







最近要使用UIMA来做文本挖掘相关工作,写下自己学习和使用它的过程,希望这次能坚持写。以下内容基本都是基于Apache UIMA网站上的说明或文档,具体的可以在文末的参考链接中找到。
what is UIMA
UIMA (Unstructured Information Management Architecture) 是一个用于分析非结构化内容(比如文本、视频和音频)的组件架构和软件框架实现。一个UIMA的应用示例是可以读入文本识别实体或者关系,如人名,地名,组织或者人和组织间的供职关系,人和地点间的位置关系。
这个框架的目的是为非结构化分析提供一个通用的平台,从而提供能够减少重复开发的可重用分析组件。
它的特点或优势是集成组件的功能:
UIMA 架构允许您轻松插入定制的分析组件,并将它们与其他组件合并。您的 UIMA 应用程序不需要知道分析组件共同合作生成结果的细节。集成和组织多个分析组件是 UIMA 框架的工作。
UIMA使得应用可以分解为多个组件,如 “language identification” => “language specific segmentation” => “sentence boundary detection” => “entity detection (person/place names etc.)”. 每一个组件完成由框架定义的接口并且提供用XML文件定义的自描述元数据。而框架负责管理这些组件和它们之间的数据流。组件用Java或者C++书写;而组件之间的数据流是根据这些语言之间有效地映射而设计的。
UIMA框架图:
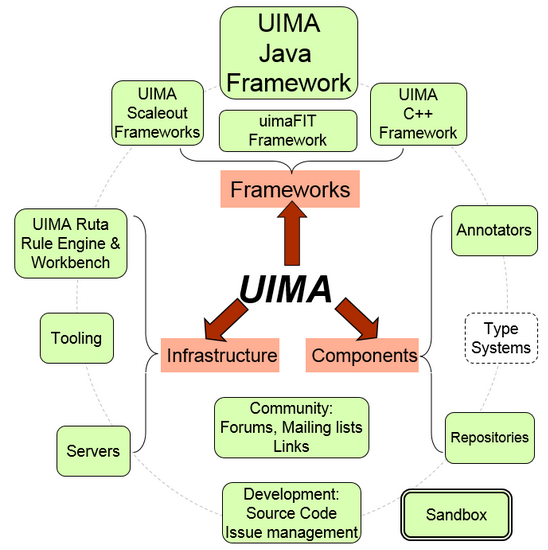
Frameworks
框架中的组件对于Java和C++都是可用的。Java构架支持Java和非Java组件(使用C++框架)。C++架构除了支持使用C/C++书写注解,而且支持Perl,Python,和TCL注解。UIMA-AS和UIMA-DUCC都是基于Java 框架下的可扩展框架。
Components
The frameworks support configuring and running pipelines of Annotator components. These components do the actual work of analyzing the unstructured information. Users can write their own annotators, or configure and use pre-existing annotators. Some annotators are available as part of this project; others are contained in various repositories on the internet.
Additional infrastructure
Additional infrastructure support components include a simple server that can receive REST requests and return annotation results, for use by other web services.
The Addons and Sandbox is for Addons (Annotators and other things) for UIMA, and a place where new ideas are developed for potential incorporation into the project.
参考
http://uima.apache.org/
http://uima.apache.org/documentation.html

















 1131
1131

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









