







声明:学习过程中的知识总结,欢迎批评指正。
ORB算法提取两路输入图像(图像A,图像B)的特征点,根据提取的特征点进行特征匹配得到特征对。
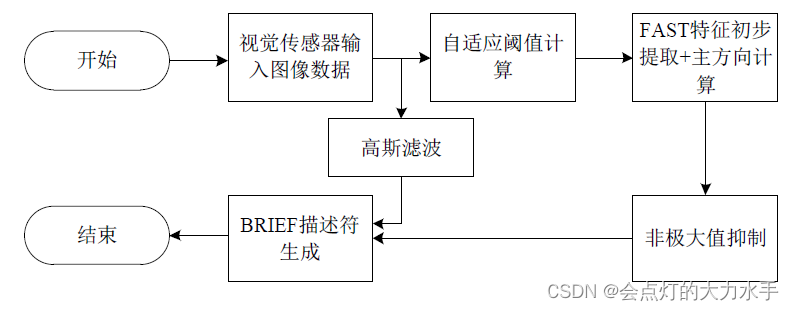
图像金字塔
因为在现实世界中,同一个物体可能会以不同的尺度出现在图像中。例如,当你走近一个物体时,它在图像中的尺度就会变大;当你远离一个物体时,它在图像中的尺度就会变小。而且在双目视角中同一物体的尺度也是不一样的,为了让特征点检测算法能够在不同尺度的图像中都能有效地检测到特征点,需要使用图像金字塔。图像金字塔是由原始图像(称为第0层Level0)经过多次下采样得到的,在每一层上重新运行特征点提取算法或者根据缩放因子把第0层的特征点均摊到其它层,这样,我们就可以在不同尺度的图像中都检测到特征点,从而实现尺度不变性。
计算FAST角点
- 选取像素p,假设它的亮度为Ip
- 设置一个阈值T(这个阈值指的是亮度差)
- 以像素p为中心,选取半径为3的圆上的16个像素点
- 假设在这个圆上,有连续N个点的亮度大于Ip+T或小于Ip-T,那么像素p就被认为是特征点
- 循环上面几步,对每个像素都执行相同操作
可以理解成用一个7×7的卷积核,把图像进行遍历。

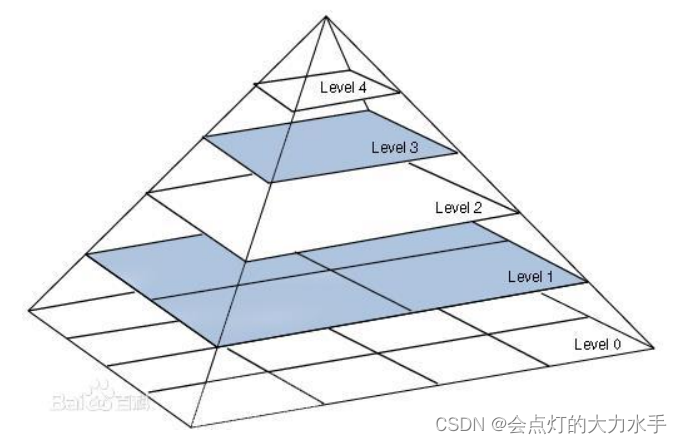
四叉树均匀化
通过四叉树均匀化把每层图像中的特征点的分布调整的更加均匀一些,在图像处理和计算机视觉中,特征点的分布往往会影响到后续算法的性能。如果特征点集中在图像的某一部分,那么这可能会导致对图像其他部分的信息损失,从而影响到后续算法的精度。
四叉树均匀化步骤:
- 将图像分割成四个等大小的区域(也就是四叉树的根节点)。
- 在每个区域中选择一定数量的特征点。如果某个区域中的特征点数量超过了预设的阈值,那么就继续将这个区域分割成四个子区域,并在每个子区域中选择特征点。
- 重复上述过程,直到所有的区域中的特征点数量都不超过阈值,或者达到了预设的最大深度。
BRIEF、ORB描述子
BRIEF算法的核心思想就是在特征点P周围以一定模式选取N个点对,比较点对的两个点(比如p,q)所在的灰度值大小:如果p比q大,则取1,反之取0。如果取了256个这样的p,q,就会得到256维由0,1组成的向量,而这个向量就是这个点的唯一表示,就可以称之为描述子。通过上述步骤我们得到了图像A和图像B的图像金字塔以及每一层中均匀分布的特征点,然后对这些特征点进行BRIEF描述子计算。FAST角点是没有方向信息的,那么在图像发生旋转的时候,其描述子也会发生变化,为了是的特征点具有旋转不变形,引出了灰度质心法来计算特征点的方向。
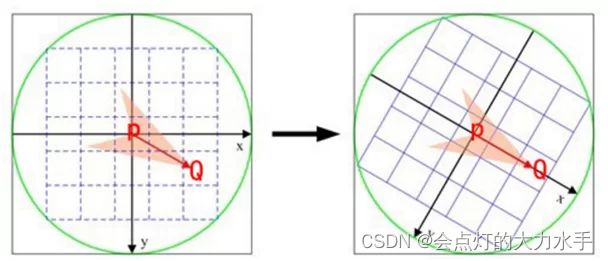
Steer BRIED描述子:上面所说的BRIEF算法,在将图像旋转后,描述子就会发生变化,为了使得描述子对旋转鲁棒,提出了灰度质心法(这个原理在下面讲解)具体做法就是将固定的pattern进行坐标转换,转换的坐标就是灰度质心法求解的向量作为x轴所在的坐标系,然后用转换后的pattern坐标下所在的像素进行对比,同样会得到唯一的描述子。如下图所示,Q就是灰度质心,坐标转换成PQ是x轴的坐标系:
BRIEF描述子的计算过程如下:
- 首先,选取特征点周围的一个小区域,通常是一个正方形区域。
- 然后,在这个区域内随机选择一对像素,计算它们的灰度值差。
