







前言
子查询可以说是select的嵌套。
主要分为以下两种基本类型:单行子查询,多行子查询。
另外,还有3种类型:多列子查询,关联子查询,嵌套子查询。
现有以下表
emp表:
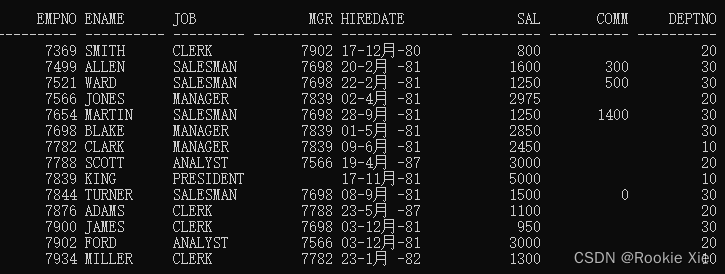
dept表:

单行子查询
内部SELECT语句给外部的SELECT语句返回0行或1行。可以在SELECT语句后面的WHERE、HAVING、FROM后面放置单行子查询。
是不是不理解什么叫“内部SELECT语句给外部的SELECT语句返回0行或1行”?
其实就是:内部SELECT语句给外部的SELECT语句返回一个值(0个值就没有意义了)
我们来看看这段语句:
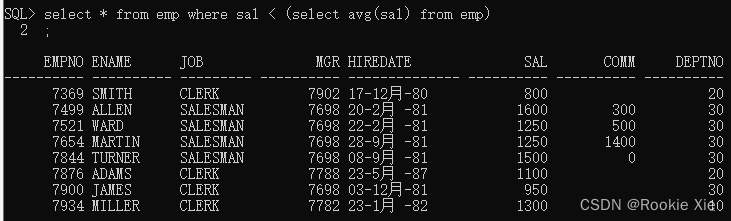
select * from emp where sal < (select avg(sal) from emp)
上面语句的意思是:查询来自emp表中sal(工资)<内部sql返回的值的所有信息;
我们把内查询语句单独拿出来看一下:
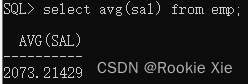
select avg(sal) from emp
“查询emp表中sal(工资)的平均值”
朋友们,什么是平均值?平均值是不是只有一个?
诶,对了。这个语句会返回单独的一个值也就是一行(在这里一行就是一个值)
接下来我们走一遍sql语句,从里向外:
首先是内查询:
然后是外查询:
观察一下外查询的结果,是不是都比内查询的平均值小?
这下你能理解什么是单行子查询了吗?
多行子查询
内部SELECT语句给外部的SELECT语句返回1行或多行
在前面我们说了单行子查询
在这里相信你应该能理解这个的意思了
不过还是要提一嘴:
也就是:内部SELECT语句给外部的SELECT语句返回n个值
在多行子查询中,我们有三个关键字,分别是:
- IN:在…之间
- ANY:任意一个
2.1:>ANY:比最小值大
2.2:<ANY:比最大值小
2.3:=ANY:跟IN一样的用法 - ALL:全部
3.1:>ALL:比最大的还大
3.2:<ALL:比最小的还小
IN关键字
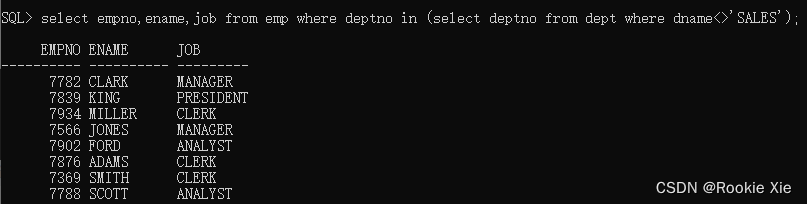
select empno,ename,job from emp where deptno in (select deptno from dept where dname<>'SALES');
//从emp表中查询部门编号等于内查询结果的empno,ename,job信息
//很拗口是吧?别急,慢慢往下看
返回结果:
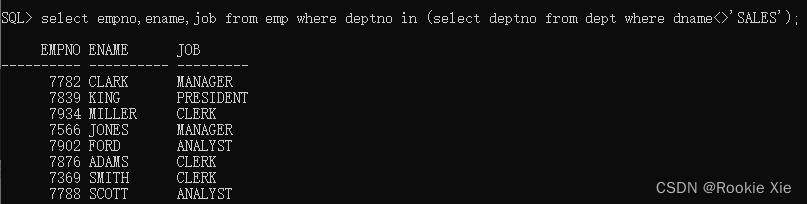
很好奇为什么会是这个对吧?那我们来拆分一下。先理解内查询的意思以及它返回的结果
select deptno from dept where dname<>'SALES'
//子查询的意思是:从dept表中查询部门名称不等于SALES的部门编号。得到以下返回值:
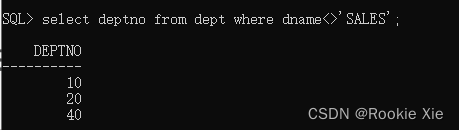
得到内结果后,把内结果带入外查询,你会得到这样一条SQL语句:
select empno,ename,job from emp where deptno in (10,20,40);
//从emp表中查询部门编号等于10,20,40的empno,ename,job信息
这下,便有了我们前面的返回结果:
any关键字
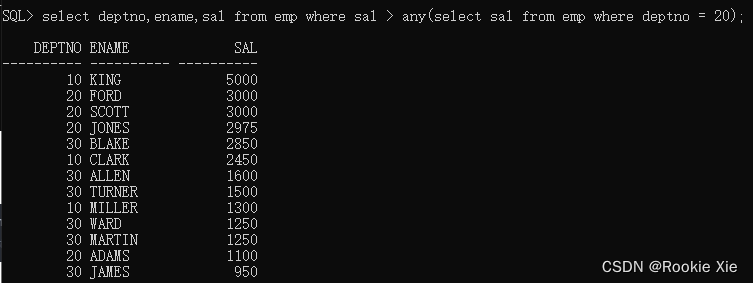
select deptno,ename,sal from emp where sal > any(select sal from emp where deptno = 20);
//从emp表中查询deptno,ename,sal信息 条件是sal大于任意内查询结果
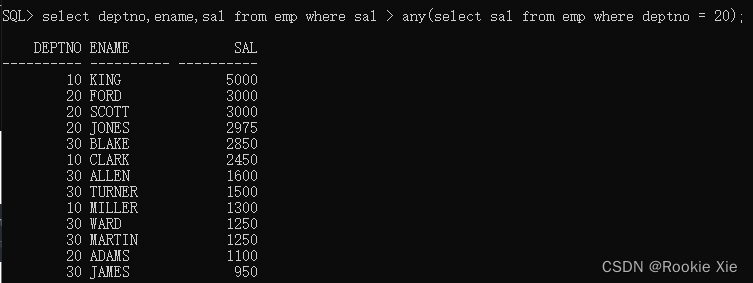
老规矩:拆就完了:
select sal from emp where deptno = 20;
//从emp表中查询deptno=20的sal信息,得到返回值
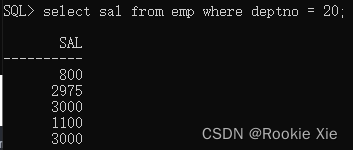
把内结果带入外查询,你会得到这样一条SQL语句:
select deptno,ename,sal from emp where sal > any(800,2975,3000,1100,3000);
//从emp表中查询deptno,ename,sal信息 条件是sal大于任意800,2975,3000,1100,3000一个,得到返回结果:
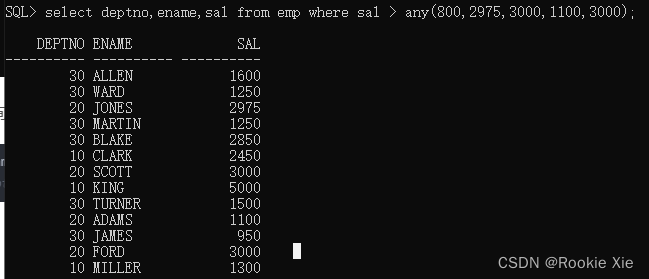
好像不太一样?不不不,他们是一样的,只是顺序乱了;可以排序一下:
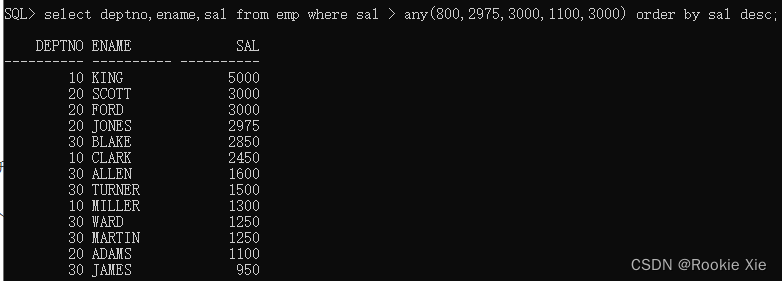
怎么样?是不是一样的?其实我们可以这样理解,大于任意结果,也就是大于最小值。
关于ANY的一些点:
”>any”就是比最小的大
”<any”就是比最大的小
”=any”和in一样用法
ALL关键字
select deptno,ename,sal from emp where sal > all(select sal from emp where deptno=30);
//从sal表查询deptno,ename,sal信息,条件是sal>所有内查询结果,得到以下结果:
先提一嘴:都要大于内查询结果,也就是说大于目标结果最大值。

