






 Nvidia发布的ChatwithRTX是一款应用,利用本地RTXGPU处理大语言模型,提供快速、安全的AI交互。文章详细介绍了其优势、核心技术、安装步骤,以及如何添加中文模型和离线使用。ChatwithRTX展示了AI在个性化和数据安全方面的潜力,预示着AI交互方式的革新。
Nvidia发布的ChatwithRTX是一款应用,利用本地RTXGPU处理大语言模型,提供快速、安全的AI交互。文章详细介绍了其优势、核心技术、安装步骤,以及如何添加中文模型和离线使用。ChatwithRTX展示了AI在个性化和数据安全方面的潜力,预示着AI交互方式的革新。

一 、 Chat with RTX概述
Chat with RTX是Nvidia发布的一款Demo应用程序,以此可以个性化 GPT 大语言模型 (LLM),使其连接到您自己的内容(文档、笔记、视频或其他数据),快速获得上下文相关答案。由于 Chat with RTX 全部在 Windows RTX PC 或工作站上本地运行,因此可以获得快速、安全的结果。
1. Chat with RTX 的优势
本地处理:隐私和性能的飞跃
Chat with RTX 的最重要优势之一是其本地处理功能。它利用 Nvidia RTX GPU 的强大计算能力,直接在用户的 PC 上运行,在 AI 交互中提供前所未有的速度和响应能力。这种本地执行模型可确保敏感数据保留在用户设备的范围内,从而提供云上人工智能服务无法比拟的隐私和数据安全级别。
高级内容分析:深入内部
Chat with RTX 包括.txt、.pdf、.doc/.docx 和 .xml 在内的多种文件格式以及 YouTube 视频。它采用复杂的人工智能模型来消化大量信息,提取相关见解并以极高的准确性总结复杂的数据。 Chat with RTX 提供的深度分析超出了单纯的关键字匹配;它理解上下文,提取相关信息,并以连贯、简洁的方式呈现它。
2. Chat with RTX 的核心技术
Chat with RTX 功能的核心基于 Mistral / Llama 2 等先进的 AI 模型,借助检索增强生成 (RAG)、NVIDIA TensorRT-LLM 软件及 NVIDIA RTX 加速技术,使模型与 Nvidia Tensor 核心的计算能力相结合,可以促进快速、准确的数据查询,将生成式 AI 功能引入由NVIDIA 赋能的本地 Windows PC。 硬件和软件之间的这种协同不仅体现了NVIDIA 致力于突破人工智能技术界限的承诺,而且还让我们得以一睹个人计算的未来,其中人工智能在提高生产力和实现新形式的创造力方面发挥着核心作用。
二 、 Chat with RTX安装
1. 软件安装及注意事项
根据官网软件运行系统需求:

本人电脑是GPU是RTX 4070Ti 12G,满足需求,可以体验!从官网Build a Custom LLM with ChatRTX ![]() https://www.nvidia.com/en-us/ai-on-rtx/chatrtx/下载安装包NVIDIA_ChatWithRTX_Demo.zip,解压得到下图所示文件列表:
https://www.nvidia.com/en-us/ai-on-rtx/chatrtx/下载安装包NVIDIA_ChatWithRTX_Demo.zip,解压得到下图所示文件列表:
点击setup安装:
首先出现Software license agreement 页

然后是安装选项页(下面的图和自己实际的不完全匹配,当时不知道啥原因,Llama2 13B INT4的选项是灰的,装不了,想想反正还有Mistral 7B INT4可以用,就先继续了。当然后面自己进行了定制和补救)


在安装前,根据网友们的提示,先前做了一些准备:
1. 在安装过程中需要联网下载miniconda、python及相应的依赖包,以及一些模型包,要确保网络能访问conda、github和Python仓库。
2. 使用默认安装路径。如果选择将应用程序安装在默认安装位置之外的其他文件夹,请确保文件夹路径或文件夹名称中没有空格。
3. 关闭杀毒软件,防止其干扰安装过程(网友总结)。
整个安装比较费时间,当你看到下述页面时,表示已经成功安装好了。

