







up主 刘二大人
RNN
处理具有序列关系的输入数据, 如天气,股市,自然语言
RNN Cell 输入包括两部分: ① : t 时刻对应的数据 ② 上一时刻的隐藏单元
RNN Cell 输出当前时刻的隐藏单元值

RNN Cell 计算过程
RNN Cell 可以看作是一个线性层
: 维度为input_size的向量
: 维度为hidden_size的向量
: (hidden_size, hidden_size)
: (hidden_size,input_size)
激活函数:

使用Pytorch RNNCell

import torch
batch_size = 1
seq_len = 3
input_size = 4
hidden_size = 2
cell = torch.nn.RNNCell(input_size=input_size, hidden_size=hidden_size)
"""
RNNCell input shape:
input_size (batch, input_size)
hidden_size (batch, hidden_size)
RNNCell output shape: (batch, hidden_size)
"""
# dataset shape = (seq_len, batch_size, input_size)
dataset = torch.randn(seq_len, batch_size, input_size)
hidden = torch.zeros(batch_size, hidden_size)
for idx, input in enumerate(dataset):
print('='*20, idx, '='*20)
print(f'Input Size: {input.shape}')
hidden = cell(input, hidden)
print(f'Output Size: {hidden.shape}')
print(hidden.data)
# 输出:
# ==================== 0 ====================
# Input Size: torch.Size([1, 4])
# Output Size: torch.Size([1, 2])
# tensor([[-0.3972, 0.6450]])
# ==================== 1 ====================
# Input Size: torch.Size([1, 4])
# Output Size: torch.Size([1, 2])
# tensor([[-0.1895, 0.5395]])
# ==================== 2 ====================
# Input Size: torch.Size([1, 4])
# Output Size: torch.Size([1, 2])
# tensor([[-0.1767, 0.9325]])
使用Pytorch RNN
Input
input shape: (seqSize, batch_size, input_size)
hidden shape: (numLayers, batch_size, hidden_size)
Output
output shape: (seqSize, batch_size, input_size)
hidden shape: (numLayers, batch_size, hidden_size)

numLayers 隐藏层的数目, 默认为1
如下图, numLayers = 3, 输出hidden值 作为下一层RNN Cell 单元的输入
numLayers 数目增加, 初始的 向量增加, 隐藏层输出也随之增加

import torch
"""
使用Pytorch RNN方法 实现RNN模型
"""
batch_size = 1
seq_len = 3
input_size = 4
hidden_size = 2
num_layers = 1
cell = torch.nn.RNN(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers, batch_first=True)
"""
RNN input shape:
input_size (seq_len, batch_size, input_size)
hidden_size (num_layers, batch_size, hidden_size)
RNN output shape
output size: (seq_len, batch, hidden_size)
hidden_size (num_layers, batch_size, hidden_size)
if batch_first is True:
RNN input input_size (batch_size, seq_len, input_size)
"""
# dataset shape = (seq_len, batch_size, input_size)
inputs = torch.randn(seq_len, batch_size, input_size)
hidden = torch.zeros(num_layers, batch_size, hidden_size)
out, hidden = cell(inputs, hidden)
print(f'Output size: {out.size()}')
print(f'Output: \n {out.data}')
print(f'Hidden size: {hidden.size()}')
print(f'Hidden: {hidden.data}')
# 输出:
# Output size: torch.Size([3, 1, 2])
# Output:
# tensor([[[-0.1632, 0.4478]],
#
# [[ 0.7569, -0.7513]],
#
# [[ 0.8531, -0.7120]]])
# Hidden size: torch.Size([1, 1, 2])
# Hidden: tensor([[[ 0.8531, -0.7120]]])
案例: 训练一个模型'hello' -> 'ohlol'
将输入hello转换成one-hot 向量,问题就变成输出各字符的概率, 将问题转变为多分类问题
seq_len = 5
input_size = 4 (4维向量表示1个字符)
hidden_size = 4
output_size = 4

