







百度飞桨202210更新的表格识别模型SLENET(Structure Location Alignment Network)。
官方给出的优化点如下:
PP-LCNet:CPU 友好型轻量级骨干网络
CSP-PAN:轻量级高低层特征融合模块
SLAHead:结构与位置信息对齐的特征解码模块
在PubTabNet英文表格识别数据集上的消融实验如下:
| 策略 | Acc | TEDS | 推理速度(CPU+MKLDNN) | 模型大小 |
|---|---|---|---|---|
| TableRec-RARE | 71.73% | 93.88% | 779ms | 6.8M |
| +PP-LCNet | 74.71% | 94.37% | 778ms | 8.7M |
| +CSP-PAN | 75.68% | 94.72% | 708ms | 9.3M |
| +SLAHead | 77.70% | 94.85% | 766ms | 9.2M |
| +MergeToken | 76.31% | 95.89% | 766ms | 9.2M |
在PubtabNet英文表格识别数据集上,和其他方法对比如下:
| 策略 | Acc | TEDS | 推理速度(CPU+MKLDNN) | 模型大小 |
|---|---|---|---|---|
| TableMaster | 77.90% | 96.12% | 2144ms | 253.0M |
| TableRec-RARE | 71.73% | 93.88% | 779ms | 6.8M |
| SLANet | 76.31% | 95.89% | 766ms | 9.2M |
以上数据来自官方github主页。
下面详细介绍一些网络的结构
图片前处理
首先看一下前处理操作
主要的图片前处理操作包括
ResizeTableImage {'max_len': 1000, }
PaddingTableImage 'size': [1000, 1000]
NormalizeImage {
'std': [0.229, 0.224, 0.225],
'mean': [0.485, 0.456, 0.406],
'scale': '1./255.',
'order': 'hwc'
}
ToCHWImage
KeepKeys {'keep_keys': ['image', 'shape']}
从上面的配置就可以看出对图片的预处理操作,具体就不展开了。
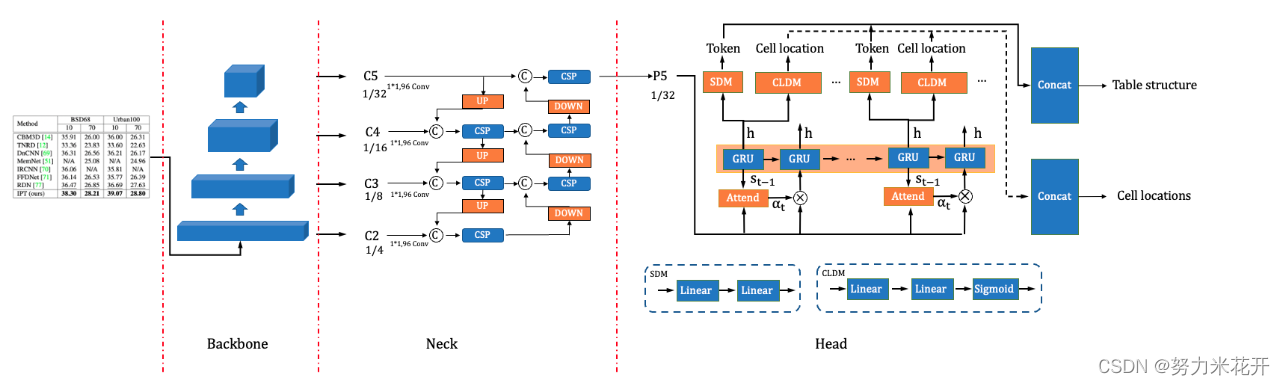
Backbone层-CPU友好型轻量级骨干网络PP-LCNet
网络代码保存在ppocr/modeling/backbones/PPLCNet中。
主要的结构是类似典型的FPN网络,但是在细节上做了一些处理。熟悉FPN网络的同学可以直接通过下面的配置信息看到网络的结构。
PP-LCNet是结合Intel-CPU端侧推理特性而设计的轻量高性能骨干网络,该方案在图像分类任务上取得了比ShuffleNetV2、MobileNetV3、GhostNet等轻量级模型更优的“精度-速度”均衡。PP-StructureV2中,我们采用PP-LCNet作为骨干网络,表格识别模型精度从71.73%提升至72.98%;同时加载通过SSLD知识蒸馏方案训练得到的图像分类模型权重作为表格识别的预训练模型,最终精度进一步提升2.95%至74.71%。
主要的特点是:
- 结合了mobilenet的关键结构deepwise conv和point_wise作为基础的结构单元,减少参数
- 在最后的一层中采用SEnet的关键结构,用于从512层的block6中获得比较重要的通道权重。
- 下面的配置中,每个列表元素分别表示(卷积尺寸、输出通道、输出通道,步长,是否使用SE模块),block5和block6中选择了5*5卷积来进一步扩大感受野
主干网络是一个自上而下的,通道数量逐渐增多,感受野逐步增大,分辨率逐渐减小的主干网络。最终的输出为block3-block6,构成一个列表输出到neck层。
"blocks2":
# k, in_c, out_c, s, use_se
[[3, 16, 32, 1, False]],
"blocks3": [[3, 32, 64, 2, False], [3, 64, 64, 1, False]],
"blocks4": [[3, 64, 128, 2, False], [3, 128, 128, 1, False]],
"blocks5":
[[3, 128, 256, 2, False], [5, 256, 256, 1, False], [5, 256, 256, 1, False],
[5, 256, 256, 1, False], [5, 256, 256, 1, False], [5, 256, 256, 1, False]],
"blocks6": [[5, 256, 512, 2, True], [5, 512, 512, 1, True]]
}
Neck层-轻量级高低层特征融合模块CSP-PAN
对骨干网络提取的特征进行融合,可以有效解决尺度变化较大等复杂场景中的模型预测问题。
早期,FPN模块被提出并用于特征融合,但是它的特征融合过程仅包含单向(高->低),融合不够充分。CSP-PAN基于PAN进行改进,在保证特征融合更为充分的同时,使用CSP block、深度可分离卷积等策略减小了计算量。在表格识别场景中,我们进一步将CSP-PAN的通道数从128降低至96以降低模型大小。最终表格识别模型精度提升0.97%至75.68%,预测速度提升10%。
-----以上描述来自官方的github介绍
输入为block3-block6层的输出,输入的通道数量分别为[64,128,256,512]
输出为一个包含96个通道的feature map。网络默认采用DWlayer(也就是deepwise+pointwise层,不过这里的激活函数默认leaky_relu),用于减少参数量。
四个输入层首先各自通过一个普通1*1卷积层+BN+hardwish激活函数,将每层的输出通道数量都统一为96。
CSP-PAN网络在backbone网路的基础上进行了依次自上而下的特征融合,又进行了依次自下而上的特征融合。通过融合低级与高级信息来增强不同 scale 的特征。因为它由分离的、仅需要最小计算量的(深度可分离卷积)卷积构成,所以即使增加了额外的自下而上的融合操作,计算量也没有增加很多。
在自上而下的上采样过程采用最近邻插值法实现,比如
{ b l o c k 6 上 采 样 ⊕ b l o c k 5 } → C S P l a y e r → i n n e r 3 \{block6上采样 \oplus block5\}\to CSPlayer\to inner3
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1631
1631

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









