







具体教程及图文源自:https://github.com/InternLM/Tutorial/blob/camp2/opencompass/readme.md

笔记部分
OpenCompass介绍
上海人工智能实验室科学家团队正式发布了大模型开源开放评测体系 “司南” (OpenCompass2.0),用于为大语言模型、多模态模型等提供一站式评测服务。其主要特点如下:
- 开源可复现:提供公平、公开、可复现的大模型评测方案
- 全面的能力维度:五大维度设计,提供 70+ 个数据集约 40 万题的的模型评测方案,全面评估模型能力
- 丰富的模型支持:已支持 20+ HuggingFace 及 API 模型
- 分布式高效评测:一行命令实现任务分割和分布式评测,数小时即可完成千亿模型全量评测
- 多样化评测范式:支持零样本、小样本及思维链评测,结合标准型或对话型提示词模板,轻松激发各种模型最大性能
- 灵活化拓展:想增加新模型或数据集?想要自定义更高级的任务分割策略,甚至接入新的集群管理系统?OpenCompass 的一切均可轻松扩展!
评测对象
本算法库的主要评测对象为语言大模型与多模态大模型。我们以语言大模型为例介绍评测的具体模型类型。
- 基座模型:一般是经过海量的文本数据以自监督学习的方式进行训练获得的模型(如OpenAI的GPT-3,Meta的LLaMA),往往具有强大的文字续写能力。
- 对话模型:一般是在的基座模型的基础上,经过指令微调或人类偏好对齐获得的模型(如OpenAI的ChatGPT、上海人工智能实验室的书生·浦语),能理解人类指令,具有较强的对话能力。
工具架构
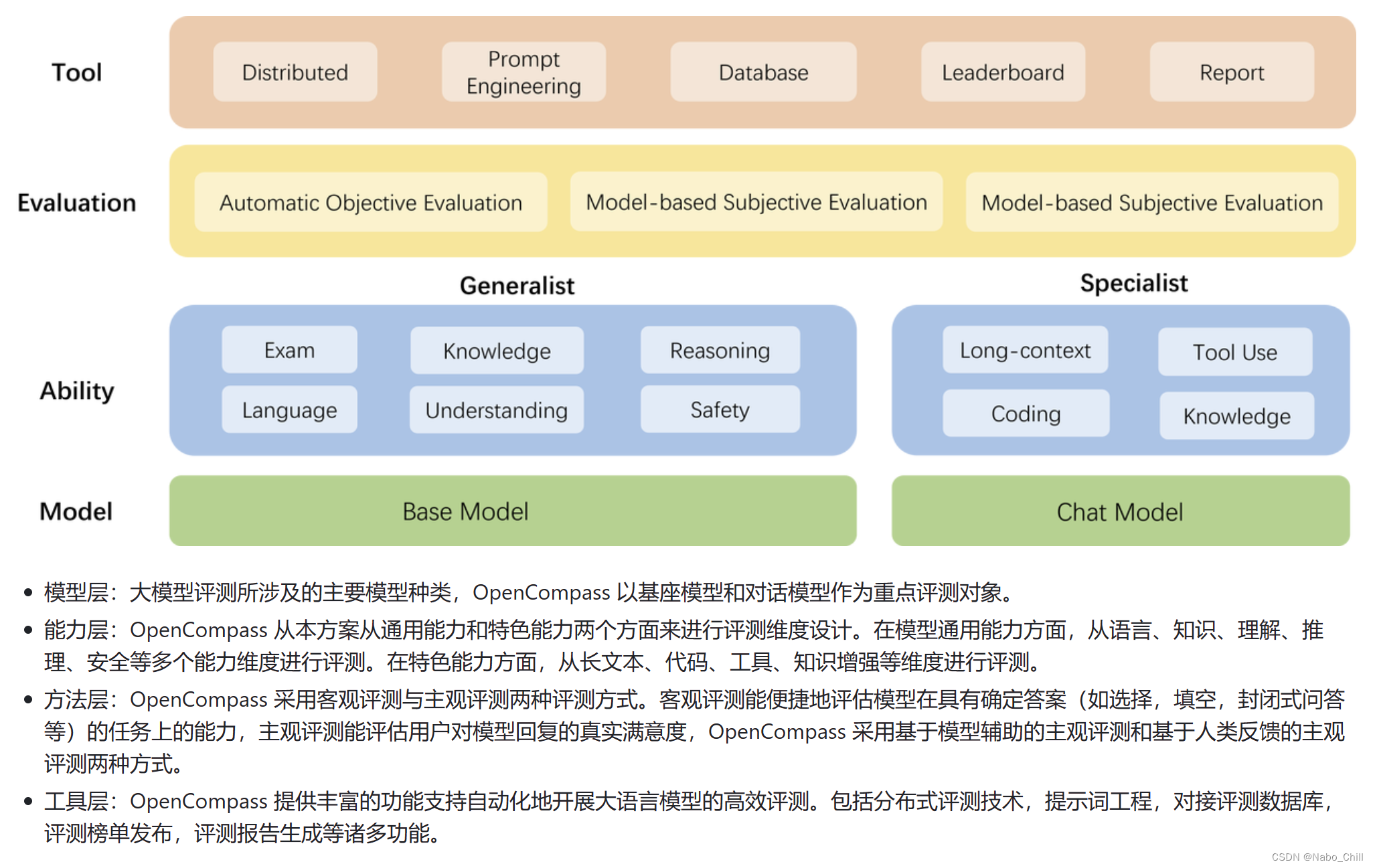
设计思路
为准确、全面、系统化地评估大语言模型的能力,OpenCompass 从通用人工智能的角度出发,结合学术界的前沿进展和工业界的最佳实践,提出一套面向实际应用的模型能力评价体系。
评测方法
OpenCompass 采取客观评测与主观评测相结合的方法。针对具有确定性答案的能力维度和场景,通过构造丰富完善的评测集,对模型能力进行综合评价。针对体现模型能力的开放式或半开放式的问题、模型安全问题等,采用主客观相结合的评测方式。


快速开始
