









 DeepLab系列算法从v1到v3+,不断优化语义分割技术。通过空洞卷积解决分辨率降低问题,引入ASPP模块捕捉多尺度信息,利用全连接CRF增强细节捕捉能力。最终版本结合encoder-decoder架构,引入分离卷积平衡精度与效率。
DeepLab系列算法从v1到v3+,不断优化语义分割技术。通过空洞卷积解决分辨率降低问题,引入ASPP模块捕捉多尺度信息,利用全连接CRF增强细节捕捉能力。最终版本结合encoder-decoder架构,引入分离卷积平衡精度与效率。
1. DeepLab v1
SEMANTIC IMAGE SEGMENTATION WITH DEEP CONVOLUTIONAL NETS AND FULLY CONNECTED CRFS
2015 年的ICLR上提出
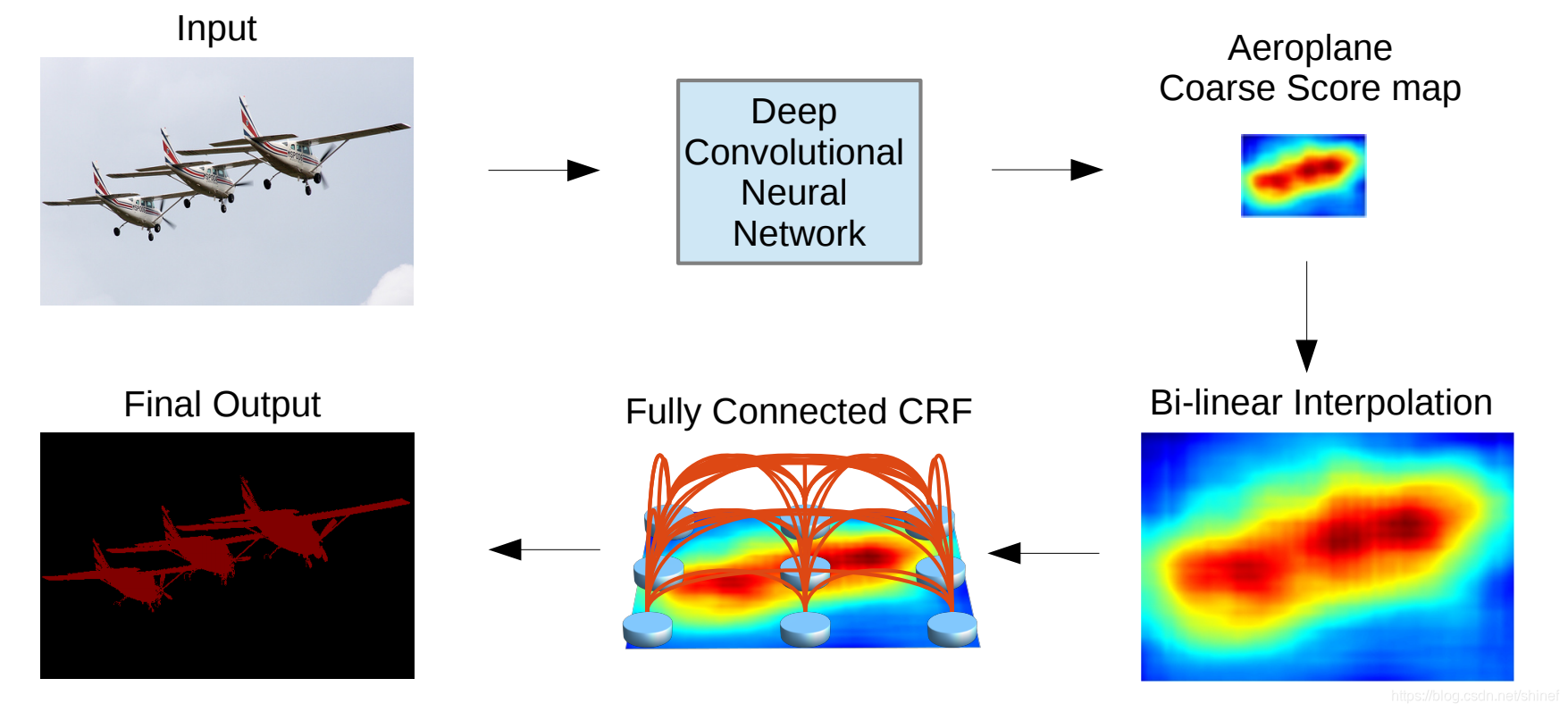
DeepLab 是结合了深度卷积神经网络(DCNNs)和概率图模型(DenseCRFs)的方法。
在实验中发现 DCNNs 做语义分割时精准度不够的问题,根本原因是 DCNNs 的高级特征的平移不变性,即高层次特征映射,根源于重复的池化和下采样。
针对信号下采样或池化降低分辨率,DeepLab 采用的空洞卷积算法扩展感受野,获取更多的语境信息。
采用完全连接的条件随机场(CRF)提高模型捕获细节的能力,简单来说,就是对一个像素进行分类的时候,不仅考虑DCNN的输出,而且考虑该像素点周围像素点的值,这样语义分割结果边界清楚。
