







金融信贷开发评分卡时,通常会准备好特征中间层供评分卡开发筛选使用。
评分卡的特征选择余地越大,后期越是有可能开发出性能更高的评分卡。但特征变量的选择在此时就成为第一个问题,如何初步筛选出合适的变量?
基于经验,我认为第一步的筛选只需要剔除那些极大概率不会被模型选中的变量即可,主要是缺失率和众数占比。如果缺失率超过一定阈值,基于有效信息考虑,该变量极大可能不会被采用。众数占比超过一定阈值,则说明该变量很可能没有区分度。
以下代码部分参考《机器学习算法竞赛实战》,用最简洁的代码实现特征最初步的筛选。
#导入数据
import pandas as pd
import numpy as np
#数据来自Kaggle
df = pd.read_csv("../input/credit-card-customers/BankChurners.csv")
df.head(5)
# 0.参数设置:设置NULL默认的值
Miss_Threhold=95
Mode_Threhold=95
Null_Number=99999999
# 1.EDA功能:基础的统计描述,缺失数值占比,众数占比,初步(根据IV等)筛选变量
all_feature=list(df.columns)
# df.describe(include=['O'])
# df.describe()
stats=[]
for col in all_feature:
stats.append((col,
df[col].nunique(),
round(df[df[col]==Null_Number][col].count()*100/len(df),3),
round(df[col].value_counts(normalize=True,dropna=False).values[0]*100,3),
df[col].dtype
))
stat_df=pd.DataFrame(stats,columns=['VarName','Var_Counts','Missing_Rate','Large_Value_Rate','Var_Type'])
stat_df['Miss_Too_Much']=stat_df['Missing_Rate'].apply(lambda x:1 if x>=Miss_Threhold else 0)
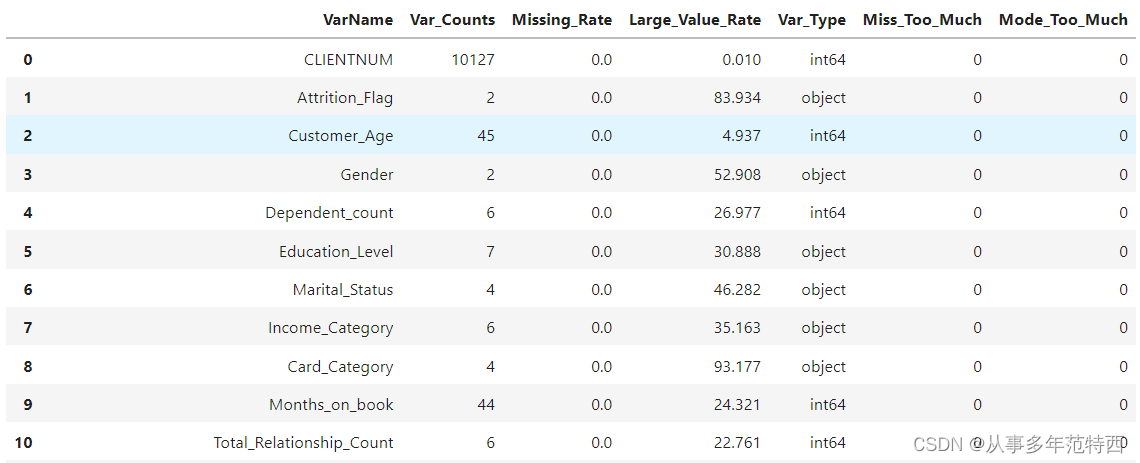
stat_df['Mode_Too_Much']=stat_df['Large_Value_Rate'].apply(lambda x:1 if x>=Mode_Threhold else 0)最后导出的结果如下:














 379
379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









