







随着阿里、腾讯、百度、字节跳动、滴滴、华为等众多互联网公司将 Flink 作为未来技术的重要发力点,越来越多的国内公司开始用 Flink 来做实时数据处理,Flink 已逐渐成为开发者进入大厂的“敲门砖”。
为更好的进行生态支持,自1.9版本开始,Apache Flink 增加对 Python 语言的支持。作为 TOP1 的流行语言,Python 在机器学习,科学计算等领域有着广泛的用户群。
炙手可热的流式计算框架 Flink,与善于数据分析的 Python 结合意味着什么?传智汇邀请到从事软件开发15年的传智教育资深研究员、Apache Flink 社区源码贡献者张老师,为大家带来 Pyflink 的深入分享。
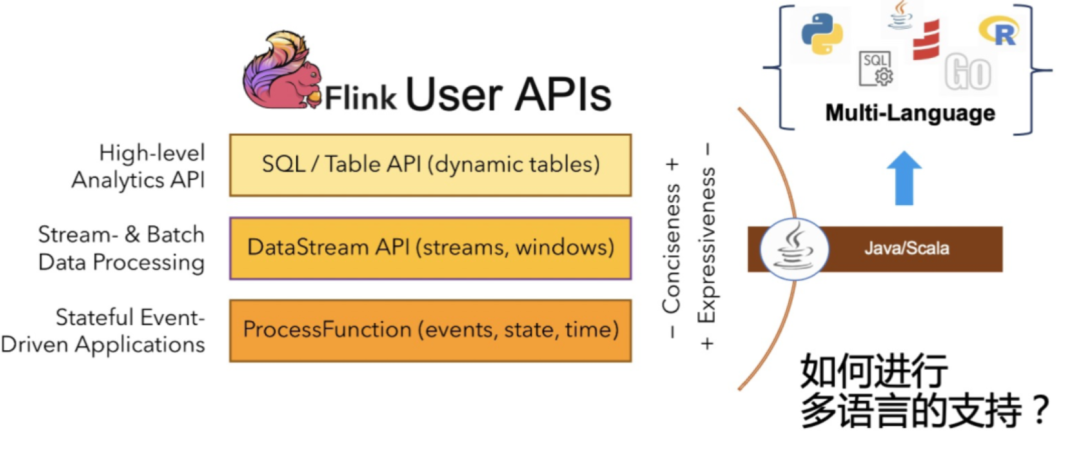
Pyflink的必要性?
Flink 是一个无界和有界数据流上进行有状态计算的分布式框架,简单的说既可以用在流计算,也可以用在批处理方面,可以做分布式计算。Flink 在实时数仓以及机器学习还有数据分析事件驱动的任务中做的非常好。
Flink 跟 Python 的整合并不仅仅是这两个框架合而为一这么简单。根据网上的统计,Python 主要用来做数据分析。Pyflink 在加入 Python 语言的同时,还可以使用 Python 的生态。
**同时对 Python 来说,可以利用 Flink 的分布式计算引擎来实现大规模数据的数据分析和机器学习,实现从单机到分布式的能力增强。**两者各取所需,是一个互补、双赢的状态。
Pyflink的架构?
