






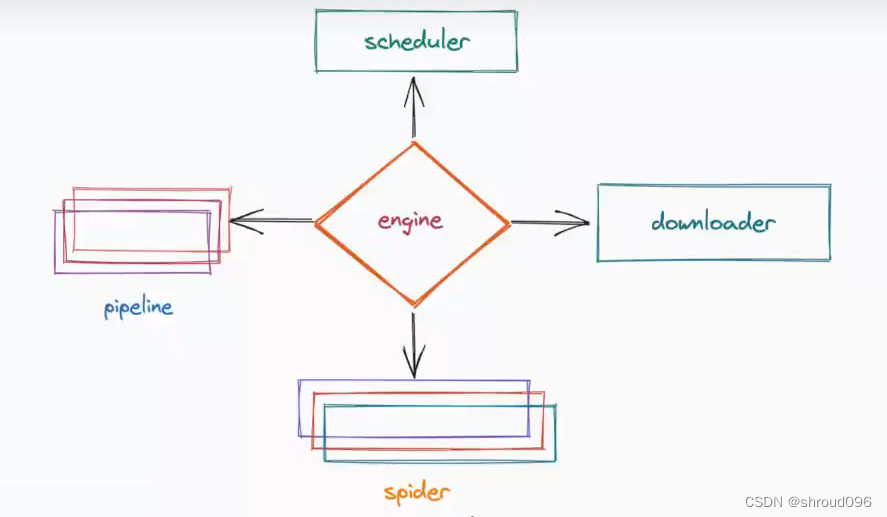
管道:用于数据存储
ctrl+f 在网页的控制台搜索
ctrl+x删除一行
ctrl+d复制一行
1.安装scrapy
2.
scrapy startproject game
//创建scrapy工程,名字为gamecd game
scrapy genspider xiao 4399.com
//创建爬虫,名字为game,要爬取的域名为4399.com

运行项目
scrapy crawl xiao
