






集成学习作业:使用AdaBoost和RF来处理西瓜数据集3.0
问题1——读入数据:
1、 因为西瓜数据集是.txt格式的,因此使用pandas该如何读取.txt格式的文件呢?
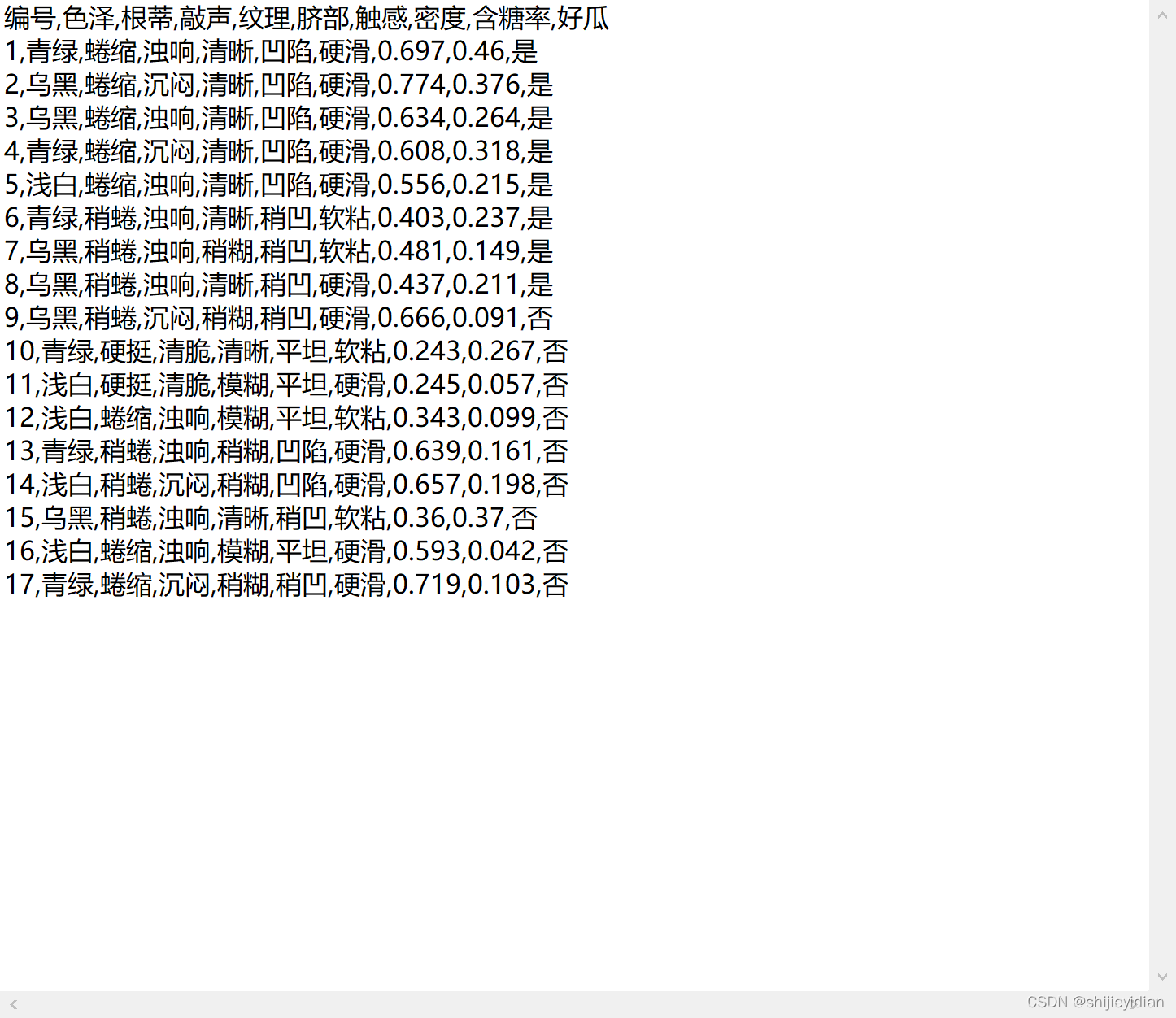
文件内容如下:
回答:
(1)我使用pandas的read_csv()函数,
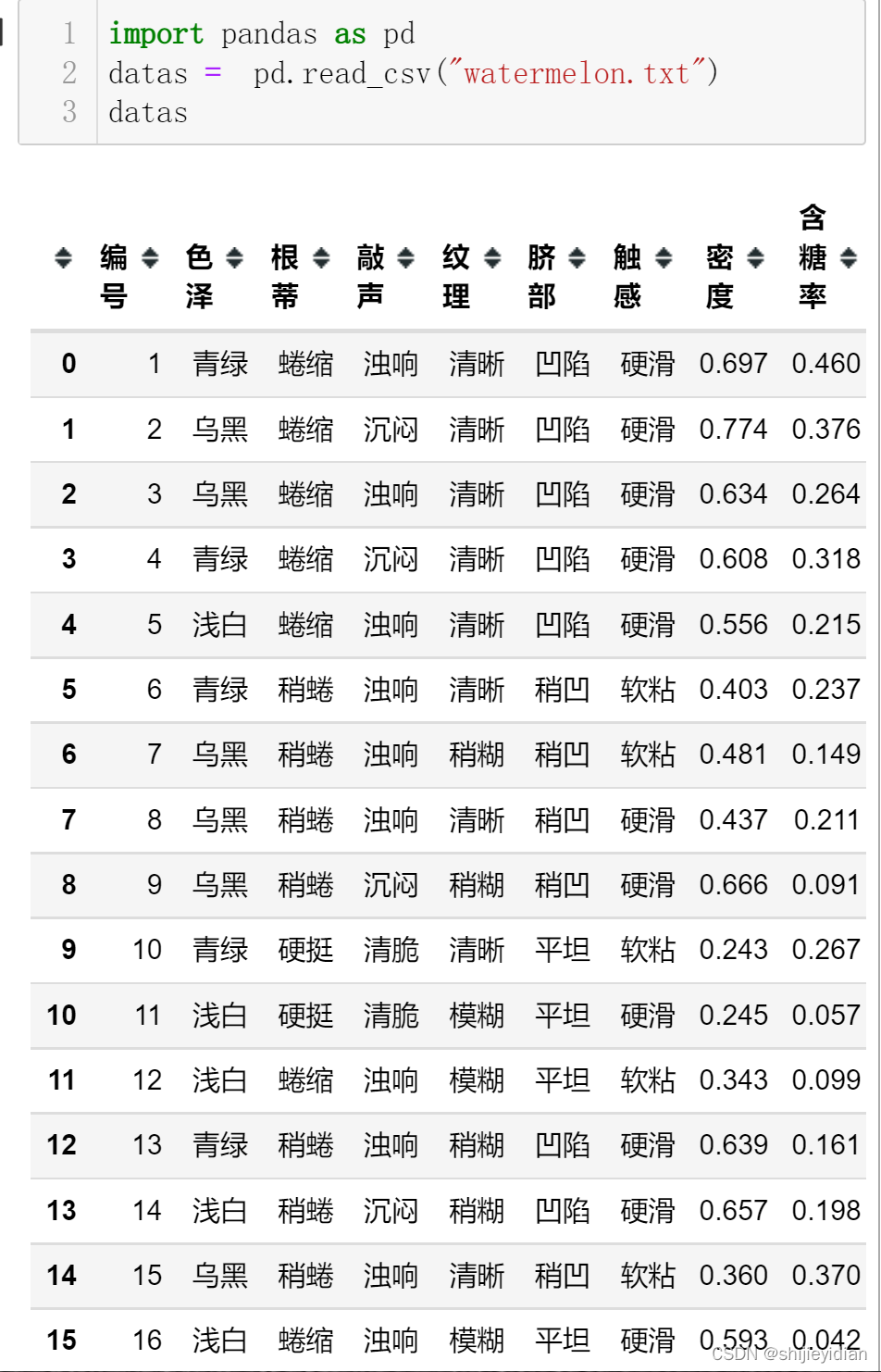
很方便,一点也不需要之前的open()函数的繁琐。只需要除去前面的序号列就可以使用。
问题二——数据预处理
我的目的是使用AdaBoost或者RF来处理这个数据集,虽然只是一个作业,但是我还是希望先采用第三方包来解决这个问题。
1、离散数据处理:
我本人不是很清楚这个使用RF进行处理的时候,中文的信息可不可以用,先试试。
刚才查看了sciki-learn的官网,才知道RandomForestClassifier的fit(X,Y)办法中,
X必须是类型为np.float32,所以不论数据是中英文,都必须转换成np.float32,所以我之前费好大劲转换成np.float64,怪不得是错的。
好,那么应该如何把字符串数据转换成32位浮点数类型的数据呢?