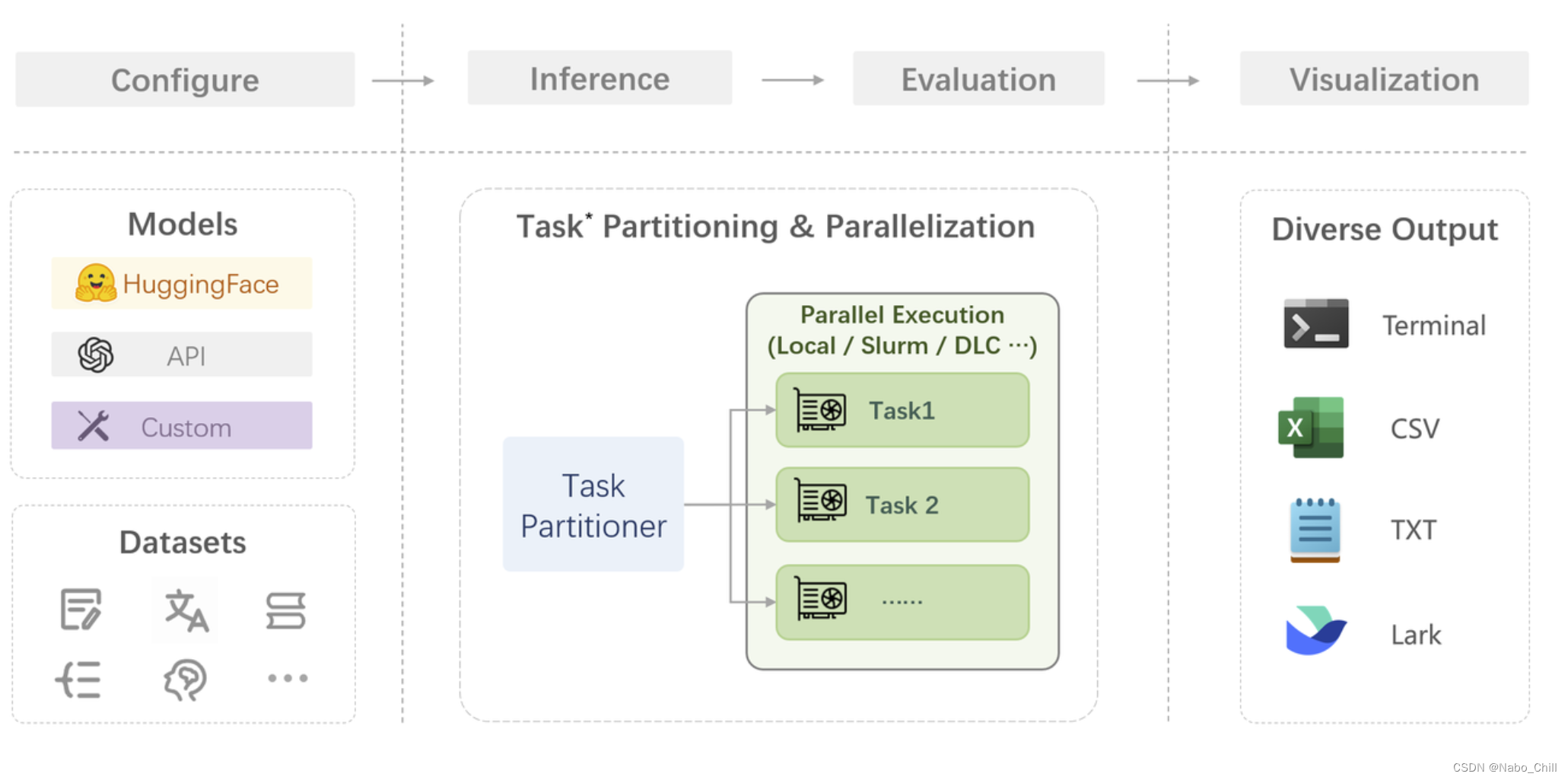

1. 环境配置
创建开发机和 conda 环境
在创建开发机界面选择镜像为 Cuda11.7-conda,并选择 GPU 为10% A100。
安装
面向GPU的环境安装
studio-conda -o internlm-base -t opencompass
source activate opencompass
cd /root
git clone -b 0.2.4 https://github.com/open-compass/opencompass
cd opencompass
pip install -e .
如果pip install -e .安装未成功,请运行:
pip install -r requirements.txt
有部分第三方功能,如代码能力基准测试 HumanEval 以及 Llama 格式的模型评测,可能需要额外步骤才能正常运行,如需评测,详细步骤请参考安装指南。
数据准备
解压评测数据集到 data/ 处
