







转自 https://blog.csdn.net/litefish/article/details/53939882
android屏幕刷新显示机制
前言
本文是通过阅读各种文章及代码,总结出来的,其中难免有些地方理解得不对,欢迎大家批评指正。
显示系统基础知识
定义
在一个典型的显示系统中,一般包括CPU、GPU、display三个部分, CPU负责计算数据,把计算好数据交给GPU,GPU会对图形数据进行渲染,渲染好后放到buffer里存起来,然后display(有的文章也叫屏幕或者显示器)负责把buffer里的数据呈现到屏幕上。很多时候,我们可以把CPU、GPU放在一起说,那么就是包括2部分,CPU/GPU 和display(本文主要按后面这种分类来解释)。
tearing: 一个屏幕内的数据来自2个不同的帧,画面会出现撕裂感
jank: 一个帧在屏幕上连续出现2次
lag:从用户体验来说,就是点击下去到呈现效果之间存在延迟
屏幕刷新频率: 一秒内屏幕刷新多少次,或者说一秒内显示了多少帧的图像,屏幕扫描是从左到右,从上到下执行的。显示器并不是一整个屏幕一起输出的,而是一个个像素点输出的,我们看不出来,是因为速度太快了,人有视觉暂留,所以看不出来。
screen tearing
显示过程,简单的说就是CPU/GPU准备好数据,存入buffer,display从buffer中取出数据,然后一行一行显示出来。display处理的频率是固定的,比如每个60ms显示完一帧,但是CPU/GPU写数据是不可控的,所以会出现有些数据根本没显示出来就被重写了,buffer里的数据可能是来自不同的帧的, 出现画面“割裂”,这就叫tearing。
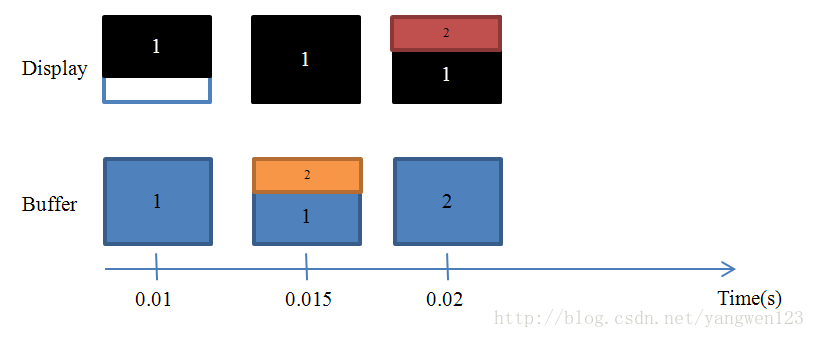
display从显示第一行到显示最后一行,我们称为一个显示周期,在一个显示周期内,如果cpu/gpu改写了后边的buffer的内容,就会出现tearing。举个例子,假设显示周期为0.01秒。
0-0.01秒的时候,CPU/GPU写了一帧数据,那display就正确的显示。
0.01-0.02秒的时候,CPU/GPU写了2帧数据(第二帧,第三帧),那display就会上半部分显示第二帧,下半部分显示第三帧,出现撕裂情况。
这其实可以类比成一个跑步游戏,display和CPU/GPU都在一个圆形操场上跑步,display慢,2者不同步,所以就会出现tearing问题。
老外还有副图解释tearing,下边的panel就是display,但是下图我比较费解,人眼看到的一帧帧图像应该是跟着Panel的,怎么会是跟着GPU的呢?人眼的识别频率大约60Hz,应该是跟panel的刷新频率类似的。

简单的说就是display在显示的过程中,buffer内数据被CPU/GPU修改,导致tearing
实际效果举例如下。也有人说CPU/GPU的频率高于display才会有tearing,这也是错误的。CPU/GPU的频率低于display也可能产生tearing的,比如display为100Hz,CPU/GPU为80Hz,那么在0.01时候显示buffer里的第一屏数据,底部会有留白,因为buffer没填满。而第二秒的时候,此时CPU/GPU,处理了1.6个buffer,所以此时buffer内的前60%是第二帧,后40%是第一帧,那也是会tearing的。
只有CPU/GPU的频率是display刷新频率的整数倍或者1/N时才不会产生tearing。
比如60Hz的刷新频率,那CPU/GPU的频率得是60, 120, 30才可以.
