







深度学习中学习率调整策略总结
在深度学习中,学习率对模型的训练过程起着很重要的作用,影响着损失函数的变化速度。学习率越低,可以确保不会错过任何局部最小值,但是也意味着将花费更长的训练时间来进行收敛,特别是陷入局部最优的情况下。学习率越高,就容易错过全局最小值导致结果不收敛。
一 学习率与batch-size的关系
一般来说,batch-size的大小一般与学习率的大小成正比。batch-size越大一般意味着算法收敛方向的置信度越大,也可以选择较大的学习率来加快收敛速度。而小的batch-size规律性较差,需要小的学习率保证不出错。在显存允许的情况下,选择大的batch-size。
学习率调整策略需要继承_LRScheduler类,该类包含三个重要属性和两个重要方法:
- 预设规则的学习率变化法:StepLR、Multi-StepLR
- 自适应的学习率变化法:ExponentialLR,CosineAnnealingLR,LambdaLR,OneCycleLR,Poly
二 学习率调整策略
在整个训练过程中,我们不能使用同样的学习率来更新权重,否则无法达到最优点,所以需要在训练过程中调整学习率的大小。在训练初始阶段,由于权重属于随机初始化的状态,损失函数更容易收敛,所以可以设置一个较大的学习率。在训练后期,由于权重已经接近最优,较大的学习率无法进一步寻找最优值,所以需要一个较小的学习率。
2.1 常用的策略
- Poly
- StepLR
- MultiStepLR
- ExponentialLR
- LambdaLR
- OneCyycleLR
- CosineAnnealingLR
其中CosineAnnealingLR无需调整超参数,鲁棒性也比较高,所以成为提高模型精度的首选策略。
2.2 StepLR单步长
StepLR学习率调整策略的优点是简单易懂,易于实现。它可以在训练过程中根据设定的步长来调整学习率,从而使模型更加稳定。
缺点是调整学习率的步长是固定的,可能不够灵活,无法适应不同的训练情况。此外,如果步长设置得不合理,可能会导致模型在训练过程中出现震荡或过拟合的情况。
因此,在使用StepLR学习率调整策略时,需要根据具体情况进行调整,以达到最佳效果。
代码实现
我们需要导入要使用的库:
import torch
import torch.optim as optim
from torch.optim import lr_scheduler
from torchvision.models import AlexNet