cp /share/temp/datasets/OpenCompassData-core-20231110.zip /root/opencompass/
unzip OpenCompassData-core-20231110.zip
将会在 OpenCompass 下看到data文件夹
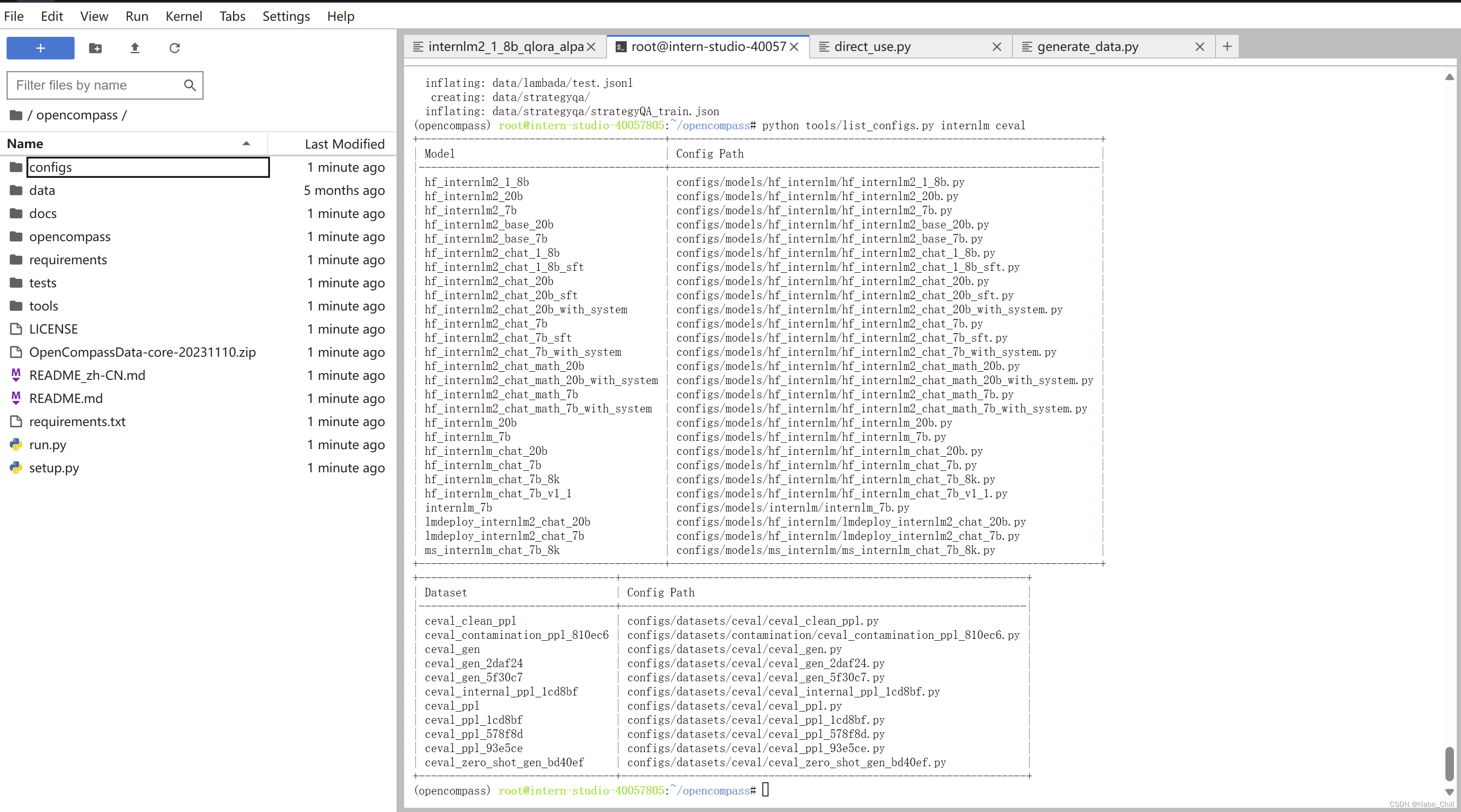
查看支持的数据集和模型
列出所有跟 InternLM 及 C-Eval 相关的配置
python tools/list_configs.py internlm ceval
启动评测 (10% A100 8GB 资源)
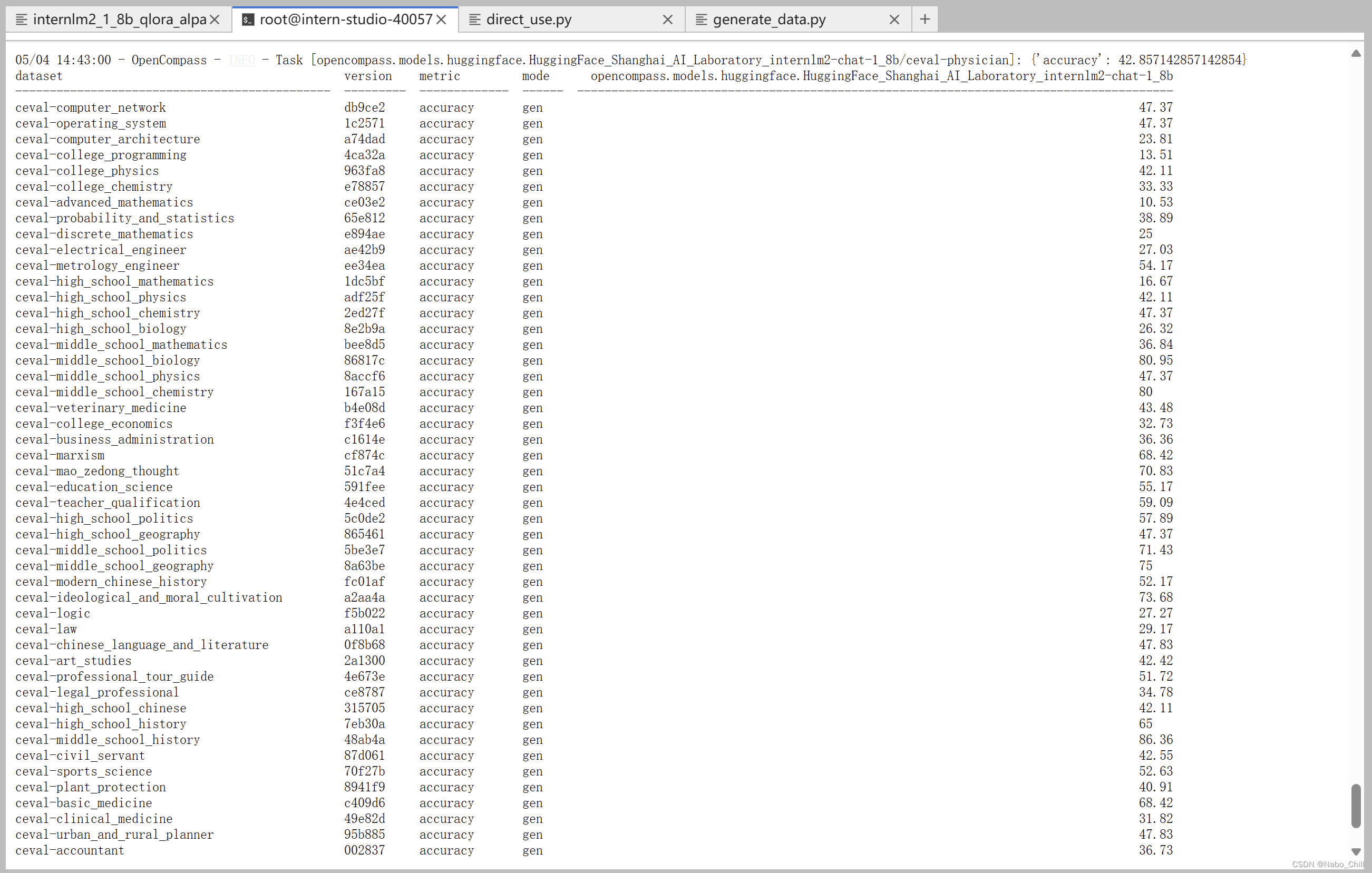
确保按照上述步骤正确安装 OpenCompass 并准备好数据集后,可以通过以下命令评测 InternLM2-Chat-1.8B 模型在 C-Eval 数据集上的性能。由于 OpenCompass 默认并行启动评估过程,我们可以在第一次运行时以 --debug 模式启动评估,并检查是否存在问题。在 --debug 模式下,任务将按顺序执行,并实时打印输出。
