







特征的好坏直接影响到机器学习的效果,机器学习模型本身只能尽可能接近本身的上限,而特征工程决定了机器学习的上限。所以特征工程尤其重要。特征构造之后就要进行特征筛选。
1、单特征分析
我们评价一个特征的好坏,一般从以下几个角度去衡量:
覆盖度
覆盖度 = 有数据的用户数/全体用户数。而覆盖度可以衍生两个指标:缺失率,零值率。
缺失率:一般就是指在全体有标签用户上的覆盖度
零值率:在数据缺失时会补零,所以需要统计零值率
业务越来越成熟,覆盖度可能会越来愈好,可以通过运营策略提升覆盖度。
区分度
评估一个特征对好坏用户的区分性能的指标。我们可以把单特征当做模型,使用AUC, KS来评估特征区分度。
例如在信贷领域,常用Information Value (IV)来评估单特征的区分度,Information Value刻画了一个特征对好坏用户分布的区分程度。IV越大越好,越小则越差。
I V = ∑ k ( p g o o d k − p b a d k ) l n ( p g o o d k p b a d k ) = ∑ k ( p g o o d k − p b a d k ) W O E k IV = \sum_{k}(p_{good}^k - p_{bad}^k)ln(\frac{p_{good}^{k}}{p_{bad}^{k}}) = \sum_{k}(p_{good}^k - p_{bad}^k)WOE_k IV=k∑(pgoodk−pbadk)ln(pbadkpgoodk)=k∑(pgoodk−pbadk)WOEk
- IV<0.02 区分度小 建模时不用 (xgboost,lightGMB 对IV值要求不高)
- IV [0.02,0.5] 区分度大 可以放到模型里 (IV0.1 考虑是否有未来信息)
- IV > 0.5 单独取出作为一条规则使用,不参与模型训练
模型中尽可能使用区分度相对较弱的特征,将多个弱特征组合,得到评分卡模型。当连续变量的IV值计算,先离散化再求IV,跟分箱结果关联很大(一般分3-5箱)。
相对性
对线性回归模型,有一条基本假设是自变量x1,x2,…,xp之间不存在严格的线性关系。当我们需要对相关系数较大的特征进行筛选,只保留其中对标签区分贡献度最大的特征,即保留IV较大的。
相关系数:
- Pearson相关系数
- Spearman相关系数
- Kendall相关系数
考察两个变量的相关关系,首先得清楚两个变量都是什么类型的。
- 连续型数值变量,如果数据具有正态性,此时首选Pearson相关系数,如果数据不服从正态分布,此时可选择Spearman和Kendall系数。
- 两个有序分类变量相关关系,可以使用Spearman相关系数。
- 一个分类变量和一个连续数值变量,可以使用kendall相关系数。
稳定性
通过计算不同时间段内同一类用户特征的分布的差异来评估。常用的特征稳定性的度量有Population Stability Index (PSI)
PSI公式:
P S I = ∑ k ( p a c t u a l k − p e x p e c t k ) l n ( p a c t u a l k p e x p e c t k ) PSI = \sum_{k}(p_{actual}^k - p_{expect}^k)ln(\frac{p_{actual}^{k}}{p_{expect}^{k}}) PSI=k∑(pactualk−pexpectk)ln(pexpectkpactualk)
PSI和IV的公式一样的,但两个衡量的特征不一样。IV是评估好坏用户分布差异的度量。PSI是评估两个时间段特征分布差异的度量。
2、多特征筛选
我们构建了大量的特征时,就要对特征进行筛选,选择合适的特征再放入模型学习,因为过多的特征会导致机器学习所需要的样本增多,机器学习变慢,同时也会让特征的存储和计算成本变高。