Pyflink 在设计之初就定义了两个目标,一是让 Flink 用户有能力输出到 Python,第二是让 Python 用户可以使用 Flink。

Flink 官方在 Flink1.8 尝试开发 Python 引擎,但这样会导致开发成本和维护成本极高。要以最小的代价完成目标,最好的方式是仅仅提供一层 Python API 复用 Java 计算引擎。也因此在 Pyflink 里有很多的方法和函数,需要我们大家自己来实现。
为两者之间实行握手来进行技术选型,在市场有两个可用方案,一是 Apache Beam,另一个是 Py4J,这两个框架都可以实现。
Py4J 和 Beam 对比,就好像穿山甲和大象,大象除了能推倒墙,还可以做更多的事情,这也导致 Beam 在这个场景上有一个弊端,即为了增强通用性而丧失了一定的灵活性。
所以,想实现互通,我们可以使用穿山甲 Py4J,想实现多元支撑,可以使用 Apache Beam,这两个框架之间并不是完全互斥的。

解决了两者之间的通信问题后,我们在 Python API 里面提供和 Java API 一样的对象,也就是说 Python 在写 Python API 的时候本质是在调用 Java API,确保 Python API 语义和 Java API 的一致性,也让 Pyflink 可以达到和 Java 一样的性能。
在2020年阿里双 11 活动中,Flink Java API 已经具备了每秒25.51亿次的数据处理的能力。
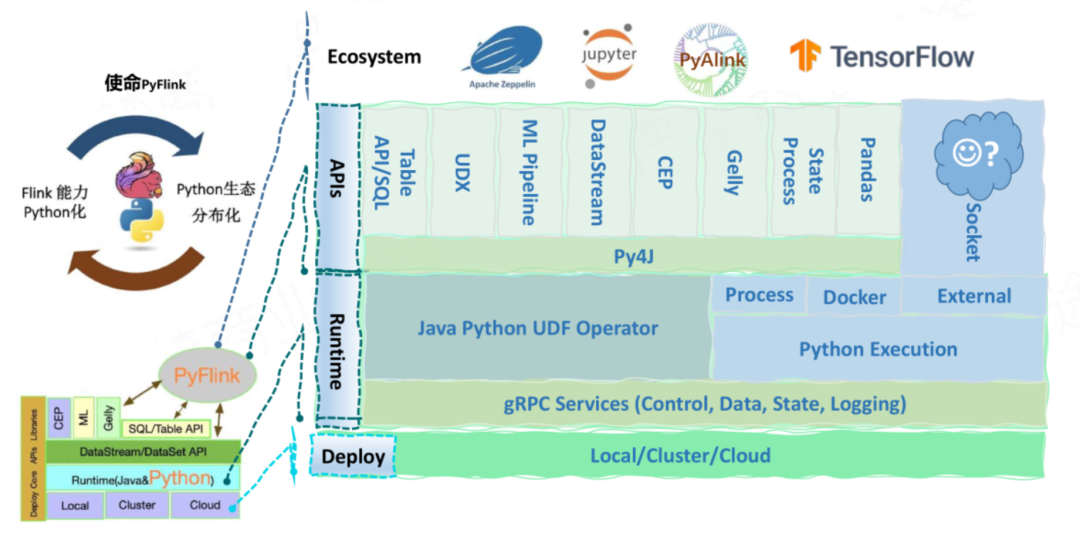
要实现第二个目标,将 Python 生态功能引入 Flink 中。这时候 Beam 更像是一只萤火虫,为在 Flink 中运行 Python UDF 照亮了道路。
