label='mu=0,sigma=2')
plt.plot(xs,[normal_pdf(x,sigma=0.5) for x in xs],':',label='mu=0,sigma=0.5')
plt.plot(xs,[normal_pdf(x,mu=-1) for x in xs],'-.',label='mu=-1,sigma=1')
plt.legend()
plt.title("Various Normal pdfs")
plt.show()
当 μ=0和 σ=1,成为标准正态分布。如果Z是一个标准正态随机变量,那么结果:
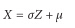
这个也是正态分布,但是其均值为μ和标准差为σ。相反的,如果X是一个正态随机变量,其均值为μ,标准差为σ,
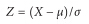
是一个标准正态变量。
有时我们需要反转normal_cdf找到对应概率的数值。反转过来计算数值没有那么容易,但是normal_cdf是连续的并且递增,所以我们可以使用二值搜索(binary search):
def inverse_normal_cdf(p, mu=0, sigma=1, tolerance=0.00001):
"""find approximate inverse using binary search"""
# if not standard, compute standard and rescale
if mu != 0 or sigma != 1:
return mu + sigma * inverse_normal_cdf(p, tolerance=tolerance)
low_z, low_p = -10.0, 0 # normal_cdf(-10) is (very close to) 0
hi_z, hi_p = 10.0, 1 # normal_cdf(10) is (very close to) 1
while hi_z - low_z > tolerance:
mid_z = (low_z + hi_z) / 2 # consider the midpoint
mid_p = normal_cdf(mid_z) # and the cdf's value there
if mid_p < p:
# midpoint is still too low, search above it
low_z, low_p = mid_z, mid_p
elif mid_p > p:
# midpoint is still too high, search below it
hi_z, hi_p = mid_z, mid_p
else:
break
return mid_z这个函数重复平分区间直到Z足够小,得到希望的概率。
中心极限定理(The Central Limit Theorem)
正态分布非常有用的一个理由是中心极限定理。一个随机变量定义为很多个独立同分布的随机变量的均值,则这样的随机变量近似正态分布。
尤其,如果x 1 ,…,x n具有相同的均值μ和标准差σ,并且n足够大,则:
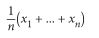
近似服从均值为 μ 和标准差为 σn√ 的正态分布。等于(但是常常更加有用):
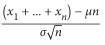
近似服从标准正态分布( μ 为0, σ 为1)。
一个简单的证明就是二项随机变量,有2个参数n和p。一个Binomial(n,p)随机变量是n个 独立Bernoulli(p)随机变量的求和。每个都是等于1其概率为p,等于0其概率为1-p:
def bernoulli_trial(p):
return 1 if random.random() < p else 0
def binomial(n, p):
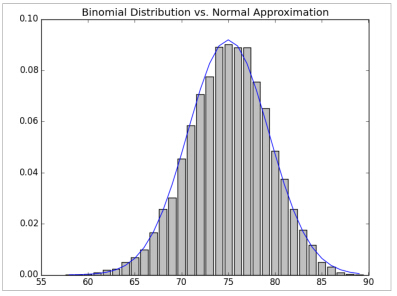
return sum(bernoulli_trial(p) for _ in range(n))Bernoulli(p)变量的均值是p,标准差是 p(1−p)−−−−−−−√ 。中心极限定理说的是当n增大,Binomial(n,p)变量近似服从均值为 μ=np ,标准差是 σ=np(1−p)−−−−−−−−√ ,如果我们画出来,你就很容易看出来相似性:
def make_hist(p, n, num_points):
data = [binomial(n, p) for _ in range(num_points)]
# use a bar chart to show the actual binomial samples
histogram = Counter(data)
plt.bar([x - 0.4 for x in histogram.keys()],
[v / num_points for v in histogram.values()],
0.8,
color='0.75')
mu = p * n
sigma = math.sqrt(n * p * (1 - p))
# use a line chart to show the normal approximation
xs = range(min(data), max(data) + 1)
ys = [normal_cdf(i + 0.5, mu, sigma) - normal_cdf(i - 0.5, mu, sigma)
for i in xs]
plt.plot(xs,ys)
plt.title("Binomial Distribution vs. Normal Approximation")
plt.show()例如,当你调用make_hist(0.75,100,1000)时,你会得到下图:















 4226
4226

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









