







 NLPIR分词工具利用N-最短路径算法进行中文词语粗分,该算法通过构造有向无环图并应用Dijkstra扩展找到最短路径。在实际应用中,通过为边分配词出现概率作为权重来优化处理长字串和大量相等长度路径的问题。
NLPIR分词工具利用N-最短路径算法进行中文词语粗分,该算法通过构造有向无环图并应用Dijkstra扩展找到最短路径。在实际应用中,通过为边分配词出现概率作为权重来优化处理长字串和大量相等长度路径的问题。
N-最短路径是中科院分词工具NLPIR进行分词用到的一个重要算法,张华平、刘群老师在论文《基于N-最短路径方法的中文词语粗分模型》中做了比较详细的介绍。该算法算法基本思想很简单,就是给定一待处理字串,根据词典,找出词典中所有可能的词,构造出字串的一个有向无环图,算出从开始到结束所有路径中最短的前N条路径。因为允许相等长度的路径并列,故最终的结果集合会大于或等于N。
根据算法思想,当我们拿到一个字串后,首先构造图,接着针对图计算最短路径。下面以一个例子“他说的确实在理”进行说明,开始为了能够简单说明,首先假设图上的边权值均为1。
先给出对这句话的3-最短路径求解过程图:
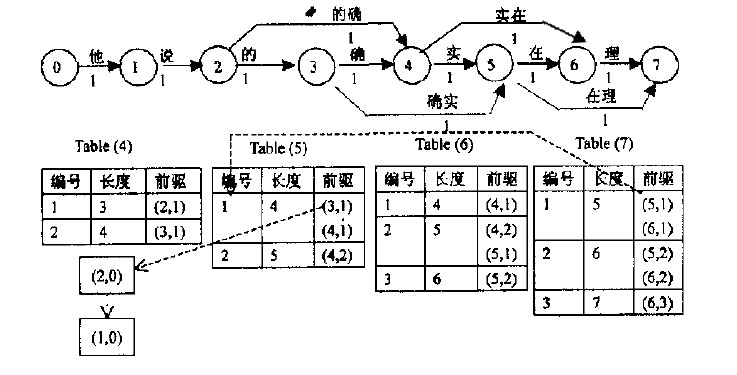
首先看图中上方,它是根据一个已有词典构造出的有向无环图。它将字串分为单个的字,每个字用图中相邻的两个结点表示,故对于长度为n的字串,需要n+1个结点。两节点间若有边,则表示两节点间所包含的所有结点构成的词,如图中结点2、3、4构成词“的确”。
图构造出来后,接下来就要计算最短路径,N-最短路径是基于Dijkstra算法的一种简单扩展,它在每个结点处记录了N个最短路径值与该结点的前驱,具体过程如上图中下方列表。Table(4)表示位于结点4时的最短路径情况,表示从结点0到4有两条路径,长度为3的路径前驱为2;长度为4的路径前驱为3。前驱括号里面第二个数表示对相同前驱结点的区分,如(4,1)、(4,2)。由列表可知,该字串的3-最短路径结果集合为{5,5,6,6,7}。
当然,在实际情况中,权值不可能都设为1的,否则随着字串长度n和最短路径N的增大,长度相同的路径数将会急剧增加。为了解决这样的问题,我们需要通过某种策略为有向图的边赋权重,很自然的想法就是边的权重就是该词出现的可能性。
设原始输入字串为C,可能划分的词串为 Wi,i=1,2,...,m ,表示对字串C有m中可能的划分。我们要求的即使概率 P(Wi
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1034
1034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