这个应该涉及到离散数据连续化
查阅sciki-learn官网,我明白可以使用OrdinalEncoder来对离散属性数据进行数值化,可又遇到了问题:
如何更跟array类型数据的数据类型:
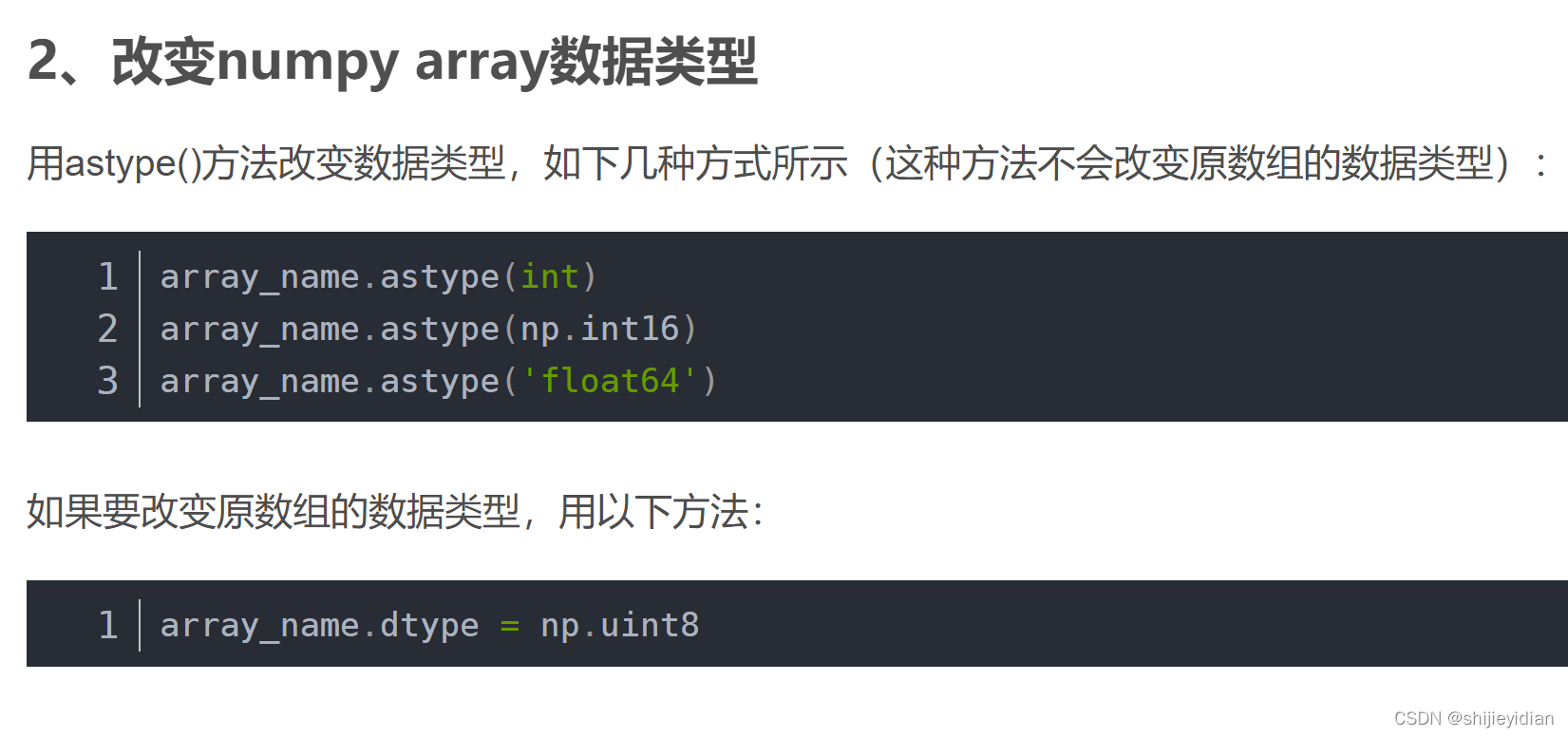
disp.dtype = np.float32
接下里要将原本离散数据(已经完成离散数据连续化)和原本的连续数据连接起来
array数据类型数据的拼接
