







A brief introduction to weakly supervised learning
分类
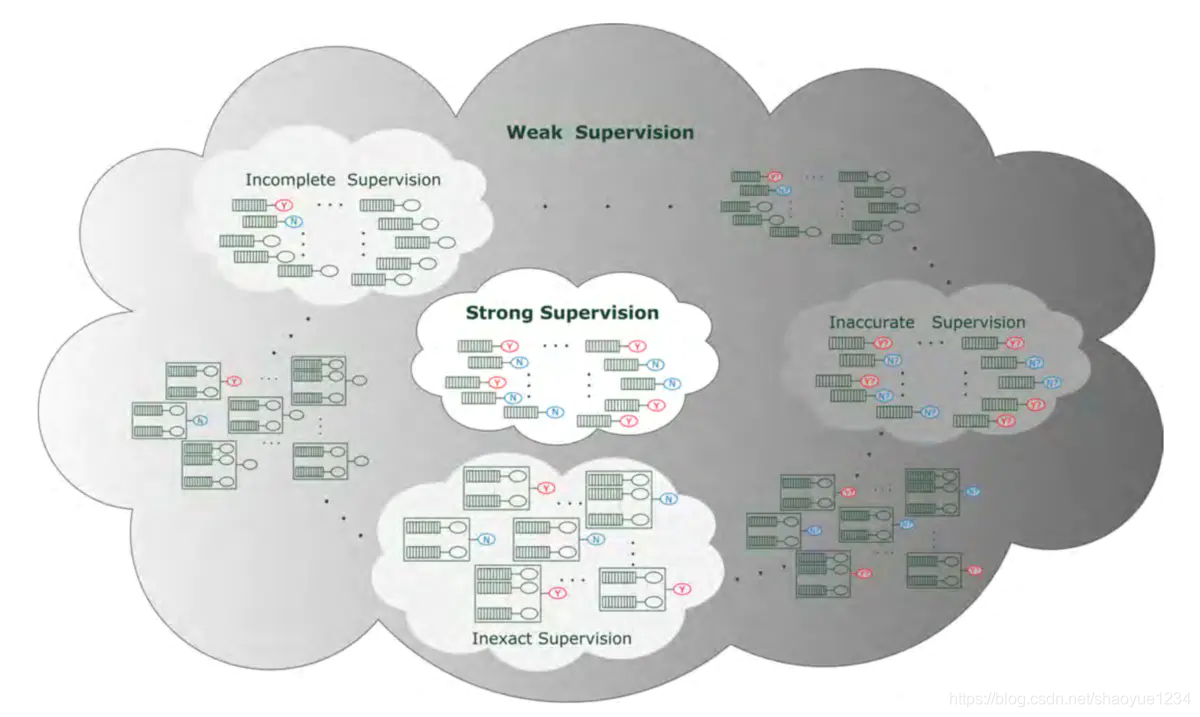
- incomplete supervision:只有一部分子集给出标签;
- inexact supervision:训练集样本只给出大概的标签;
- inaccurate supervision:训练集样本不一定可信。
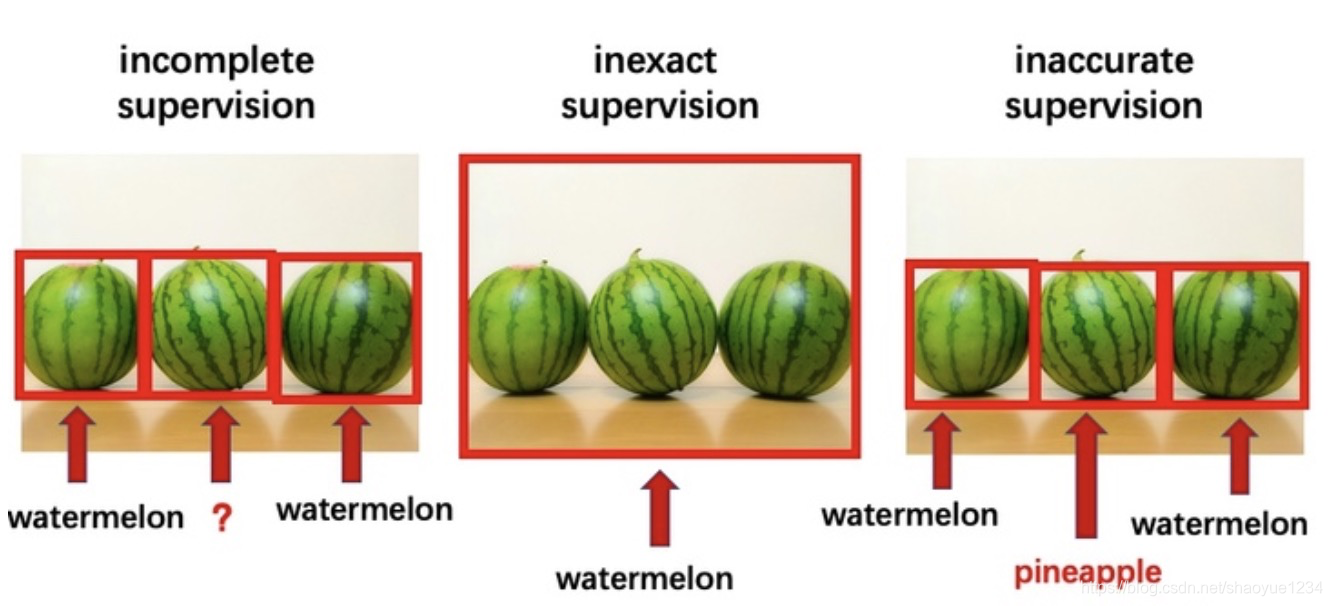
需要注意的是这三种方法往往可以同时运用。
应用

常用方法
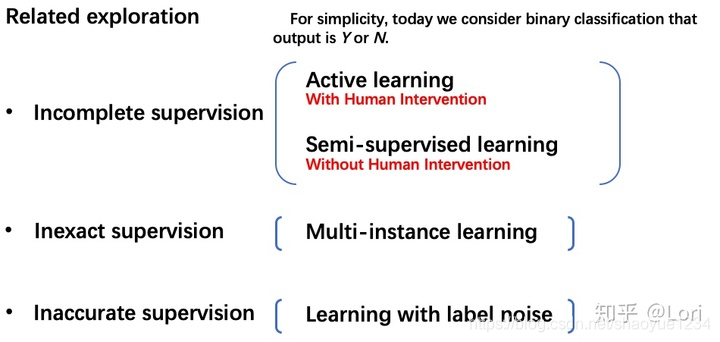
incomplete supervision
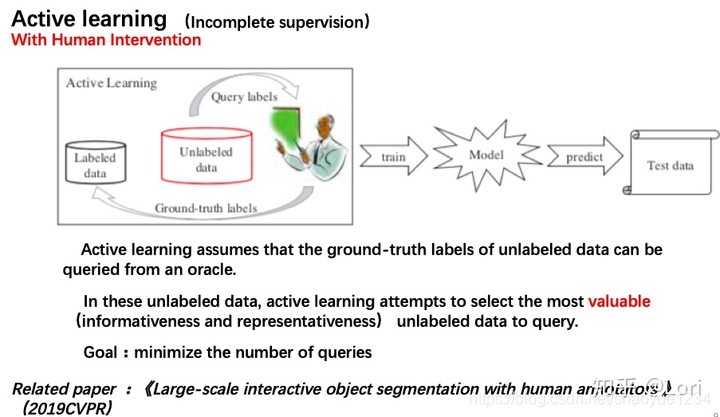
active learning
-
假设:未标注数据的真值标签可以向"先知”查询。
-
思想:标注成本只与查询次数有关->主动学习的目标就是最小化查询次数->
选最有价值的未标注数据来查询先知 -
价值衡量标准:
- 信息量(informativeness)一个未标注数据能够在多大程度上降低统计模型的不确定性。
- 不确定抽样(uncertainty sampling)训练单个学习器,选择学习器最不确信的样本向先知询问标签信息;投票询问(query-by-committee)生成多个学习器,选择各个学习器争议最大的样本向先知询问标签信息。
- 代表性(representativeness)衡量一个样本在多大程度上能代表模型的输入分布。
- 用聚类方法来挖掘未标注数据的集群结构
- 同时利用信息量和代表性度量:
- 基于信息量的方法,主要缺点是为了建立选择查询样本所需的初始模型,而严重依赖于标注数据,并且当标注样本较少时,其性能通常不稳定。基于代表性的方法,主要缺点在于其性能严重依赖于由未标注数据控制的的聚类结果,当标注数据较少时尤其如此。