除空洞卷积和 CRFs 之外,论文使用的 tricks 还有 Multi-Scale features,与FCN skip layer类似,具体实现上,在输入图片与前四个 max pooling 后添加卷积层,这四个预测结果和模型输出拼接。
模型流程:
2. DeepLab v2
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
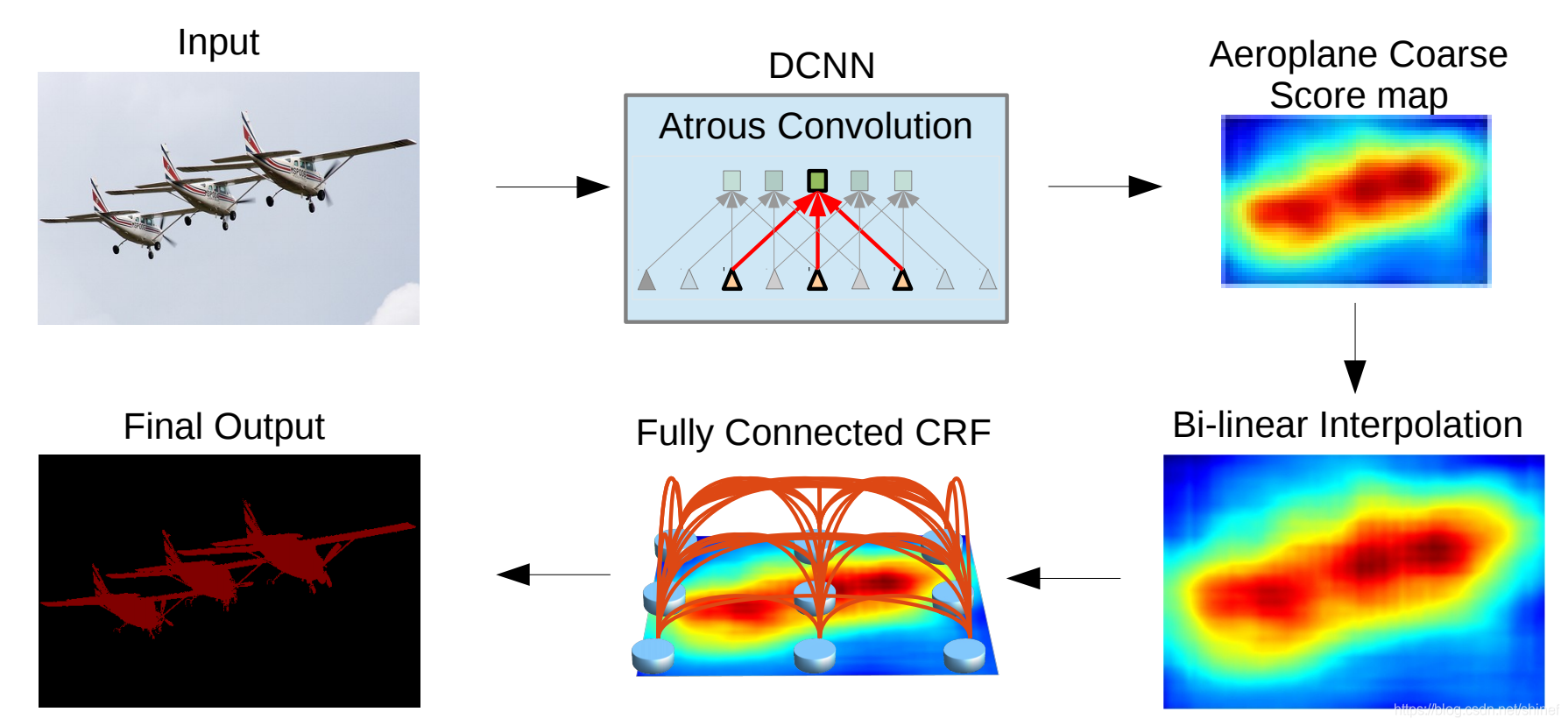