1. 使用RNNCell
import torch
"""
使用Pytorch RNNCell方法 训练一个模型'hello' -> 'ohlol'
"""
class Model(torch.nn.Module):
def __init__(self, input_size, hidden_size, batch_size):
super(Model, self).__init__()
self.batch_size = batch_size
self.input_size = input_size
self.hidden_size = hidden_size
self.rnn_cell = torch.nn.RNNCell(input_size=self.input_size, hidden_size=self.hidden_size)
def forward(self, input, hidden):
hidden = self.rnn_cell(input, hidden)
return hidden
def init_hidden(self):
return torch.zeros(self.batch_size, self.hidden_size)
batch_size = 1
seq_len = 3
input_size = 4
hidden_size = 4
idx2char = ['e', 'h', 'l', 'o'] # 按照字母表顺序
x_data = [1, 0, 2, 2, 3]
y_data = [3, 1, 2, 3, 3]
one_hot_lookup = [[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]]
# x_one_hot = [[0, 1, 0, 0], [1, 0, 0, 0], [0, 0, 1, 0], [0, 0, 1, 0], [0, 0, 0, 1]]
x_one_hot = [one_hot_lookup[i] for i in x_data]
# input size (seq_len, batch_size, input_size)
inputs = torch.Tensor(x_one_hot).view(-1, batch_size, input_size)
# labels size (seq_len, 1)
labels = torch.LongTensor(y_data).view(-1, 1)
net = Model(input_size, hidden_size, batch_size)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.01)
for epoch in range(15):
loss = 0
optimizer.zero_grad()
hidden = net.init_hidden()
print("Predicted String: ", end='')
for input, label in zip(inputs, labels):
# hidden shape: (batch_size, hidden_size)
hidden = net(input, hidden)
loss += criterion(hidden, label)
# idx: 返回hidden
_, idx = hidden.max(dim=1)
print(idx2char[idx.item()], end='')
loss.backward()
optimizer.step()
print(', Epoch [%d/15] loss=%.4f' % (epoch + 1, loss.item()))
# 输出
# Predicted String: oheee, Epoch [1/15] loss=7.4199
# Predicted String: oheee, Epoch [2/15] loss=7.2861
# Predicted String: oheee, Epoch [3/15] loss=7.1553
# Predicted String: oheee, Epoch [4/15] loss=7.0271
# Predicted String: oheee, Epoch [5/15] loss=6.9017
# Predicted String: oheee, Epoch [6/15] loss=6.7795
# Predicted String: oheee, Epoch [7/15] loss=6.6607
# Predicted String: oheho, Epoch [8/15] loss=6.5454
# Predicted String: oheoo, Epoch [9/15] loss=6.4334
# Predicted String: oheoo, Epoch [10/15] loss=6.3249
# Predicted String: ohooo, Epoch [11/15] loss=6.2196
# Predicted String: ohooo, Epoch [12/15] loss=6.1176
# Predicted String: ohooo, Epoch [13/15] loss=6.0185
# Predicted String: ohooo, Epoch [14/15] loss=5.9223
# Predicted String: ohooo, Epoch [15/15] loss=5.8291
2. 使用RNN
import torch
"""
使用Pytorch RNN方法 训练一个模型'hello' -> 'ohlol'
"""
class Model(torch.nn.Module):
def __init__(self, input_size, hidden_size, batch_size, num_layers=1):
super(Model, self).__init__()
self.batch_size = batch_size
self.input_size = input_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.rnn = torch.nn.RNN(input_size=self.input_size, hidden_size=self.hidden_size, num_layers=self.num_layers)
def forward(self, input):
# init h0 shape: (num_layers, batch_size, hidden_size)
hidden = torch.zeros(self.num_layers, self.batch_size, self.hidden_size)
