







脚本的开发占用我们的开发的大部分时间,所以学习一些技巧有很大的好处。脚本涉及的范围很广,这一章就只介绍unity脚本相关的,关于一些围绕MonoBehaviours, Gameobjects和相关的函数的问题。
这一章,在一下几个方面来探讨性能提高的方法:
- 访问组件
- 组件的回调(update(), Awake()等)
- 协程
- 内部object的通信
- 数学的运算
- 场景和prefab载入
使用最快的方法获取components
GetComponnet()方法有三个重载, 每个都有不同的开销, 因此在选择版本的时候要谨慎, 三个方法为:
1.Getcomponnet(string)
2.GetComponents();
3.GetComponnets(typeof(T))
最快的版本依赖于你正在使用的unity版本,不过从unity5以后, 最好使用GetComponnet()方法。
它只比GetComponnet(typeof(T))快一点,但是GetComponent(string)是非常慢的。
移除空的调用的定义
unity中的脚本的最初的方法是在类中定义继承自MonoBehaviour的回调函数,这些函数会在必要的时候由unity调用。四种最常用的方法是Awake(), Start(), Update(), FixedUpdate()。
Awake()将在MonoBehaviour第一次创建的时候调用,不管是在场景初始化或者新的包含Mono的Gameobject在运行时从prefab实例化的时候。Start()将会在Awake()后调用,不过在第一次的Update()之前。
初始化后, update()将会重复调用,每次渲染通道提供新的画面。当mono的父物体Gameobject是激活状态,update()就会持续的调用。
FixedUpdate()在物体引擎update之前调用,并在yield waitFixedupdate()结束,为一个物理循环。 它不会和渲染帧率直接相关,它是基于时间调用的。物理的循环可能在一帧调用多次, 如果fixed时间小于实际的帧的update时间。
关于调用顺序的官方说明:
官方文档
当场景中的MonoBehaviour被第一次实例化,unity将脚本中定义的回调添加到函数指针列表中,在特殊时刻调用。我们需要意识到不管这个回调函数是否是空的,untiy都会调用。unity引擎不知道这个方法是否是空的,它只知道是否被定义。当场景中有上千个脚本都只是个空的定义,就会引起场景初始化的缓慢和浪费CPU时间。尤其是执行关键游戏事件发生这用空的调用,比如创建粒子特效,伤害飘字等,出现实例化的。突然请求CPU进行大量的变换,但是只有有限的时间来处理。
同时,如果有空的update,将会在每一帧都浪费大量的CPU资源。
解决办法就是删除空的回调定义,但是找到空的定义比较困难,不过可以利用正则表达式来查找。
当然了,其他的回调也会造成这种问题,比如OnGUI(), OnEnable(), OnDestory()等,要特别注意OnGUI(),它可能在一帧中调用多次。
可能最多出现的性能问题的原因都是unity脚本的update()回调中的错误使用:
1.对一些极少变换的值的重复计算
2.对一些可能共享的结果在多个组件中计算。
3.不必要的处理
在upate()编写每一行代码时,要养成习惯来考虑这些问题。
缓存component的引用
在unity编写脚本时,重复的计算某个值是常见的错误,特别是涉及到GetComponent()方法。