底下的是日志信息
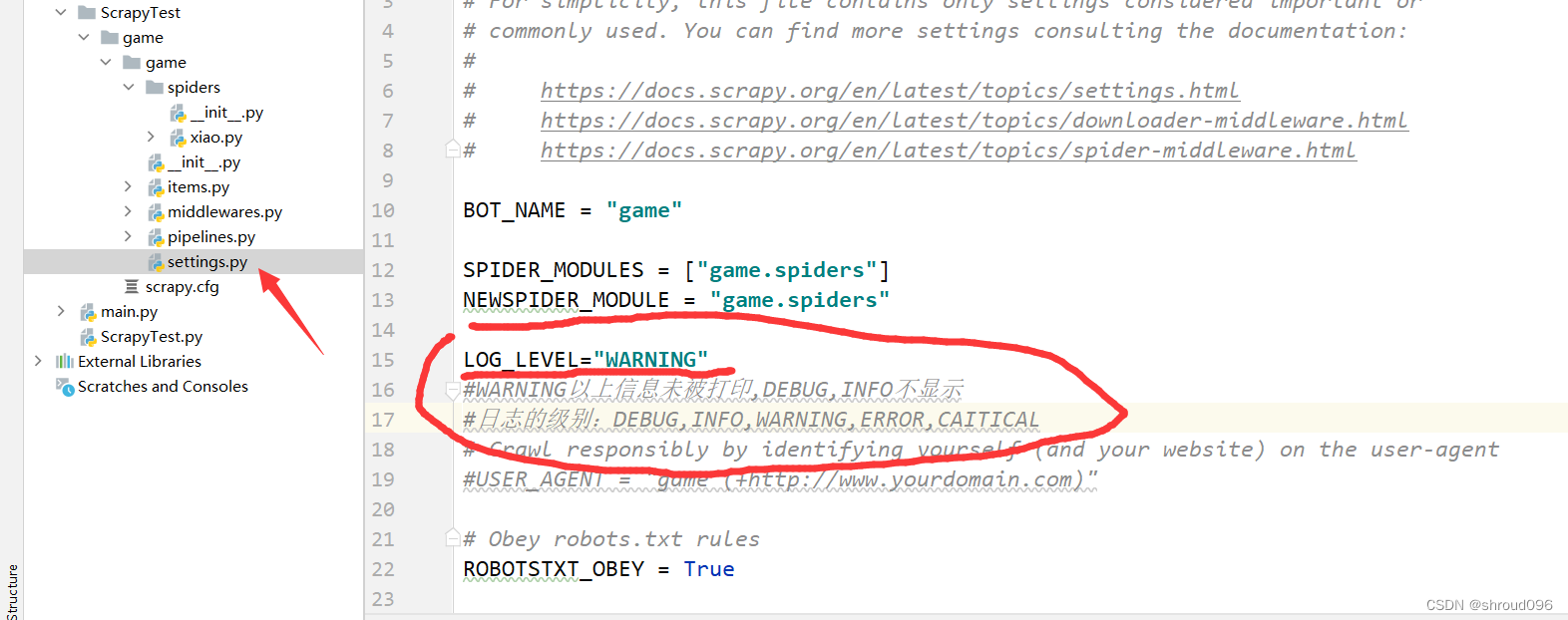
设置日志信息的显示:
设置级别为wraning,在此之下的信息不显示
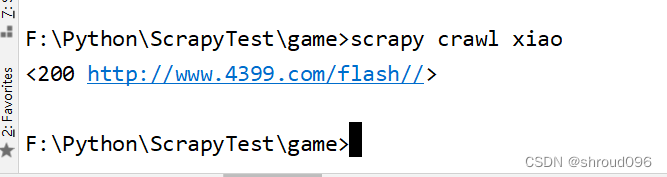
设置之后的结果
获取4399所有的游戏名称(一次性获取)xpath
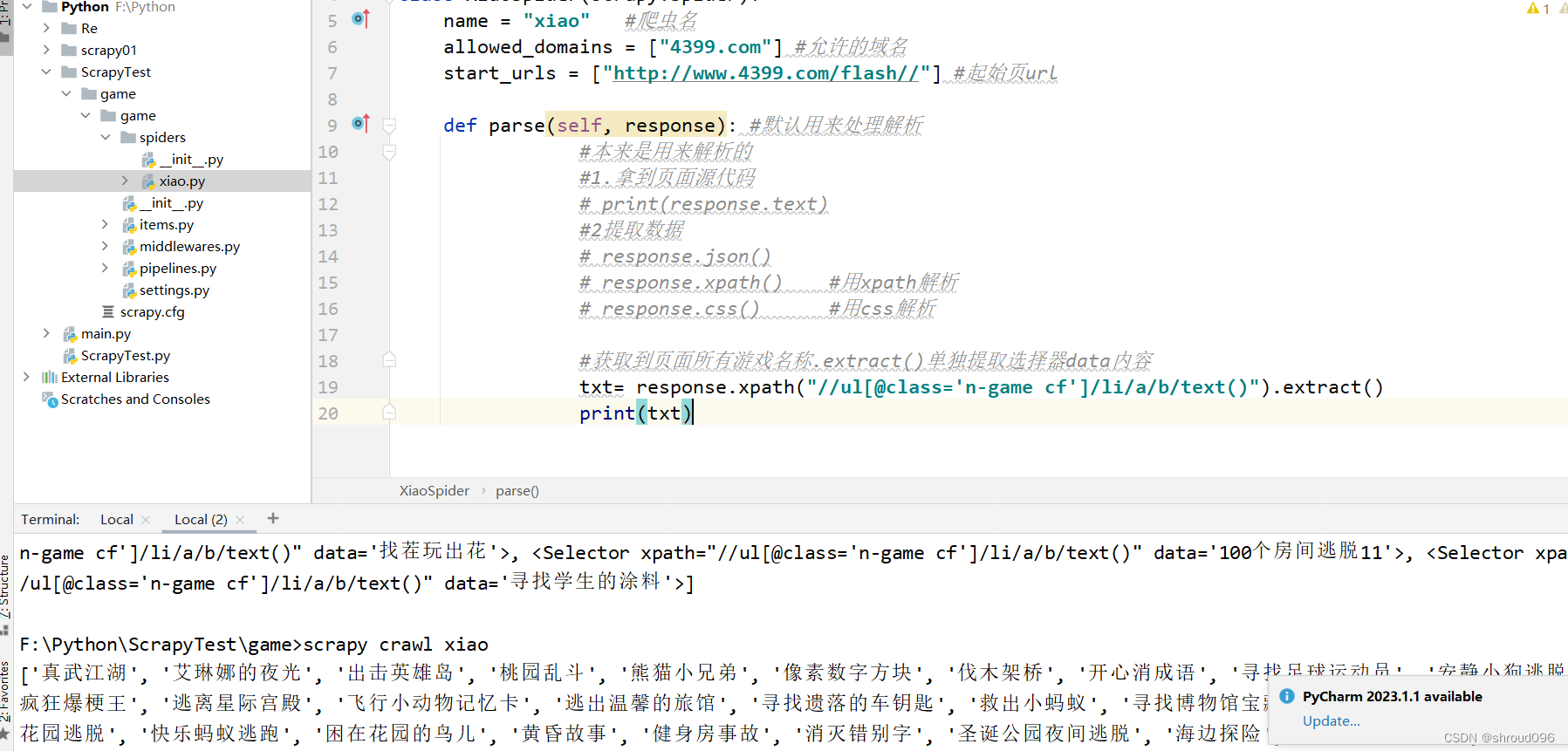
分块提取数据
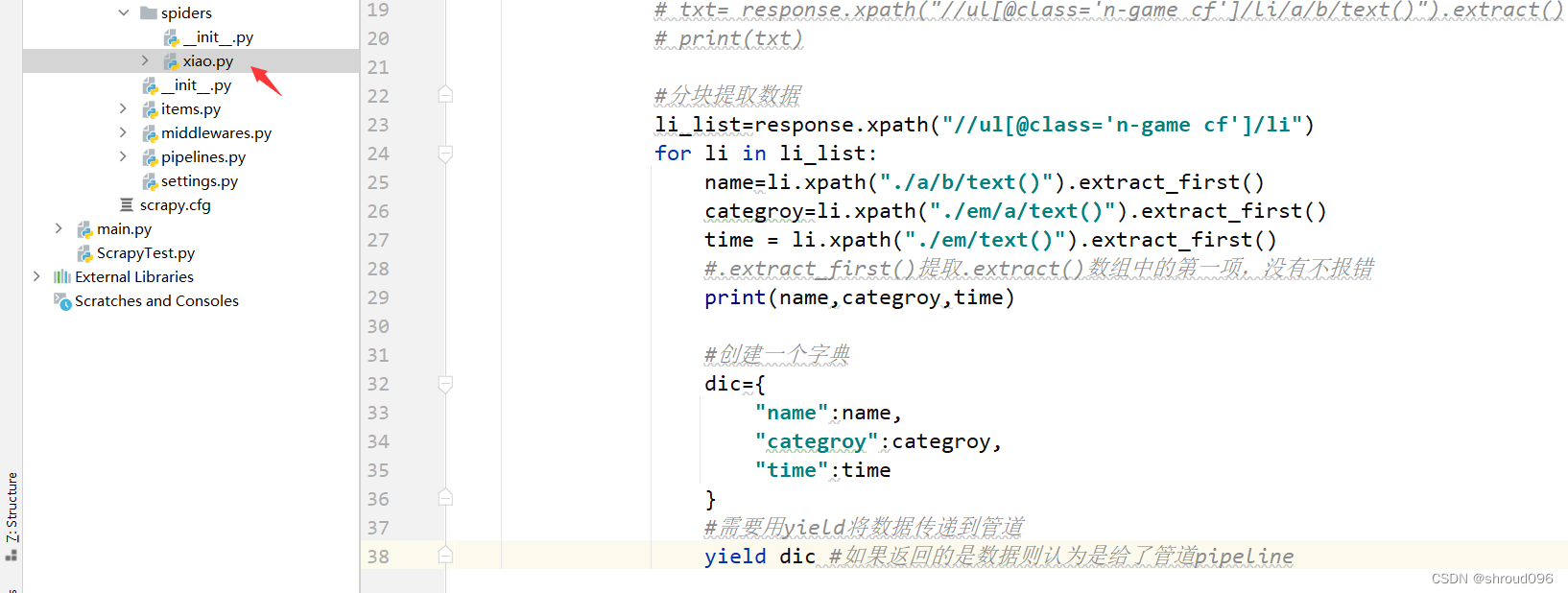