2. 离线使用
虽然模型的推理是利用TensorRT-LLM在本地进行,但是在使用中还是需要链接一下互联网(甚至需要科学上网)。接下来我们就介绍下如何完全离线运行.
1. 修改user_interface.py文件
打开你的安装目录C:\Users\youname\AppData\Local\NVIDIA\ChatWithRTX,在C:\Users\youname\AppData\Local\NVIDIA\ChatWithRTX\RAG\trt-llm-rag-windows-main\ui里面有一个user_interface.py文件,打开它并找到254行左右的位置,在interface.launch函数里加上share=True, 如下图所示:

2. 配置UAE-Large-V1
启动Chat With RTX时,需要联网的原因可能是它需要从HF上下载一个文件,我们打开:C:\Users\youname\AppData\Local\NVIDIA\ChatWithRTX\RAG\trt-llm-rag-windows-main\config\app_config.json,如下图, 我们可以看到:

它会去到HF网站中下载“WhereIsAI/UAE-Large-V1"这个embedding模型,所以我们可以直接从HF下载(地址:https://huggingface.co/WhereIsAI/UAE-Large-V1/tree/main), 然后修改这个路径就好。当然,对于无法访问HF的朋友,可以搜索百度云盘地址。
当然,如果你以及正常联网使用了一次,那么就可以将上述UAE-Large-V1地址改成本地缓存路径(我这里就使用了缓存的UAE-Large-V1模型):