这个方法每次执行,都要重新获取5个不同组件的引用,这对于CPU的使用时非常不友好的。特别是当这个方法在update()中调用时。
将这些引用保存起来等待将来使用,只会销毁很少的内存空间,因此,除非处在内存的极端瓶颈, 最好的方法就是在初始化时获取这些引用并保存,虽然占用了少量内存,但是是值得的。
共享计算的结果
每次进行开销比较大的操作时,就要思考是否正在被多个地方调用,但是得到的结果是一致的,如果是这种情况,就要重构代码,达到只计算一次,然后将结果分发给需要的object,减少重新计算的次数。
养成在基类中隐藏复杂的函数,并定义派生类来利用这个函数的习惯。最好使用unity Profiler来统计这个开销函数可能被调用了多少次,不预优化函数,除非已经证明了它是性能问题。
Update, 协程,InvokeRepeating
另一个容易犯错的习惯就是在update()中调用某个函数超过必要的次数。
比如
void Update()
{
ProcessAI();
}
在update()的每一帧都调用AI的处理函数,这函数可能是非常复杂的,需要AI系统来计算寻路的网格或者一些其他的需求。如果这个调用会验证影响到帧率,并且这个调用可以更低频率的计算但是不会造成显著的问题,最好的优化方法就是减少ProcessAI()的调用次数。可以通过Time.deltatime来计算时间,控制在一秒中调用5次。代价就是代码看起来不太直观,很小的内存占用来保存float变量
private float delay = 0.2f;
private flaot timer = 0.0f;
void Update()
{
timer += Time.deltaTime;
if(timer > delay)
{
ProcessAI();
timer -= delay;
}
}
这个例子可以转换成协程,利用携程的延迟调用的特性。协程主要被用来执行短期的序列事件一次,或者多次。我们要和线程区分开,线程是可以以并发的方式运行在完全不同的CPU上, 多个线程可以同时运行。但是协程只能在主线程中以顺序执行的方式,在一个时刻只能有一个协程执行,每个线程都通过yield状态来决定何时继续和挂起。
void Start()
{
StartCoroutine(ProcessAICoroutine());
}
IEnumerator ProcessAICoroutine()
{
while(true)
{
ProcessAI();
yield return new WatiForSeconds(delay);
}
}
在协程中,通过yield来暂停,可以控制调用的次数。
不过使用协程也会带来额外的开销,需要一些内存分配来保存当前的状态。因此我们要权衡协程带来的利与弊。而且, 一旦初始化,协程的运行就独立于MonoBehaviour组件的update(), 它将会继续的执行而不管脚本是否可用,如果我们会使用大量gameobject的创建和销毁时使用就非常不明智。协程会自动停止因为它绑定的gameobject会关闭,但是gameobject重新激活时,却不会自动重新开始。
我们通过将方法转换为协程实现,我们可以从整体上减少性能问题,但是如果是调用的方法本身影响帧率,比如不管我们调用方法次数有多少,仍然会超出范围。因此这个方法最好的使用情景就是,由于方法调用次数问题而导致的瓶颈,而不是这个方法本身消耗太大。
接下来介绍一些yield的类型:
- waitForSeconds , 暂停给定的秒数
- waitForSecondsRealtime , 它不同于waitForSeonds, 它使用非缩放时间, WaitForSconds是受全局的Time.timeScale的影响。因此在我们修改了TimeScale时,使用yield要小心。
- waitForEndOfFrame, 将会在下一个update之后继续执行。waitForFixedUpate,将会在下一个FixedUpdate()结束后继续。
我们在一些update() 中的实现,可以用协程更简洁的使用yield类型来实现。但是我们应该意识到上面提到的可能的问题。协程触发在调用堆栈中是找不到调用者,因此如果协程处理复杂的任务并和其他的子系统有交互,可能会导致严重的bug,可能是难以复现的。所以,当我们想要使用协程时,最好的方式就是保持协程独立于其他的复杂子系统。
如果我们的协程很简单,我们可以将它替换为InvokeRepeating()调用,它非常简单,并且有更少的消耗。InvokeRepeating()是完全独立于monobehaviour和Gameobject的状态。只有两个方法能停止invokeRepeating调用。
1.调用CancelInvoke()停止所有的InvokeRepeating调用
2.摧毁相关的MonoBehaviour或者它的父Gameobject ; 禁用mono或gameobject是没用的。
更快的gameobject空引用检查
进行gameobjet的null检查时,会导致不必要的性能问题。GameObjects和MonoBehaviours与C#的典型object比起来,是特殊的对象,以为它们在内存中有两个表示。一个存在于我们编写的C#代码(托管代码)管理的内存中,另一个存在于本地代码(Native code)分隔处理的不同内存空间中。数据可以在两个内存空间中移动,但是每一次都会造成额外的CPU使用和内存分配。这种现象可以引用为穿过Native-Managed桥。如果发生了,可能会有额外的内存分配来支持object数据通过桥实现拷贝,这将会引起GC问题。详细的介绍将在第八章中给出,我们暂且认为有很多的小问题可以突然导致这个问题,简单的null引用检查,就是其中的一个:
if(gameobject != null)
一个可以替代且快两倍的函数式的方法是system.object.ReferenceEquals()
这个方法可以应用到Gameobjects和MonoBehaviours, 和unity的其他objects, 比如www类。然而一些测试证明了null检查,仅仅消耗几纳秒的时间, 因为,除非你使用了大量的null检查,这个增益可能是最低优先级考虑。但是,我们要记住这个特性,它可能会有很多。
避免检索gameobject的string类型的属性
通常情况下在c#中,从对象中检索或访问string属性和检索其他属性一样, 没有额外的内存消耗。但是从GameObjects中检索string属性却是另一种偶然引起本地-托管交互的方式。
Gameobject中受影响的特效是tag和name,因此在游戏逻辑中使用这两个特性是不明智的,可以在一些性能不重要的地方,比如编辑器下。但是tag系统经常被用来运行识别对象。
我们想要避免这种本地-托管交互的消耗,幸运的时,tag属性经常被用于比较,gameobject提供了CompareTag()方法来替代来tag属性的比较,可以完全避免本地-托管内存的交互。
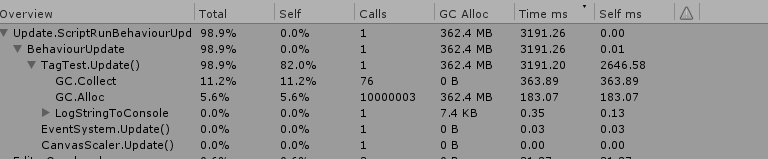
在upate中进行测试,分别进行10000000次的比较,可以看到tag属性导致了360多的内存分配, 我们可以在timelines上看到峰值的GC分配。整个过程花费了3000多ms, 一旦string对象不再需要,进行的垃圾回收消耗了360多ms。
同时,可以看到compareTag方法,整个过程的消耗将近1000ms, 在内存上分配几乎没有。通过对比可以知道,我们必须避免使用name和tag属性,如果必要要使用tag比较,就使用comapreTag。但是name属性没有替代品,我们尽量使用tag来替代name。

