




一、泛化能力
泛化能力指的是训练得到的模型对未知数据的预测能力。我们建模的目的是让模型不仅对已知数据,而且对未知数据都能有较好的预测能力。对模型预测能力的评估,可以通过样本上的训练误差和测试误差来估计。这里有三个概念:
- 损失函数:度量预测错误程度的函数
- 训练误差:训练数据集上的平均损失,虽然有意义,但本质不重要
- 测试误差:测试数据集上的平均损失,反应了模型对未知数据的预测能力
我们通常利用最小化训练误差的原则来训练模型,但真正值得关心的是测试误差。一般情况下我们通过测试误差来近似估计模型的泛化能力。对于一个好的模型,其训练误差约等于泛化误差。
二、过拟合和欠拟合
1、基本概念
当机器学习模型对训练集学习的太好的时候,此时表现为训练误差很小,而泛化误差会很大,这种情况我们称之为过拟合,而当模型在数据集上学习的不够好的时候,此时训练误差较大,这种情况我们称之为欠拟合。
2、过拟合产生原因
过拟合产生的原因主要有三个:
模型记住了数据中的噪音 意味着模型受到噪音的干扰,导致拟合的函数形状与实际总体的数据分布相差甚远。这里的噪音可以是标记错误的样本,也可以是少量明显偏离总体分布的样本(异常点)。通过清洗样本或异常值处理可以帮助缓解这个问题。
训练数据过少 导致训练的数据集根本无法代表整体的数据情况,做什么也是徒劳的。需要想方设法增加数据,包括人工合成假样本。
模型复杂度过高 导致模型对训练数据学习过度,记住了过于细节的特征,如下图(来源Coursera的机器学习课程)。
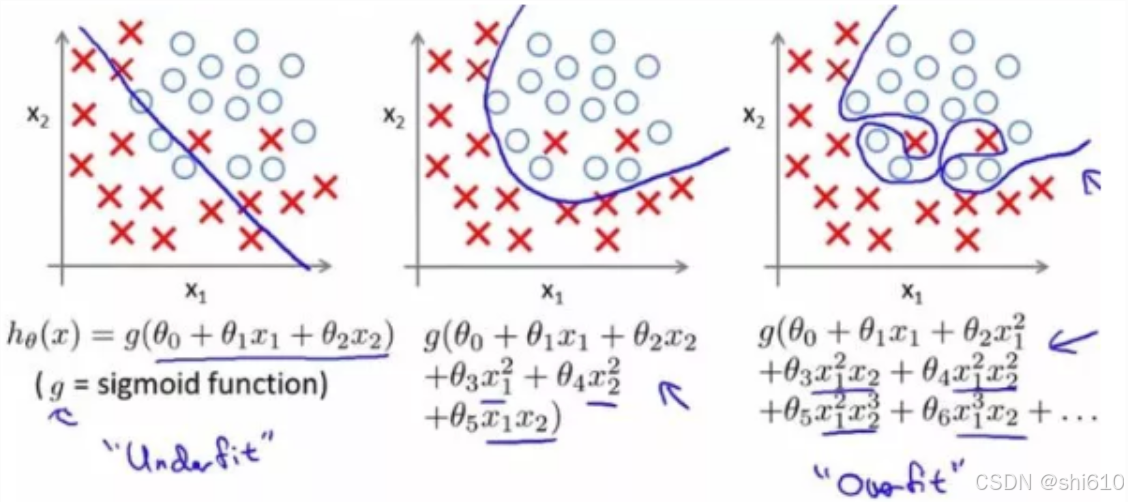
3、欠拟合产生原因
欠拟合产生的原因主要有两个:
模型过于简单 即模型形式太简单,以致于无法捕捉到数据特征,无法很好的拟合数据,如下图。在模型后加入一个二次项,拟合能力就提升了许多。
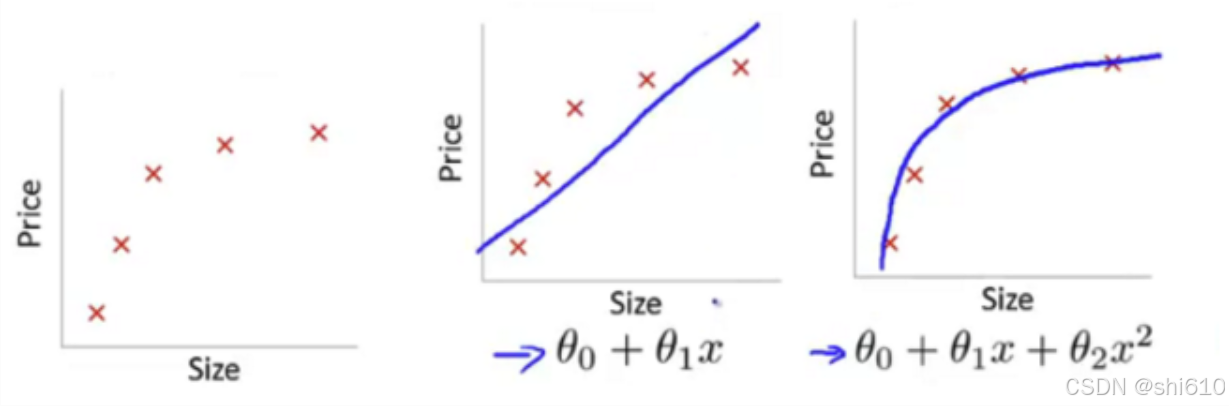 缺乏强预测能力的特征 很容易懂,可以通过组合、泛化等各种手段增加特征。
缺乏强预测能力的特征 很容易懂,可以通过组合、泛化等各种手段增加特征。
三、混淆矩阵
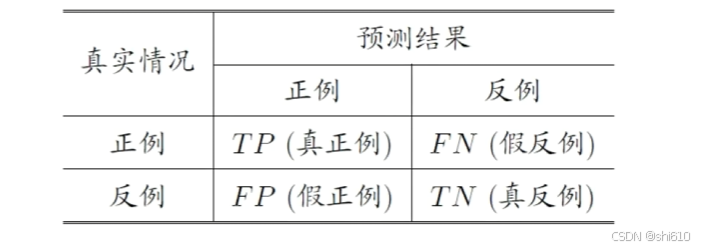
- TP: TRUE POSITIVE 分类器将正类预测为正类的数量