import matplotlib.pyplot as plt
from torch.optim.lr_scheduler import _LRScheduler
model = AlexNet(num_classes=2)
optimizer = optim.SGD(params=model.parameters(),lr=0.05)
scheduler = lr_scheduler.StepLR(optimizer,step_size=30,gamma=0.1)
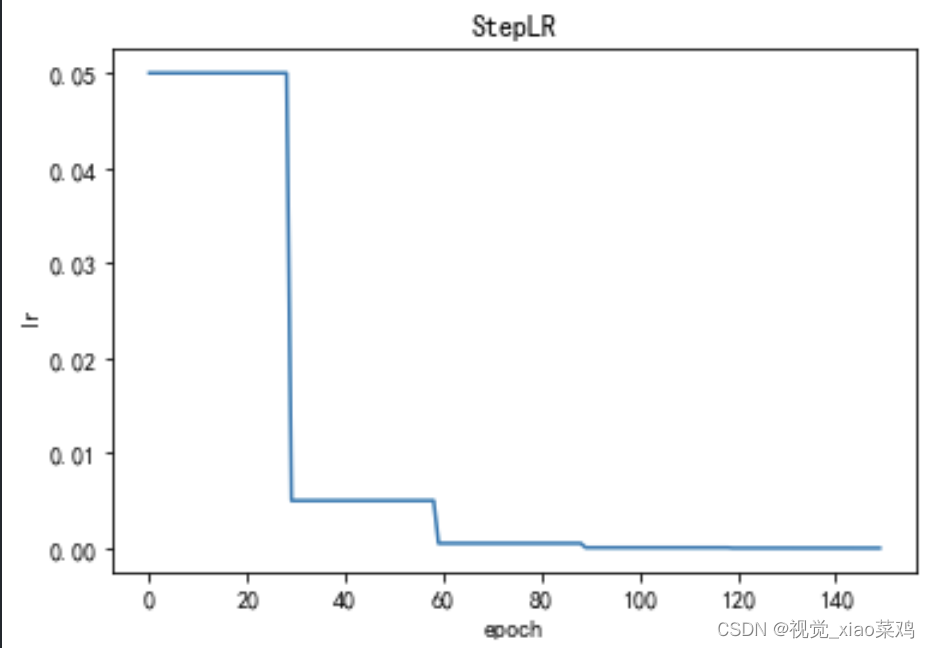
2.3 MultiStepLR多步长
MultiStepLR学习率调整策略的优点是比StepLR更加灵活,可以根据设定的milestones来调整学习率,从而更好地适应不同的训练情况。此外,它也比较简单易懂,易于实现。缺点是milestones的设置需要根据具体情况进行调整,如果设置不合理,可能会导致模型在训练过程中出现震荡或过拟合的情况。因此,在使用MultiStepLR学习率调整策略时,需要根据具体情况进行调整,以达到最佳效果。
代码实现
model = AlexNet(num_classes=2)
optimizer = optim.SGD(params=model.parameters(),lr=0.05)
scheduler = lr_scheduler.MultiStepLR(optimizer,[30,80,100],0.1)
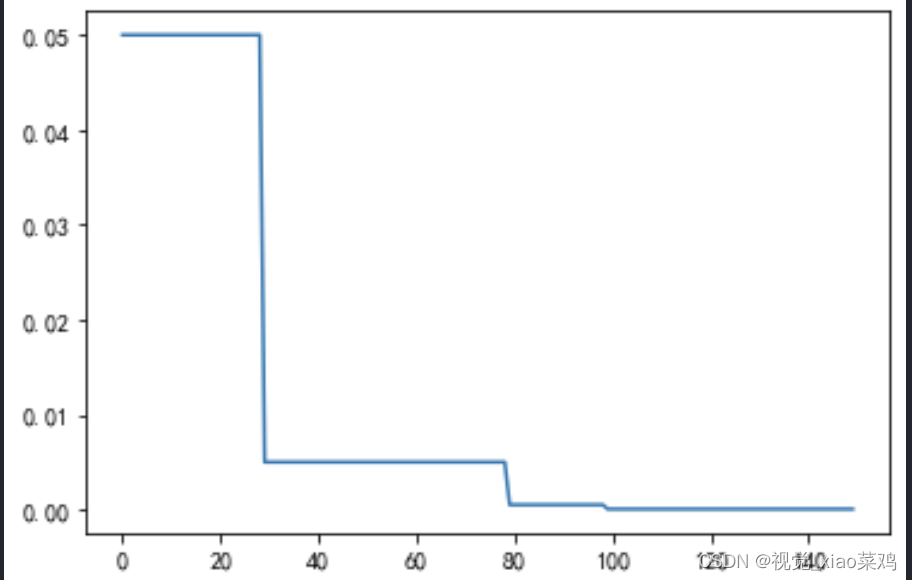
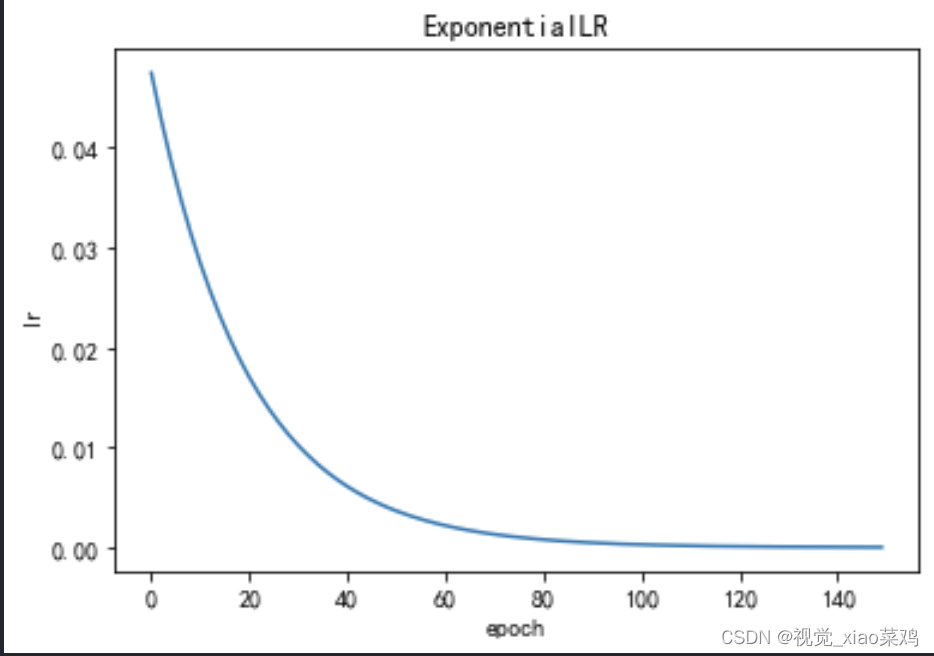
2.4 ExponentialLR指数衰减
指数衰减策略的优点是可以使学习率在训练过程中逐渐减小,从而使模型更加稳定。它的缺点是衰减速度比较快,可能会导致模型在训练初期学习率过大,出现梯度爆炸的情况。此外,指数衰减策略的衰减因子需要根据具体情况进行调整,如果设置不合理,可能会导致模型在训练过程中出现震荡或过拟合的情况。因此,在使用指数衰减策略时,需要根据具体情况进行调整,以达到最佳效果。
代码实现
"""
指数衰减
lr_scheduler.ExponentialLR
new_lr = initial_lr * (gamam ** epoch)
"""
model = AlexNet(num_classes=2)
