







深入解析MoE中的Expert Choice Routing:革新路由策略的突破
在大型语言模型(LLM)的快速发展中,Mixture-of-Experts (MoE) 架构因其在大幅扩展模型参数的同时保持计算效率而备受关注。然而,MoE的性能高度依赖于其路由策略,即如何将输入 token 分配到合适的专家网络。传统 MoE 模型采用 Token-Choice Routing,即每个 token 选择 Top-k 个专家,但这种方法常导致专家负载不均、训练效率低下等问题。2022 年发表在 NeurIPS 的论文 Mixture-of-Experts with Expert Choice Routing(作者:Yanqi Zhou 等,Google 团队)提出了一种全新的路由方法——Expert Choice Routing,通过让专家选择 token,显著提升了训练效率和下游任务性能。本文将面向熟悉 LLM 和 MoE 的读者,详细解析这篇论文的核心内容,并深入解释其数学公式。
Paper: https://arxiv.org/pdf/2202.09368
背景:传统 MoE 的局限性
MoE 架构的核心思想是通过稀疏激活实现高效计算。每个 MoE 层包含多个专家(通常是前馈神经网络,FFN),通过门控网络(Gating Network)决定每个 token 由哪些专家处理。传统 MoE 采用 Token-Choice Routing,即每个 token 根据门控网络的输出选择 Top-1 或 Top-2 个专家(如 Switch Transformer 和 GShard)。然而,这种方法存在以下问题:
- 负载不均(Load Imbalance):某些专家可能被分配过多的 token,导致计算瓶颈,而其他专家则未被充分利用。论文提到,传统方法中某些专家的超载率可达 20%-40%,导致部分 token 被丢弃。
- 专家欠特化(Under Specialization):由于负载不均或过强的辅助损失(用于平衡负载),专家可能无法充分学习特定任务,导致模型容量浪费。
- 计算分配不灵活:传统方法为每个 token 分配固定数量的专家(如 Top-1 或 Top-2),无法根据 token 的复杂性动态调整计算资源。
为了解决这些问题,论文提出了 Expert Choice Routing,一种反转传统思路的路由策略:不是 token 选择专家,而是专家选择 token。
Expert Choice Routing 的核心思想
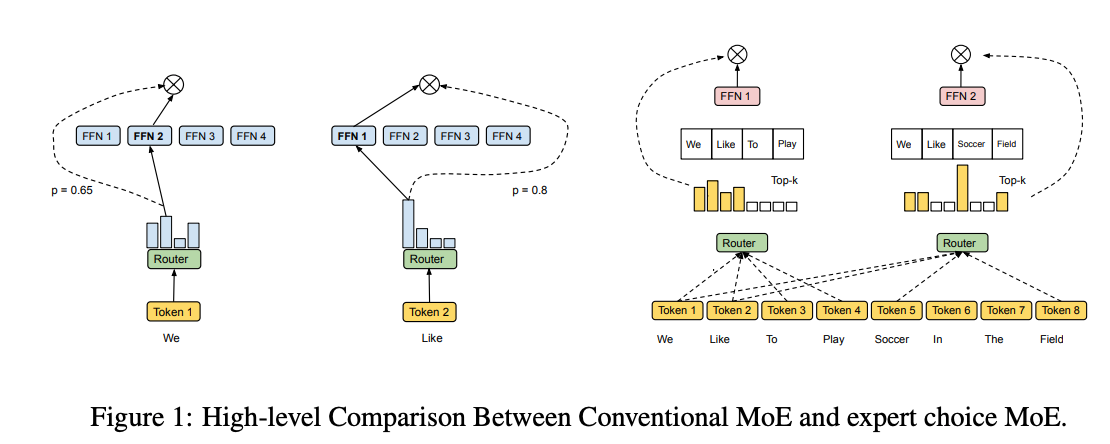
Expert Choice Routing 的核心创新在于让每个专家选择 Top-k 个 token,而不是让 token 选择专家。这种方法有以下优势:
- 完美负载均衡:每个专家固定处理 k 个 token,保证了计算资源的均匀分配,无需额外的辅助损失。
- 灵活的计算分配:不同 token 可以被不同数量的专家处理,允许模型根据 token 的复杂性动态分配计算资源。
- 更高的训练效率:实验表明,Expert Choice 在同等计算资源下,训练收敛速度比 Switch Transformer(Top-1)和 GShard(Top-2)快 2 倍以上。
具体来说,Expert Choice Routing 的流程如下:
- 计算 token-专家亲和度:通过门控网络计算每个 token 对所有专家的亲和度得分。
- 专家选择 token:每个专家从所有 token 中选择 Top-k 个得分最高的 token。
- 动态路由:根据选择的 token 和对应的权重,执行专家计算并聚合结果。
数学公式详解
Expert Choice Routing 的实现依赖于几个关键的数学公式,以下逐一解析。
1. 专家容量计算
每个专家的容量(即处理的 token 数量,记为 ( k k k ))由以下公式确定:
k = n × c e k = \frac{n \times c}{e} k=en×c
- ( n n n ):输入批次中的总 token 数(如 batch size × sequence length)。