首先把之前的连续值找出来,但是发现连续值的类型:dtype=object
使用之前的方法更改,发现出现问题
continuous_value = train[:, -2:]
continuous_value.dtype = np.float32
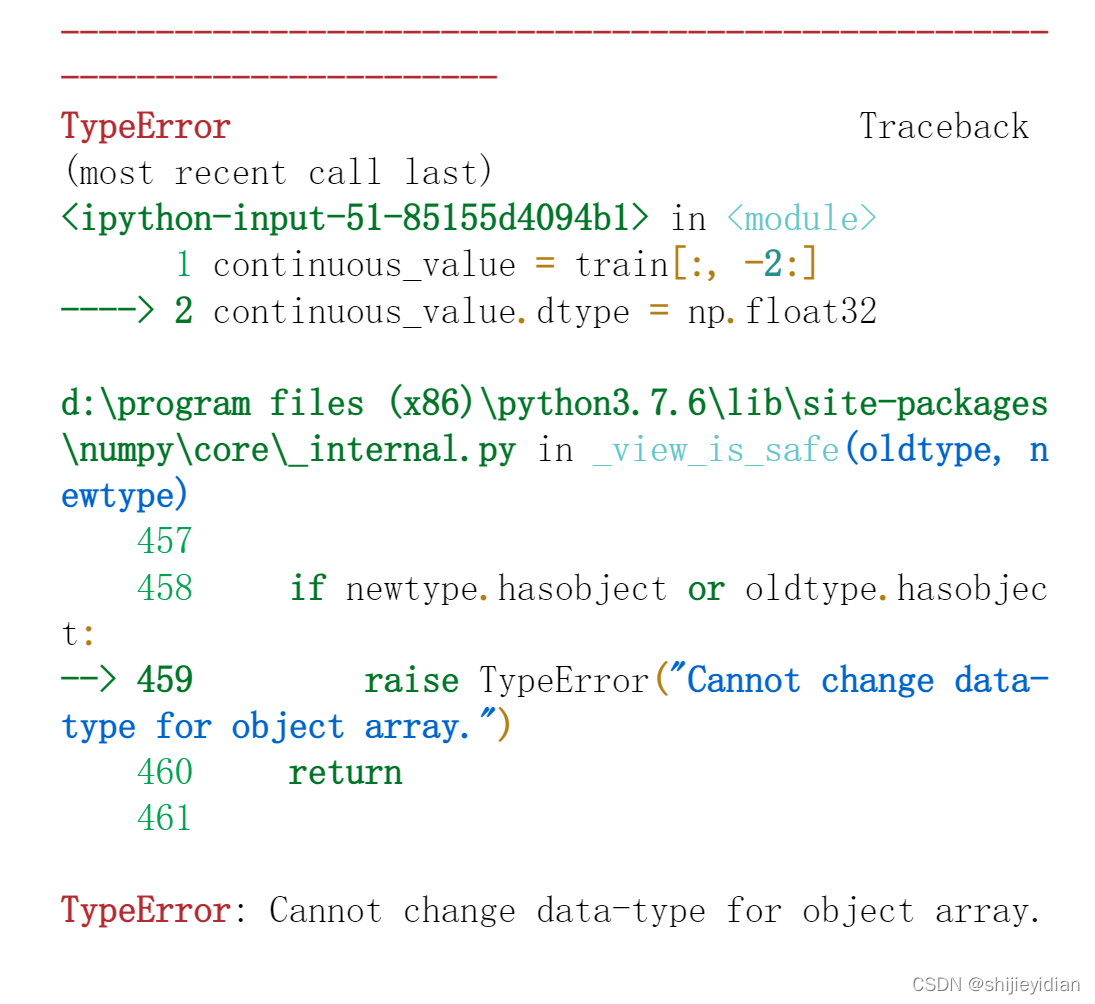
出现了:Cannot change data-type for object array.的问题。
这个是为什么?