- FN: FALSE NEGATIVE 分类器将正类预测为负类的数量
- FP: FALSE POSITIVE 分类器将负类预测为正类的数量
- TN: TRUE NEGATIVE 分类器将负类预测为负类的数量
查准率: Precision = TP/(TP+FP),即所有被预测为正例的样本中,多少比例是真的正例。
查全率: Recall = TP/(TP+FN),即所有真的正例中,多少比例被模型预测出来了。
F1 Score:精确率和召回率的调和平均。F1认为两者同等重要。
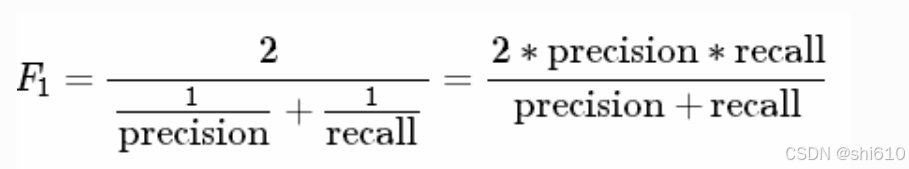
F-beta Score:F1 更一般的形式。
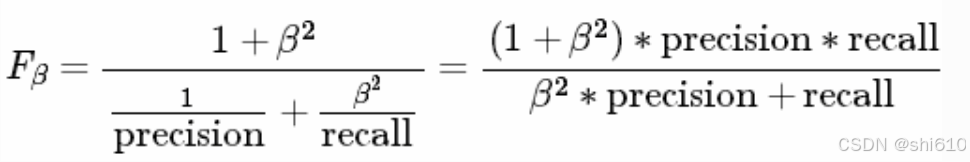
其中 Beta 度量了查全率对查准率的相对重要性。Beta大于1时,召回率更重要,在0-1之间时,精确率更重要。常用的Beta值有 2 和 0.5。
四、模型选择方法
- 留出法 Hold-out
- K 折交叉验证法 k-fold cross validation
- 留一法 Leave-One-Out cross-validation
- 分层 K 折交叉验证法 Stratified k-fold cross validation
- 自助法 bootstrapping
1.留出法
留出法(Hold-out)是最经典也是最简单的评估模型泛化能力的方式。最简单的来讲,我们把数据集分为训练集和测试集两部分,前者用来训练模型,后者用来评估模型的泛化能力。大多数情况下我们需要做参数调优以进一步的提升模型表现(即模型选择步骤),例如调节决策树模型中树的最大深度。
一般情况下,我们根据模型在测试集上的表现进行参数调优,但如果我们一直用同一份测试集作为参考来调优,最后的结果很可能使得模型过拟合于这份测试集。因此,更好的做法是将数据集切分为三个互斥的部分——训练集、验证集与测试集,然后在训练集上训练模型,在验证集上选择模型,最后用测试集上的误差作为泛化误差的估计。我们可以在验证集上反复尝试不同的参数组合,当找到一组满意的参数后,最后在测试集上估计模型的泛化能力。整个过程如下图:
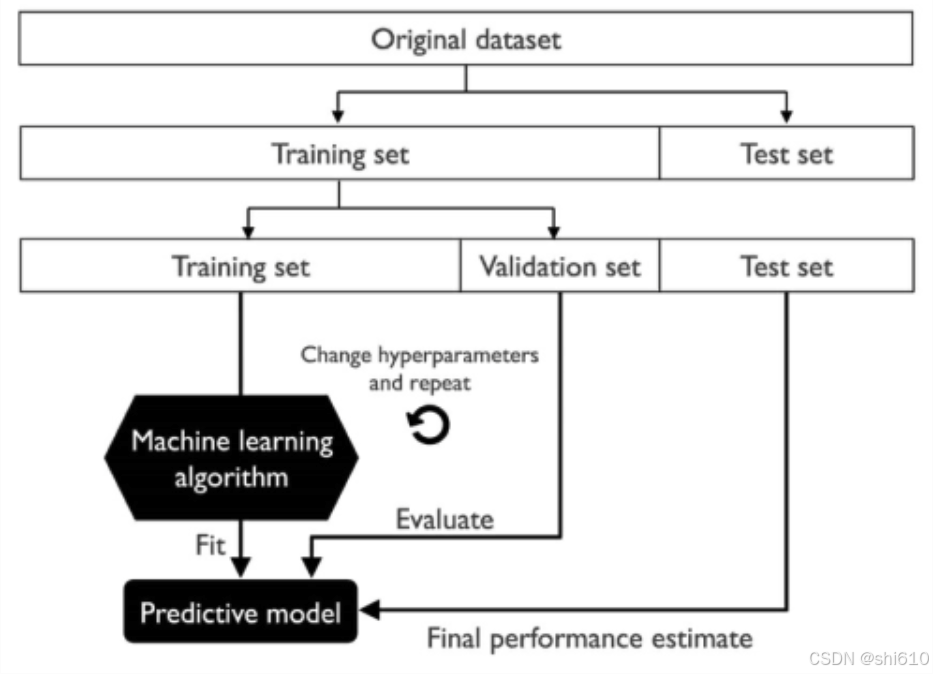
- 三部分划分比例,通常取 60%:20%:20%(或者两部分划分比例70%:30%)。如果训练集的比例过小,则得到的模型很可能和全量数据得到的模型差别很大;训练集比例过大,则测试的结果可信度降低。
- 数据集的划分要尽可能保持数据分布的一致性,避免因数据划分过程引入额外的偏差而对最终结果产生影响。若训练集、验证集、测试集中各个类别比例差别很大,则误差估计将由于训练/验证/测试数据分布的差异而产生偏差。
- 单次留出法得出的估计结果往往不够稳定可靠,通常会进行多次留出法,每次随机划分数据集,将多次得到的结果平均。
2.K折交叉验证法
K 折交叉验证法(k-fold cross validation):数据随机划分为 K 个互不相交且大小相同的子集,利用 K-1个子集数据训练模型,利用余下的一个子集测试模型(一共有 K 种组合方式,训练得到 K 个模型)。
对 K 种组合依次重复进行,获取测试误差的均值,将这个均值作为泛化误差的估计。由于是在 K 各独立的测试集上获得的模型表现平均情况,因此相比留出法的结果更有代表性。利用 K 折交叉验证得到最优的参数组合后,一般在整个训练集上重新训练模型,得到最终模型。
K 折交叉验证的优点是每个样本都会被用作训练和测试,因此产生的参数估计的方差会很小。以10折交叉验证为例(下图),对模型的泛化能力评估由10份独立的测试集上的结果平均得到。
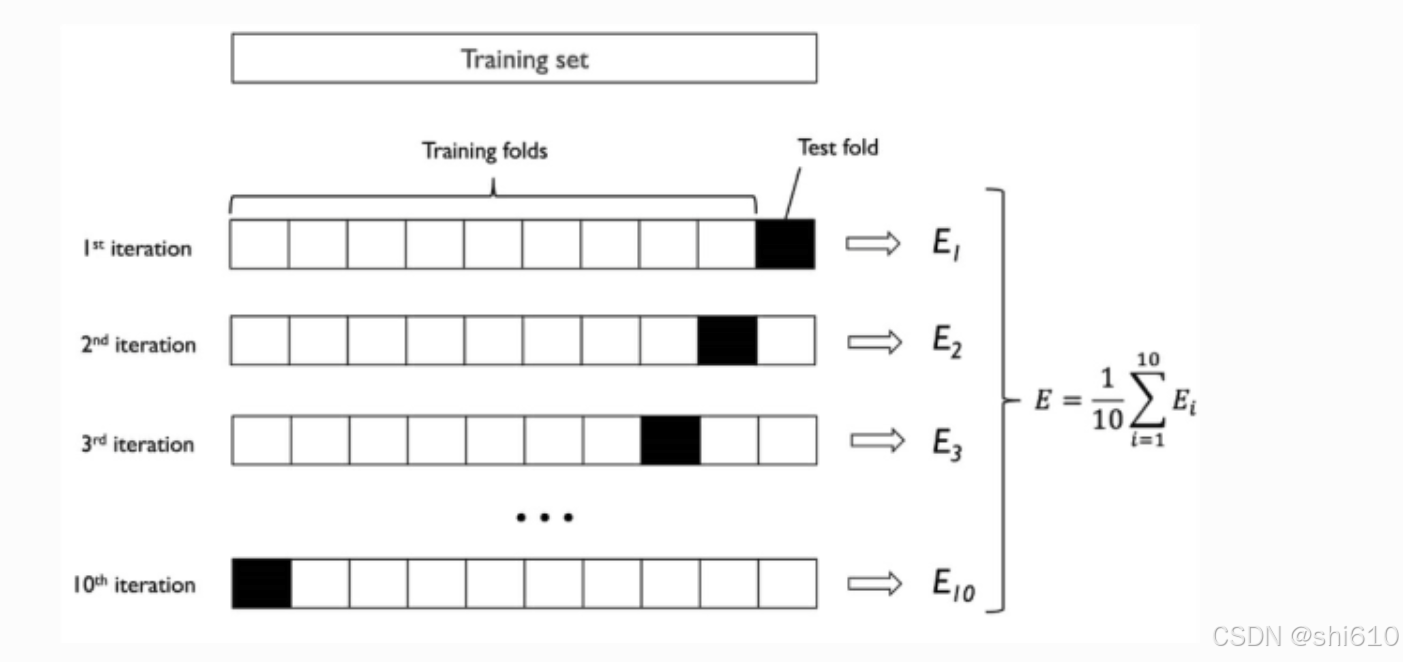
K 取太大,实验成本高,太小则实验的稳定性依然偏低。一般K取值为5或10。如果训练集数量不多,则可以再增加K的大小,这样每次训练会用到更多的样本,对泛化能力估计的偏差会小一些。
与留出法相似,将数据集划分为 K 个子集同样存在多种划分方式。为了减少因为样本划分不同而引入的差别, K 折交叉验证通常需要随机使用不同划分重复多次,多次 K 折交叉验证的测试误差均值作为最终的泛化误差的估计。
3.留一法
留一法(Leave-one-out cross validation):假设数据集中存在 N 个样本,令 K=1 则得到了 K 折交叉验证的一个特例。这个方法适合于数据集很小的情况下的交叉验证。