但是但是,实际上display的刷新频率是固定的,但是CPU/GPU写buffer的时间是不定的,所以tearing的产生几乎是必然的。

double-buffer
tearing发生的原因是display读buffer同时,buffer被修改,那么多一个buffer是不是能解决问题,是的,事实上目前所有的显示系统都是双缓存的,单缓存存在于30年前。
双缓冲技术,基本原理就是采用两块buffer。一块back buffer用于CPU/GPU后台绘制,另一块framebuffer则用于显示,当back buffer准备就绪后,它们才进行交换。不可否认,doublebuffering可以在很大程度上降低screen tearing错误,但是它是万能的吗?
一个需要考虑的问题是我们什么时候进行两个缓冲区的交换呢?假如是back buffer准备完成一帧数据以后就进行,那么如果此时屏幕还没有完整显示上一帧内容的话,肯定是会出问题的。看来只能是等到屏幕处理完一帧数据后,才可以执行这一操作了。
我们知道,一个典型的显示器有两个重要特性,行频和场频。行频(Horizontal ScanningFrequency)又称为“水平扫描频率”,是屏幕每秒钟从左至右扫描的次数; 场频(Vertical Scanning Frequency)也称为“垂直扫描频率”,是每秒钟整个屏幕刷新的次数。由此也可以得出它们的关系:行频=场频*纵坐标分辨率。
当扫描完一个屏幕后,设备需要重新回到第一行以进入下一次的循环,此时有一段时间空隙,称为VerticalBlanking Interval(VBI)。大家应该能想到了,这个时间点就是我们进行缓冲区交换的最佳时间。因为此时屏幕没有在刷新,也就避免了交换过程中出现 screentearing的状况。VSync(垂直同步)是VerticalSynchronization的简写,它利用VBI时期出现的vertical sync pulse来保证双缓冲在最佳时间点才进行交换。
所以说V-sync这个概念并不是Google首创的,它在早些年前的PC机领域就已经出现了。不过Android 4.1给它赋予了新的功用,稍后就可以看到。
android