python run.py --datasets ceval_gen --hf-path /share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b --tokenizer-path /share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b --tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True --model-kwargs trust_remote_code=True device_map='auto' --max-seq-len 1024 --max-out-len 16 --batch-size 2 --num-gpus 1 --debug
遇到错误
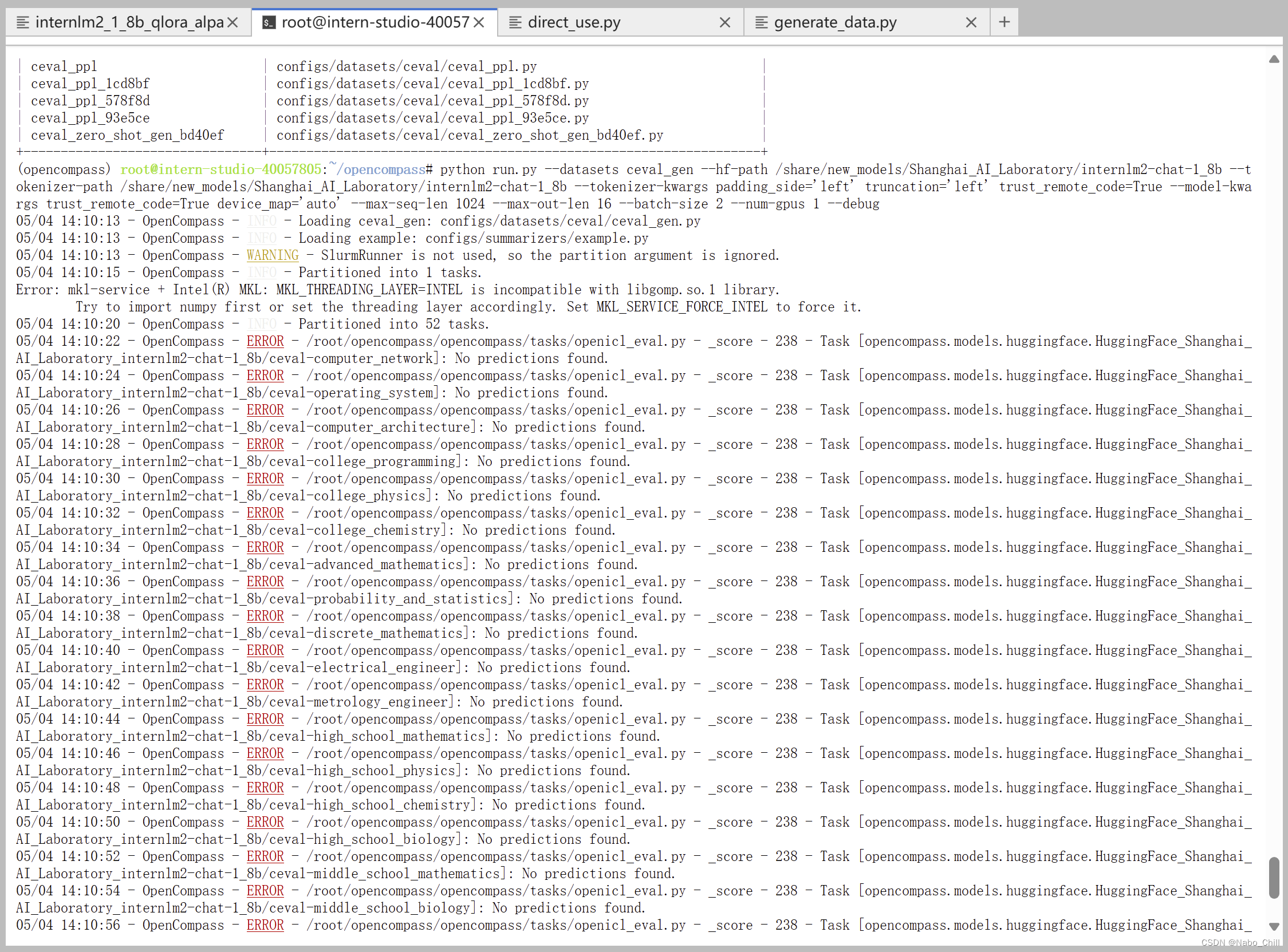
解决方案:
pip install protobuf
命令解析
python run.py
--datasets ceval_gen \