DCNN 连续池化和下采样造成分辨率降低,DeepLabv2 在最后几个最大池化层中去除下采样,取而代之的是使用空洞卷积,以更高的采样密度计算特征映射。
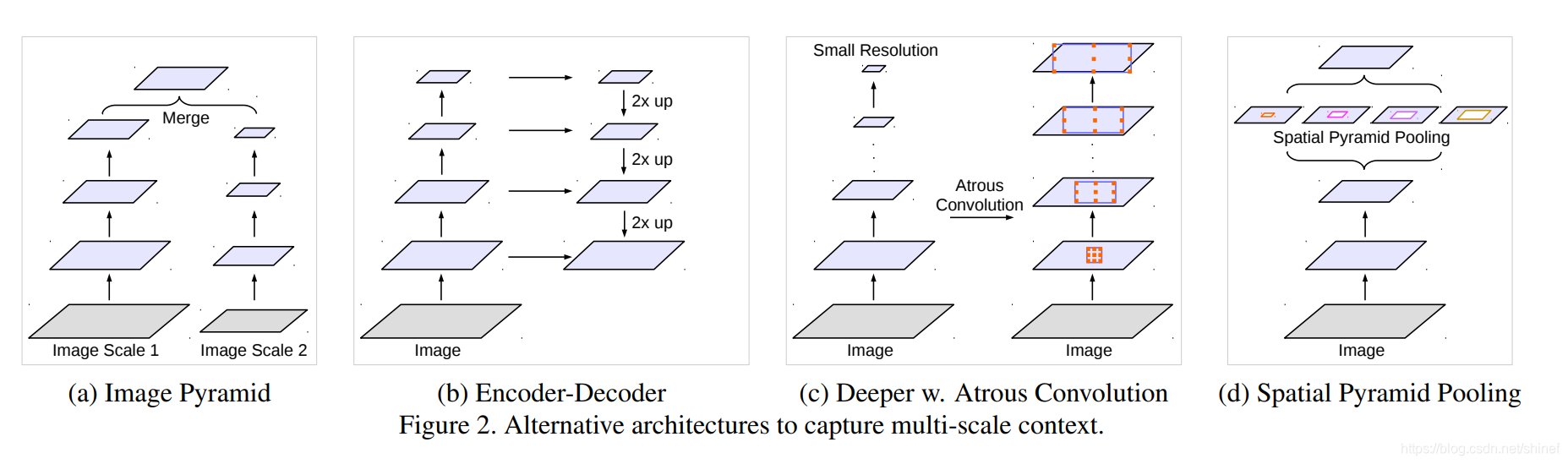
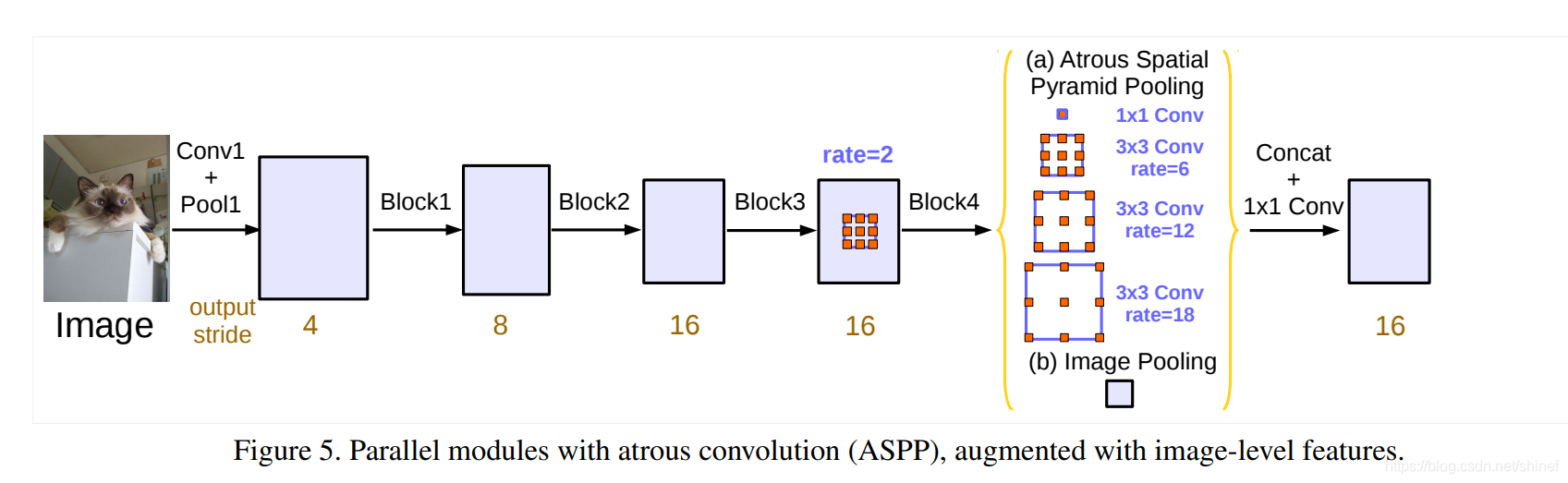
基于 Spatial Pyramid Pooling (SPP) ,在给定的输入上以不同采样率的空洞卷积并行采样,相当于以多个比例捕捉图像的上下文,该论文称为 ASPP (atrous spatial pyramid pooling) 模块。
关于条件随机场,DeepLabv2 是采样全连接的 CRF 在增强模型捕捉细节的能力
问题:特征分辨率的降低、物体存在多尺度,DCNN 的平移不变性。