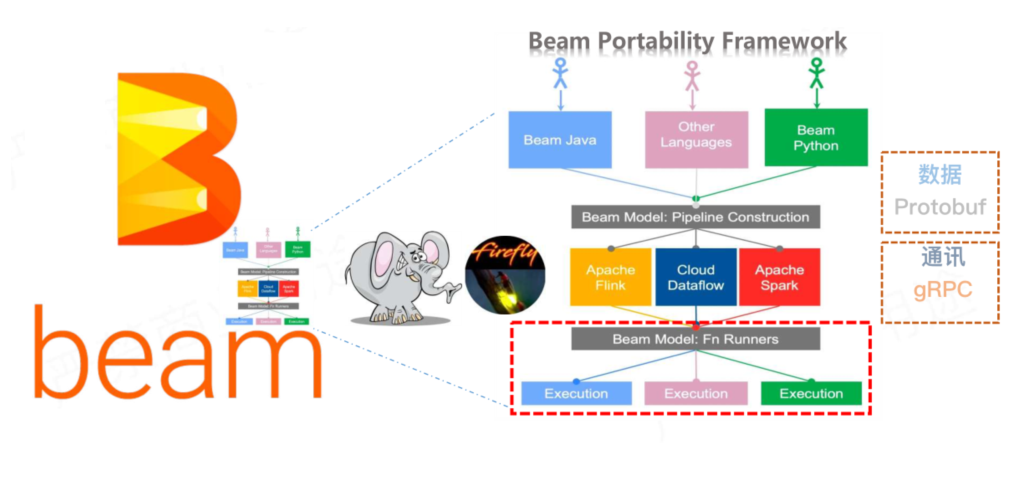
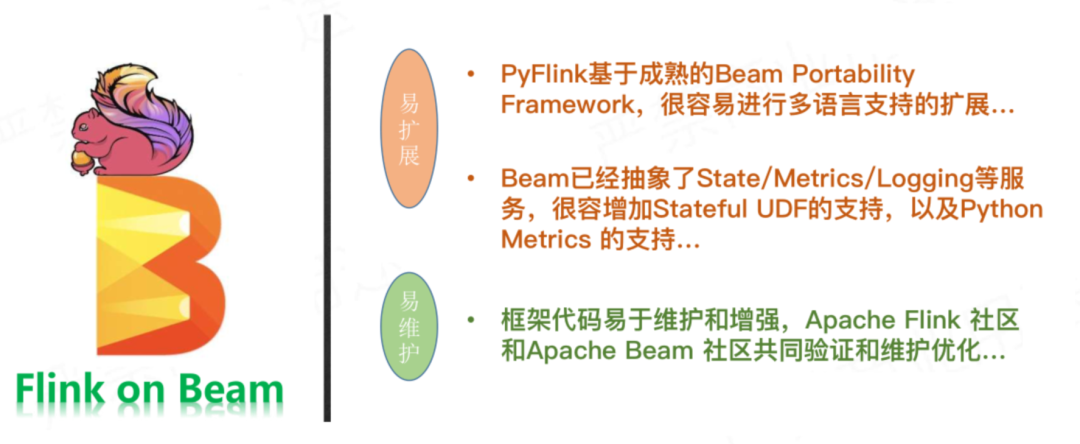
这样一来,Pyflink 基于成熟的 Beam portability Framework,很容易进行多语言支持的扩展;Beam 已经抽象了 State、Metrics、Logging 等服务,很容易增加 stateful UDF 的支持,以及 Python Metrics 的支持。
框架代码易于维护和增强,得到 Apache Flink 社区和 Apache Beam 社区共同验证和维护优化。
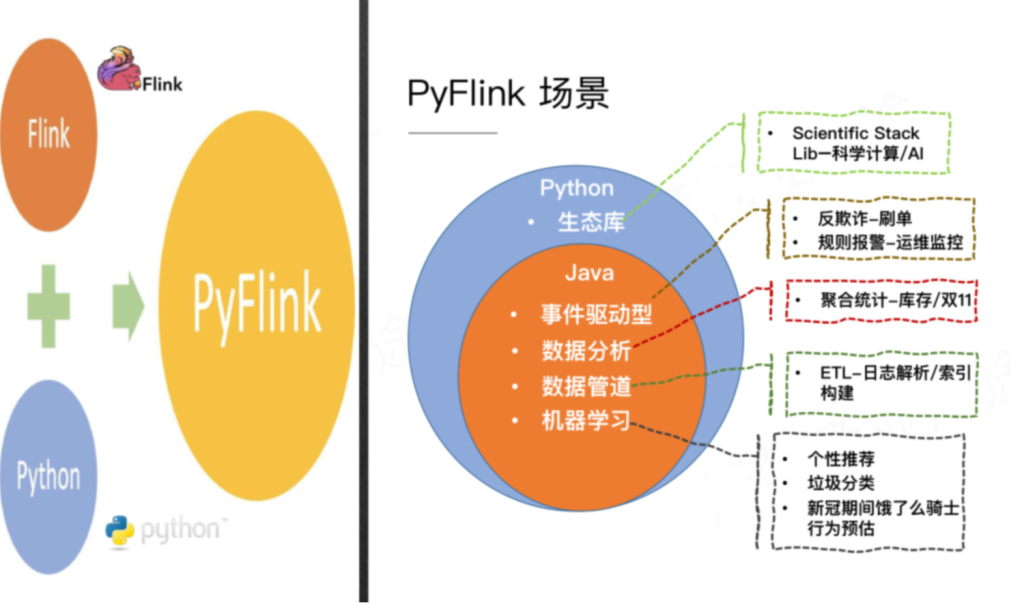
PyFlink的使用场景
Pyflink 的使用场景包括:
1. 事件驱动型,比如:刷单反欺诈,运维监控等
2. 数据分析,比如:聚合统计库存,双11等
3. 数据管道,比如 ETL 场景,日志解析、索引构建等
4. 机器学习,比如个性推荐、垃圾分类、骑手行为预估等
5. Python 生态特有场景,比如科学计算等
PyFlink 支持 pip install 安装,命令是:pip install apache-Flink。
目前 Java API 里面有什么功能 ,Pyflink 也有什么功能。除此之外 Pyflink 还增加了比如 columns 的处理,这些在 Java 里是不支持的。
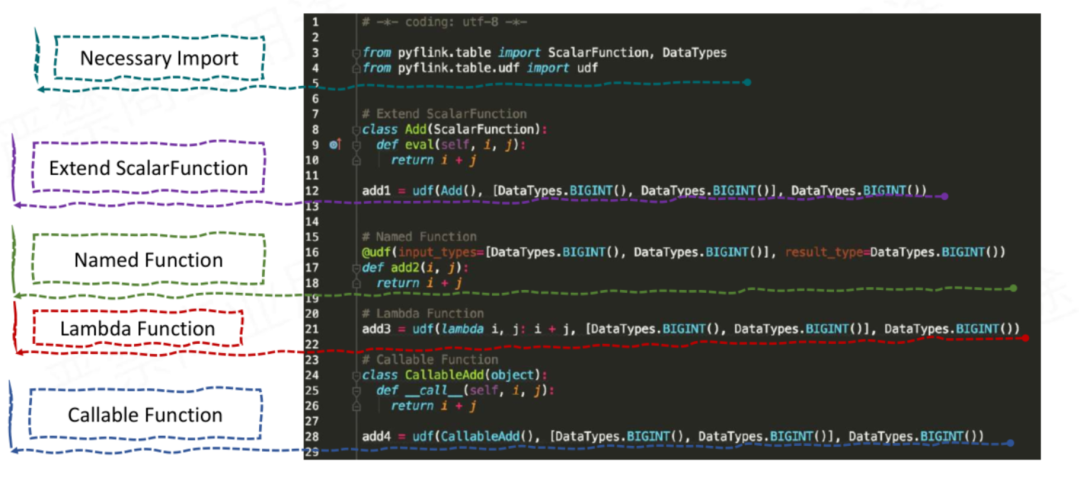
在 PyFlink 中支持多种方式来定义 Python UDF。你可以定义一个 Python 类,继承 ScalarFunction,也可以定义一个普通的 Python 函数或者 Lambda 函数,实现自定义函数的逻辑。