- 信息量(informativeness)一个未标注数据能够在多大程度上降低统计模型的不确定性。
-
理论研究
- 已经证明对于可实现(realizable)情况(假设数据在假设的空间中完全可分),随着样本复杂性的增加,主动学习的性能可以获得指数提升。对于不可实现(non-realizable)的情况(即由于噪声的存在,以致数据在任何假设下都不完全可分),在没有对噪声模型的先验假设时,主动学习的下确界相当于被动学习的上确界,换句话说,主动学习并不是非常有用。当假设噪声为Tsybakov噪声模型时,我们可以证明,在噪声有界的条件下,主动学习的性能可呈指数级提升;如果能够挖掘数据的一些特定性质,像多视角结构(multi-view structure),那么即使在不对噪声进行限制的情况下,其性能也能呈指数级提升。换句话说,只要设计得巧妙,主动学习在解决困难问题时仍然有用。
- 已经证明对于可实现(realizable)情况(假设数据在假设的空间中完全可分),随着样本复杂性的增加,主动学习的性能可以获得指数提升。对于不可实现(non-realizable)的情况(即由于噪声的存在,以致数据在任何假设下都不完全可分),在没有对噪声模型的先验假设时,主动学习的下确界相当于被动学习的上确界,换句话说,主动学习并不是非常有用。当假设噪声为Tsybakov噪声模型时,我们可以证明,在噪声有界的条件下,主动学习的性能可呈指数级提升;如果能够挖掘数据的一些特定性质,像多视角结构(multi-view structure),那么即使在不对噪声进行限制的情况下,其性能也能呈指数级提升。换句话说,只要设计得巧妙,主动学习在解决困难问题时仍然有用。
semi-supervised learning
- 假设
- 聚类假设(cluster assumption):数据具有内在的聚类结构,因此,落入同一个聚类的样本类别相同。
