







介绍 SeaEval:多语言基础模型的全面评估基准
近年来,大型语言模型(LLMs)作为一种基础模型(FMs)得到了快速发展,展现了其在多种下游任务中的泛化和适应能力。然而,随着这些模型在全球范围内的广泛应用,评估其多语言能力和文化理解能力的需求变得日益迫切。2024年由新加坡A*STAR信息通信研究所(I²R)等机构的研究团队发表的论文《SeaEval for Multilingual Foundation Models: From Cross-Lingual Alignment to Cultural Reasoning》提出了一种全新的多语言基础模型评估基准——SeaEval。本篇博客将详细介绍SeaEval的背景、设计理念、数据集、评估协议以及主要发现,为研究LLM多语言能力的研究者提供深入的参考。
Paper:https://aclanthology.org/2024.naacl-long.22v2.pdf
SeaEval:多语言基础模型的全面评估基准
背景与动机
随着大型语言模型的迅速发展,如ChatGPT、LLaMA、Baichuan等模型在自然语言处理(NLP)任务中表现出色,研究者开始关注这些模型在多语言和多文化场景下的表现。传统评估基准多集中于英语或中文等高资源语言,忽视了低资源语言和文化背景的复杂性。此外,现有基准往往仅关注语言理解和生成能力,缺乏对复杂推理、文化理解以及跨语言知识迁移能力的系统评估。SeaEval的提出旨在填补这一空白,通过设计一个全面的评估框架,探索多语言基础模型在语言、文化、推理和跨语言一致性四个维度的能力。
SeaEval的设计理念
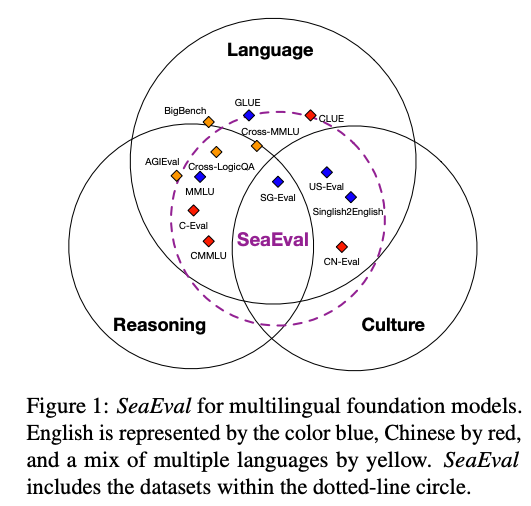
SeaEval的目标是构建一个多维度的评估基准,涵盖以下四个核心方面:
- 经典NLP任务:包括语言理解和生成任务,如情感分析、文本蕴含、对话理解、翻译和摘要生成,覆盖英语、汉语、印尼语等多种语言。
- 复杂推理:评估模型在多跳推理、数值推理和逻辑推理等复杂任务中的表现,采用如MMLU、C-Eval等数据集。
- 文化理解与推理:通过新构建的四个数据集(SG-Eval、US-Eval、CN-Eval、PH-Eval)测试模型对美国、新加坡、中国和菲律宾等地区文化规范和习俗的理解。
- 跨语言知识迁移与一致性:通过Cross-MMLU和Cross-LogiQA数据集,评估模型在不同语言中回答相同事实性问题的能力,检测跨语言一致性。
SeaEval包含29个数据集,其中7个为新构建的数据集,总计超过13,000个样本,覆盖英语、汉语、印尼语、西班牙语、越南语、马来语和菲律宾语等7种语言。这些数据集不仅测试模型的语言能力,还深入挖掘其文化敏感性和跨语言知识共享能力。
数据集与任务选择
数据集概览
SeaEval整合了18个经典NLP任务数据集和11个复杂推理及文化理解数据集,具体如下:
-
经典NLP任务:
- GLUE基准:包括SST-2、COLA、QQP等8个任务,测试英语环境下的语言理解能力。
- 其他语言任务:如DREAM(英语对话理解)、OCNLI和C3(汉语阅读理解)、Indo-Emotion(印尼语情感分析)。
- 生成任务:包括FLoRes(多语言翻译)、SAMSum和DialogSum(英语摘要生成)。
-
复杂推理:
- MMLU:测试英语环境下的多学科知识理解。
- C-Eval、CMMLU、ZBench:针对汉语的学科知识和复杂推理能力。
-
文化理解:
- SG-Eval、US-Eval、CN-Eval、PH-Eval:分别针对新加坡、美国、中国和菲律宾的文化知识,包含100-105个多选题,问题来源于当地居民提案、政府网站、历史教材等。
- Singlish2English:包含546个句子,测试从新加坡英语(Singlish)到标准英语的翻译能力,考察模型对混合语言和文化特性的理解。
-
跨语言一致性:
