







DeepLab V1 - V3+ 带孔卷积总结
一 前置知识
1.1 分辨率
连续的池化或下采样操作会导致图像的分辨率大幅度下降,从而损失了原始信息,且在上采样过程中难以恢复。因此,越来越多的网络都在试图减少分辨率的损失,比如使用空洞卷积,或者用步长为2的卷积操作代替池化,实验证明,诸如此类的替代方法的确是有效的。

2.1 多尺度特征
通过设置不同参数的卷积层或者池化层,提取到不同尺度的特征图,将这些特征图送入到网络做融合,对于整个网络的性能的提升很大,但是由于图像金字塔的多尺度输入,造成计算时保存了大量的梯度,从而导致对硬件的要求很高,多数论文是将网络进行多尺度训练,在测试阶段进行多尺度融合,如果网络遇到瓶颈,可以考虑引入多尺度信息,有助于提高网络性能。

二 研究成果及意义
2.1 优势总结
- 参数同比减少,所以占内存减小,速度快
- ResNet的引入,越深沉的网络准确率越高
- 连续卷积核池化不可避免的会带来分辨率降低,然而空洞卷积却可以在尽可能保证分辨率的情况下,扩大视野
- ASPP
2.2 V1摘要
- 背景概述:DCNNs的最后一层不足以进行精确分割目标
- 主要贡献:本文将深度卷积神经网络和CRF相结合,克服了深度网络的局部化特征
- 网络效果:该网络超过了以往方法的精度水平,可以更好的定位分割边界
2.3 V2摘要
- 主要贡献:充分利用空洞卷积,可实现在不增加参数量的情况下有效扩大感受野,合并更多的上下文信息,DCNNs与CRF结合,进一步优化网络效果,提出了ASPP模块
- 网络效果:ASPP增强了网络在多尺度下多类别分割时的鲁棒性,使用不同的采样比例与感受野提取输入特征,能在多个尺度上补货目标与上下文信息
2.4 V3摘要
- 主要贡献:为了解决多尺度下的分割问题,本文设计了及联活并行的空洞卷积模块,扩充了ASPP模块
- 网络效果:网络没有经过DenseCRF后处理,也可以得到不错的结果
2.5 V3+摘要
- 背景概述:深度神经网络通常采用ASPP模块或编码器结构进行语义分割
- 主要分割:通过添加一个简单而有效的解码器模块优化V3
- 网络效果:该网络超过了以往方法的精度水平,可以更好地定位分割边界
摘要逻辑
整体逻辑 总体概述 本文方法 实验结果


三 模块架构
3.1 V1
结合了深度卷积神经网络和概率图模型的方法
深度卷积神经网络采用FCN思想,修改了VGG16网络,得到coarse score map并插值到原图大小
采用Atrous convolution得到更稠密且感受野不变的feature map
概率图模型借用fully connected CRF对从DCNNs得到的分割结果进行细节上的refine。
结构
- 把全链接层(fc6,7,8)改成卷积层
- 最后两个池化层步长改为1
- 把最后三个卷积层(conv5_1、conv5_2、conv5_3)的dilate rate设置为 2,且第一个全连接层的dilate rate设置为4(保持感受野)
- 把最后一个全连接层fc8的通道数从1000改为21(分类数为21)
- 第一个全连接层fc6,通道数从4096变为1024,卷积核大小从7x7变为3x3, 后续实验中发现此处的dilate rate为12时(LargeFOV),效果最好
实验设置

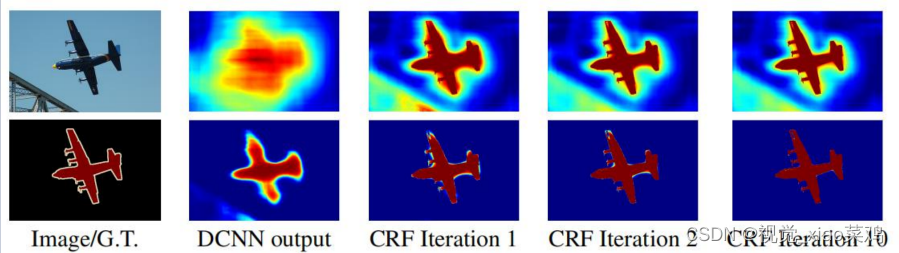
3.2 V2
- 针对分辨率过低的特征图,文章通过修改最后几个池化操作,避免特征图分辨率损失过大,通过引入空洞卷积,在没有增加参数与计算量的情况下增大了感受野
- 需要分割的目标具有多样的尺度大小,针对这个问题,文章参考了空间金字塔的思想,这里使用了不同比例的膨胀卷积构造“金字塔结构”
- DCNN网络对目标边界的分割准确率不高,文章引入了全链接条件随机场,使得分割边界的定位更加准确,从而解决此问题
空洞卷积

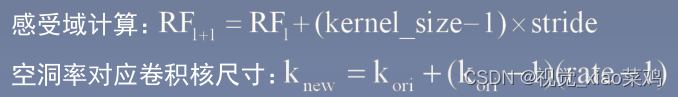
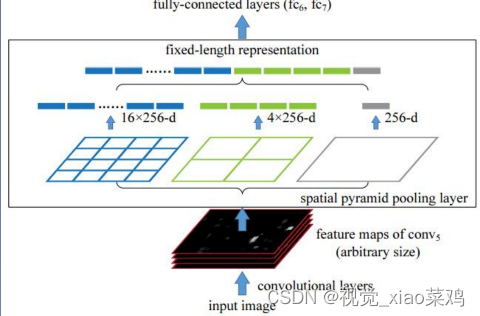
SPPNet
提出初衷是为了解决CNN对输入图片尺寸的限制,由于全链接层的存在,与之相连的最后一个卷积层的输出特征需要固定尺寸,从而要求输入图片尺寸也要固定,SPPNet之前的做法是将图片裁剪或变形,但是裁剪或者变形问题是导致图片信息缺失或变形影像精度。
bottom-up & top-down
top-down:在模式识别的过程中使用了上下文信息
bottom-up:以数据为主要趋动
算法架构