c_v = continuous_value.astype(np.float32)
# 以后我就用这个来改变array类型
不知道为什么,这个东西采用这个方法就可以做到?暂时先把这个问题放一下。
接下来是array数组的拼接
np.hstack((disp,c_v))
成功完成数组的横轴方向拼接。
接下来就是测试/训练集的划分
from sklearn.model_selection import train_test_split
X_train,X_test,Y_train,Y_test = train_test_split(train_data,label,test_size=0.3)
# X_train:是训练集的特征
# Y_train:是训练集的标签
# X_test:是测试集的特征
# Y_test:是测试集的标签
创建随机森林:
clf.fit(X_train,Y_train)
成功了,就这么简单的训练出来了。真的太开心了,以前一直没办到的,现在我做到了。
测试创建的随机森林
1、先查看模型的输出是否正常:
clf.predict(X_test)
>>>['是' '是' '否' '是' '否' '是']
输出正常
2、在查看模型的分类精度:
clf.score(X_test,Y_test)
>>>0.6666666666666666
clf.score可以给出平均分类精度(mean accuray)

绘制ROC曲线
首先,什么是ROC曲线.
这个是个问题,我考完了考试,却没有真正明白什么是ROC曲线。
让我写下ROC曲线的定义:
ROC曲线的横坐标是FPR(假阳性率)= FP/(N)意思是学习器判断正确同时本身为负例的样例占所有负例的比值。
纵坐标FPR(真阳性率) = TP/(P) 意思是学习器判断正确同时样例是正例的样例占所有本身为正例的比例。
可以使用sklearn中的metrics中的roc_curve函数来获取一系列的坐标。
但是这个样例的判断可能性怎么考虑
就是这个模型对样本属于正例的概率输出,这个该怎么计算,看看RandomForestClassifier中有没有相关的函数.
果然,有一个predict_proba函数,可以用来计算每一个样例在二分类中属于正负两类各自的概率大小.
clf.predict_proba(X_test)
>>>array([[0.3 , 0.7 ],
[0.5 , 0.5 ],
[0.8 , 0.2 ],
[0.35, 0.65],
[0.95, 0.05],
[0.8 , 0.2 ]])
我发现array中第二个是对应着“是”,即正例的,所以应该把它提取出来.
positive = positive[:,-1]
好,开始做出ROC曲线吧。
使用roc_curve函数可以很方便的求出FPR,TPR
fpr, tpr, thresholds = roc_curve(Y_test, positive, pos_label="是")
使用同样在metrics包中的auc函数,可以将之前通过roc_curve函数计算得到的TPR,FPR输入之后,就可以得到此个ROC曲线的AUC
from sklearn.metrics import auc
Auc = auc(fpr, tpr)
>>>0.937
绘制ROC曲线
