






压缩音频文件可减小文件的大小,从而更轻松地上传到其他平台,或轻松的通过电子邮件进行分享。除此之外,压缩音频文件还可以节省硬盘上的储存空间。那MP3音频文件体积怎么缩小呢?继续阅读可查看压缩的详细流程。
什么是音频文件压缩?
音频文件压缩意味着简单地减小音频文件大小,同时保持原始数据完整。关键是您可以节省存储空间,并且可以更轻松地将文件传输给其他人。
压缩的第一种方法:使用金狮视频助手
金狮视频助手是一款多功能音视频编辑工具,它包含视频压缩、合并、剪辑,以及音频文件的压缩。要在Windows/macOS上压缩音频文件,应首先安装此音频压缩软件,因金狮视频助手是压缩速度很快的音视频文件工具之一,受到了很多用户的喜爱。
第一步:打开你电脑上安装的金狮视频助手,如果没有此软件,可先在官网进行下载安装再将其打开。软件打开后,可在首界面看到4个模块,我们点击“工具”模块,在此模块中找到“音频压缩”小工具,然后点击它。
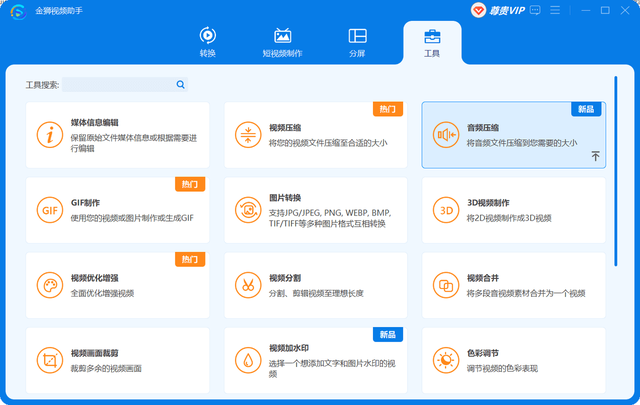
第二步:此时将弹出添加音频文件的界面,点击“+”将需要压缩的MP3音频文件添加进来。
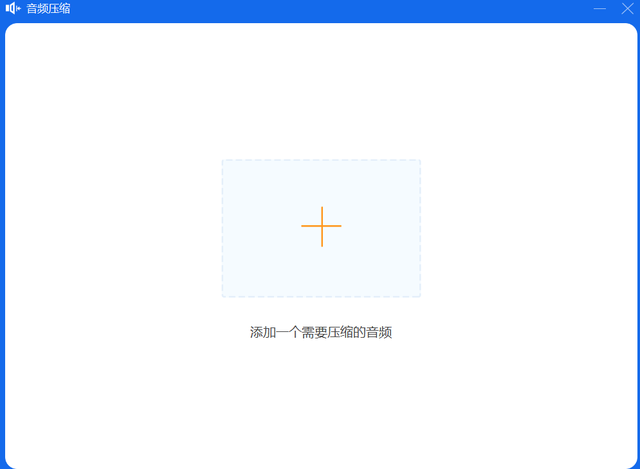
第三步:MP3音频文件添加进来后,我们可以通过更改音频的比特率、采样率、声道来缩小 MP3 文件。你还可以设置比特率预设或自定义比特率以获得更好的压缩效果。
设置好后,点击右下角的“压缩”按钮即可压缩MP3音频文件。
压缩的第二种方法:使用VLC播放器
如果你在电脑上安装了 VLC 作为媒体播放器,则还可以将其用作基本的压缩工具。虽然 VLC 在音频压缩方面提供的选项比金狮视频助手少,步骤多,但如果你电脑有此款软件又不想安装第三方软件,是可以尝试下的。
第一步:启动 VLC,转到媒体 > 转换/保存选项。(快捷键是 Ctrl + R,Mac 为 cmd+R)
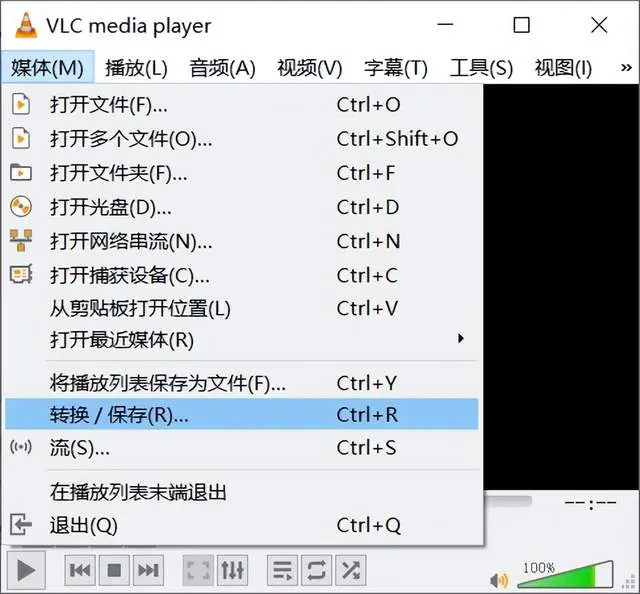
第二步:在文件选择中,添加要压缩的音频文件,然后单击转换/保存按钮。