optimizer = optim.SGD(params=model.parameters(),lr=0.05)
scheduler = lr_scheduler.ExponentialLR(optimizer,gamma=0.95)
plt.figure()
y.clear()
for epoch in range(150):
optimizer.zero_grad()
optimizer.step()
scheduler.step()
y.append(scheduler.get_last_lr()[0])
plt.plot(x, y)
plt.xlabel("epoch")
plt.ylabel("lr")
plt.title("ExponentialLR")
plt.show()
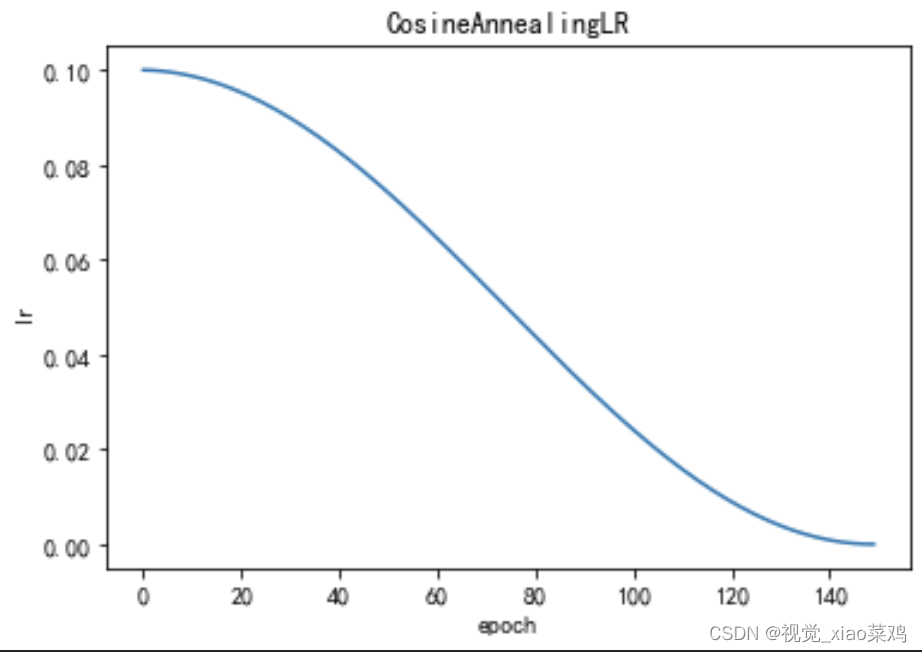
2.5 CosineAnnealingLR余弦退火策略
余弦退火策略的优点是可以使学习率在训练过程中逐渐减小,从而使模型更加稳定。与指数衰减策略相比,余弦退火策略的衰减速度更加缓慢,可以避免梯度爆炸的情况。此外,余弦退火策略可以根据当前epoch的索引和最大迭代次数计算出一个余弦因子,从而更好地适应不同的训练情况。缺点是余弦退火策略的实现比较复杂,需要计算余弦因子,可能会影响训练速度。因此,在使用余弦退火策略时,需要根据具体情况进行调整,以达到最佳效果。
代码实现
"""
余弦退火
lr_scheduler.CosineAnnealingLR
new_lr = lr = 0.5 * base_lr * (1 + cos(epoch / T_max * pi))
Tmax:极速下降到0的epoch
其中,lr表示当前的学习率,base_lr表示初始学习率,epoch表示当前的epoch数,T_max表示总的epoch数,pi表示圆周率。这个公式会根据当前的epoch数和总的epoch数来计算当前的学习率,学习率会在前半段逐渐增加,在后半段逐渐减小,最终回到初始学习率。这种学习率调整策略可以帮助模型在训练初期快速收敛,在训练后期避免过拟合。
"""
model = AlexNet(num_classes=2)
optimizer = optim.SGD(model.parameters(),lr=0.1)
scheduler = lr_scheduler.CosineAnnealingLR(optimizer,T_max=150)
plt.figure()
y.clear()