绘制曲线一直是我的短板,实在是羞愧。但是我今天发现了一个练习的好地方,那就是scikit-learn官网。我真的是以前瞎了眼睛,怎么就是不肯看一看官网有什么,真是愚蠢。
scikit-learn官网有所有机器学习函数的函数API介绍、函数使用、学习样板,真的是超过我的想象。
以下是我绘制ROC曲线的代码:
plt.figure()
lw = 2
plt.plot(fpr,tpr,color="darkorange",lw=lw,label="ROC curve (area = %0.2f)" % Auc)
plt.plot([0,1],[0,1],color="navy",lw=lw, linestyle="--")
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.ylabel("False Positive Rate")
plt.xlabel("True Positive Rate")
plt.title("Receiver operating characteristic example")
plt.legend(loc="lower right")
plt.show()
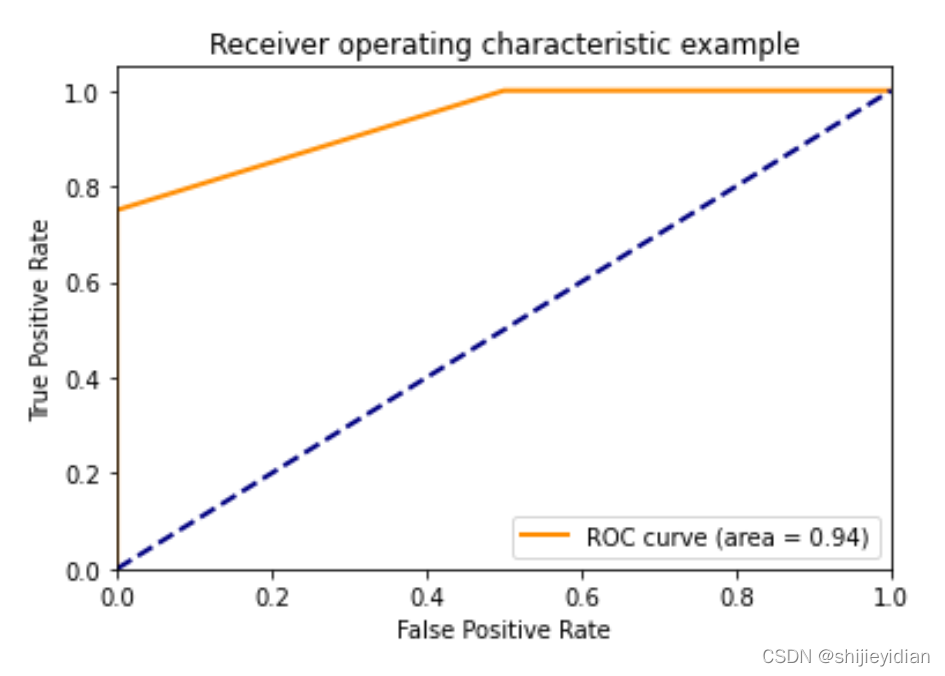
对,就是这样子,很好看,很清晰,我很满意。
接下来就是使用AdaBoost来做.
二、使用AdaBoost来对西瓜数据及进行分类
1、数据集划分
同上
2、模型训练
代码:
from sklearn.ensemble import AdaBoostClassifier
clf_A = AdaBoostClassifier(n_estimators=50, random_state=0)
clf_A.fit(X_train, Y_train)
好了,已经训练出来一个模型了,一个有着50个基学习器的AdaBoost模型
3、绘制ROC曲线,计算AUC
代码如下:
fpr_A, tpr_A, thresholds = roc_curve(Y_test, A, pos_label="是")
计算AUC值:
auc = auc(fpr_A, tpr_A)
>>> 0.6785
绘制ROC曲线:
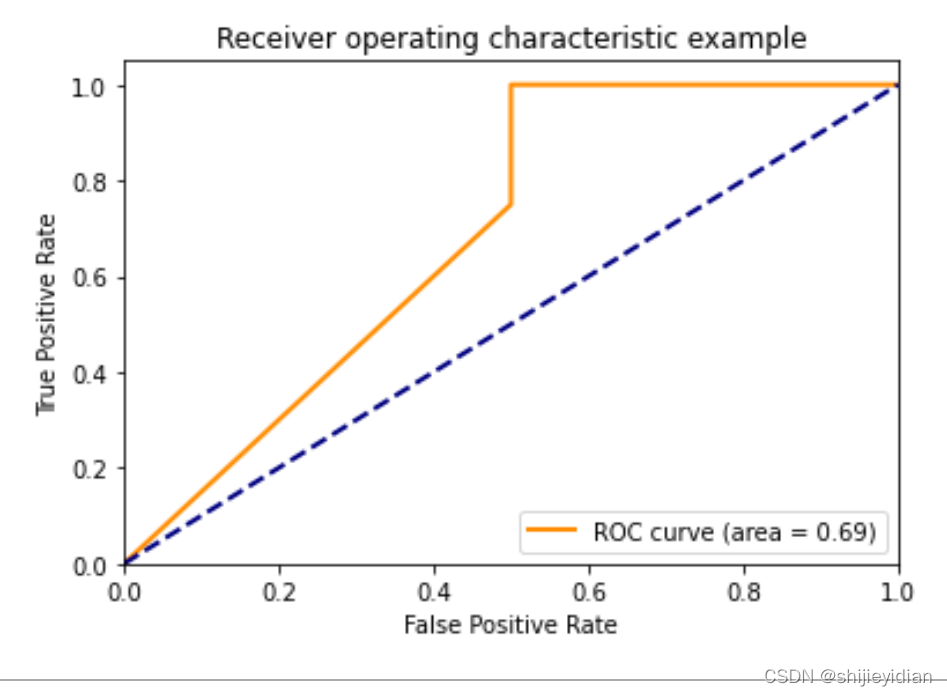
代码如下:
plt.figure()
lw = 2
plt.plot(fpr_A,tpr_A,color="darkorange",lw=lw,label=" ROC curve (area = %0.2f)" % auc)
plt.plot([0,1],[0,1],color="navy",lw=lw, linestyle="--")
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.ylabel("True Positive Rate")
plt.xlabel("False Positive Rate")
plt.title("Receiver operating characteristic example")
plt.legend(loc="lower right")
plt.show()
好了,现在我要把所有的代码都整理一遍,用pycharm完整写一遍。这样子能清晰很多.
