






1. 简介
ChatRTX 是Nvidia 发布的一款演示应用程序,它基于大型语言模型 (LLM),借助检索增强生成 (RAG)技术,个性化连接本机/私域或外部内容(文档、笔记、照片或其他数据),利用TensorRT-LLM 和 RTX 加速,使模型与 Nvidia Tensor 核心的计算能力相结合,实现查询自定义聊天机器人以快速获得与上下文相关的答案。ChatRTX 在 Windows RTX PC 或工作站上本地运行,因此可以获得快速、安全的结果。ChatRTX 支持多种文件格式,包括文本、pdf、doc/docx(带 LLM)和 jpeg、gif 和 png(带 CLIP)。只需将应用程序指向包含文件的文件夹,它就会在几秒钟内将它们加载到库中。
NVIDIA在2月推出了Chat with RTX的技术演示应用,可给用户体验本地的聊天机器人,它用到了TensorRT -LLM和NVIDIA RTX加速技术,也是NVIDIA展示技术的一个方式。5月1日,NVIDIA在官方博客(Say It Again: ChatRTX Adds New AI Models, Features in Latest Update, https://blogs.nvidia.com/blog/ai-decoded-chatrtx-update/)中隆重推出新版本的聊天机器人,并正式改名为ChatRTX。

ChatRTX最新版本增加了对其他 LLM 的支持,包括 Gemma,这是由 Google 训练的 LLM,根据用于创建公司 Gemini 模型的相同研究和技术开发的,专为负责任的 AI 开发而构建。ChatRTX 现在还支持 ChatGLM3,这是一个基于通用语言模型框架的开放双语(英语和中文)LLM。借助OpenAI的CLIP模型支持,用户可以通过单词、术语和短语与本地设备上的照片和图像进行交互,可根据你给出的信息搜索本地指定目录里面的图片。ChatRTX还允许人们使用语音与他们的数据聊天。基于 Whisper,一种使用 AI 处理口语的自动语音识别系统,用户可以向应用程序发送语音查询,ChatRTX 将提供文本响应。

废话不多说,那就开始体验吧。
2. 安装
从官方网站(https://www.nvidia.com/en-us/ai-on-rtx/chatrtx/)得知,ChatRTX的运行软硬件要求与原先的Chat with RTX一致,对个人电脑来说,需要RTX 30或40系列显卡(显存不小于8G),笔者是12G的4070Ti 卡,满足运行需求。从官方页面下载压缩包ChatRTX_Installer _Mistral_4_24_Final.zip(从压缩包的命名来看,貌似是4月24日最终版),压缩包大小“只有”11.6G,比上个版本35G瘦身了不少。
解开压缩包,双击安装文件setup.exe,软件在进行相关软硬件环境检测后,弹出软件协议对话框(可以看到现有ChatRTX版本号为0.3),选择“同意并继续(AGREE AND CONTINUE)”:
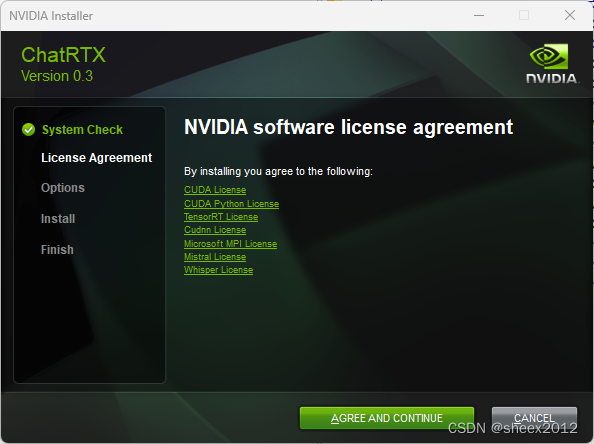
接下来是组件安装选项页面,在笔者的主机上,Whisper是可选项,ChatRTX和Mistral是必选项(这符合安装压缩包的命名),点击"下一步(NEXT)":
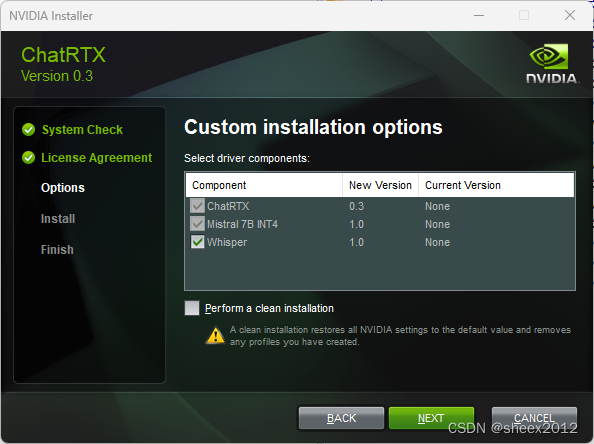
与原先的Chat with RTX相比,ChatRTX多了一个安装位置选项,最好还是用默认的(安装目录必须全英文,无空格)。
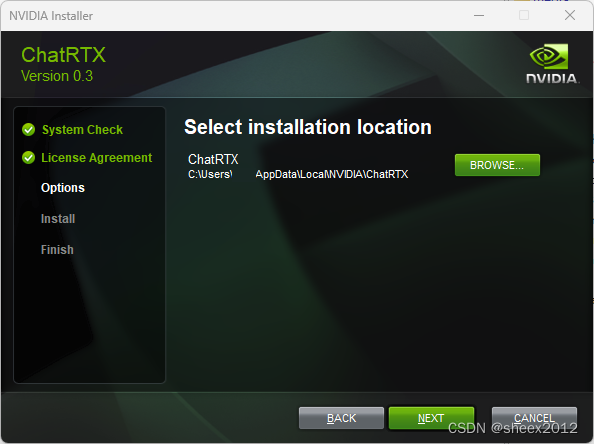
安装页面中记录了安装了哪些组件,我们可以发现,除了选择的Mistral,Whisper之外,ChatRTX还需先安装moniconda环境、python及依赖环境等。