# output shape: (seq_len, batch, hidden_size)
output, _ = self.rnn(input, hidden)
# return shape: (seq_len x batch, hidden_size)
return output.view(-1, self.hidden_size)
batch_size = 1
seq_len = 5
input_size = 4
hidden_size = 4
num_layers = 1
idx2char = ['e', 'h', 'l', 'o'] # 按照字母表顺序
x_data = [1, 0, 2, 2, 3]
y_data = [3, 1, 2, 3, 2]
one_hot_lookup = [[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]]
# x_one_hot = [[0, 1, 0, 0], [1, 0, 0, 0], [0, 0, 1, 0], [0, 0, 1, 0], [0, 0, 0, 1]]
x_one_hot = [one_hot_lookup[i] for i in x_data]
# input shape: (seq_len, batch_size, input_size)
inputs = torch.Tensor(x_one_hot).view(seq_len, batch_size, input_size)
# labels shape: (seq_len x batch, hidden_size)
labels = torch.LongTensor(y_data)
net = Model(input_size, hidden_size, batch_size, num_layers)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.01)
for epoch in range(15):
loss = 0
optimizer.zero_grad()
output = net(inputs)
loss = criterion(output, labels)
loss.backward()
optimizer.step()
_, idx = output.max(dim=1)
idx = idx.data.numpy()
print(f"Predicted String: {''.join([idx2char[x] for x in idx])}", end='')
print(', Epoch [%d/15] loss=%.4f' % (epoch + 1, loss.item()))
# 输出
# Predicted String: ooooh, Epoch [1/15] loss=1.1544
# Predicted String: ooooh, Epoch [2/15] loss=1.1279
# Predicted String: ooooh, Epoch [3/15] loss=1.1021
# Predicted String: ooooh, Epoch [4/15] loss=1.0771
# Predicted String: ooooh, Epoch [5/15] loss=1.0531
# Predicted String: ooooh, Epoch [6/15] loss=1.0302
# Predicted String: ooool, Epoch [7/15] loss=1.0085
# Predicted String: ohlol, Epoch [8/15] loss=0.9881
# Predicted String: ohlol, Epoch [9/15] loss=0.9690
# Predicted String: ohlol, Epoch [10/15] loss=0.9511
# Predicted String: ohlol, Epoch [11/15] loss=0.9345
# Predicted String: ohlol, Epoch [12/15] loss=0.9191
# Predicted String: ohlol, Epoch [13/15] loss=0.9049
# Predicted String: ohlol, Epoch [14/15] loss=0.8916
# Predicted String: ohlol, Epoch [15/15] loss=0.8792
Embedding
one-hot 编码方式有如下问题: 1) 维度高 2) 稀疏矩阵 3) 硬编码
为解决上述问题, 推出Embedding技术, 即将离散变量转为连续向量表示的一个方式。
借鉴博客:
用万字长文聊一聊 Embedding 技术 - 极术社区 - 连接开发者与智能计算生态
在上面案例中, 加上Embedding Layer以及全连接层
Embedding Layer:
Input : (batch_size, seq_len)
Output : (batch_size, seq_len, embedding_size)
RNN Layer (num_layers = 2, batch_first=True):
Input x: (batch_size, seq_len, embedding_size)
Input hidden: (num_layers, batch_size, hidden_size)
Output: (batch_size, seq_len, hidden_size)
FC Layer (out_feature=num_class=4类 ‘e/h/l/o’)
Input: (batch_size, seq_len, hidden_size)
Output: (batch_size, seq_len, num_class)
问题总结:
1) Embedding 层在反向传播中如何计算梯度
如下图1, 4个五维词向量, 可以用4*5矩阵表示, 如要取出第三行,可以通过图2矩阵运算得到。那么在反向传播计算梯度时, 可以通过矩阵求导获得梯度
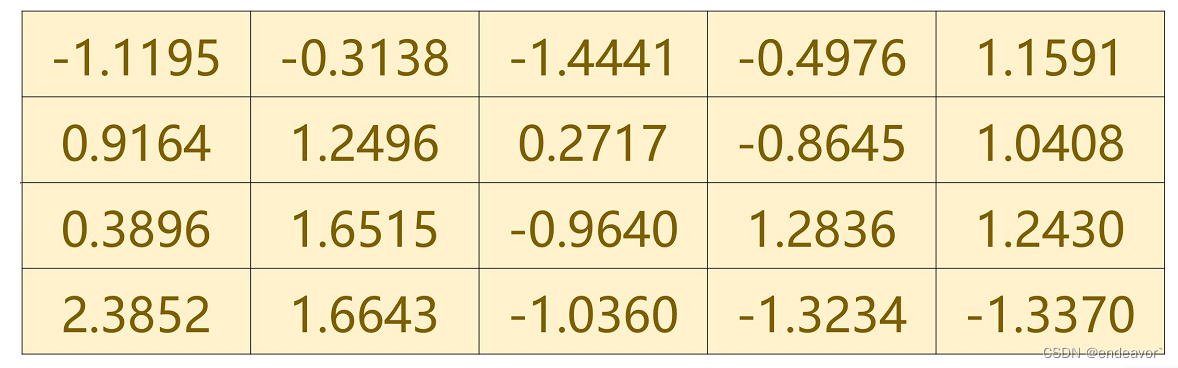
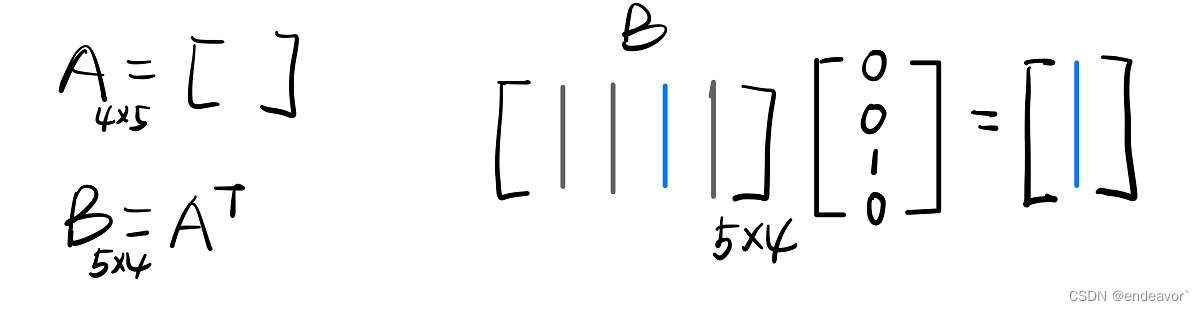
2) RNN layer 之后加上线性层的原因是:
由于RNN 输出维度与hidden size相同(这里hidden_size =8),与我们最终想要的维度不同, 如我们这里需要计算交叉熵, 最终输出维度等于num_class=4。

