







前言
上一节我们学习了无监督降维方法PCA,在学习PCA的输入数据时我们了解一些数据处理的方法,其中提到了非结构化数据如何转化成结构化数据的方法序号编码,独热编码,二进制编码以及encoding编码。本节将讲述Categorical Embedder方法,如何通过神经网络编码分类变量将非结构化指标映射为浮点数张量,进而满足神经网络输入需求。
1.神经网络的数据预处理
机器学习模型离不开数据的预处理,预处理对于构建网络模型同样非常重要往往能决定训练结果,对于不同的数据集,预处理方法都会有或多或少的局限性和特殊性,特别是神经网络输入数据仅支持浮点数张量。无论处理什么数据(声音,图像还是文本),都需要将其转化为张量,然后再提供给神经网络模型。当我们遇到比如这些数据可以通过序号编码(Ordinal Encoding)、独热编码(One-hot Encoding)、二进制编码 (Binary Encoding)等方法将其转化为数字。接下来介绍一种更为先进的神经网络编码方法。
2.什么是embedding
embedding是将离散变量转化为连续向量表示的一种方式。在Google官方教程表述embedding使大型输入(例如表示单词的稀疏向量)进行机器学习变得更加容易。它可以帮助我们研究非结构化数据内容时,将这些离散变量转换为数字更有助于模型训练。比如说某一公司有三个产品,平均每个产品又五万条评论,语料库中唯一的词总数为100万。我们将得到一个形状为(150K,1M)的矩阵。对任何模型来说,这种输入非常大也非常稀疏。我们假设将维度减少到15(每个产品的15位ID),取每个产品嵌入的平均值,然后根据数值对他们进行上色,将得到如下图;
嵌入意味着用一组固定的数字来表示一个类别,我们可以通过(3,15)的矩阵来表示每个产品之间的相似程度。更加可视化也降低复杂度。
每个类别都映射到一个不同的向量,并且在训练神经网络时可以调整或学习向量的属性。向量空间提供类别的投影,从而使得那些接近或相关的类别自然地聚在一起。为了学习嵌入,我们创建了一个使用这些嵌入作为特征并与其他特征交互以学习上述任务。此时需要引用一个概念:词向量。
2.1 词向量
词向量是一种语言的每个词的嵌入向量。词向量的整个想法是,在句子中出现更近的词通常彼此更接近。嵌入是**n **维向量。每个维度捕获每个单词的某些属性/属性,因此更接近属性,更接近单词。为了学习词向量,我们创建了一组出现在一个小词窗口(比如 5 个词)内的词对作为正例,并创建一组没有出现在该窗口中的词对作为负例。
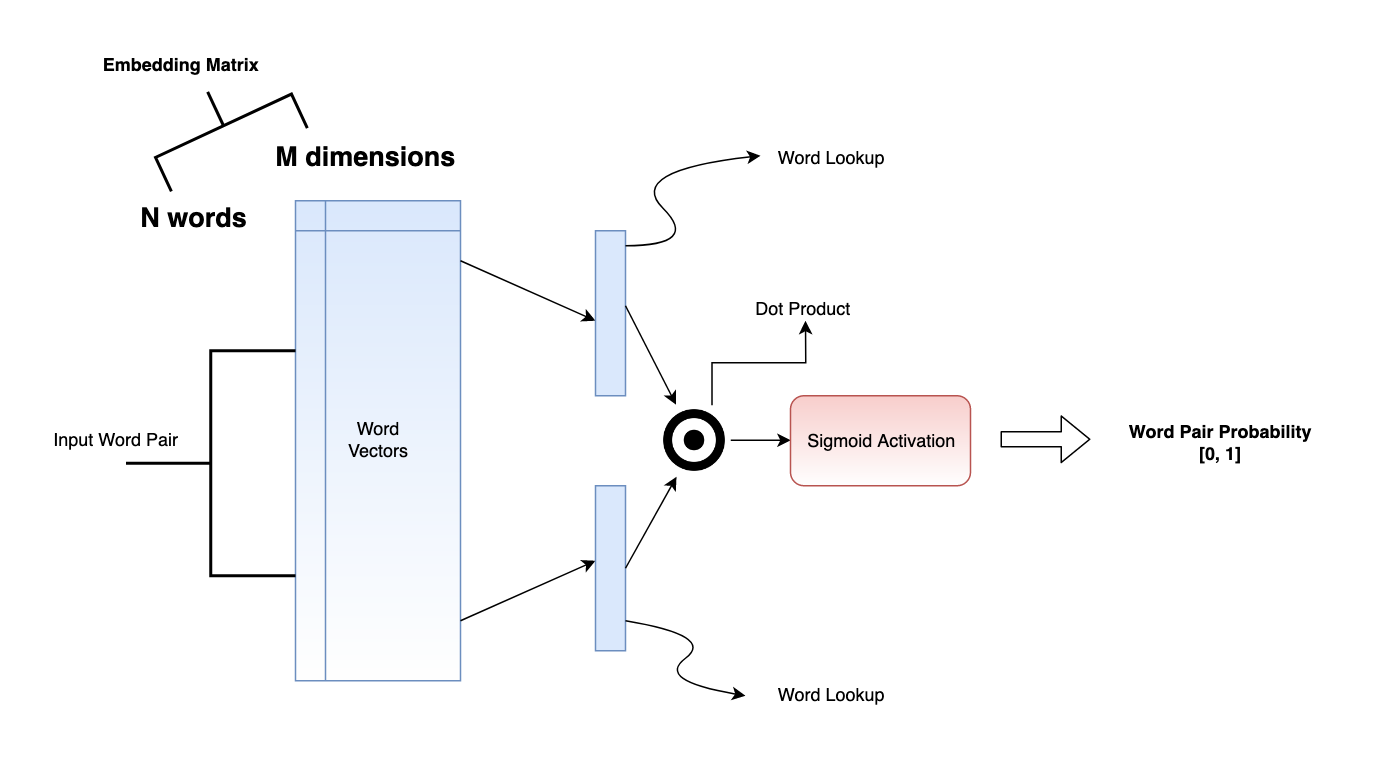
当我们在足够大的数据集上训练上述神经网络时,模型会学习预测两个词是否相关。然而,这个模型的副产品是嵌入矩阵,它是词汇表中每个单词的信息丰富的向量表示。(参考Categorical Embedding and Transfer Learning一篇)
2.2传统方法
- 序号编码(Ordinal Encoding)序号编码通常用于处理类别间具有大小关系的数据。
- 独热编码(One-hot Encoding)使用稀疏向量来节省空间,配合特征选择来降低维度
- 二进制编码 (Binary Encoding)二进制编码主要分为两步,先用序号编码给每个类别赋予一个类别ID,然后 将类别ID对应的二进制编码作为结果。
2.3 categorical_embedder工作原理
首先,每个分类变量类别都映射一个n维向量。这种映射是在标准的监督训练过程中由神经网络学习的。如果我们想使用上述15维ID作为特征,那么我们将以监督方式训练神经网络,获取每个特征的向量并生成如下所示的3*15的矩阵。如下图所示(太多神经节点不好表示,下图仅参考)