- Cross-MMLU、Cross-LogiQA:包含900和1,056个样本,覆盖7种语言,测试模型在不同语言中回答相同常识或逻辑问题的能力。
数据 curation
为了降低评估成本,SeaEval对现有数据集进行了随机采样,同时将所有判别任务转换为多选题形式,以方便量化评估。对于生成任务(如翻译和摘要),保留了原始的基于词匹配的评估流程(如BLEU和ROUGE)。新数据集的构建由语言专家完成,确保文化问题的地区特异性和语言表达的准确性。例如,Singlish2English数据集包含新加坡特有的语言元素,需理解马来语、汉语方言和泰米尔语的混合特性。
评估协议
SeaEval引入了两种新的评估维度,以补充传统准确率指标:
-
指令敏感性(Instruction Sensitivity):
- 方法:为每个数据集设计5种由NLP专家改写的指令,测试模型对不同表述的鲁棒性。
- 发现:如ChatGPT在改写指令下表现更稳定,而LLaMA-2性能波动较大,表明指令表述对模型性能影响显著(发现1)。
-
跨语言一致性(Cross-Lingual Consistency):
- 方法:引入一致性分数(Consistency Score)和AC3分数(准确率与一致性的调和平均),评估模型在不同语言中回答相同问题的稳定性。公式如下:
M{l1,l2,…,ls}=∑i=1N1{al1i=al2i=⋯=alsi}N M_{\{l_1, l_2, \ldots, l_s\}} = \frac{\sum_{i=1}^N \mathbb{1}_{\{a_{l_1}^i = a_{l_2}^i = \cdots = a_{l_s}^i\}}}{N} M{l1,l2,…,ls}=N∑i=1N1{al1i=al2i=⋯=alsi}
Consistencys=∑{l1,l2,…,ls}∈C(s,qi)M{l1,l2,…,ls}C7s \text{Consistency}_s = \frac{\sum_{\{l_1, l_2, \ldots, l_s\} \in C(s, q_i)} M_{\{l_1, l_2, \ldots, l_s\}}}{C_7^s} Consistencys=C7s∑{l1,l2,…,ls}∈C(s,qi)M{l1,l2,…,ls}
AC3s=2⋅Accuracy⋅ConsistencysAccuracy+Consistencys AC3_s = 2 \cdot \frac{\text{Accuracy} \cdot \text{Consistency}_s}{\text{Accuracy} + \text{Consistency}_s} AC3s=2⋅Accuracy+ConsistencysAccuracy⋅Consistencys - 参数:默认使用 ( s=3s=3s=3 ),即要求答案在至少3种语言中一致。
- 发现:大多数模型在跨语言问题上表现出不一致性,如ChatGPT在6种语言中的一致性仅为26%,表明语义表示的泛化能力不足(发现3)。
- 方法:引入一致性分数(Consistency Score)和AC3分数(准确率与一致性的调和平均),评估模型在不同语言中回答相同问题的稳定性。公式如下:
此外,SeaEval通过随机打乱标签顺序避免标签排列的暴露偏见(Exposure Bias),发现部分模型(如LLaMA-2)对标签位置敏感(发现2)。
主要发现
通过对多个模型(包括Baichuan-2、LLaMA-2、BLOOMZ、ChatGPT和GPT-4)的广泛测试,SeaEval得出了以下关键结论:
- 指令敏感性:模型对改写指令的反应差异显著,ChatGPT表现更鲁棒,而LLaMA-2受指令变化影响较大。
- 标签排列偏见:标签顺序会影响模型预测,特别是在小规模模型中,需通过随机化标签顺序消除此偏见。
- 跨语言不一致性:即使是针对事实性、科学性和常识性问题,模型在不同语言中的回答也不一致。例如,ChatGPT在Cross-MMLU数据集上显示出47%的一致性,而GPT-4达到75%,但在 ( s=6 ) 时下降至64%。