当出现下述页面时,表明ChatRTX已经成功安装完毕了。安装完成之后,启动 ChatRTX,会出现一个的 命令行窗口 框,然后自动打开一个网页。

在ChatRTX页面中,我们发现CLIP和ChatGLM 6B不可以直接使用,而是多了个“Add new models”的选项,需要下载和安装,我们选择"CLIP",勾选“License”,首先下载CLIP模型。

命令行窗口显示,CLIP模型是从huggingface下载的(所以需要科学上网)。

模型下载完成后,再点击“安装”,页面中会有下述的提示信息,安装完成后,就可以使用了。类似地,我们还需要网页端,安装ChatGLM 6B模型。
3. 语言模型增配
笔者显卡有12G内存,根据一般规律,可以正常运行6B以内的大语言模型,因而,缺省安装了Mistral 7B int4和ChatGLM3 6B int4两个模型。根据笔者在上一个版本中的使用经验(Chat With RTX安装及中文大语言模型配置与使用体验),应该还可以配置参数更大的模型。
我们从软件安装目录的配置文件夹C:\Users\yourname\AppData\Local\ NVIDIA\ ChatRTX \RAG \trt-llm-rag-windows-ChatRTX_0.3\config中,有一个config.json文件,里面记录了支持的语言模型,其中含有Gemma 7B和Llama2 13B模型。这两个模型配置中都有一项"min_gpu_memory: 16",应该这一行限制了这两个模型在本机中的安装使用。
"name": "Gemma 7B int4",
"id": "Gemma_model",
"ngc_model_name": "nvidia/llama/gemma-7b-int4-rtx:1.1",
"is_downloaded_required": true,
"downloaded": true,
"is_installation_required": true,
"setup_finished": true,
"min_gpu_memory": 8,
象以前一样,把这个值改成8,然后重启ChatRTX。
和我们预料中一致,重启后,网页中出现了Gemma 7B和Llama2 13B这两个模型的安装选项。我们把这两个模型分别下载并安装,并在完成后重新启动ChatRTX。

