







Batch Normalization

Abstract
训练神经网络的过程中,随着先前各层的参数发生变化,各层的输入分布也会发生变化。因此需要降低学习率、谨慎的进行参数初始化,因此训练速度会变慢,而且很难得到饱和的非线性模型。这种现象被称为 internal covariate shift。BN层就是为了解决该问题。
BN层的优点:
1.可以选择较大的学习率,使得训练速度增长的很快,具有快速收敛性,对参数初始化也不敏感;
2.在某些情况下,可以不使用Dropout和L2正则化;
3.BN层的本质是一个归一化网络层,可以替代局部响应归一化层;
4.可以打乱样本训练顺序
Introduction
使用SGD及其变体可以很好的进行神经网络的训练,但是网络训练需要谨慎的选择参数(学习率、参数初始化、权重衰减系数、Dropout的比例等),参数的选择对训练结果有很大的影响。
神经网络层输入的改变,使神经网络层必须不停的的适应新的数据分布,一个学习系统的输入分布发生变换被称为Experience covariate shift。解决这种现象的典型方法是域适应。
对于一个子网络 :
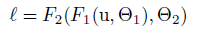
其中F1和F2是函数,通过学习参数θ_1,θ_2来最小化L。
θ_2的学习:如果X = F(u,θ_1)为子网络的输入,则 :
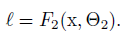
θ_2的更新为(m:批量数据的样本树,α:学习率)
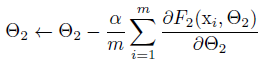
输入数据分布相同的特性可以使得网络更容易训练。这和训练数据和测试数据有相同分布是相似的。因此保持X的分布不变是有利的。
缓解 internal covariate shift的方法
在训练过程中加入归一化处理,即将输入数据变化为零均值和单位方差,并进行去相关。对网络中的每一层进行归一化处理有利于缓解 internal covariate shift。但是在求激活值后进行归一化,在反向传播的过程中传递到上一层的误差会越来越小,会造成梯度弥散的问题。
上述方法的问题在于梯度下降没有考虑归一化的情况。处理该问题,需要确保对于任何参数,神经网络都由期望分布产生激活值。这样就能确保模型参数的损失函数梯度把归一化的情况都考虑进去。
BN
因为对于每一层的输入进行归一化计算量大,而且不是处处可微,因此做两个简化:
1.对标量特征进行单独的零均值方差归一化代替对每层网络输入输出进行归一化:对于有d维输入x=(x(1),x(2),…,x^(d))的神经网络层,利用下式进行归一化:
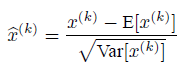
简单的归一化神经网络的输入,可能会改变该层的表征能力,例如,对于sigmoid函数的输入进行归一化,会使归一化后的输入曲线趋向s型函数的线端。为了避免这个问题,需要确保穿插在网络内部的变换能够表示同样的变换。对于每一个激活值x^(k)
都引入一对超参数λ^(k) 和β^(k),这两个参数能够缩放和平移归一化的输入:
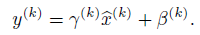
通过这两个参数可以恢复模型的表征能力。
2.在随机梯度下降中,采用mini-batch的方式,这样就能通过每个mini-batch为每个激活值计算出对应的均值和方差。通过这样的方式进行归一化所需要的统计信息能够完全被考虑到梯度下降中去。
BN层的计算流程

λ和β是需要学习的参数。BN变换不仅与单个训练样本相关,也与mini-batch中的其它训练样本有关。由缩放和平移变换而来的y作为下一层的输入。
在训练过程中需要计算经过BN层的误差,同时也要计算BN变换中涉及到的参数的误差。利用链式规则:
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