系统流程:
ASPP模型:

3. DeepLab v3
Rethinking Atrous Convolution for Semantic Image Segmentation
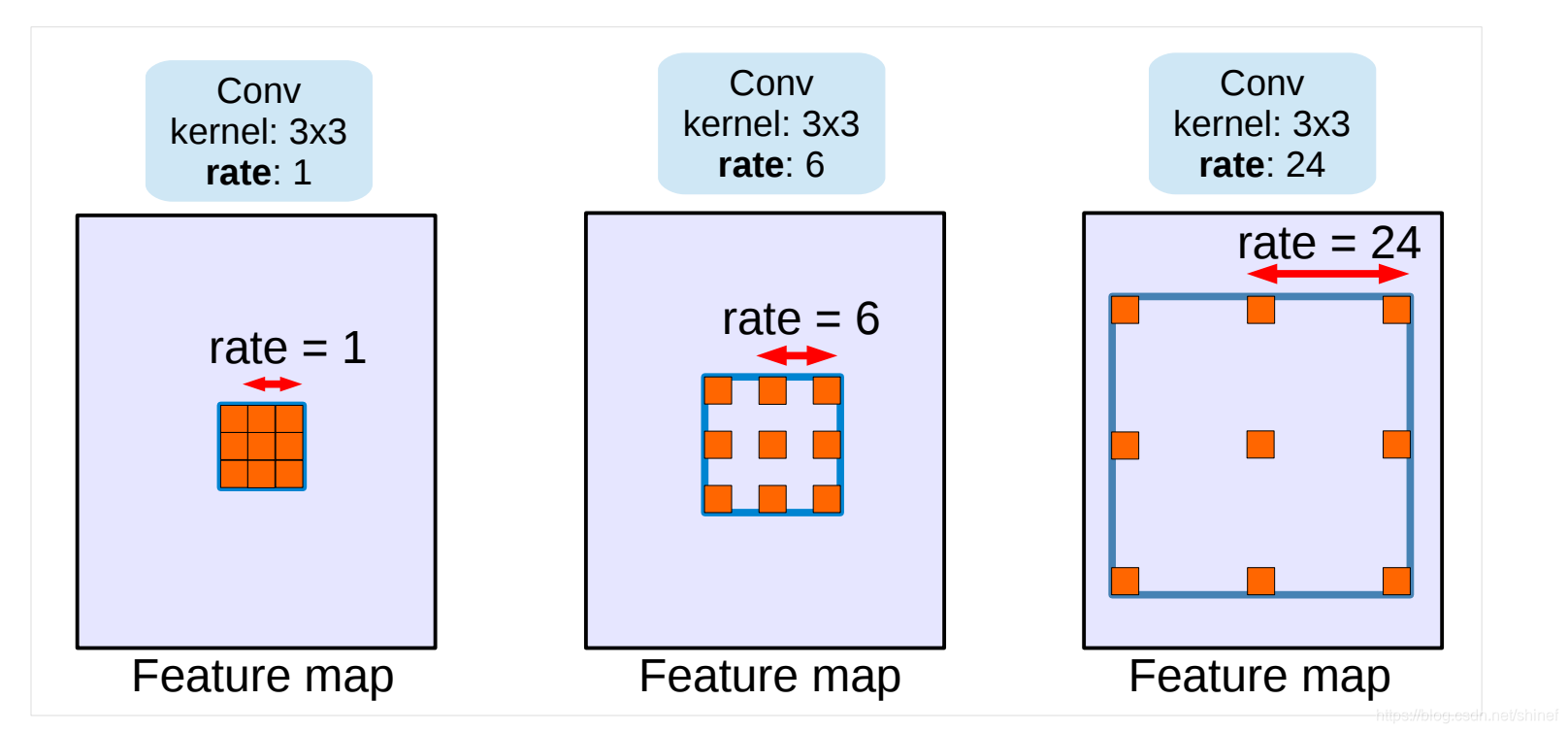
DeepLabv3 设计采用多比例的空洞卷积级联或并行来捕获多尺度背景,并且修改了空洞空间金字塔池化模块。
但是CRF就没有用了。
空洞卷积示意:
提取多尺度信息网络选择:
4. DeepLab v3+
Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