--hf-path /share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b \ # HuggingFace 模型路径
--tokenizer-path /share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b \ # HuggingFace tokenizer 路径(如果与模型路径相同,可以省略)
--tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True \ # 构建 tokenizer 的参数
--model-kwargs device_map='auto' trust_remote_code=True \ # 构建模型的参数
--max-seq-len 1024 \ # 模型可以接受的最大序列长度
--max-out-len 16 \ # 生成的最大 token 数
--batch-size 2 \ # 批量大小
--num-gpus 1 # 运行模型所需的 GPU 数量
--debug
遇到错误
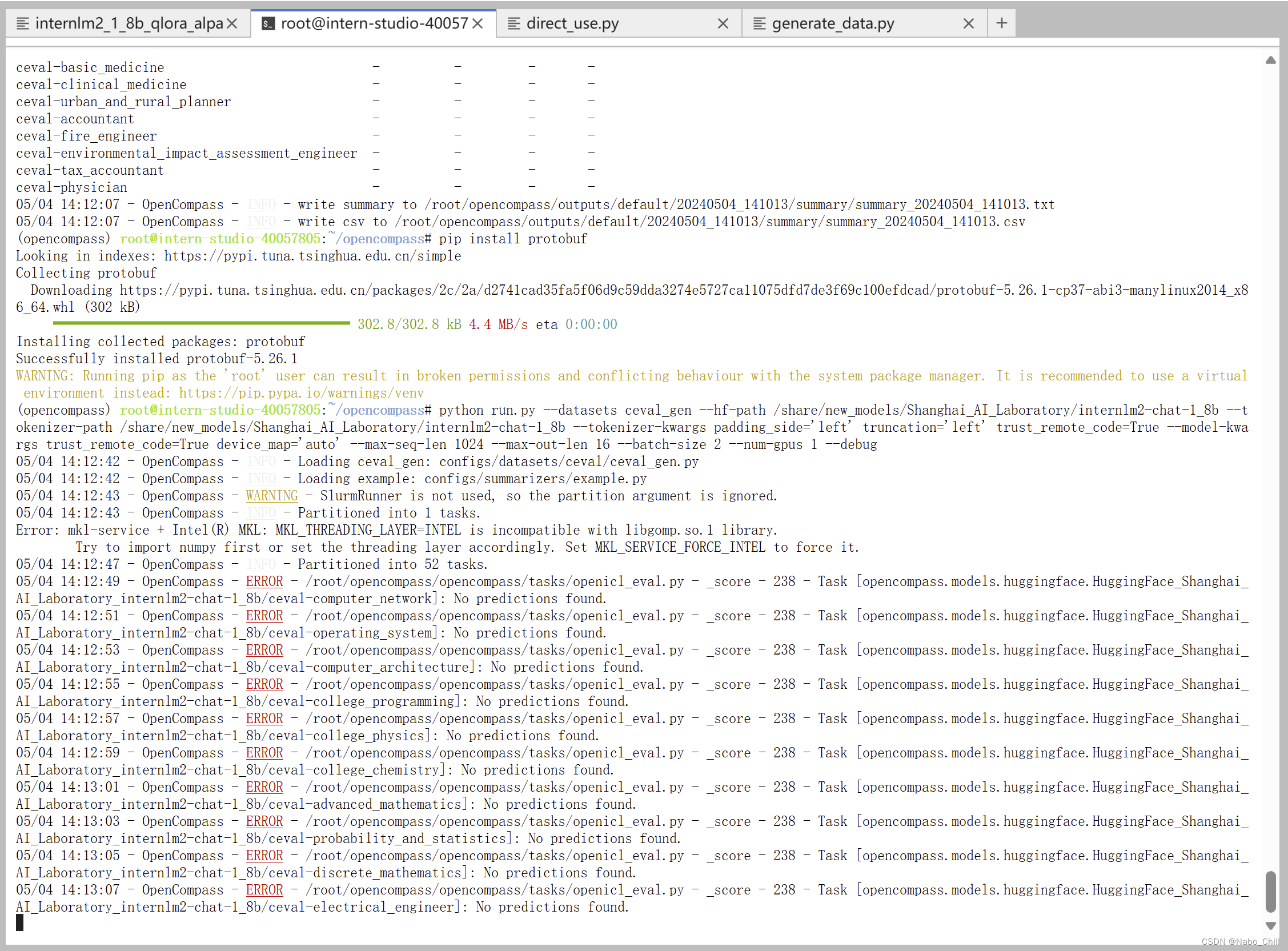
遇到错误mkl-service + Intel® MKL MKL_THREADING_LAYER=INTEL is incompatible with libgomp.so.1 … 解决方案:
export MKL_SERVICE_FORCE_INTEL=1
#或
export MKL_THREADING_LAYER=GNU
如果一切正常,您应该看到屏幕上显示 “Starting inference process”:
[2024-03-18 12:39:54,972] [opencompass.openicl.icl_inferencer.icl_gen_inferencer] [INFO] Starting inference process...
















 720
720

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