三、中文大语言模型配置和Llama2补救
由于在Chat With RTX安装过程中没有成功安装Llama2模型,并且内置的两个语言模型对中文支持不是很好,因此需要增加中文模型,并将Llama2重新配置。
1. 安装chatglm3_6b_32k
要增加一个模型,那么我们就需要TensorRT-LLM,TensorRT-LLM是专门为大语言模型推理而设计的,这也是能让那些大语言模型在我们这些游戏显卡上运行的一个重要原因。这个工具能够加速AI模型的推理速度,让我们的模型运行起来更快,更节省内存。
幸运的是,Chat With RTX已经替我们事先安装好了一个TensorRT-LLM(版本号0.7.0)。
接下来我们详细说明如何安装大语言模型(必须是TensorRT-LLM支持的):
0)下载chatglm3_6b_32k模型包;
1)从启动菜单栏,点击Miniconda3 Power Shell,进入PS命令行窗口;
2)激活RAG环境: 这一步是激活我们Chat With RTX的环境,意味着我们接下来的操作和我们运行Chat With RTX处于同一情形,避免出现因为某些包的版本不匹配而造成的错误;
conda activate C:\Users\Yourname\AppData\Local\NVIDIA\ChatWithRTX\env_nvd_rag3)进入TensorRT-LLM的chatglm目录:
cd C:\Users\Yourname\AppData\Local\NVIDIA\ChatWithRTX\TensorRT-LLM\TensorRT-LLM-0.7.0\examples\chatglm\
4)构建TensorRT-LLM模型,
python build.py -m chatglm3_6b_32k --model_dir c:\\2024\\chatglm3_6b_32k --output_dir trt_engines/chatglm3_6b-32k/fp16/1-gpu --use_weight_only --weight_only_precision int4 --max_input_len 3900不幸的是,在biuld过程中报错,如下图:
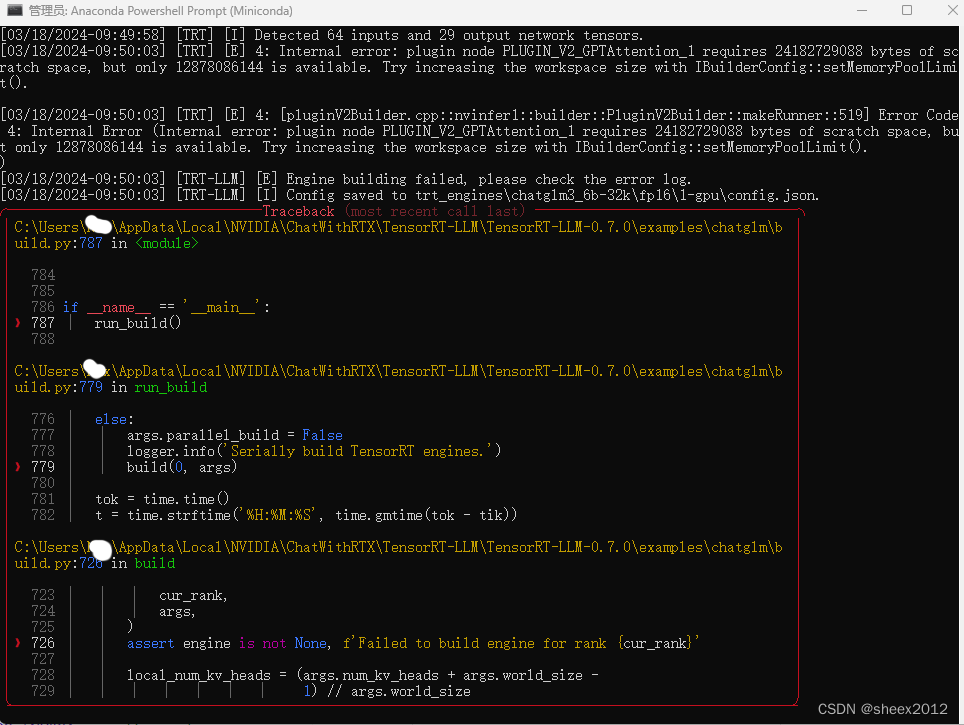
[E] 4: Internal error: plugin node PLUGIN_V2_GPTAttention_1 requires 24182729088 bytes of scratch space, but only 12878086144 is available. Try increasing the workspace size with IBuilderConfig::setMemoryPoolLimit().
从字面上理解是内存(显存)不够造成的,查找相关文献,给出了下述方法:
IBuilderConfig config = new IBuilderConfig();
config.setMemoryPoolLimit(1024);但在build.py中如何应用这个限制,没有方法。
后来,在TensoRT-LLM官方中的Failed to Build Llama-7b Engine Because of Insufficient Memory找到了解决方案,增加选项--enable_context_fmha,可以 It can save lots of memory,实践发现有效!
5)构建成功后这时候, 我们就能在trt_engines/chatglm3_6b-32k/fp16/1-gpu目录下看到生成好的引擎:
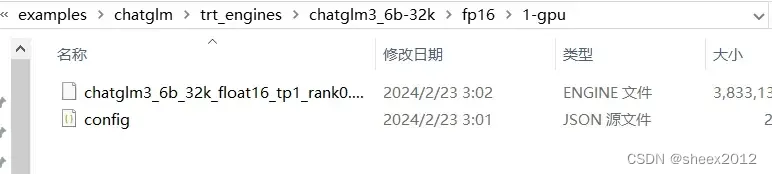
接下来我们打开文件夹, 找到C:\Users\Yourname\AppData\Local\NVIDIA\ChatWithRTX\RAG\trt-llm-rag-windows-main\model目录,创建一个新的文件夹:chatglm
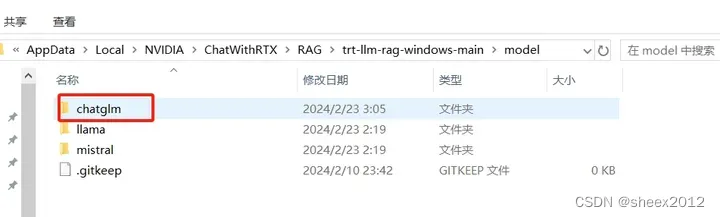
然后在chatglm里面分别创建chatglm_engine和chatglm_hf文件夹:

把上面生成好的引擎和配置文件复制到chatglm_engine文件夹中:

把我们下载的c:\2024\chatglm3_6b_32k文件夹中的config.json, tokenization_chatglm.py, tokenizer.model和tokenizer_config.json文件放到chatglm_hf文件夹中:

打开C:\Users\Yourname\AppData\Local\NVIDIA\ChatWithRTX\RAG\trt-llm-rag-windows-main\config文件夹中的config.json文件, 将我们新创建的chatglm模型的信息放在里面,如下图:

至此,chatglm3_6b_32k已成功接入。
2. Llama2补救配置
Chat With RTX在安装过程中,会对显卡硬件进行检测,在缺省情况下,如果显存小于15G时,将不安装Llma2。
一种方法是在安装前修改安装包RAG文件夹中的llama13b.nvi里面的 <string name="MinSupportedVRAMSize" value="15"/> 数值修改。将"15"这个数值,修改成本机显卡的内存值,例如12(当然如果显存小于8G,就没有必要改了,装了叶不能用)。
另一种方法,则是在安装后构建和配置Llama2,这个方法和前述的chatglm3_6b_32k构建和配置方法是一样的。
类似地,在2)步骤中进入llama目录,
cd C:\Users\Yourname\AppData\Local\NVIDIA\ChatWithRTX\TensorRT-LLM\TensorRT-LLM-0.7.0\examples\llama然后执行下述命令构建
python build.py --model_dir C:\2024\Software\NVIDIA_ChatWithRTX_Demo\llama\llama13_hf --quant_ckpt_path C:\2024\Software\NVIDIA_ChatWithRTX_Demo\llama\llama13_int4_awq_weights\llama_tp1_rank0.npz --dtype float16 --remove_input_padding --use_gpt_attention_plugin float16 --enable_context_fmha --use_gemm_plugin float16 --use_weight_only --weight_only_precision int4_awq --per_group --output_dir C:\2024\llama13_int4_engine --world_size 1 --tp_size 1 --parallel_build --max_input_len 3900 --max_batch_size 1 --max_output_len 1024构建完成后,将相应模型拷贝到的新建的llama目录中,并config.json文件。
3. 安装通义千问
流程与chatglm3_6b_32k构建和配置方法是一样,但新增下述要求,
首先要安装transformers_stream_generator和einops这两个包:
pip install transformers_stream_generator einops -i https://pypi.tuna.tsinghua.edu.cn/simple然后执行下述命令构建:
python build.py --hf_model_dir C:\2024\Qwen_7B_Chat --dtype float16 --remove_input_padding --use_gpt_attention_plugin float16 --use_gemm_plugin float16 --use_weight_only --weight_only_precision int4 --output_dir ./Qwen/7B/trt_engines/int4_weight_only/1-gpu/ --max_input_len 2048最后,复制模型目录D:\models\Qwen\Qwen-7B-Chat 的 config.json, tokenization_qwen.py,generation_config.json和tokenizer_config.json文件放到 E:\LLM\NVIDIA_ChatWithRTX\RAG\trt-llm-rag-windows-main\model\qwen\qwen_hf 文件夹中:
最后需要注意的是,qwen.tiktoken 这个不能缺。
从测试情况来看,似乎Qwen引擎没有安装成功,一直没有输出。
四、不同语言模型测试
笔者以“模型抖动是什么原因”为题,分别使用上述语言模型,看看结果如何:
首先是Mistral,中文问题,英文回答(没有找到相关线索),显存占用7G左右。


