







文章
2021.CVPR.Anomaly Detection in Video via Self-Supervised and Multi-Task Learning
资源
问题描述
以往的方法都是单独考虑单个任务,在某些场景下不好:
如,车突然停了,但是重构预测都很好,就是因为没有考虑上下文。
思想
同时完成四项任务:
1、在时间纬度上进行正序和倒序的训练
2、在连续维度上判断是否为连续帧
3、在预测维度上,预测空缺帧
4、学习教师模型
做法

-
用预训练好的yolov3进行检测,获得目标物体,并在前后k帧范围内进行检测,获得数据:
- arrow of time,正序,倒序的2k+1帧,正序为一类,倒序为另一类
- motion irregularity,正序2k+1帧,正序但是随机采样,不连续的2k+1帧,连续为一类,不连续为另一类
- missing middle box,正序2k帧,中间帧被扣掉,目的是预测中间帧
- middle box,用教师模型进行学习
-
同时训练四个任务,这四个任务共享前面的权重(3d卷积),各个任务头的loss如下:
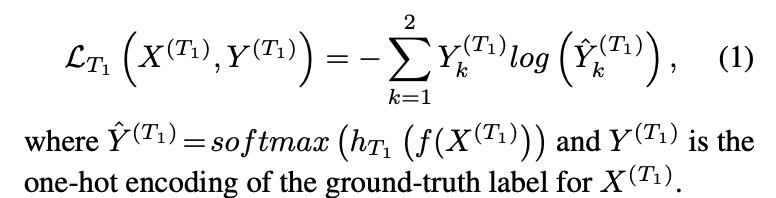
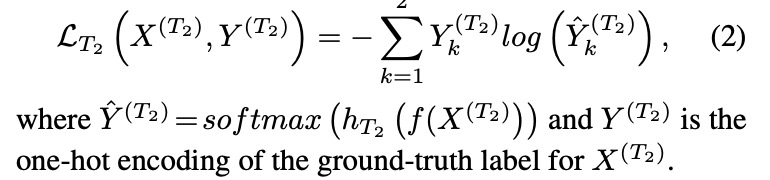
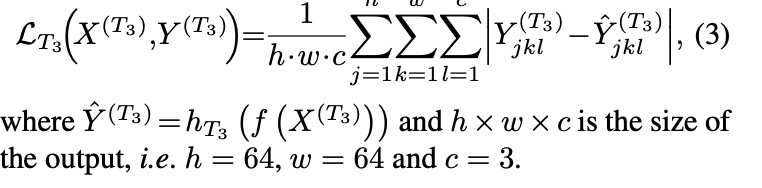
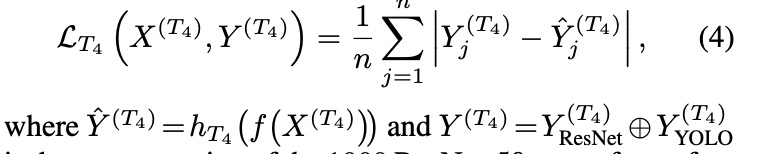
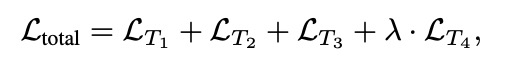
-
预测阶段,获得的最终分数:
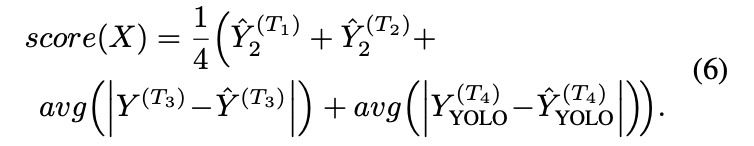
网络

结果
上面的分数转化为pixel-level的,因为这种方法是基于检测出的物体得到的分数,所以最终还是要转化为帧级别的(分数做了时间维度上的平滑):
第一是物体级别:对像素级别的做3d mean filter,取最大;
第二是帧级别:不用yolov3
第三种是late fusion。
做
存在的问题
略复杂?















 1538
1538











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