- 多语言能力不平衡:模型在高资源语言(如英语、汉语、西班牙语)上的表现优于低资源语言(如印尼语、越南语),显示出多语言能力的非均衡性(发现4)。例如,BLOOMZ在跨语言一致性上优于ChatGPT(54% vs. 47%),但整体准确率较低。
模型性能分析
- GPT-4:在大多数任务中表现最佳,跨语言和跨文化任务中均有显著优势,显示出强大的多语言能力。
- Baichuan-2:在汉语文化理解(CN-Eval)上表现突出,甚至超越GPT-4,归功于其高质量的预训练数据。
- LLaMA-2:因90%的训练数据为英语,英语任务表现优异,但在多语言和文化任务中表现较弱。
- BLOOMZ:作为开源多语言模型,在跨语言一致性上表现优异,但因模型规模和预训练限制,整体性能不如GPT-4。
局限性与未来方向
尽管SeaEval提供了全面的评估框架,但仍存在以下局限性:
- 语言与文化覆盖有限:目前仅涵盖7种语言和4个地区的文化,需扩展到更多低资源语言和文化背景。
- 开放式问题评估不足:SeaEval专注于量化评估,难以覆盖主观性和对话场景,需开发自动化评估方法。
- 安全与效率问题:未涵盖模型安全性和计算效率,未来需纳入这些维度。
研究团队建议通过自动化数据收集方法提升数据集的多样性,并开发更实用的开放式问题评估技术,同时关注模型的安全性和效率优化。
结论
SeaEval通过整合经典NLP任务、复杂推理、文化理解和跨语言一致性评估,提供了一个多维度的多语言基础模型评估框架。其新颖的评估协议(如指令敏感性和跨语言一致性)揭示了现有模型在多语言和多文化场景下的不足,为未来的模型优化提供了方向。研究者可通过SeaEval的开源数据集和工具包(https://github.com/SeaEval/SeaEval)进一步探索多语言LLM的潜力,推动更通用、更平衡的多语言语义表示和文化上下文建模。
跨语言一致性指标
跨语言一致性(Cross-Lingual Consistency)是评估多语言基础模型(Multilingual Foundation Models)的重要指标,旨在衡量模型在不同语言中对相同语义内容的回答是否保持一致。SeaEval 论文中提出的跨语言一致性评估方法为研究多语言模型的语义泛化能力提供了新颖的视角。本文将详细解析 SeaEval 中的跨语言一致性指标(包括一致性分数和 AC3 分数),通过示例说明其计算过程,并探讨其他文献中相关的跨语言一致性指标。
SeaEval 中的跨语言一致性指标
SeaEval 引入了两个核心指标来评估跨语言一致性:一致性分数(Consistency Score) 和 AC3 分数。这些指标基于模型在不同语言中对同一问题的回答一致性进行量化,特别针对常识性、科学性和事实性问题,这些问题在语义上应具有跨语言的等价性。
1. 一致性分数(Consistency Score)
定义:一致性分数衡量模型在不同语言中对同一问题是否给出相同答案的比例,不考虑答案的正确性。它通过以下公式计算:
M{l1,l2,…,ls}=∑i=1N1{al1i=al2i=⋯=alsi}N M_{\{l_1, l_2, \ldots, l_s\}} = \frac{\sum_{i=1}^N \mathbb{1}_{\{a_{l_1}^i = a_{l_2}^i = \cdots = a_{l_s}^i\}}}{N} M{l1,l2,…,ls}=N∑i=1N1{al1i=al2i=⋯=alsi}
Consistencys=∑{l1,l2,…,ls}∈C(s,qi)M{l1,l2,…,ls}C7s \text{Consistency}_s = \frac{\sum_{\{l_1, l_2, \ldots, l_s\} \in C(s, q_i)} M_{\{l_1, l_2, \ldots, l_s\}}}{C_7^s} Consistencys=C7s∑{l1,l2,…,ls}∈C(s,qi)M{l1,l2,…,ls}