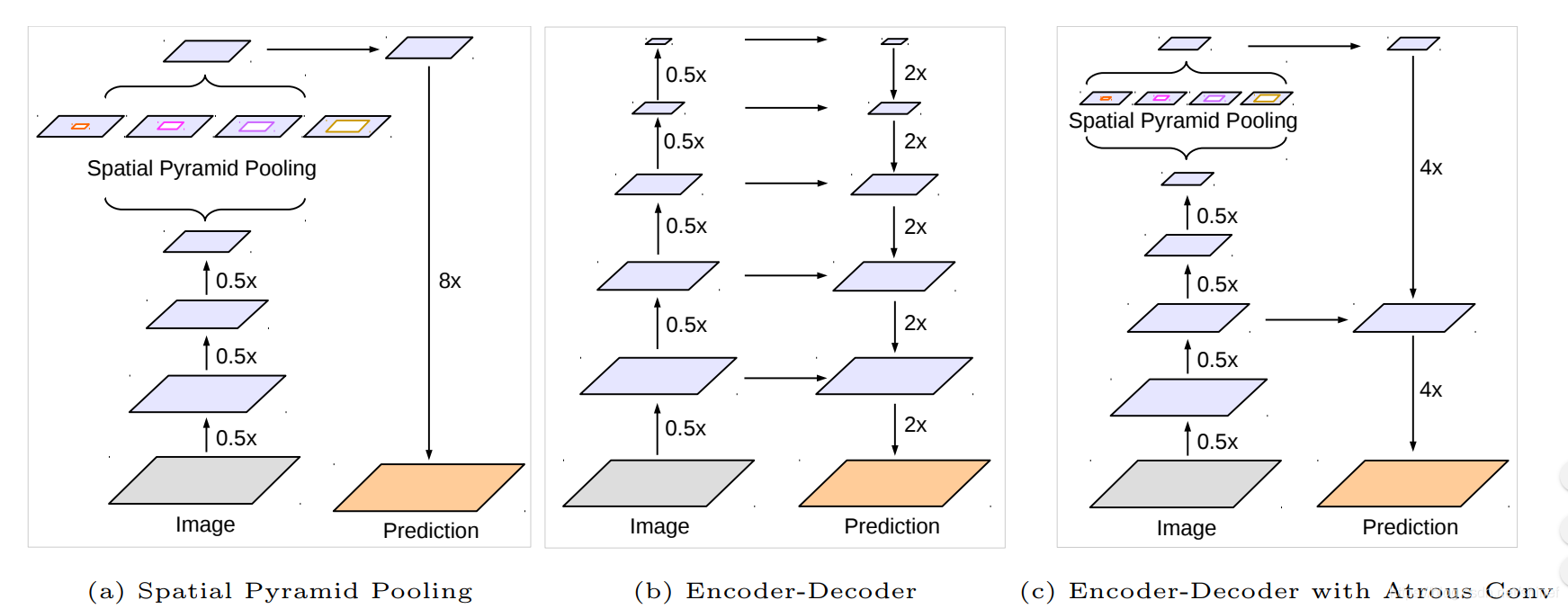
为了融合多尺度信息,引入语义分割常用的 encoder-decoder,同时引入可任意控制编码器提取特征的分辨率,通过空洞卷积平衡精度和耗时。
网络结构如下:
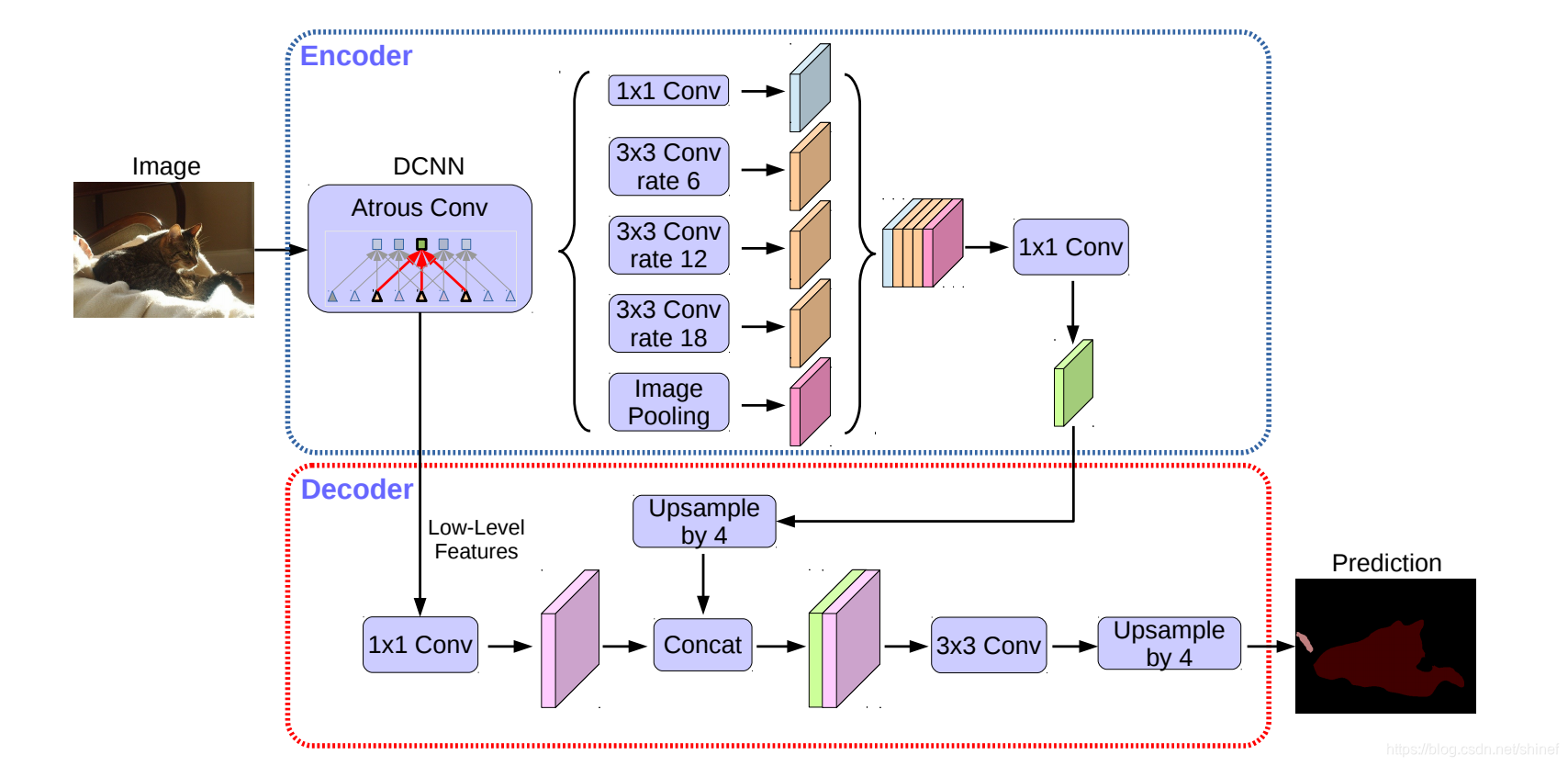
编码器提出特征:
总结
DeepLabv1-v3+ 没有用很多 tricks,都是从网络架构中调整,主要是如何结合多尺度信息和空洞卷积

















 849
849

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