接下来,我们将使用数据中对应的向量来替换每个类别。这样做的优点在于我们限制了每个类别所需的列的数量。这在列具有高基数是非常有用(基数是指对集合元素数量的度量)。从神经网络获得的生成嵌入揭示了分类变量的内在属性。这意味着相似的类别将具有相似的嵌入。
2.4 学习嵌入矩阵
嵌入矩阵是浮点数N*M矩阵。这里N是唯一类别的数量,M是嵌入维度。我们决定M的值。通常将M设置为等于N的平方根,然后根据需要增加或减少。实际上,嵌入矩阵是向量的查找表。嵌入矩阵的每一行都是一个唯一类别的向量。
对于公司而言,它有三个产品,每个产品的评价为五万个唯一值,要构建分类嵌入,我们需要解决有意义的任务深度学习模型,在上述任务中使用嵌入矩阵来表示分类变量。我们用15维变量来预测公司的产品关联。可以通过颜色的区分来分析哪个产品具有相关性,当然这个属于推荐系统的一个分析思路。更多的是将样本的属性分门别类构建对应的embedding矩阵,通过这些Label_embedding矩阵,通过Faltten层,输入神经网络中进行训练
3 基于Python的categorical_embedder
3.1 神经网络编码代码复现
pip install categorical_embedder
注意:这个库要求tensorflow的版本在2.1以下,高于此版本会出现未知错误。
在这个categorical_embedder包含一些重要的函数定义,我们仔细描述其含义。
- ce.get_embedding_info(data,categorical_variables=None):这个函数的目的是识别数据中所有的分类变量,确定其嵌入大小。分类变量的嵌入大小由至少50个或一半的数量决定。唯一值,即嵌入列大小 = Min(50,#该列中的唯一值)。我们可以在categorical_variables参数中传递一个明确的分类变量列表。如果没有,这个函数会自动接受所有数据类型为对象的变量。
def get_embedding_info(data, categorical_variables=None):
'''
this function identifies categorical variables and its embedding size
:data: input data [dataframe]
:categorical_variables: list of categorical_variables [default: None]
if None, it automatically takes the variables with data type 'object'
embedding size of categorical variables are determined by minimum of 50 or half of the no. of its unique values.
i.e. embedding size of a column = Min(50, # unique values of that column)
'''
if categorical_variables is None:
categorical_variables = data.select_dtypes(include='object').columns
return {
col:(data[col].nunique(), 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 278
278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