- 如果灰度值差大于0,那么在BRIEF描述子中对应的位置为1,否则为0。
- 重复上述过程,直到得到一个足够长的二进制向量。通常,BRIEF描述子的长度可以是128、256或512。
ORB(Oriented FAST and Rotated BRIEF)描述子是在BRIEF的基础上加入旋转不变性的。这是通过引入特征点的方向信息来实现的。
具体的步骤:
- 特征点检测:ORB使用FAST角点检测器来找到图像中的特征点。
- 计算特征点的方向:对于每个关键点,ORB计算其周围像素的质心,然后计算特征点到质心的向量,该向量的角度就是特征点的方向。具体来说,如果图像中的点为𝑝(𝑥,𝑦),其强度质心为𝐶,则角度𝜃可以通过下面的公式计算:
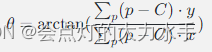 其中,𝑝是特征点周围的像素,𝐶是这些像素的质心,𝑥和𝑦是像素的坐标。
其中,𝑝是特征点周围的像素,𝐶是这些像素的质心,𝑥和𝑦是像素的坐标。 - 生成旋转不变的BRIEF描述子:在生成BRIEF描述子的时候,ORB考虑了特征点的方向。具体来说,它根据特征点的方向,将比较的像素对进行旋转,然后再比较它们的灰度值。这样生成的BRIEF描述子就具有旋转不变性了。
非极大值抑制
在特征点检测和描述子生成的过程中,非极大值抑制(Non-Maximum Suppression,NMS)是一个常用的步骤,用于减少冗余的特征点,并保留最显著的特征点。这在处理大量图像数据时是非常重要的,因为它可以显著减少计算量和存储需求。
特别是在特征点检测阶段,我们通常会得到大量的候选特征点,其中许多可能是相互非常接近或者在某种程度上是冗余的。非极大值抑制就是在这些候选特征点中选择最显著的特征点。通常,这是通过比较每个特征点与其邻域内其他特征点的响应值来实现的。只有当一个特征点的响应值大于其所有邻域内的其他特征点时,我们才保留这个特征点。
然而,对于特征点的主方向的计算,非极大值抑制并不常用。主方向的计算通常是基于特征点周围像素的梯度方向和大小,通过形成一个方向直方图,然后找到直方图的峰值来确定的。这个过程并不涉及非极大值抑制。但在某些算法中,可能会在计算主方向后再次使用非极大值抑制,以进一步减少特征点的数量。
特征点匹配
对同一层中的特征点进行特征匹配得到特征对,然后把每一层得到的特征对都叠加到第0层,再到一连串完整的特征对。
- 特征描述子计算:对每个特征点,计算其特征描述子。这可以使用BRIEF、SIFT、SURF、ORB等方法。
- 特征描述子比较:计算两个图像中所有特征描述子之间的距离。这通常使用欧氏距离或汉明距离,取决于特征描述子的类型,如果是使用具有旋转不变性的描述子计算方法,那么可以通过汉明距离来比较他们之间的距离。
- 匹配:根据特征描述子之间的距离,找到最相似的特征点对。常用的策略有最近邻匹配(Nearest Neighbor matching)和比值测试(Ratio Test)。最近邻匹配是找到距离最近的特征点对,而比值测试是找到第二近的特征点,并计算最近和第二近的距离比值,如果这个比值小于某个阈值(如0.8),则认为这是一个好的匹配。
- 剔除错误匹配:由于噪声和其他因素的影响,可能会产生一些错误的匹配。因此,通常需要使用一些方法来剔除这些错误的匹配,如RANSAC(RANdom SAmple Consensus)算法。
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