- 符号说明:
- ( NNN ):数据集中的问题总数。
- ( qiq^iqi ):第 ( iii ) 个问题,翻译成不同语言(如英语、汉语、印尼语等)。
- ( alkia_{l_k}^ialki ):模型在语言 ( lkl_klk ) 中对问题 ( qiq^iqi ) 的回答。
- ( 1{al1i=al2i=⋯=alsi}\mathbb{1}_{\{a_{l_1}^i = a_{l_2}^i = \cdots = a_{l_s}^i\}}1{al1i=al2i=⋯=alsi} ):指示函数,若模型在 ( sss ) 种语言中的回答完全相同,则为 1,否则为 0。
- ( C(s,qi)C(s, q_i)C(s,qi) ):从 7 种语言中选择 ( sss ) 种语言的所有可能组合。
- ( C7sC_7^sC7s ):组合数,表示从 7 种语言中选择 ( sss ) 种的可能组合数。
- ( sss ):要求一致的语言数量,默认 ( s=3s=3s=3 )。
解释:
- ( M{l1,l2,…,ls}M_{\{l_1, l_2, \ldots, l_s\}}M{l1,l2,…,ls} ) 计算在特定 (sss ) 种语言组合中,模型对所有问题 ( qiq^iqi ) 的回答是否一致的比例。
- ( Consistencys\text{Consistency}_sConsistencys ) 是所有 ( sss ) 种语言组合的平均一致性分数,反映模型在任意 ( sss ) 种语言中的回答一致性。
2. AC3 分数
定义:AC3 分数综合考虑准确率(Accuracy)和一致性分数(Consistency Score),通过调和平均计算:
AC3s=2⋅Accuracy⋅ConsistencysAccuracy+Consistencys AC3_s = 2 \cdot \frac{\text{Accuracy} \cdot \text{Consistency}_s}{\text{Accuracy} + \text{Consistency}_s} AC3s=2⋅Accuracy+ConsistencysAccuracy⋅Consistencys
- 符号说明:
- ( Accuracy\text{Accuracy}Accuracy ):模型在所有语言中的平均正确率。
- ( Consistencys\text{Consistency}_sConsistencys ):上述一致性分数。
- ( AC3sAC3_sAC3s ):范围在 [0, 1],综合反映模型的准确性和一致性。
目的:单独的准确率可能掩盖跨语言不一致问题,而单独的一致性分数不考虑答案正确性。AC3 分数通过调和平均平衡两者,提供更全面的评估。
默认参数:论文中默认使用 ( s=3s=3s=3 ),即要求答案在至少 3 种语言中一致。这一选择基于以下原因:
- 允许一定程度的语言一致性容忍度,不要求所有语言完全一致。
- 适应部分模型可能不支持所有 7 种语言的情况。
- 实验表明,( sss ) 增加(如 ( s=6s=6s=6 ))会导致一致性分数显著下降(如 ChatGPT 的 26%),因此 ( s=3 ) 是折中选择。
示例说明
假设有一个数据集包含 10 个问题(( N=10N=10N=10 )),测试语言为英语(Eng)、汉语(Zho)、印尼语(Ind),共 3 种语言 (( s=3s=3s=3 ))。每个问题有 4 个选项(A, B, C, D),正确答案为 C。模型的回答如下:
| 问题 | 英语 | 汉语 | 印尼语 | 是否一致 | 正确性 |
|---|---|---|---|---|---|
| q1 | C | C | C | 是 | 正确 |
| q2 | A | A | A | 是 | 错误 |
| q3 | B | C | C | 否 | - |
| q4 | C | C | C | 是 | 正确 |
| q5 | D | D | C | 否 | - |