重启后,却发现命令行窗口中出现下述错误,没能正常启动进入网页。
C:\Users\?\AppData\Local\NVIDIA\ChatRTX\RAG\trt-llm-rag-windows-ChatRTX_0.3\ui\user_interface.py:340: GradioUnusedKwargWarning: You have unused kwarg parameters in Blocks, please remove them: {'js': 'C:\\Users\\?\\AppData\\Local\\NVIDIA\\ChatRTX\\RAG\\trt-llm-rag-windows-ChatRTX_0.3\\ui\\www/app.js'}
with gr.Blocks(
C:\Users\?\AppData\Local\NVIDIA\ChatRTX\RAG\trt-llm-rag-windows-ChatRTX_0.3\ui\user_interface.py:617: GradioUnusedKwargWarning: You have unused kwarg parameters in Dropdown, please remove them: {'filterable': False}
model_dropdown = gr.Dropdown(
C:\Users\?\AppData\Local\NVIDIA\ChatRTX\RAG\trt-llm-rag-windows-ChatRTX_0.3\ui\user_interface.py:648: GradioUnusedKwargWarning: You have unused kwarg parameters in Dropdown, please remove them: {'filterable': False}
download_model_dropdown = gr.Dropdown(
C:\Users\?\AppData\Local\NVIDIA\ChatRTX\RAG\trt-llm-rag-windows-ChatRTX_0.3\ui\user_interface.py:761: GradioUnusedKwargWarning: You have unused kwarg parameters in Dropdown, please remove them: {'filterable': False}
dataset_source_dropdown = gr.Dropdown(
C:\Users\?\AppData\Local\NVIDIA\ChatRTX\RAG\trt-llm-rag-windows-ChatRTX_0.3\ui\user_interface.py:770: GradioUnusedKwargWarning: You have unused kwarg parameters in Textbox, please remove them: {'autoscroll': True}
dataset_source_textbox = gr.Textbox(
C:\Users\?\AppData\Local\NVIDIA\ChatRTX\RAG\trt-llm-rag-windows-ChatRTX_0.3\ui\user_interface.py:866: GradioUnusedKwargWarning: You have unused kwarg parameters in Chatbot, please remove them: {'sanitize_html': True}
chatbot_window = gr.Chatbot(
C:\Users\?\AppData\Local\NVIDIA\ChatRTX\RAG\trt-llm-rag-windows-ChatRTX_0.3\ui\user_interface.py:879: GradioUnusedKwargWarning: You have unused kwarg parameters in Audio, please remove them: {'sources': ['upload', 'microphone']}
chat_mic_component = gr.Audio(label="Microphone", sources=["upload", "microphone"], type="filepath", elem_id='microphone', render=isChatWithMicEnabled, visible=False)
Traceback (most recent call last):
File "C:\Users\?\AppData\Local\NVIDIA\ChatRTX\RAG\trt-llm-rag-windows-ChatRTX_0.3\app.py", line 706, in <module>
interface.render()
File "C:\Users\?\AppData\Local\NVIDIA\ChatRTX\RAG\trt-llm-rag-windows-ChatRTX_0.3\ui\user_interface.py", line 420, in render
self._handle_events()
File "C:\Users\?\AppData\Local\NVIDIA\ChatRTX\RAG\trt-llm-rag-windows-ChatRTX_0.3\ui\user_interface.py", line 948, in _handle_events
self._handle_settings_event()
File "C:\Users\?\AppData\Local\NVIDIA\ChatRTX\RAG\trt-llm-rag-windows-ChatRTX_0.3\ui\user_interface.py", line 1253, in _handle_settings_event
self._uninstall_model_dict[key]['delete_button'].click(
TypeError: EventListenerMethod.__call__() got an unexpected keyword argument 'js'从上述提示信息来看,貌似gradio模块没能将配置页面正常加载,那就把gradio模块升级一下试试。进入ChatRTX对应的虚拟环境,然后升级gradio。
conda activate C:\Users\Yourname\AppData\Local\NVIDIA\ChatRTX\env_nvd_rag
pip install gradio --upgrade运气不错,重新启动后,一切OK!
4. 评测
4.1 搜图测试
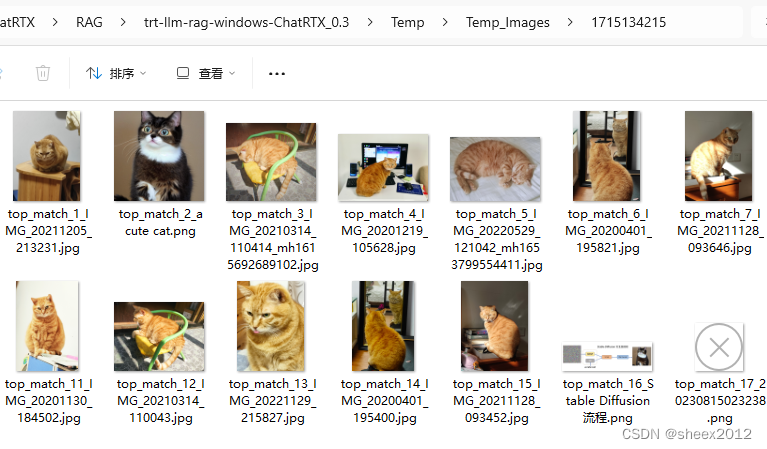
首先来看一下CLIP支持的搜图功能。选择CLIP模型,然后指定图像路径,输入"cat",然后回车,很快地,网页中显示了三张含有猫的图片(应该是置信度最高的三张)。