使用合适的数据结构
C#的system.Collections命名空间中提供了很多不同的数据结构,我们不应该习惯于每次都使用一样的数据结构。在软件开发过程中,比较常见的性能问题就是数据结构的使用不当。两个最常用的结构时List和Dictionary<K, V>。
如果想迭代一系列的objects, list是最好的选择,因为list实际上是动态数组, objects在内存中是连续的,因此会产生很小的缓存未命中问题。
Dictionary用在两个有联系的objects, 我们希望能够快速获取,插入或删除这种联系。不过有时候,我们要结合这两种数据结构,一起使用来解决问题。
什么是缓存未命中?
由于CPU和内存和工作频率不一致,如果CPU直接从内存中读取数据,CPU会花费很长时间来等待数据,所以在CPU和内存之间加入了三级缓存,L1,L2, L3。越靠近CPU,读取速度越快。CPU读取数据时先查找L1缓存, 找到就返回,如果L1中不存在,再去L2中查找,然后L3, 如果缓存中未找到,最后才去内存中查找。如果在缓存中未找到,就是属于缓存未命中。不过CPU在从内存中读取数据时,就将相邻的数据一并读取到缓存中,以缓存行(cache line)的形式保存在缓存中;对数组的遍历时, 当遍历完第一个元素后,相邻的元素会被加载到缓存中,后续的遍历时,CPU就可以直接在缓存中找到,不需要到内存中查找。
这样的读取机制,能够使CPU读取缓存的命中率非常高,在90%左右。
避免在运行时再次设置Transform的父节点
在更早的unity版本中(5.3前), Transform组件的引用在内存中一般是随机排列的。这意味这由于可能的缓存未命中,导致遍历多个Transform时比较慢。好处就是重置GameObject的父节点时,不会造成严重的性能问题, 因为对Transforms的操作像堆结构一样, 在插入和删除上有很快的速度。
然而,从unity5.4开始,Transform组件的内存放置反生了很大的变化。Transform的父子关系更像动态数组,unity将具有共同父节点的Transform保存在预先分配的内存缓冲中, 并根据transform在Hierarchy中的深度来排序。这样的数据结构,会有非常快的迭代速度。但是缺点就是,当你修改GameObject的父节点时, 这个父节点必须根据新的子节点来调整预分配的内存缓冲,并根据新的深度信息来重新排序。如果父节点没有足够的内存来保存新节点,就需要去扩展内存缓冲。对于比较复杂的Gameobject结构,将会花费一些时间去完成。
当使用GameObject.Instantiate()来实例化新的GameObject时,其中一个参数是想要设置为Gameobject的父Transfform,默认是null, 如果为null, Transform将会被放置到Hierarchy 窗口的根节点下。所有的这些根节点下的Transforms需要分配一个缓冲来保存它当前的子节点或者以后将要添加的(子Transform就不需要分配),但是,如果你在Instantiate后,直接重置了Transform的父节点,就会丢弃刚分配的内存。为了避免这样,我们应该在调用GameObject.Instantiate()时, 提供了父Transform参数,这样可以跳过缓冲分配这一步。
另外一个减少这个过程开销的方法是在我们需要扩展之前,让根Trasnform预分配更大的缓冲,这样可以避免在同一帧扩展缓冲同时,又重置Gameobject父节点到这个buffer中。可以通过修改Transform组件的hierarchyCapacity属性来解决。如果可以预估父节点可能容纳的子节点数量,我们可以节省很多不必要的内存分配。
(未完待续。。。)















 213
213











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









