







Hologres多实例读写分离高可用部署(共享存储)
Hologres 从V1.1版本开始,针对线上生产环境高可用的场景,提供了共享存储的多实例部署方式,在该模式下支持故障隔离,负载隔离,有效支撑了高可用场景。
单实例自动恢复的高可用方案
Hologres计算节点均为容器调度(即下图中的Worker Node),资源管理器(Resource Manager)负责周期性健康检查。当出现1分钟容器响应超时(可能是内存溢出、硬件故障、软件Bug等原因导致),Resource Manager会自动拉起新的计算节点,并迁移Shard职责到新的节点上(例如Worker Node3响应超时,Resource Manager拉起Worker Node4取代Worker Node3),实现系统状态的快速恢复。数据状态保存在盘古分布式存储系统中,无需从计算节点迁移,计算节点轻量无状态,系统可以快速从故障中恢复。该方案为当前每个实例内部默认启用,当系统发生故障时,无需手工运维介入,系统可以自动恢复。在恢复期间,如果查询算子需要访问恢复中的节点,则查询会立即失败。Hologres从V1.1版本开始,采用全新恢复机制,节点恢复速度在一分钟左右,比早期版本提速5~10倍。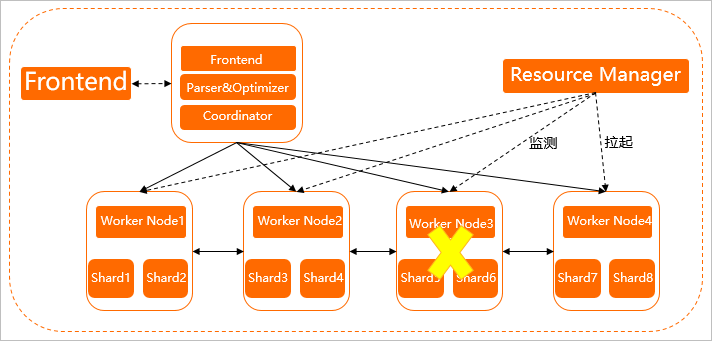
共享存储的多实例高可用方案
在单实例方案中,采用的是故障实时监测、节点替换的方案&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 980
980











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