- ( c c c ):容量因子(Capacity Factor),表示平均每个 token 分配到多少个专家。论文默认 ( c=2 ),以匹配 GShard 的 Top-2 路由的计算量。
- ( e e e ):专家总数。
解释:这个公式确保每个专家处理固定数量的 token,从而实现负载均衡。容量因子 ( c c c ) 控制了稀疏性:较大的 ( c c c ) 意味着更多的 token 被处理,计算成本更高;较小的 ( c c c ) 则更稀疏。
2. 门控函数与亲和度计算
门控网络计算 token 到专家的亲和度得分,公式为:
S = Softmax ( X ⋅ W g ) , S ∈ R n × e S = \text{Softmax}(X \cdot W_g), \quad S \in \mathbb{R}^{n \times e} S=Softmax(X⋅Wg),S∈Rn×e
- ( X ∈ R n × d X \in \mathbb{R}^{n \times d} X∈Rn×d ):输入 token 的表示,( d d d ) 是模型的隐藏维度。
- ( W g ∈ R d × e W_g \in \mathbb{R}^{d \times e} Wg∈Rd×e ):专家嵌入矩阵,可学习的参数。
- ( S S S ):亲和度矩阵,( S [ i , j ] S[i, j] S[i,j] ) 表示第 ( i i i ) 个 token 对第 ( j j j ) 个专家的亲和度得分。
解释:通过矩阵乘法 ( X ⋅ W g X \cdot W_g X⋅Wg ),每个 token 获得一个对所有专家的得分向量,再通过 Softmax 转换为概率分布。Softmax 确保亲和度总和为 1,便于后续选择。
接着,专家选择 Top-k 个 token:
G , I = TopK ( S ⊤ , k ) , P = Onehot ( I ) G, I = \text{TopK}(S^\top, k), \quad P = \text{Onehot}(I) G,I=TopK(S⊤,k),P=Onehot(I)
- ( S ⊤ ∈ R e × n S^\top \in \mathbb{R}^{e \times n} S⊤∈Re×n ):转置后的亲和度矩阵,从 token 视角转为专家视角。
- ( TopK ( S ⊤ , k ) \text{TopK}(S^\top, k) TopK(S⊤,k)):对每个专家(每行)选择得分最高的 ( k k k ) 个 token,返回对应的权重 ( G ∈ R e × k G \in \mathbb{R}^{e \times k} G∈Re×k ) 和索引 ( I ∈ R e × k I \in \mathbb{R}^{e \times k} I∈Re×k )。
- ( P ∈ R e × k × n P \in \mathbb{R}^{e \times k \times n} P∈Re×k×n ):索引 ( I I I ) 的独热编码,用于后续 token 分配。
解释:转置 ( S ⊤ S^\top S⊤ ) 使每个专家能从所有 token 中选择 Top-k 个。( G G G ) 记录选择的权重,( I I I ) 记录选择的 token 索引,( P P P ) 是一个稀疏矩阵,用于高效地聚集 token。
3. 专家计算与输出聚合
输入 token 根据分配矩阵 ( P P P ) 重新排列,生成专家的输入:
X in = P ⋅ X X_{\text{in}} = P \cdot X Xin=P⋅X
- ( X in ∈ R e × k × d X_{\text{in}} \in \mathbb{R}^{e \times k \times d} Xin∈Re×k×d ):每个专家的输入,( X in [ i ] ∈ R k × d X_{\text{in}}[i] \in \mathbb{R}^{k \times d} Xin[i]∈Rk×d ) 是第 ( i i i ) 个专家的 ( k k k ) 个 token。
每个专家计算输出:
X e [ i ] = GeLU ( X in [ i ] ⋅ W 1 [ i ] ) ⋅ W 2 [ i ] ⊤ X_e[i] = \text{GeLU}(X_{\text{in}}[i] \cdot W_1[i]) \cdot W_2[i]^\top Xe[i]=GeLU(Xin[i]⋅W1[i])⋅W2[i]⊤
- ( W 1 [ i ] , W 2 [ i ] ∈ R d × d W_1[i], W_2[i] \in \mathbb{R}^{d \times d} W1[i],W2[i]∈Rd×d ):第 ( i i i ) 个专家的权重矩阵。
- ( GeLU \text{GeLU} GeLU):激活函数。
- ( X e [ i ] ∈ R k × d X_e[i] \in \mathbb{R}^{k \times d} Xe[i]∈Rk×d ):第 ( i i i ) 个专家的输出。
最终输出通过加权聚合:
X out [ t , d ] = ∑ i , j P [ i , j , t ] G [ i , j ] X e [ i , j , d ] X_{\text{out}}[t, d] = \sum_{i, j} P[i, j, t] G[i, j] X_e[i, j, d] Xout[t,d]=i,j∑P[i,j,t]G[i,j]Xe[i,j,d]
- ( X out ∈ R n × d X_{\text{out}} \in \mathbb{R}^{n \times d} Xout∈Rn×d):MoE 层的最终输出。
- ( P [ i , j , t ] P[i, j, t] P[i,j,t] ):指示第 ( i i i ) 个专家的第 ( j j j ) 个 token 是否为第 ( t t t ) 个输入 token。
- ( G [ i , j ] G[i, j] G[i,j] ):对应的权重。
解释:这个公式将每个专家的输出按照权重 ( G G G ) 加权求和,恢复到原始 token 顺序。论文提到,这一步可以通过高效的 Einstein 求和(einsum)操作实现。
4. 带约束的 Expert Choice(可选)
为了探索限制每个 token 分配的专家数量的影响,论文提出了一种正则化的 Expert Choice 变体,解决以下优化问题:
max A ⟨ S ⊤ , A ⟩ + λ H ( A ) \max_A \langle S^\top, A \rangle + \lambda H(A) Amax⟨S⊤,A⟩+λH(A)
s.t. ∀ i : ∑ j ′ A [ i , j ′ ] = k ; ∀ j : ∑ i ′ A [ i ′ , j ] ≤ b ; ∀ i , j : 0 ≤ A [ i , j ] ≤ 1 \text{s.t.} \quad \forall i: \sum_{j'} A[i, j'] = k; \quad \forall j: \sum_{i'} A[i', j] \leq b; \quad \forall i, j: 0 \leq A[i, j] \leq 1 s.t.∀i:j′∑A[i,j′]=k;∀j:i′∑A[i′,j]≤b;∀i,j:0≤A[i,j]≤1
- ( A ∈ R e × n A \in \mathbb{R}^{e \times n} A∈Re×n ):分配矩阵,( A [ i , j ] A[i, j] A[i,j] ) 表示第 ( I I I ) 个专家选择第 ( j j j ) 个 token 的程度。
- ( ⟨ S ⊤ , A ⟩ \langle S^\top, A \rangle ⟨S⊤,A⟩):亲和度得分与分配矩阵的内积,最大化 token-专家匹配。
- ( H ( A ) = ∑ i , j − A [ i , j ] log A [ i , j ] H(A) = \sum_{i,j} -A[i, j] \log A[i, j] H(A)=∑i,j−A[i,j]logA[i,j] ):元素级熵正则化,促进稀疏解。
- ( λ \lambda λ ):熵正则化的权重(论文使用 ( λ = 0.001 \lambda = 0.001 λ=0.001 ))。