for epoch in range(150):
optimizer.zero_grad()
optimizer.step()
scheduler.step()
y.append(scheduler.get_last_lr()[0])
plt.plot(x, y)
plt.xlabel("epoch")
plt.ylabel("lr")
plt.title("CosineAnnealingLR")
plt.show()
2.6 LambdaLR自定义
lr_scheduler.LambdaLR的优点是可以根据自定义的函数来调整学习率,灵活性比较高。可以根据具体任务和模型的需求来选择合适的函数,以提高模型的性能。缺点是需要自己定义函数,可能需要一定的数学知识和经验。此外,如果函数定义不合理,可能会导致模型在训练过程中出现震荡或过拟合的情况。因此,在使用LambdaLR时,需要根据具体情况进行调整,以达到最佳效果。
代码实现
model = AlexNet(num_classes=2)
optimizer = optim.Adam(model.parameters(),lr=0.1)
scheduler = lr_scheduler.LambdaLR(optimizer=optimizer,lr_lambda=lambda epoch:0.5**epoch**2)
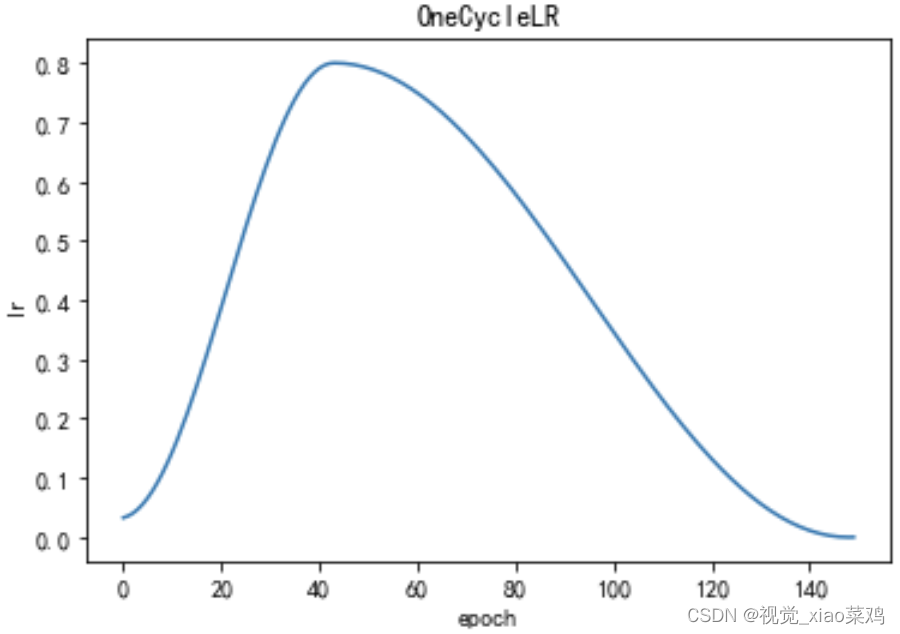
2.7 OneCycleLR
OneCycleLR学习率调整策略的优点包括:
更快的收敛速度:OneCycleLR学习率调整策略可以在训练初期快速提高学习率,加速模型的收敛速度。
更好的泛化能力:OneCycleLR学习率调整策略可以在训练后期逐渐降低学习率,避免过拟合,提高模型的泛化能力。
更稳定的训练过程:OneCycleLR学习率调整策略可以通过动态调整学习率来避免训练过程中出现梯度爆炸或梯度消失等问题,提高训练的稳定性。
更好的超参数调整:OneCycleLR学习率调整策略可以通过调整超参数来适应不同的数据集和模型,提高模型的性能。
OneCycleLR学习率调整策略的缺点包括:
对超参数敏感:OneCycleLR学习率调整策略的性能很大程度上取决于超参数的选择,需要进行仔细的调参。
不适用于所有模型:OneCycleLR学习率调整策略可能不适用于所有类型的模型,需要根据具体情况进行选择。
计算量较大:OneCycleLR学习率调整策略需要进行多次迭代计算,计算量较大,可能会影响训练速度。