第三步:在新弹出的转换窗口中,管理音频压缩设置。
①在配置文件中,选择音频-MP3,然后单击扳手图标。
②单击“音频编解码器”选项卡,然后调整采样率。您可以在 VLC 中选择 8000 Hz、11025 Hz、22050 Hz、44100 Hz 和 48000 Hz。由于您想将音频压缩为更小的尺寸,因此可以使用 44100 Hz 以下的频率。
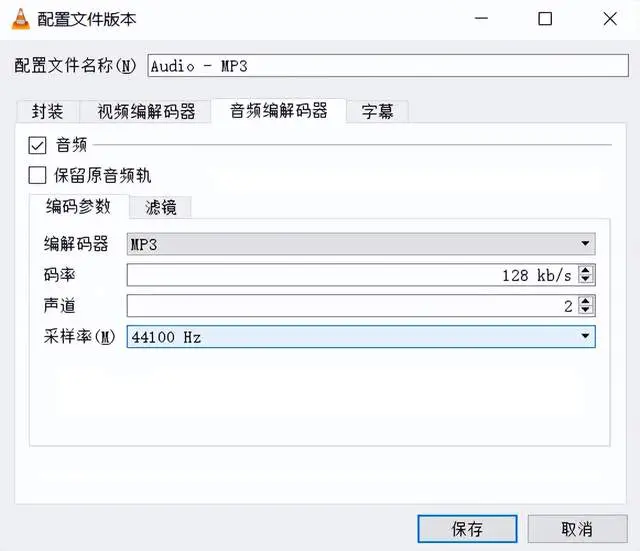
③您可以将比特率保留为 128 kb/s。
第四步:单击保存以保存配置文件的设置。
第五步:单击“浏览”指定输出文件夹。
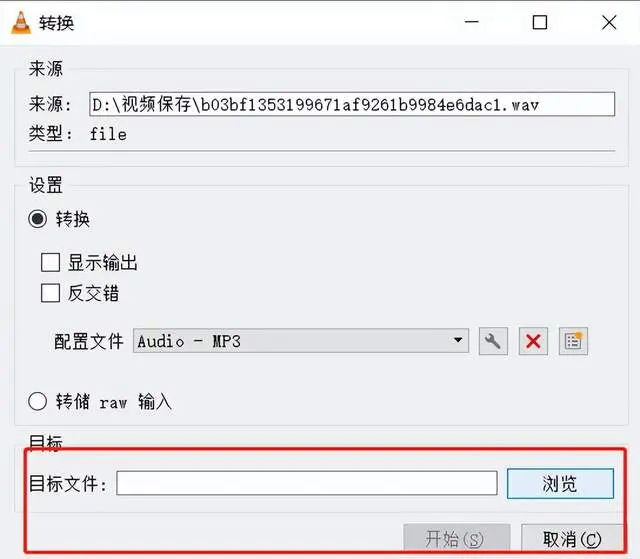
第六步:单击开始压缩音频文件即可。
总结
阅读完这篇文章后,相信你已经了解到了什么是音频文件压缩,以及如何去压缩。本文提供了2种压缩MP3音频文件的方法,你可以选择其中一种进行操作。金狮视频助手相比于VLC操作简单,但如果你不想安装第三方软件且电脑又装有VLC的话,也是可以直接使用VLC去进行压缩的,就是步骤有那么一点点繁琐。

















 1234
1234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