| q6 | C | C | C | 是 | 正确 |
| q7 | A | B | C | 否 | - |
| q8 | C | C | C | 是 | 正确 |
| q9 | B | B | B | 是 | 错误 |
| q10 | C | C | D | 否 | - |
计算一致性分数:
- 一致的问题(所有 3 种语言回答相同):q1, q2, q4, q6, q8, q9(共 6 个)。
- ( M_{{\text{Eng, Zho, Ind}}} = \frac{6}{10} = 0.6 )。
- 由于只有 3 种语言,( C_3^3 = 1 ),因此:
[
\text{Consistency}3 = \frac{M{{\text{Eng, Zho, Ind}}}}{C_3^3} = 0.6
]
计算准确率:
- 正确回答的问题(以英语为例,正确答案为 C):q1, q4, q6, q8(共 4 个)。
- ( Accuracy=410=0.4\text{Accuracy} = \frac{4}{10} = 0.4Accuracy=104=0.4 )(假设只考虑英语;实际中可能取多语言平均)。
计算 AC3 分数:
AC33=2⋅0.4⋅0.60.4+0.6=2⋅0.241.0=0.48
AC3_3 = 2 \cdot \frac{0.4 \cdot 0.6}{0.4 + 0.6} = 2 \cdot \frac{0.24}{1.0} = 0.48
AC33=2⋅0.4+0.60.4⋅0.6=2⋅1.00.24=0.48
分析:
- 一致性分数 0.6 表示模型在 60% 的问题上跨 3 种语言回答一致。
- 准确率 0.4 表明模型在英语中的正确率较低。
- AC3 分数 0.48 综合了两者,反映模型在一致性和准确性上的平衡表现。
扩展到 7 种语言:
若扩展到 7 种语言(如英语、汉语、印尼语、西班牙语、越南语、马来语、菲律宾语),则 ( C73=(73)=35C_7^3 = \binom{7}{3} = 35C73=(37)=35 ),需要计算所有 3 种语言组合的一致性平均值。论文中发现,ChatGPT 在 ( s=6s=6s=6 ) 时一致性仅为 26%,表明跨语言一致性问题显著。
实验发现
- 不一致性现象:大多数模型在跨语言问题上表现出不一致性。例如,ChatGPT 在 Cross-MMLU 数据集上 6 种语言的一致性仅为 26%,表明语义表示在多语言环境中泛化不足。
- 模型差异:
- BLOOMZ:因其平衡的多语言训练语料,在一致性上优于 ChatGPT(54% vs. 47%)。
- GPT-4:一致性最高(75%),但在 ( s=6s=6s=6 ) 时下降至 64%,仍有改进空间。
- 语言资源影响:高资源语言(如英语、汉语)的一致性和准确率高于低资源语言(如印尼语、越南语)。
其他文献中的跨语言一致性指标
虽然 SeaEval 的跨语言一致性指标较为新颖,但其他文献中也有相关研究探讨了多语言模型的跨语言性能一致性。以下是一些相关指标和方法:
1. M3Exam (Zhang et al., 2023)
- 指标:M3Exam 是一个多语言、多模态、多级别的评估基准,测试模型在 9 种语言中的考试问题表现。它未明确提出“一致性分数”,但通过比较模型在不同语言中的准确率(Accuracy)间接评估跨语言一致性。
- 方法:使用相同的考试问题(如数学、科学)翻译成多种语言,计算每种语言的准确率,并分析性能差异。例如,模型在英语中的准确率可能显著高于低资源语言,暗示跨语言不一致。
- 差异:M3Exam 更注重准确率比较,未引入类似 SeaEval 的 Consistency Score 来专门量化回答一致性。
2. XGLUE (Liang et al., 2020)
- 指标:XGLUE 是一个跨语言理解和生成基准,包含任务如跨语言自然语言推理(XNLI)。它通过跨语言任务的准确率和 F1 分数评估模型,但也关注跨语言迁移能力。