为了优化显示性能,android 4.1版本对Android Display系统进行了重构,实现了Project Butter,引入了三个核心元素,即VSYNC、Triple Buffer和Choreographer。
CPU/GPU根据VSYNC信号同步处理数据
Project Butter规定系统一旦收到vsync通知(16ms触发一次),CPU和GPU就立刻开始工作把显示数据写入buffer。在这之前,CPU和GPU的写buffer时机是比较随意的,这么做有什么好处呢?
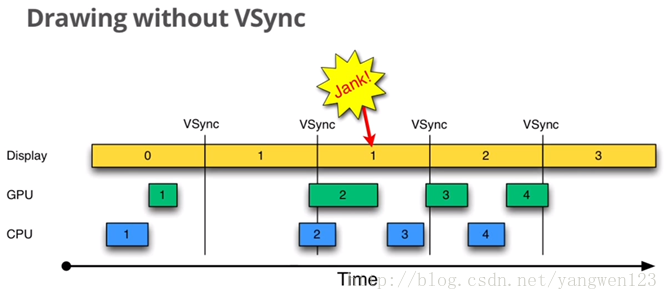
看下图,这是4.1之前android绘制图形的一个case,使用了双缓冲
以时间的顺序来看下将会发生的异常:
Step1. Display显示第0帧数据,此时CPU和GPU渲染第1帧画面,而且赶在Display显示下一帧前完成
Step2. 因为渲染及时,Display在第0帧显示完成后,也就是第1个VSync后,正常显示第1帧
Step3. 由于某些原因,比如CPU资源被占用,系统没有及时地开始处理第2帧,直到第2个VSync快来前才开始处理
Step4. 第2个VSync来时,由于第2帧数据还没有准备就绪,显示的还是第1帧。这种情况被Android开发组命名为“Jank”。
Step5. 当第2帧数据准备完成后,它并不会马上被显示,而是要等待下一个VSync。
所以总的来说,就是屏幕平白无故地多显示了一次第1帧。原因大家应该都看到了,就是CPU没有及时地开始着手处理第2帧的渲染工作,以致“延误军机”。 Android在4.1之前一直存在这个问题。
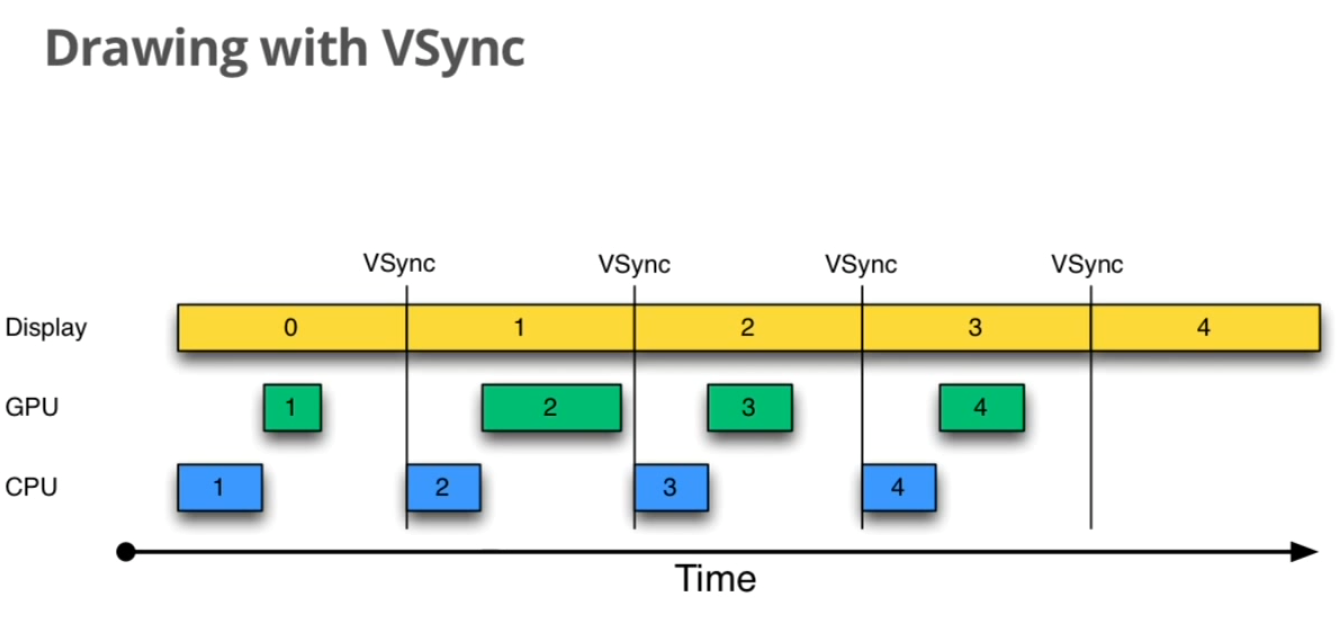
现在加入了这个规则,旦收到vsync通知(16ms触发一次),CPU和GPU就立刻开始工作把显示数据写入buffer。效果如下所示。
CPU/GPU根据VSYNC信号同步处理数据,可以让CPU/GPU有完整的16ms时间来处理数据,减少了jank。假如CPU/GPU的FPS(FramesPer Second)高于这个值,那么这个方案是完美的,显示效果将很好。
一句话总结,vync同步使得CPU/GPU充分利用了16ms时间,减少jank
Triple Buffer
在双缓存的基础上,android又引入了三缓存技术,这是拿来干嘛的呢?