其次,是Llama2,中文问题,英文回答(没有找到相关线索),显存占用12G左右(几乎满了)。
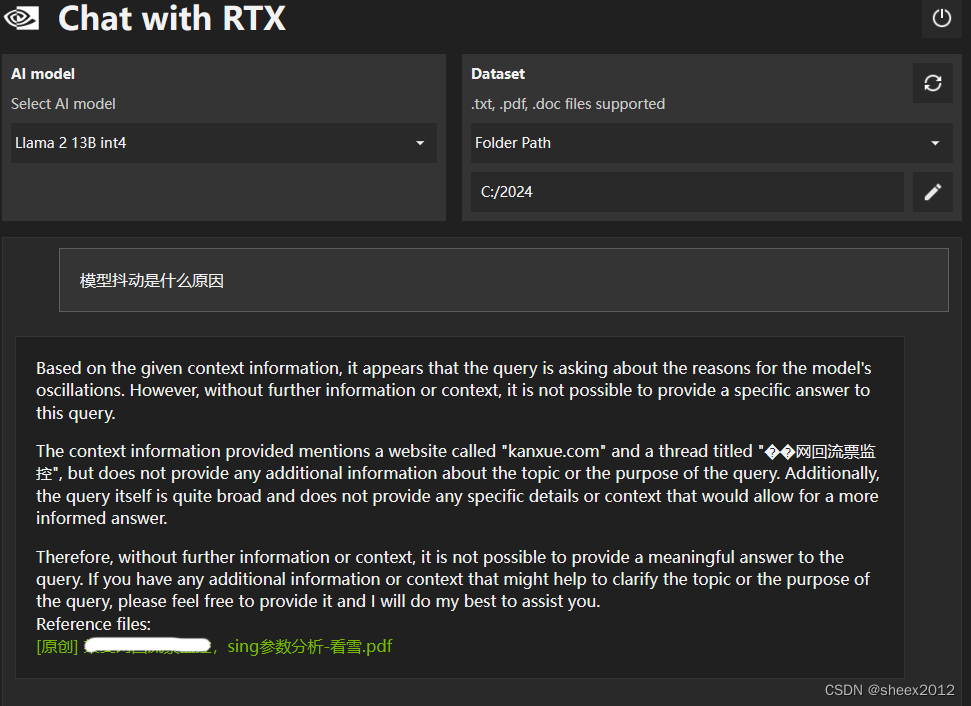
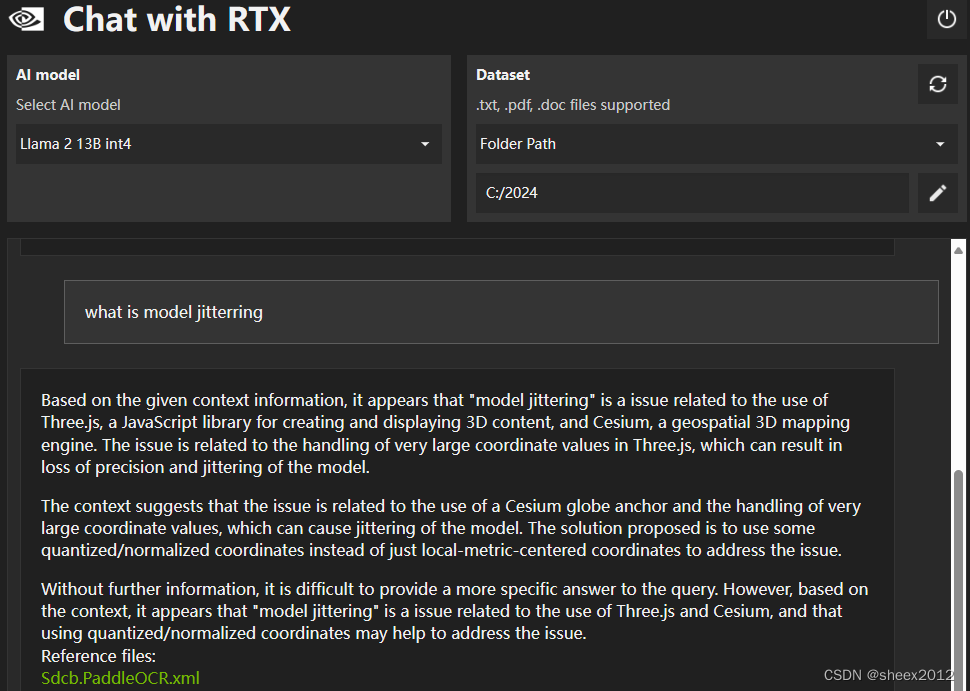
用英文问,回答的稍微好一点:
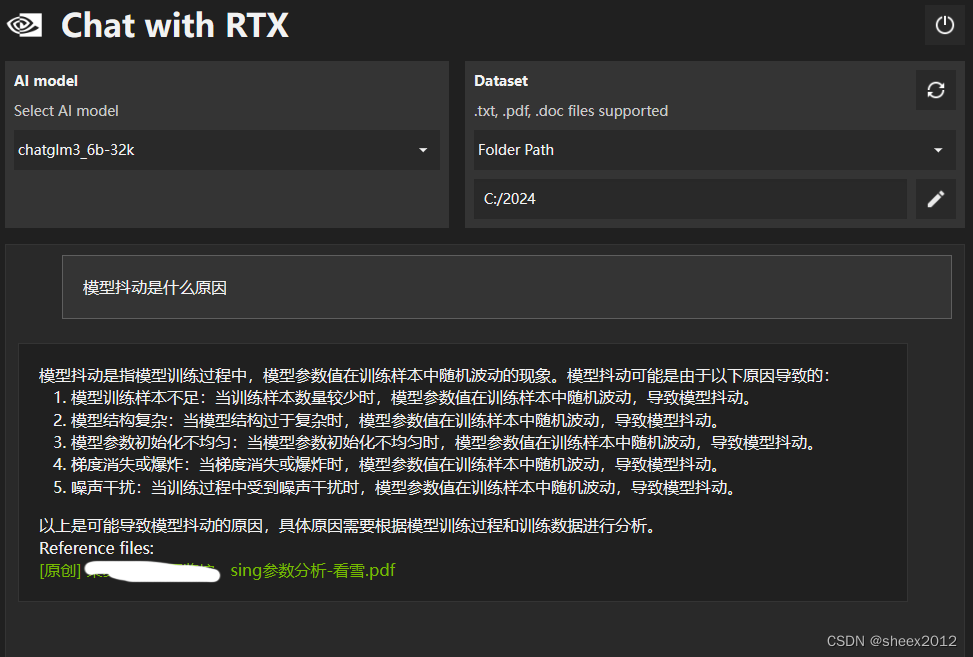
第三,是Chatglm,中文问题,中文回答,看似不错,显存占用9G左右。
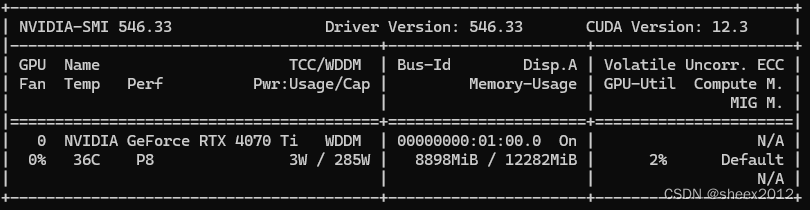
五、体验小结
一是预装的大模型Mistral和Llama2对中文语境支持比较差,可以增加优秀的中文模型来多个选择;二是文档的读入速度比较慢,需要2分钟一篇的样子,如果没读完,程序禁止用户使用;三是应用程序无法记住上下文。这意味着后续问题的回答不会基于先前问题的上下文。例如,如果您先前问过“小编长得很美么?”,然后问“小编年纪多大?”,应用程序将不知道您在小编的信息;四是响应中的源文件归属不一定正确。这将在以后的版本中改进。
Nvidia Chat with RTX 向我们展示了个人 AI 的潜力。未来个人 AI 将成为我们数字生活不可或缺的一部分。Chat with RTX 标志着 AI 向更个性化、高效和安全的 AI 交互方式转变,赋予用户释放数据全部潜力的能力。当我们站在这个新时代的起点时,这种技术的意义深远,它不仅承诺提高我们对信息的理解和使用,还将激发我们在数字领域解决问题和抓住机遇方式上的创新。随着 Chat with RTX 的能力和应用的不断发展,我们将进入一个崭新的 AI 交互前沿,在这里个人数据分析变得更加容易访问、富有洞察力和安全。Chat with RTX 的旅程才刚刚开始,但它改革我们数字生活的潜力是不可否认的,标志着人工智能持续进化中的一个重要里程碑。
参考文献:
https://zhuanlan.zhihu.com/p/683494847
https://blog.csdn.net/richardjung/article/details/136179448
https://zhuanlan.zhihu.com/p/683556790















 1555
1555











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