点击"See all matches",弹出一个文件夹,里面包含所有猫的照片,从结果看还是比较准确的。
接着查询输入"docker",也返回三张docker的图片,结果相当理想。
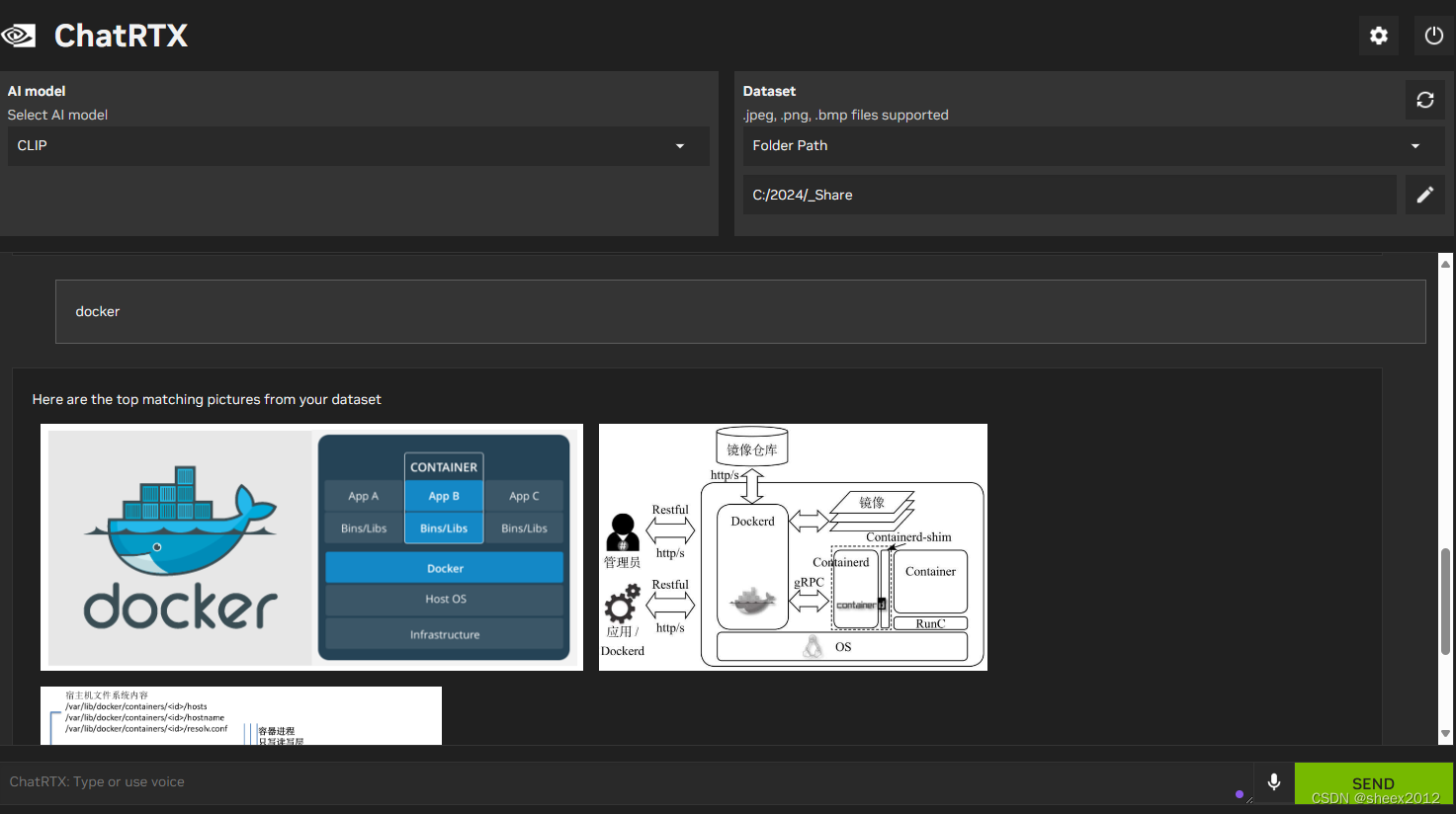
4.2 不同语言模型测试
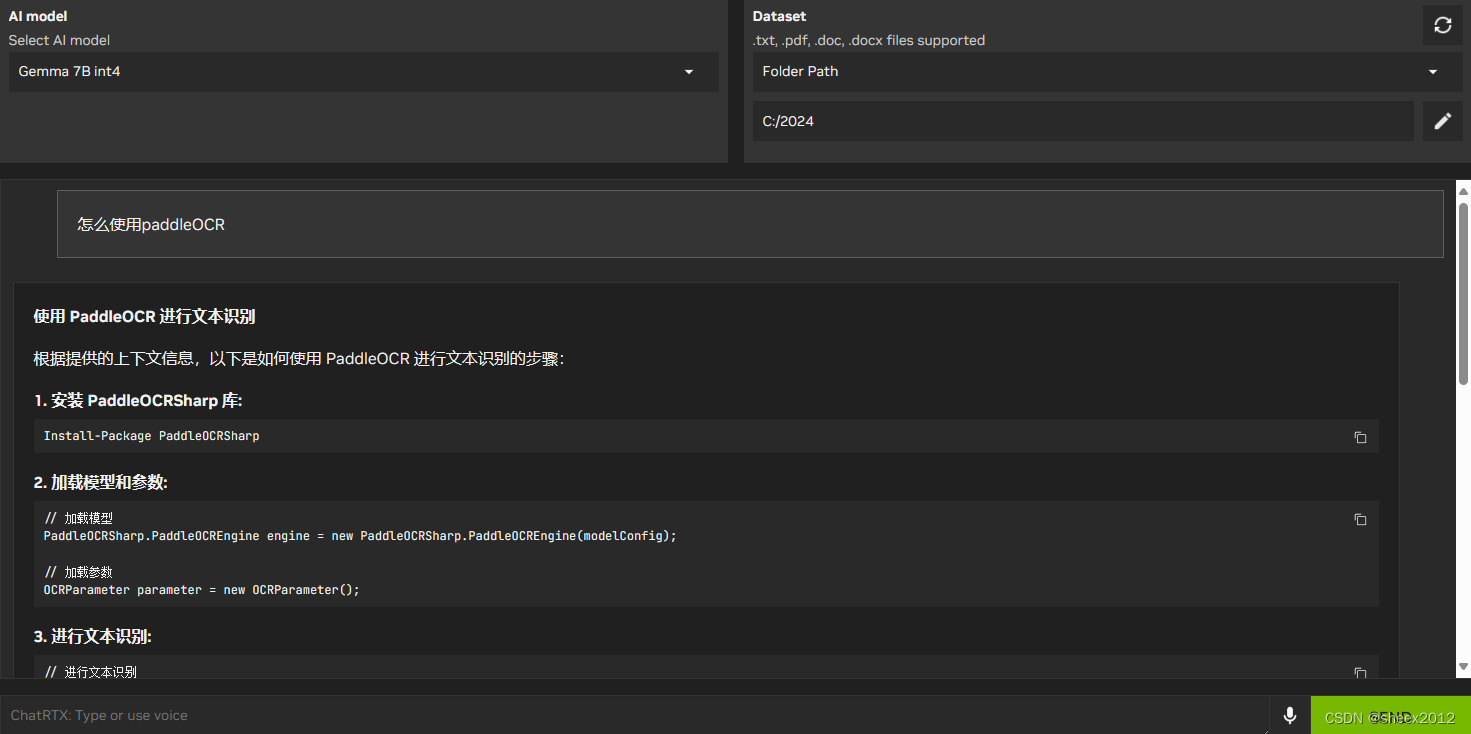