好,现在是第三部分,要在pycharm上在把程序整体化一遍
出了点问题。
问题1:为什么pycharm上的sklearn中没OrdinalEncoder?
我初步认定是我pycharm中的scikit-learn包太老土了,我要升级一下。那我先升级。顺便现在网上查一查问题来源。
看样子是版本太旧,我pycharn中scikit-learn才0.19,但是现在都1.01了,所以我需要在Anaconda中将scikit-learn重新更新一遍(可恨的pycharm,更新总出错)。
可恨,Anaconda慢的要死,还是需要我在交互端自己用命令方式来更新.
使用Anaconda Propmt来就快多了,直接使用
pip uninstall scikit-learn
pip install scikit-learn
然后就好了,我就有了OrdinalEncoder?
奇怪了,那为什么jupyter上就可以?
管他呢,我先把所有的代码整理出来
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_curve
from sklearn.metrics import auc
from sklearn.preprocessing import OrdinalEncoder
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import AdaBoostClassifier
import matplotlib.pyplot as plt
def RandonForest(X_Train,X_test,Y_train,Y_test):
rfc = RandomForestClassifier(n_estimators=50)
rfc.fit(X_Train,Y_train)
score = rfc.score(X_test,Y_test)
positive = rfc.predict_proba(X_test)[:,-1]
fpr,tpr,thresholds = roc_curve(Y_test, positive,pos_label="是")
Auc = auc(fpr, tpr)
return score, fpr, tpr, thresholds, Auc
def AdaBoost(X_Train, X_test, Y_train, Y_test):
abc = AdaBoostClassifier(n_estimators=50)
abc.fit(X_Train, Y_train)
score = abc.score(X_test, Y_test)
positive = abc.predict_proba(X_test)[:, -1]
fpr, tpr, thresholds = roc_curve(Y_test, positive, pos_label="是")
Auc = auc(fpr, tpr)
return score, fpr, tpr, thresholds, Auc
def ROC(fpr, tpr, Auc):
plt.figure()
lw = 2
plt.plot(fpr, tpr, color="darkorange", lw=lw, label="ROC curve (area = %0.2f)" % Auc)
plt.plot([0, 1], [0, 1], color="navy", lw=lw, linestyle="--")
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.ylabel("True Positive Rate")
plt.xlabel("False Positive Rate")
plt.title("Adaboost")
plt.legend(loc="lower right")
plt.show()
def Preprocessing(name):
raw_data = pd.read_csv(name)
data = raw_data.values
data = data[:,1:]
label = data[:,-1]
train = data[:,:-1]
disp = train[:,:-2]
c_v = train[:,-2:]
enc = OrdinalEncoder()
enc.fit(disp)
disp_data = enc.transform(disp)
disp_data = disp_data.astype(np.float32)
c_v = c_v.astype(np.float32)
train_data = np.hstack((disp_data, c_v))
X_train,X_test,Y_train, Y_test = train_test_split(train_data, label, train_size=0.7)
return X_train,X_test,Y_train,Y_test
def main():
name = "D:\\ML\\Datasets\\watermelon\\watermelon.txt"
X_train,X_test,Y_train,Y_test = Preprocessing(name)
score_RF, fpr_RF, tpr_RF, thresholds_RF, Auc_RF = RandonForest(X_train,X_test,Y_train,Y_test)
score_AD, fpr_AD, tpr_AD, thresholds_AD, Auc_AD = AdaBoost(X_train,X_test,Y_train,Y_test)
ROC(fpr_RF,tpr_RF,Auc_RF)
ROC(fpr_AD,tpr_AD,Auc_AD)
if __name__ =="__main__":
main()














 2300
2300











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