除此之外,还支持通过 Callable Function 和 Partial Function 定义 Python UDF。你可以根据自己的需要选择最适合自己的方式。
Pyflink的未来
目前 Pyflink 已经非常成熟了,功能上完全追平了 Table API 和 Data Stream API 的能力, Python UDF 性能接近 Java UDF,兼顾开发和运行的效率。
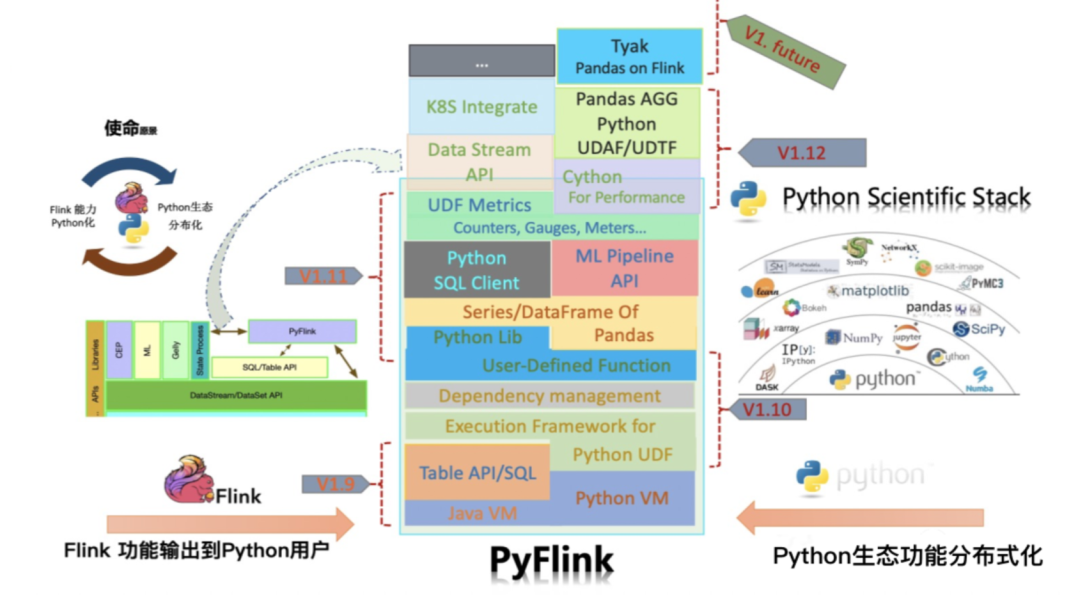
Pyflink 最重的愿景就是,将 JavaAPI、Javaflink 里面所有的功能移植到 Pyflink 里面。
如果有一天 Pyflink 能够完整继承 Javaflink 的功能,依托 Python 的生态,他的前景一定会更加广泛。
Q&A
1.讲解一下 Flink 的四层 Graph:
Flink 中的执行图可以分成四层:StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图。
StreamGraph 根据用户编写的 Stream API 而生成的最初的作业拓扑图,经过作业链优化生成 JobGraph,提交给 JobManager 的数据结构。
JobManager 根据 JobGraph 生成 ExecutionGraph,对 Job 进行调度后,在各个 TaskManager 上部署 Task 后形成的“图”就是物理执行图。
**2.**Pyflink 现有 API 不满足要求,能重写源码功能吗?
需要区别分析是 JavaAPI 不满足还是 PythonAPI 不满足,如果 Java API 里没有这个功能,那么 Pyflink 就肯定不支持这功能。
反过来说如果你想实现这个功能的话,你必须要在 JavaAPI 里面实现这个功能,然后才能在 Pyflink 里实现功能。