代码实现
"""
lr_scheduler.OneCycleLR
optimizer, 优化器
max_lr, 学习率最大值
total_steps=None, 总step次数
pct_start=0.3, 学习率上升的部分step数量的占比
div_factor=25.0, 初始学习率 = max_lr / div_factor
final_div_factor=10000.0, 最终学习率 = 初始学习率 / final_div_factor
"""
model = AlexNet(num_classes=2)
optimizer = torch.optim.Adam(model.parameters(),lr=0.1)
scheduler = lr_scheduler.OneCycleLR(optimizer, max_lr=0.8, total_steps=150, pct_start=0.3)
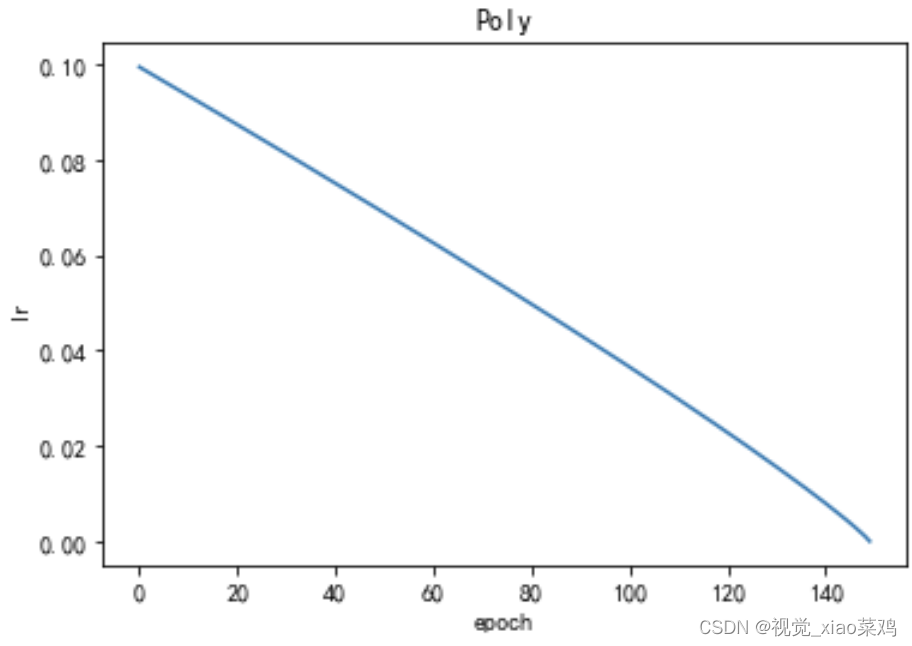
2.8 Poly
Poly学习率调整策略的优点包括:
更好的泛化能力:Poly学习率调整策略可以在训练后期逐渐降低学习率,避免过拟合,提高模型的泛化能力。
对超参数不敏感:Poly学习率调整策略的性能不太受超参数的影响,相对比较稳定。
计算量较小:Poly学习率调整策略的计算量相对较小,不会影响训练速度。
Poly学习率调整策略的缺点包括:
收敛速度较慢:Poly学习率调整策略在训练初期学习率较低,收敛速度较慢。
不适用于所有模型:Poly学习率调整策略可能不适用于所有类型的模型,需要根据具体情况进行选择。
代码实现
from torch.optim.optimizer import Optimizer
class PolyLR(_LRScheduler):
def __init__(self,optimizer,max_iters,power=0.9,last_epoch=-1,min_lr=1e-6):
# super(PolyLR,self).__init__(optimizer,last_epoch)
self.power = power
self.max_iters = max_iters
self.min_lr = min_lr
super(PolyLR, self).__init__(optimizer, last_epoch)
def get_lr(self) -> float:
return [ max( base_lr * ( 1 - self.last_epoch/self.max_iters )**self.power, self.min_lr)
for base_lr in self.base_lrs]
model = AlexNet(num_classes=2)
optimizer = torch.optim.Adam(model.parameters(),lr=0.1)
scheduler = PolyLR(optimizer, max_iters=150, power=0.9, last_epoch=-1, min_lr=1e-6)
2.9 WarmupLR
Warm up是指在训练开始时,先使用一个较小的学习率进行训练,然后逐渐增加学习率,直到达到设定的最大学习率。这样可以使模型更加稳定,避免在训练初期出现梯度爆炸或梯度消失的情况。
要实现Warm up,可以在自定义学习率更新策略的get_lr()方法中加入一个判断,当当前epoch的索引小于设定的Warm up epoch时,使用一个较小的学习率,否则使用正常的学习率更新策略。具体实现可以参考以下代码:
代码实现
class WarmupLR(_LRScheduler):
def __init__(self, optimizer, warmup_epochs, warmup_lr, last_epoch=-1):
self.warmup_epochs = warmup_epochs
self.warmup_lr = warmup_lr
super(WarmupLR, self).__init__(optimizer, last_epoch)
def get_lr(self):
if self.last_epoch < self.warmup_epochs:
return [self.warmup_lr + (base_lr - self.warmup_lr) * self.last_epoch / self.warmup_epochs
for base_lr in self.base_lrs]
else:
return [base_lr * self.gamma ** (self.last_epoch - self.warmup_epochs)
for base_lr in self.base_lrs]
















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









