







Spark经常需要从hdfs读取文件生成RDD,然后进行计算分析。这种从hdfs读取文件生成的RDD就是HadoopRDD。那么HadoopRDD的分区是怎么计算出来的?如果从hdfs读取的文件非常大,如何高效的从hdfs加载文件生成HadoopRDD呢?本篇文章探讨这两个问题。
SparkContext.objectFile方法经常用于从hdfs加载文件,从加载hdfs文件到生成HadoopRDD的函数调用过程为:
SparkContext.objectFile->
SparkContext.sequenceFile->
SparkContext.hadoopFile->
new HadoopRDD
SparkContext.objectFile方法定义如下:
从以上代码可知如果不设置加载的hdfs文件生成的HadoopRDD的分区个数,默认最小分区个数是2
SparkContext.objectFile方法的minPartitions参数没有改变,一直传递到HadoopRDD的构造函数
HadoopRDD.getPartitions方法用于创建HadoopRDD的分区。
在本篇文章中,以如下语句加载hdfs文件创建HadoopRDD,创建的HadoopRDD分区个数最小是24个
hdfs上/data/login/1448419800022/目录内的文件情况,如下图所示:
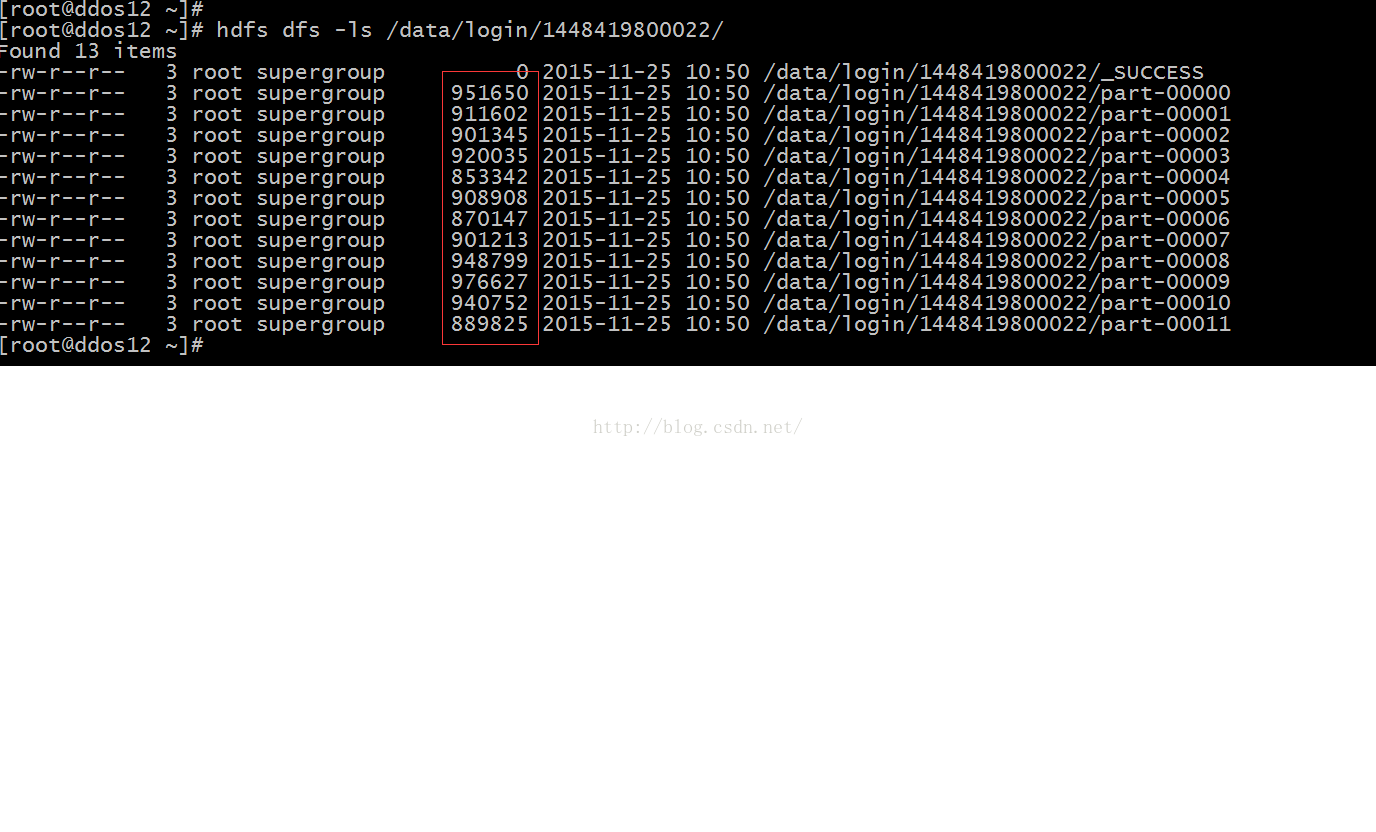
目录下存在12个文件,12个文件总共10974245字节,如果按照24个分区计算,平均一个分区是457260字节
分区的 创建在HadoopRDD.getPartitions方法:
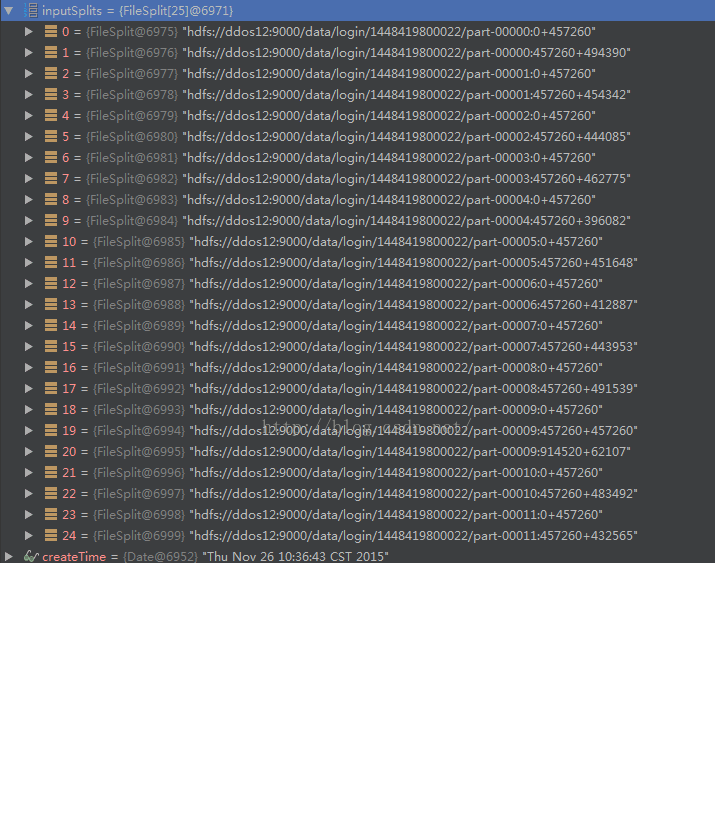
可见总共创建了25个分区,通过上图可得出结论在切分hdfs目录中的文件的时候,对每个文件按照分区平均长度457260进行切分,每个分区的长度不能大于457260.比如说part-00009文件,切分成了3个分区,最后一个分区的长度只有62107字节
下图表示了一个index为1分区的详细信息:
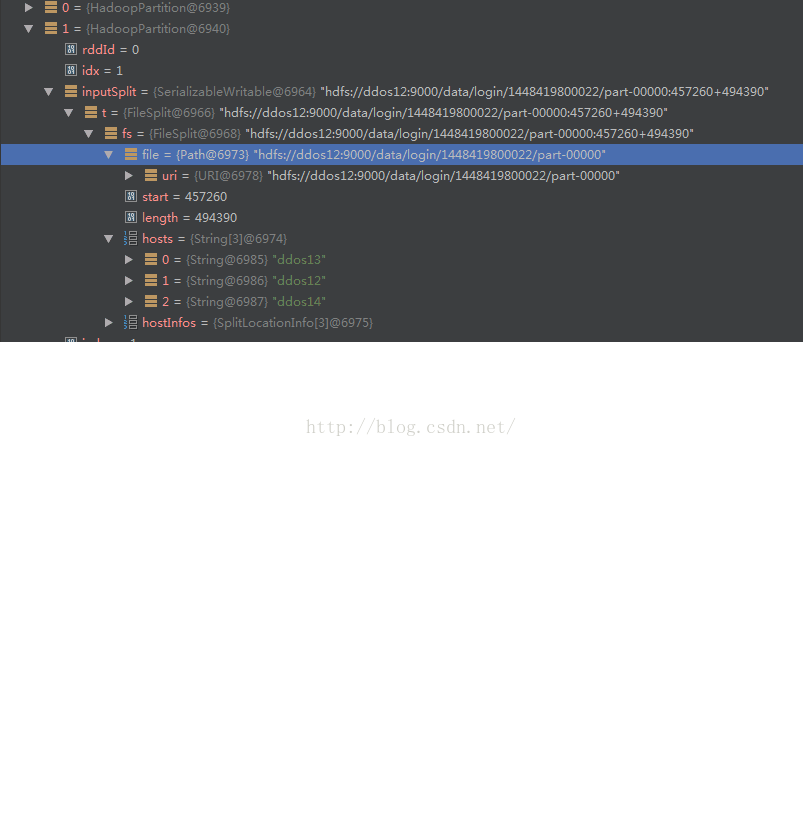
可见里面包含了分区所在的hdfs的文件,以及分区数据在这个文件的起始位置,分区的大小
但是默认情况下,HadoopRDD一个分区最大是128M,假设一个文件大小是1G+10M,但是我设置4个分区,那么在计算分区个数的时候会计算为9个分区,最后一个分区大小为10M。















 518
518

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