import torch
"""
使用Pytorch RNN方法 训练一个模型'hello' -> 'ohlol'
使用Embedding 表示词向量
"""
class Model(torch.nn.Module):
def __init__(self, input_size, hidden_size, batch_size, embedding_size, num_class, num_layers=1):
super(Model, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.batch_size = batch_size
self.embedding_size = embedding_size
self.num_class = num_class
self.num_layers = num_layers
"""
add embedding layer
embedding shape: (input_size, embedding_size)
"""
self.emb = torch.nn.Embedding(input_size, embedding_size)
self.rnn = torch.nn.RNN(input_size=self.embedding_size, hidden_size=self.hidden_size,
num_layers=self.num_layers, batch_first=True)
self.fc = torch.nn.Linear(hidden_size, self.num_class)
def forward(self, x):
"""
Input x should be LongTensor: (batch_size, seq_len)
Input of RNN: (batch_size, seq_len, embedding_size)
Output of RNN: (batch_size, seq_len, hidden_size)
Input of FC Layer: (batch_size, seq_len, hidden_size)
Output of FC Layer: (batch_size, seq_len, num_class)
Reshape result to use Cross Entropy Loss : (batch_size * seq_len, num_class)
"""
# init h0 shape: (num_layers, batch_size, hidden_size)
hidden = torch.zeros(self.num_layers, self.batch_size, self.hidden_size)
# shape: (batch, seq_len, embedding_size)
x = self.emb(x)
x, _ = self.rnn(x, hidden)
x = self.fc(x)
x = x.view(-1, self.num_class)
return x
batch_size = 1
seq_len = 5
input_size = 4
num_class = 4
hidden_size = 8
embedding_size = 10
num_layers = 2
idx2char = ['e', 'h', 'l', 'o'] # 按照字母表顺序
# x_data shape: (batch_size, seq_len)
x_data = [[1, 0, 2, 2, 3]]
# y_data shape: (batch_size * seq_len)
y_data = [3, 1, 2, 3, 2]
inputs = torch.LongTensor(x_data)
labels = torch.LongTensor(y_data)
net = Model(input_size, hidden_size, batch_size, embedding_size, num_class, num_layers=num_layers)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.05)
for epoch in range(15):
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
_, idx = outputs.max(dim=1)
idx = idx.data.numpy()
print(f"Predicted String: {''.join([idx2char[x] for x in idx])}", end='')
print(', Epoch [%d/15] loss=%.4f' % (epoch + 1, loss.item()))
# 输出
# Predicted String: eeeeh, Epoch [1/15] loss=1.4651
# Predicted String: ollol, Epoch [2/15] loss=1.0395
# Predicted String: ohool, Epoch [3/15] loss=0.8335
# Predicted String: ohool, Epoch [4/15] loss=0.6724
# Predicted String: ohlol, Epoch [5/15] loss=0.5123
# Predicted String: ohlol, Epoch [6/15] loss=0.3649
# Predicted String: ohlol, Epoch [7/15] loss=0.2682
# Predicted String: ohlol, Epoch [8/15] loss=0.1961
# Predicted String: ohlol, Epoch [9/15] loss=0.1404
# Predicted String: ohlol, Epoch [10/15] loss=0.0982
# Predicted String: ohlol, Epoch [11/15] loss=0.0685
# Predicted String: ohlol, Epoch [12/15] loss=0.0488
# Predicted String: ohlol, Epoch [13/15] loss=0.0358
# Predicted String: ohlol, Epoch [14/15] loss=0.0270
# Predicted String: ohlol, Epoch [15/15] loss=0.0208















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