3.3 V3
本文贡献:
- 本文重新讨论了空洞卷积的使用,这让我们在串行模块和空间金字塔池化的框架下,能够获得更大的感受野从而获取多尺度信息
- 改进ASPP模块,有不同采样的空洞卷积和BN组成
- 采用大采样率,因为图片边界响应无法捕捉距离信息(对于小目标),会退化为1X1卷积
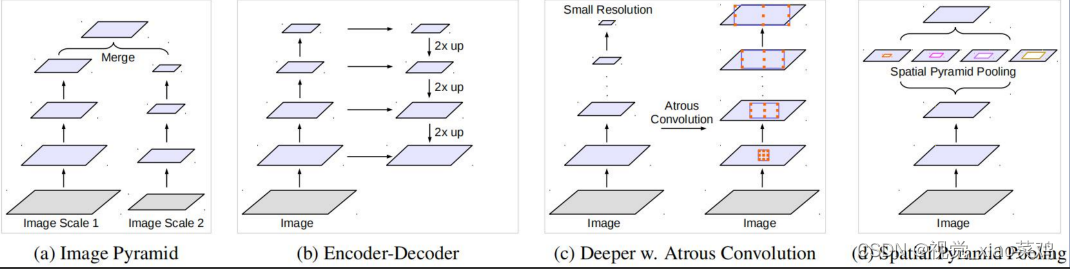
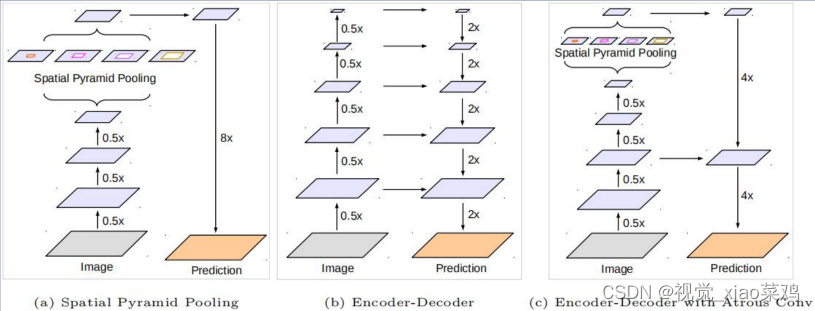
语义分割常用特征提取框架
- 图像金字塔:从输入图像入手,将不同尺度的图像分别送入网络进行特征提取,后期再融合
- 编解码结构:编码器部分采用下采样进行特征提取,解码器部分利用上采样还原特征图尺寸
- 深度网络VS空洞卷积:经典分类算法利用连续下采样提取特征,而空洞卷积是利用不同的采样率
- 空间金字塔结构:除ASPP外,仍有网络使用了该思想
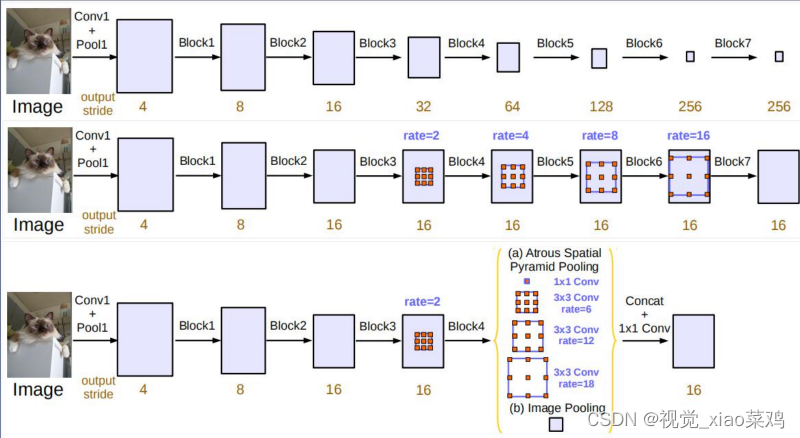
3.4 V3+
提出了一种编码器-解码器结构,采用DeepLab v3作为encoder,添加decoder得到新的模型 (DeepLabv3+)
将Xception模型应用于分割任务,模型中广泛使用深度可分离卷积
架构

四 总结
DeepLab系列发展历程:
V1:修改经典分类网络(VGG16),将空洞卷积应用于模型中,试图解决分辨率 过低及提取多尺度特征问题,用CRF做后处理
V2:设计ASPP模块,将空洞卷积的性能发挥到最大,沿用VGG16作为主网络, 尝试使用ResNet-101进行对比实验,用CRF做后处理
V3:以ResNet为主网络,设计了一种串行和一种并行的DCNN网络,微调ASPP模 块,取消CRF做后处理
V3+:以ResNet或Xception为主网络,结合编解码结构设计了一种新的算法模 型,以v3作为编码器结构,另行设计了解码器结构,取消CRF做后处理
















 1226
1226











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