- 流形假设(manifold assumption);数据分布在一个流形上,因此,相近的样本具有相似的预测。
- 方法
- 生成式方法(generative methods)
- 假设标注数据和未标注数据都由一个固有的模型生成。因此,未标注数据的标签可以看作是模型参数的缺失,并可以通过EM算法(期望-最大化算法)等方法进行估计。这类方法随着为拟合数据而选用的不同生成模型而有所差别。
- 基于图的方法(graph-based methods)
- 构建一个图,其节点对应训练样本,其边对应样本之间的关系(通常是某种相似度或距离),而后依据某些准则将标注信息在图上进行扩散;例如标签可以在最小分割图算法得到的不同子图内传播【23】。很明显,模型的性能取决于图是如何构建的【26-28】。值得注意的是,对于m个样本点,这种方法通常需要O(m^2 )存储空间和O(m^3)计算时间复杂度。因此,这种方法严重受制于问题的规模;而且由于难以在不重建图的情况下增加新的节点,所以这种方法天生难以迁移。
- 低密度分割法(low-density separation methods)
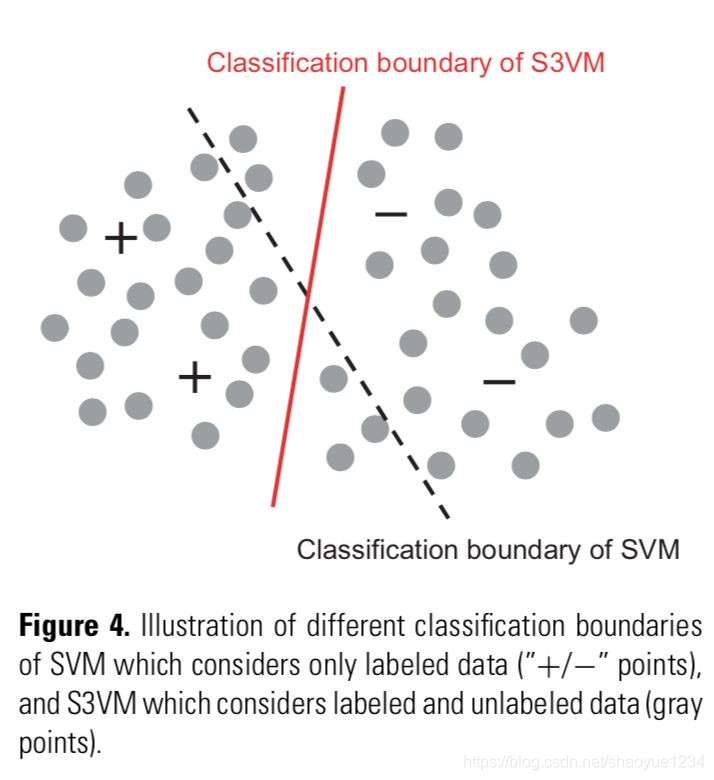
- 强制分类边界穿过输入空间的低密度区域。最著名的代表就是S3VMs(半监督支持向量机)。图示意了一般的监督SVM和S3VM的区别。很明显,S3VM试图在保持所有标注样本分类正确的情况下,建立一个穿过低密度区域的分类界面。这一目标可以通过用不同方法给未标注数据分配标签来达成,而这往往会造成优化问题很复杂。因此,在这个方向很多的研究都致力于开发高效的优化方法。
- 基于分歧的方法(disagreement methods)