- ( b b b ):每个 token 最多被 ( b b b ) 个专家选择的上界。
- 约束:
- 每个专家选择 ( k k k ) 个 token(负载均衡)。
- 每个 token 最多被 ( b b b ) 个专家选择(控制稀疏性)。
- ( A [ i , j ] A[i, j] A[i,j] ) 在 [0, 1] 之间。
求解:使用 Dykstra 算法迭代投影到三个凸集的交集,得到近似整数解。然后通过 ( TopK ( A , k ) \text{TopK}(A, k) TopK(A,k) ) 选择路由索引 ( I I I )。
解释:这个优化问题平衡了亲和度最大化和负载均衡,同时通过熵正则化确保解的稀疏性。实验表明,限制专家数量(例如 ( b = 2 b=2 b=2 ))会略微降低性能,但仍优于传统 Top-2 路由。
实验结果与关键发现
论文通过广泛的实验验证了 Expert Choice Routing 的有效性,以下是主要结果:
-
训练效率:
- 在 8B/64E(80 亿激活参数,64 个专家)模型上,Expert Choice 的训练收敛速度比 Switch Transformer(Top-1)和 GShard(Top-2)快 2 倍以上(见图 2a)。
- 随着专家数量从 16 到 128 增加,训练困惑度(perplexity)持续降低,表明方法具有良好的扩展性(见图 2b)。
-
下游任务性能:
- 在 GLUE 和 SuperGLUE 的 11 个任务上,Expert Choice(EC-CF2,容量因子 ( c=2 ))显著优于 Top-1 和 Top-2 路由。例如,在 100M/64E 模型上,平均准确率从 Top-1 的 78.4% 和 Top-2 的 82.2% 提升到 84.0%(见表 2)。
- 8B/64E 的 Expert Choice 模型在 7/11 个任务上超越了 T5 11B 密集模型,平均准确率从 89.2% 提升到 92.6%(见表 3)。
-
异构性分析:
- 允许 token 被不同数量的专家处理(即异构路由)显著提升性能。限制每个 token 最多 2 个专家(EC-CAP2)会导致性能下降(平均准确率从 84.0% 降到 83.2%),而允许 3 个专家(EC-CAP3)与无限制的情况相当(见表 4)。
- 统计显示,约 23% 的 token 被分配到 3-4 个专家,3% 被分配到 4 个以上专家,验证了异构路由的必要性(见图 3)。
-
与其他方法的比较:
- 与 Hash Layer(基于哈希的路由)相比,Expert Choice 在下游任务上表现更好(平均准确率 84.0% vs. 81.3%),表明负载均衡并非唯一优势,学习的亲和度分配至关重要(见表 4)。
- 即使将容量因子降低到 1 或 0.5,Expert Choice 仍优于 Top-1 路由(见图 4a)。
局限性与未来方向
尽管 Expert Choice Routing 表现出色,论文也指出了其局限性:
- 自回归生成:当前实现依赖于全局 Top-k 选择,可能不适合自回归生成任务(需要同时考虑过去和未来 token)。可能的解决方案包括分组处理序列或在推理时选择全局 Top-k。
- 内存占用:MoE 模型的参数数量随专家数量线性增长,尽管计算成本降低,但硬件设备的静态功耗仍然较高。未来的优化可能包括动态电源管理。
总结
Expert Choice Routing 通过颠倒传统 MoE 的路由逻辑,实现了负载均衡、灵活计算分配和更高的训练效率。其核心在于让专家选择 token,并通过数学公式精确控制路由过程。实验结果表明,该方法不仅加速了训练(2 倍以上),还在下游任务中显著优于传统 MoE 和密集模型。对于熟悉 LLM 的研究者和工程师来说,Expert Choice Routing 提供了一个值得探索的思路,可能成为下一代高效 MoE 架构的基础。
后记
2025年5月5日于上海,在grok 3大模型辅助下完成。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