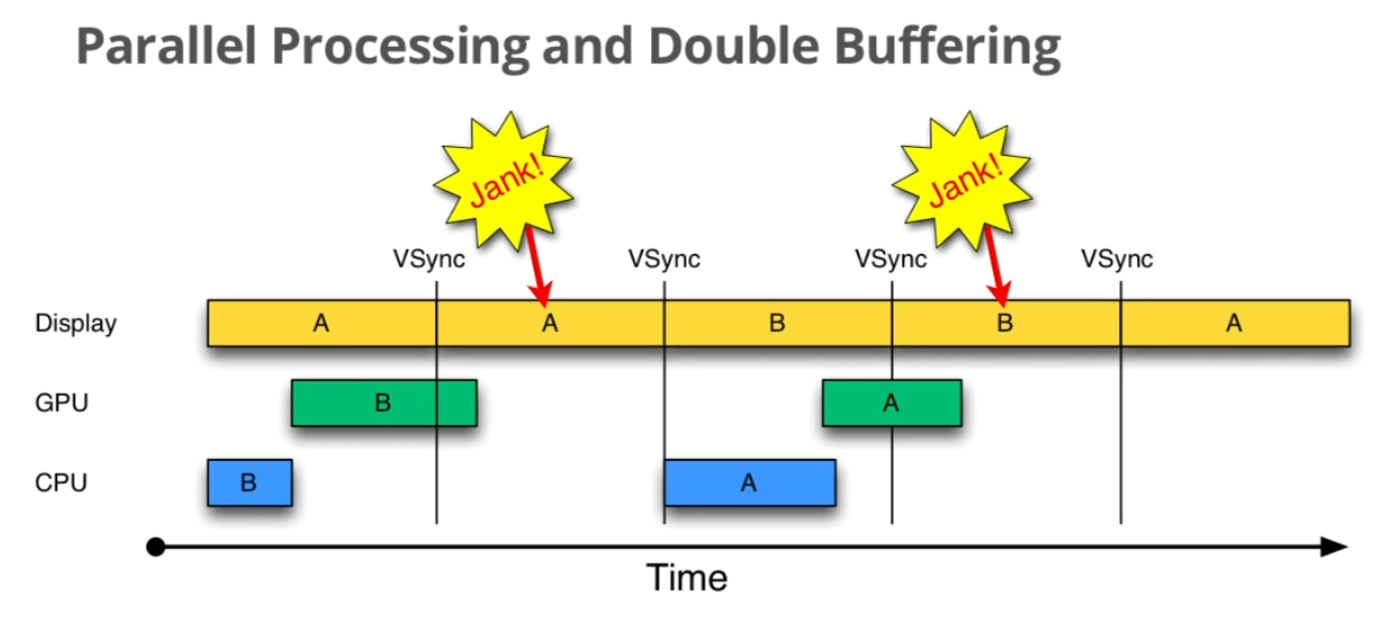
举个例子,如果界面比较复杂,CPU/GPU的处理时间较长,会出现如下情况
当CPU/GPU的处理时间超过16ms时,第一个VSync到来时,缓冲区B中的数据还没有准备好,于是只能继续显示之前A缓冲区中的内容。而B完成后,又因为缺乏VSync pulse信号,它只能等待下一个signal的来临。于是在这一过程中,有一大段时间是被浪费的。当下一个VSync出现时,CPU/GPU马上执行操作,此时它可操作的buffer是A,相应的显示屏对应的就是B。这时看起来就是正常的。只不过由于执行时间仍然超过16ms,导致下一次应该执行的缓冲区交换又被推迟了——如此循环反复,便出现了越来越多的“Jank”。
那么有没有规避的办法呢?
很显然,第一次的Jank看起来是没有办法的,除非升级硬件配置来加快FPS。我们关注的重点是被CPU/GPU浪费的时间段,怎么才能充分利用起来呢?分析上述的过程,造成CPU/GPU无事可做的假象是因为当前已经没有可用的buffer了。换句话说,如果增加一个buffer,情况会不会好转呢?