3.JavaAPI 有了新的功能,Pyflink 是不是要做相应的开发去适应和实现?
如果是 TableAPI 的话,JavaAPI 做了然后 Pyflink 里面有支持。如果是 DataStreamAPI 的话,目前支撑不是特别完善,可能存在个别需要适配的算子。
4.Python 调用 Java 的话,会不会消耗更多的一些内存资源?
理论上肯定是有消耗的,因为毕竟是两个框架,底层要进行通信。但是这个消耗是非常非常小的。
5.目前 Flink 实际的就业形势?
Flink 目前主要是在实时领域做的多一些,如果你想找实时的工作,那 Flink 肯定是我们的首选,因为招聘这个实时岗要求 Flink 的公司是最多的。
6.Pyflink 这种趋势下,Scala 的前景如何,还有必要深入了解吗?
Scala 的话大家没有必要再去学习了,这个语言已经日落西山。Scala 完全是因为 spark 的推动,而 spark 目前在实时领域没有话语权。我们要关注的应该是当下的热点,以及将来的方向。
7.Go 和 Python 有什么区别?
Go 主要是做高并发,服务端开发会多一些;Python 主要是用在数据分析,这两个应用场景是不一样的,数据分析和机器学习 Python 会多一些,推荐 Python 作为大数据第一编程语言。
8、现在有哪些用 PyFlink 的公司?
比较知名的公司有聚美优品和 BTC.com,阿里目前也有一部分业务在用 Pyflink。
参考文献:https://mp.weixin.qq.com/s/Y71YhvwQU4dCm4r41_I5sQ















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