- 生成多个学习器,并让它们合作来挖掘未标注数据,其中不同学习器之间的分歧是让学习过程持续进行的关键。最为著名的典型方法——联合训练(co-traing),通过从两个不同的特征集合(或视角)训练得到的两个学习器来运作。在每个循环中,每个学习器选择其预测置信度最高的未标注样本,并将其预测作为样本的伪标签来训练另一个学习器。这种方法可以通过学习器集成来得到很大提升【34,35】。值得注意的是,基于分歧的方法提供了一种将半监督学习和主动学习自然地结合在一起的方式:它不仅可以让学习器相互学习,对于两个模型都不太确定或者都很确定但相互矛盾的未标注样本,还可以被选定询问“先知”。
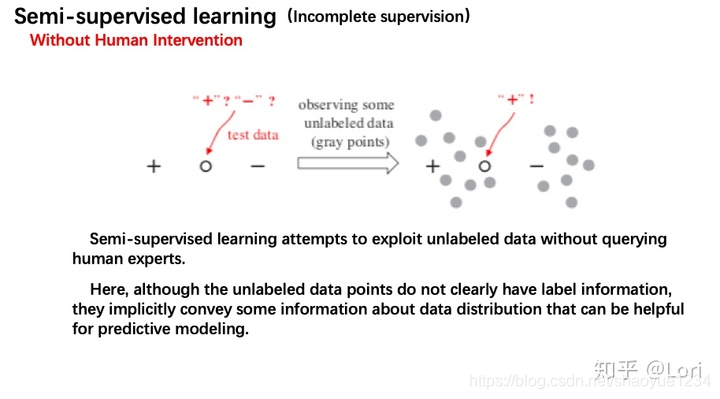
- 生成多个学习器,并让它们合作来挖掘未标注数据,其中不同学习器之间的分歧是让学习过程持续进行的关键。最为著名的典型方法——联合训练(co-traing),通过从两个不同的特征集合(或视角)训练得到的两个学习器来运作。在每个循环中,每个学习器选择其预测置信度最高的未标注样本,并将其预测作为样本的伪标签来训练另一个学习器。这种方法可以通过学习器集成来得到很大提升【34,35】。值得注意的是,基于分歧的方法提供了一种将半监督学习和主动学习自然地结合在一起的方式:它不仅可以让学习器相互学习,对于两个模型都不太确定或者都很确定但相互矛盾的未标注样本,还可以被选定询问“先知”。
- 生成式方法(generative methods)
二者的区别
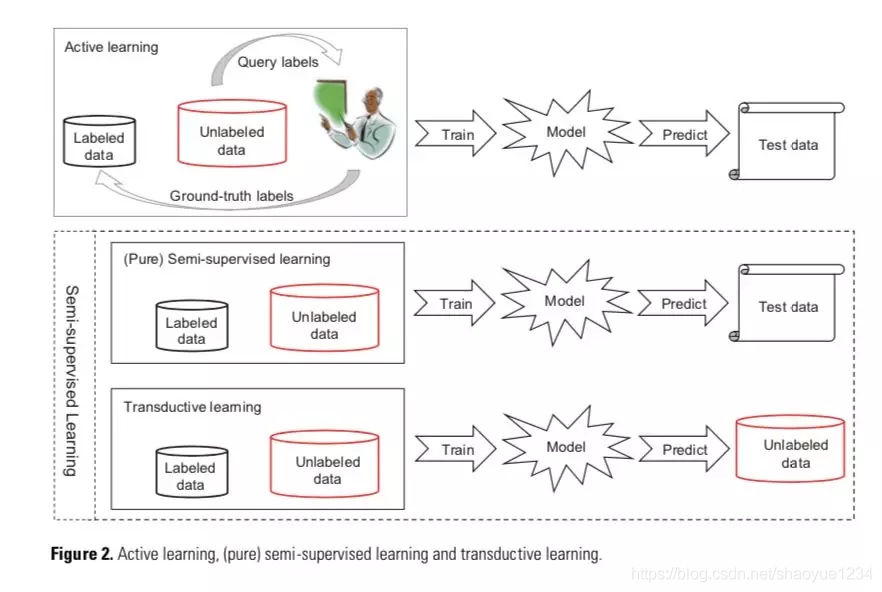
inexact supervision
multi-instance learning

inaccurate supervision
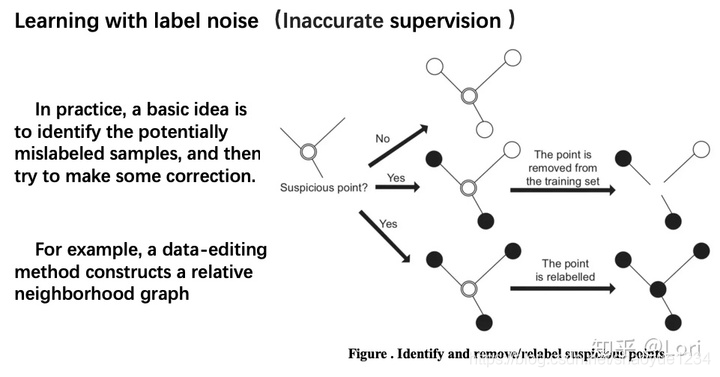
learning with label noise














 1171
1171











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