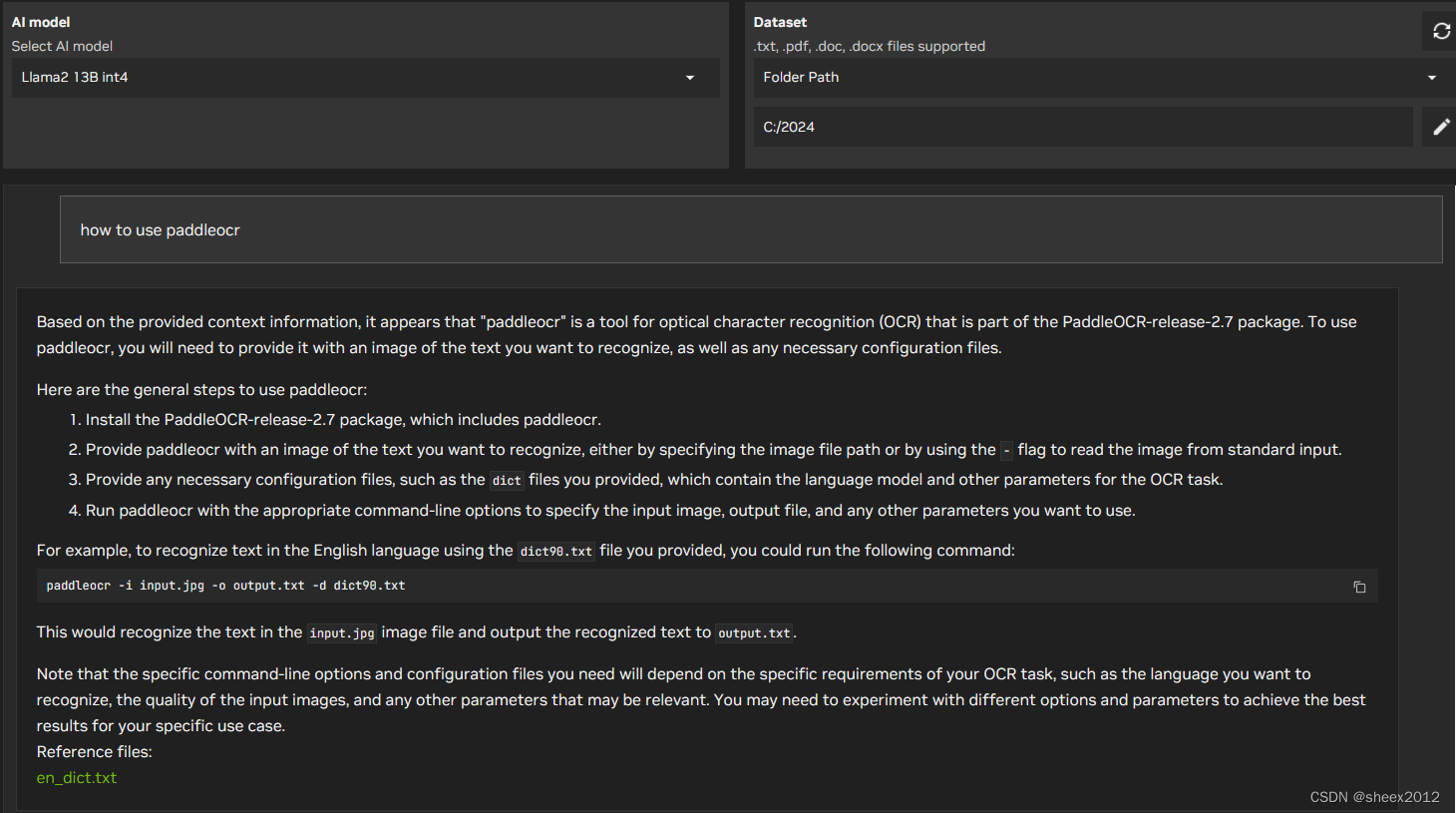
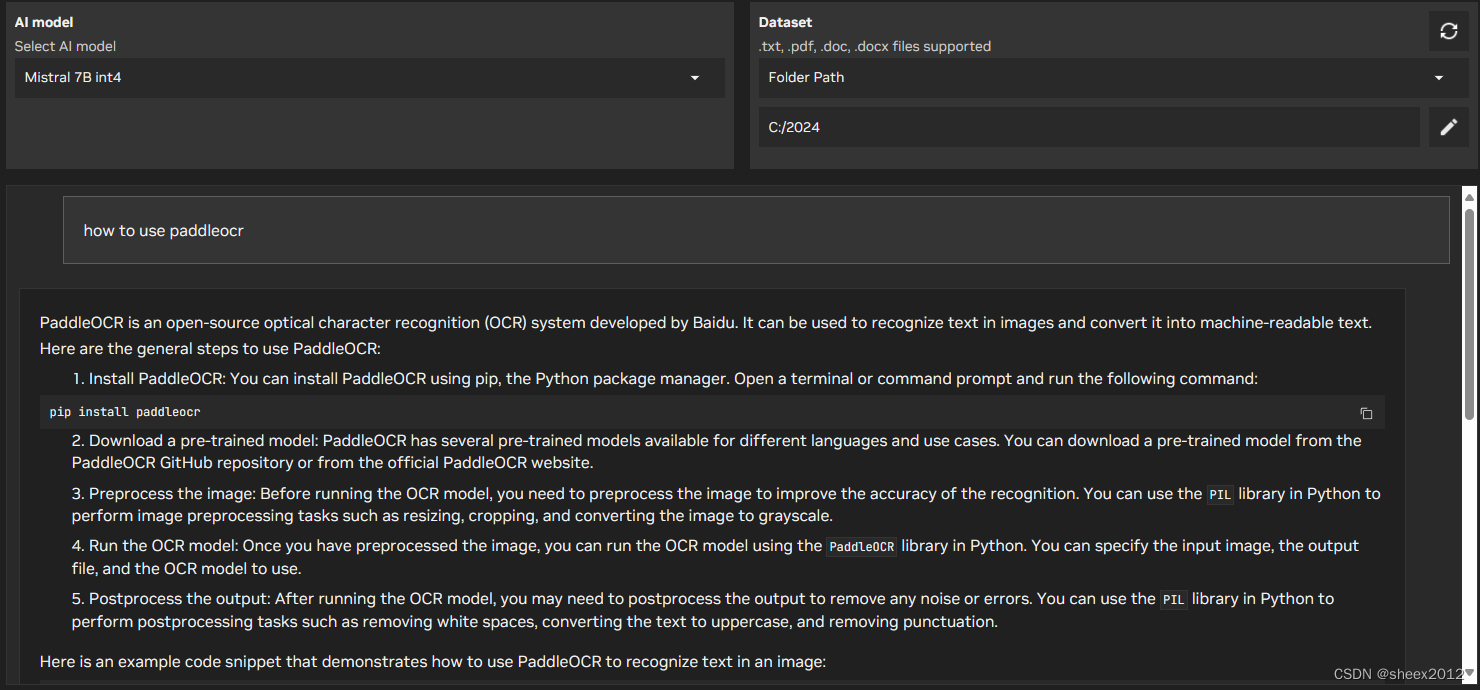
笔者主机文件夹中包含了一些有关PaddleOCR使用的文本文件,这里就分别以“怎么使用PaddleOCR”和"how to use PaddleOCR"两个问题,看看各个模型结果如何。
ChatGLM3 6B查询结果:


Gemma 7B模型查询结果:

LLama2 13B 查询结果:

Mistral 7B 查询结果:

显存占用情况:
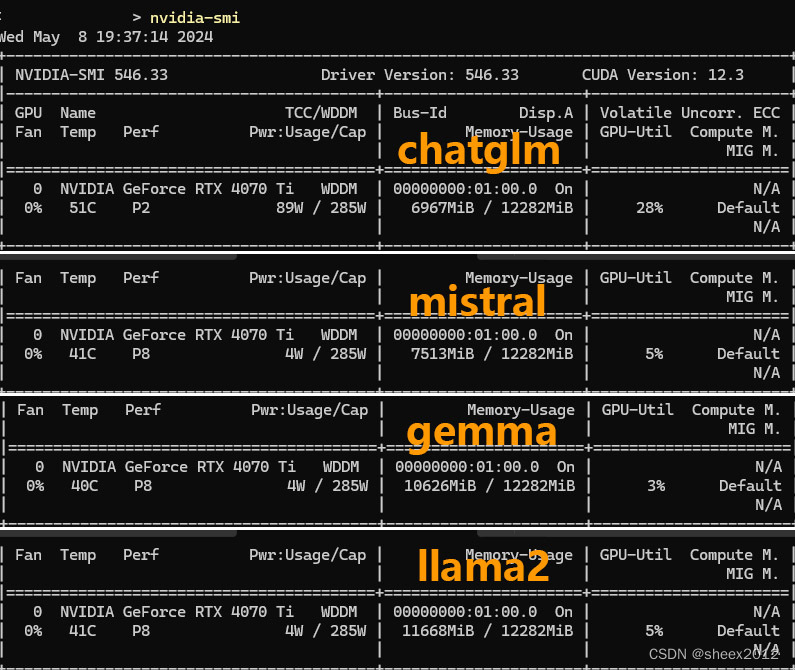
各模型比较简表:
| how to use paddleocr | 如何使用paddleOCR | 显存占用 | |
|---|---|---|---|
| ChatGLM3 6B | 英文回答 内容正确 参考无效 | 中文回答 内容正确 参考有效 | 6.9G |
| Gemma 7B | 英文回答 无内容 参考无效 | 中文回答 内容正确 参考有效 | 10.6G |
| Llama2 13B | 英文回答 内容正确 参考无效 | 英文回答 内容正确 参考有效 | 11.6G |
| Miatral 7B | 英文回答 内容正确 参考无效 | 英文回答 内容正确 参考有效 | 7.5G |
可以看到,采用英文提问时,其列出的参考文件不对(参考文件实际上并没有包含问题内容),但除了Gemma外都回答得基本准确;而使用中文提问时,ChatGLM3和Gemma使用中文回答,特别是Gemma令人感到意外。参考文件在英文提问时不准确,可能是嵌入模型、匹配算法不适合造成的,但不同模型的回答结果不同,一定程度上显示出语言模型与嵌入模型的匹配度。
要构造良好的智能问答系统,需要LLM、嵌入模型、文字分块算法、嵌入匹配算法的精细化调整,还有很多的路要走。
由于笔者主机没有麦克风,所以语言输入功能没有测试。
5. 比较
与2月份发布的Chat with RTX相比,除了官方提及的增加基于CLIP的图像搜索和基于Whiper的语言识别,以及增加内置的中文语言模型外,其用户体验方面的提升也是是很明显的,表现为以下几点:一是增加中文模型(ChatGLM3)的原生内置支持;二是将语言模型放到Nvidia网站中,从而实现模型的高速下载;三是对诸如CLIP等放在HuggingFace中的模型,作为选项安装,并可以实现地址替换,尽量避免国内用户科学上网(真是良心啊);四是语言模型的下载和安装自动化,不需要自己写转换脚本(引擎构建代码放在config.json中)。
从程序本身来看,ChatRTX内置的TensorRT-LLM引擎和语言嵌入模型也有所不同。
| Chat with RTX | ChatRTX | |
|---|---|---|
| TensorRT-LLM | 版本0.7.0 | 版本0.9.0 |
| 嵌入模型 | UAE-Large-V1 / 1024维 | multilingual-e5-base / 768维 |
我们再来看看安装压缩包有什么区别:左边是Chat with RTX版本的,右边是ChatRTX版本的。

可以看到,Chat with RTX版本中内置了llama模型,有24.5G。

Chat with RTX和ChatRTX都内置了mitral模型,Chat with RTX的模型是HF格式的,而ChatRTX是转换后的TensorRT-LLM格式,节省了10G的空间。安装包包含的内容格式更为精简,所以尺寸比原先的小多了。
 从安装过程来看, Chat with RTX在安装过程中必须连接互联网(需要科学上网),ChatRTX则可以离线安装使用,与私有知识库的应用场景进一步贴近起来。
从安装过程来看, Chat with RTX在安装过程中必须连接互联网(需要科学上网),ChatRTX则可以离线安装使用,与私有知识库的应用场景进一步贴近起来。
参考文献
https://blogs.nvidia.com/blog/ai-decoded-chatrtx-update/
















 8741
8741











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