- 优点:由于训练集与初始数据集相比仅仅少一个样本,因此留一法的训练数据最多,模型与全量数据得到的模型最接近。
- 缺点:在数据集比较大时,训练 K 个模型的计算量太大。每个模型只有1条测试数据,无法有效帮助参数调优。
4.分层 K 折交叉验证法
如果样本类别不均衡,则常用分层 K 折交叉验证法。这个方法在进行 K 折交叉验证时,对每个类别单独进行划分,使得每份数据中各个类别的分布与完整数据集一致,保证少数类在每份数据中的数据量也基本相同,从而模型能力估计的结果更可信。
5.自助法
在留出法和 K 折交叉验证法中,由于保留了一部分样本用于测试,因此实际训练模型使用的训练集比初始数据集小(虽然训练最终模型时会使用所有训练样本),这必然会引入一些因为训练样本规模不同而导致的估计偏差。留一法受训练样本规模变化的影响较小,但是计算量太大。
自助法是一个以自助采样法(bootstrap sampling)为基础的比较好的解决方案。
自助采样法:给定包含 N 个样本的数据集 D ,对它进行采样产生数据集 D’:
- 每次随机从 D 中挑选一个样本,将其拷贝放入D’ 中,然后再将该样本放回初始数据集D 中(该样本下次采样时仍然可以被采到)。
- 重复这个过程 N 次,就得到了包含 N 个样本的数据集 D’。
显然,D 中有些样本会在 D’ 中多次出现; D 中有些样本在 D’ 中从不出现。D 中某个样本始终不被采到的概率为 (1-1/m)^m 。
根据极限:
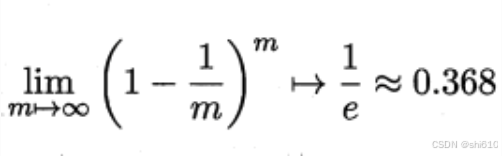
即通过自助采样,初始数据集中约有 36.8% 的样本未出现在采样数据集 D’ 中。
将 D’ 用作训练集,D-D’ 用作测试集,这样的测试结果称作包外估计 out-of-bag estimate (OOB)。
自助法在数据集较小时很有用。
- 优点:能从初始数据集中产生多个不同的训练集,这对集成学习等方法而言有很大好处。
- 缺点:产生的数据集改变了初始数据集的分布,这会引入估计偏差。因此在初始数据量足够时,留出法和折交叉验证法更常用。

















 497
497

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