- 方法:XNLI 数据集提供 15 种语言的平行句子对,测试模型在不同语言中的一致性表现。例如,模型在英语训练后,在其他语言上的推理准确率下降,反映了跨语言不一致性。
- 差异:XGLUE 侧重于任务迁移性能,未明确量化回答一致性,且数据集中问题并非完全语义等价。
3. XTREME (Hu et al., 2020)
- 指标:XTREME 是一个多语言基准,覆盖 40 种语言,测试跨语言迁移能力。它使用零样本跨语言迁移(Zero-shot Cross-lingual Transfer)的准确率差异来评估模型一致性。
- 方法:在英语上训练模型后,测试其在其他语言上的性能。例如,在 XNLI 任务中,模型在英语上的准确率与目标语言的准确率差异反映了跨语言一致性问题。
- 差异:XTREME 关注迁移性能,未设计专门的一致性指标,且测试场景多为单向迁移而非多语言平行回答。
4. Multilingual Machine Translation (Zhu et al., 2023a)
- 指标:Zhu 等人评估了大型语言模型在多语言机器翻译任务中的性能,使用 BLEU 分数比较翻译质量。他们通过分析模型在不同语言对上的翻译一致性(语义等价性)间接探讨跨语言一致性。
- 方法:测试模型将同一句子翻译成多种目标语言,比较翻译结果的语义一致性。例如,若模型将英语句子翻译成汉语和西班牙语时语义不一致,则表明跨语言能力不足。
- 差异:该方法更适用于生成任务,未针对多选题设计一致性分数,且未使用调和平均综合准确率和一致性。
5. MEGA (Ahuja et al., 2023)
- 指标:MEGA 是一个多语言生成模型评估基准,测试模型在生成任务(如摘要、问答)中的跨语言一致性。它使用 ROUGE 分数和人类评估来比较不同语言生成内容的语义一致性。
- 方法:要求模型在多种语言中生成相同内容的回答,评估生成文本的语义等价性。例如,模型在英语和汉语中回答同一问题时,生成内容的 ROUGE 分数差异反映一致性。
- 差异:MEGA 更适合开放式生成任务,而 SeaEval 专注于多选题的量化一致性评估。
比较与讨论
- SeaEval 的独特性:
- 明确定义了 Consistency Score 和 AC3 分数,专门针对多选题的跨语言一致性。
- 通过调和平均(AC3)综合准确率和一致性,平衡了两者的评估需求。
- 针对语义等价的常识性问题设计平行数据集(如 Cross-MMLU),更直接地测试语义泛化能力。
- 其他方法的局限性:
- 大多数基准(如 XGLUE、XTREME)通过准确率差异间接评估一致性,缺乏专门的一致性指标。
- 生成任务(如 MEGA)的一致性评估依赖语义相似性度量(如 ROUGE),难以量化多选题场景。
- 现有研究多关注高资源语言,SeaEval 则涵盖低资源语言(如印尼语、菲律宾语),更全面。
结论与建议
SeaEval 的跨语言一致性指标(Consistency Score 和 AC3 分数)通过量化模型在多语言平行问题上的回答一致性,揭示了多语言模型在语义泛化上的不足。其公式设计直观,适用于多选题场景,且通过 ( s ) 参数灵活调整一致性要求。示例分析表明,模型如 ChatGPT 和 GPT-4 在高资源语言中表现较好,但在低资源语言和严格一致性要求(高 ( s ) 值)下性能下降。
其他文献中的跨语言一致性评估多依赖准确率差异或生成任务的语义相似性,缺乏 SeaEval 的直接量化方法。未来研究可结合 SeaEval 的指标与生成任务的语义一致性评估(如 ROUGE 或 BERTScore),开发更综合的跨语言一致性框架。此外,扩展到更多语言和开放式问题场景将进一步增强评估的全面性。
后记
2025年5月23日于上海,在grok 3大模型辅助下完成。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