我们来逐步分析下这个是否有效。首先和预料中的一致,第一次“Jank”无可厚非。不过让人欣慰的是,当第一次VSync发生后,CPU不用再等待了,它会使用第三个buffer C来进行下一帧数据的准备工作。虽然对缓冲区C的处理所需时间同样超过了16ms,但这并不影响显示屏——第2次VSync到来后,它选择buffer B进行显示;而第3次VSync时,它会接着采用C,而不是像double buffering中所看到的情况一样只能再显示一遍B了。这样子就有效地降低了jank。但是带来了lag的问题,如上图所示,A这一帧在第4个vsync来的时候才显示,如果是双缓冲,那在第三个vynsc就可以显示了。
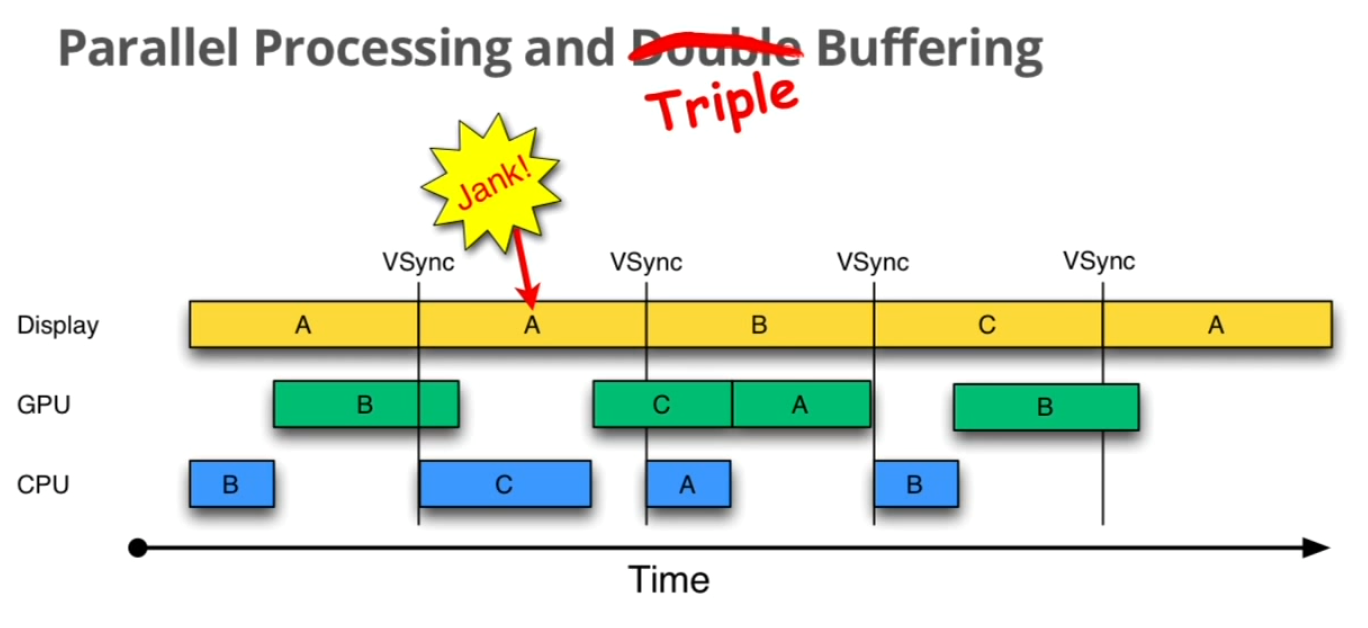
三缓冲作用:
简单的说在2个缓存区被GPU和display占据的时候,开辟一个缓冲区给CPU用,一般来说都是用双缓冲,需要的时候会开启3缓冲,三缓冲的好处就是使得动画更为流程,但是会导致lag,从用户体验来说,就是点击下去到呈现效果会有延迟。所以默认不开三缓冲,只有在需要的时候自动开启
一句话总结三缓冲有效利用了等待vysnc的时间,减少了jank,但是带来了lag
vsync请求与接收
vsync请求
vsync信号如何产生的可以参考http://shangjin615.iteye.com/blog/1775684,SurfaceFlinger进程收到Vsync,转发到有画图请求的客户App,所以说对一个app来说,onVsync并不是16ms来一次的,得有需求才会来。如果一个应用没有请求VSyn事件,surfaceflinger不会给这个应用发VSync事件,那么应用的画图代码永远也不会调用。所以应用必须向surfaceflinger请求VSync。
应用如何请求vsync呢?
当应用需要同步信号的时候,最终会调用到scheduleVsync函数,里面调用到了nativeScheduleVsync函数。
举个例子,invalidate或requestLayout会调用scheduleTraversals,scheduleTraversals -》scheduleVsync
过程是 scheduleTraversals调用 mChoreographer.postCallback(
Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null);
然后调用postCallbackDelayedInternal-》scheduleFrameLocked-》scheduleVsyncLocked-》mDisplayEventReceiver.scheduleVsync();
vsync接收
SurfaceFlinger进程收到vsync信号后,转发给请求过的应用,应用的socket接收到vsync,调用DisplayEventReceiver#dispatchVsync-》FrameDisplayEventReceiver#onVsync-》run-》Choreographer#doFrame-》doCallbacks(Choreographer.CALLBACK_TRAVERSAL, frameTimeNanos)-》
这里各种time














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