拆!
select sal from emp where deptno=30;
//从emp中查询deptno=30的sal,返回:

代入!
select deptno,ename,sal from emp where sal > all(1600,1250,1250,2850,1500,950);
//从sal表查询deptno,ename,sal信息,条件是sal要比1600,1250,1250,2850,1500,950都大。得到以下结果:

再排序一下然后对比:


关于ALL的一些点:
”>all”就是比最大的还大
”<all”就是比最小的还小
至于=…你可以亲自试一下,啥都查不出
关联子查询
select empno,ename,sal from emp f where sal > (select avg(sal) from emp where job = f.job) order by job;
//从emp表中查询sal>内查结果的empno,ename,sal信息
//内查询:从emp表中查询job=f.job(f也就是emp表,在from emp f这里 f相当于emp的绰号,称为别名)的平均工资
拆!拆个头头,这不好拆
这次稍微有点麻烦,我们得先来理解一下:
在sql中,数据的查询是一行一行来的。我们来模拟一下:
假设ename=张三,empno=001,sal=4000,job=技术员。
那么在使用以上子查询时:
检索到张三这个人时,系统会去查询张三所在部门的平均工资
也就是括号里的(select avg(sal) from emp where job = f.job)
然后用张三的工资对比部门平均工资
如果比平均工资大,留下,如果比平均工资小,丢掉。
这东西…很抽象…很难用文字描述的清。不理解推荐去搜详解视频看看。















 951
951











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