常见的特征筛选方法有:星座特征、Boruta、方差膨胀系数、后向筛选、L1惩罚项、业务逻辑。
星座特征
人物信息中的星座特征是最没用的,我们将区分度低于星座的特征可以认为是无用特征
把所有特征加上星座特征一起做模型训练,拿到特征的重要度排序,多次训练的重要度排序都低于星座的特征可以剔除。
Boruta
使用特征的重要性来提取。原理如下:
- 将每个真实特征R随机打乱顺序,得到阴影矩阵S,将两者拼接,构成特征矩阵N。
- 将矩阵N作为输入,训练模型,其中模型需要采用能够输出特征的模型,例如RandomForest、lightgbm、xgboost,我们可以得到真实特征和阴影特征的feature importances。
- 从阴影特征的feature importances中取最大值Smax,则真实特征中的feature importances小于Smax的都被认为是不重要特征。
- 删除不重要特征,重复1-3步骤,直到满足条件。
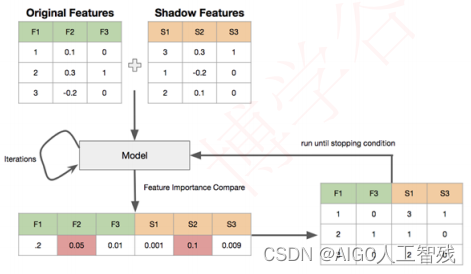
Boruta有专门的包,我们直接安装包来使用
pip install Boruta
方差膨胀系数VIF
一个特征可以由其他特征线性组合而成,则特征不会为模型提供额外的信息,我们可以去掉该特征。VIF公式如下:
V
I
F
=
1
1
−
R
2
VIF = \frac{1}{1-R^2}
VIF=1−R21
VIF越大拟合效果越好,则共线性越强,该特征可以删除。
递归特征消除RFE
使用排除法训练模型,将模型性能下降最少的特征删除掉,反复上述训练直到满足特征的数量。
sklearn.feature_selection.RFE
L1范式
使用L1范式作为惩罚项的线性模型会得到稀疏解:即大部分的特征的系数对应为0。所以我们希望减少特征维度时,可以通过feature_selection.SelectFromModel来选择不为0的系数。
sklearn.feature_selection.SelectFromModel
3、 内部特征监控
- 前端监控:监控特征的稳定性,一般情况下,业务越来越稳定,缺失率是逐渐降低的。如果缺失率突然变动,需要注意。
- 后端监控:特征区分度,主要监控AUC\KS,IV的波动跟分箱有关,所以波动会大一些。
- 分箱风险:注意每个特征的风险趋势单调性。
4、外部特征评估
- 如何评估外部数据?
外部数据一般用覆盖度、区分度和稳定性来评估,跟单特征分析一样。外部数据的覆盖率=交集用户数/内部目标客群。 - 需要对内部用户调用外部数据吗?
当外部数据免费时,全部调用,否则在必要的时候调用。并且在计算外部数据覆盖率时,应先确定适合第三方数据的客群。一般在缺少内部数据并且第三方数据能够提升区分度时,这个时候第三方数据才有用。 - 如何避免内部数据泄露?
对交出去的数据,先进行Hash处理再匹配。

- 如何避免第三方公司对结果进行美化?
分为两种情况:
一种是自己调用第三方接口,这时计算覆盖率即可;
另一种是把样本交给外部公司,这种情况要增加标记假样本,这样对方只能匹配结果无法得知覆盖率,而自己计算覆盖率时,可以排除假样本,计算真实覆盖率,如果覆盖率有变动,则结果有问题。 - 黑名单型外部数据
使用混淆矩阵评估区分度
| 外部命中 | 外部未命中 | |
|---|---|---|
| 内部坏 | TP | FN |
| 内部好 | FP | TN |
Precision = TP/(TP+FP)
Recall = TP/(TP+FN)
F1 = 2×Precision×Recall/(Precision+Recall)
Precision:外部尽可能命中内部的坏客户
Recall:内部坏客户尽可能与外部名单命中
















 227
227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