在setting中吧管道打开,找到管道代码,取消注释(默认是注释掉的)

接下来就可以使用管道了
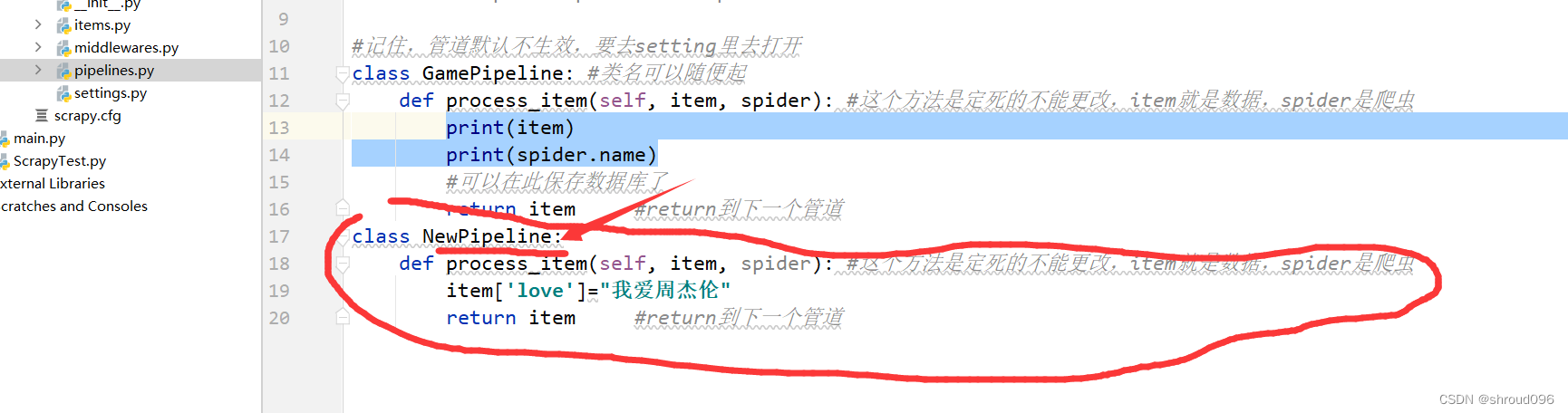
创建第二个管道,设置优先级,在setting中设置优先级

总结:
1.创建项目
scrapy startproject 项目名
2.进入项目
cd 项目名称
3.创建爬虫
scrapy genspider 名字 域名
4.可能需要修改statr_urls,修改成你要抓取的哪个页面
5.对数据进行解析,在spider里面的parse(response)方法中进行解析
def parse(self, response): # response.text #拿页面源代码 # response.xpath() #用xpath解析 # response.css() #用css解析解析数据时,要注意默认xpath()返回的是Selector对象
想要数据必须使用extract()提取数据
extract()返回列表
extract——first()返回一个数据
yield返回数据 把数据交给pipeline来进行持久化存储
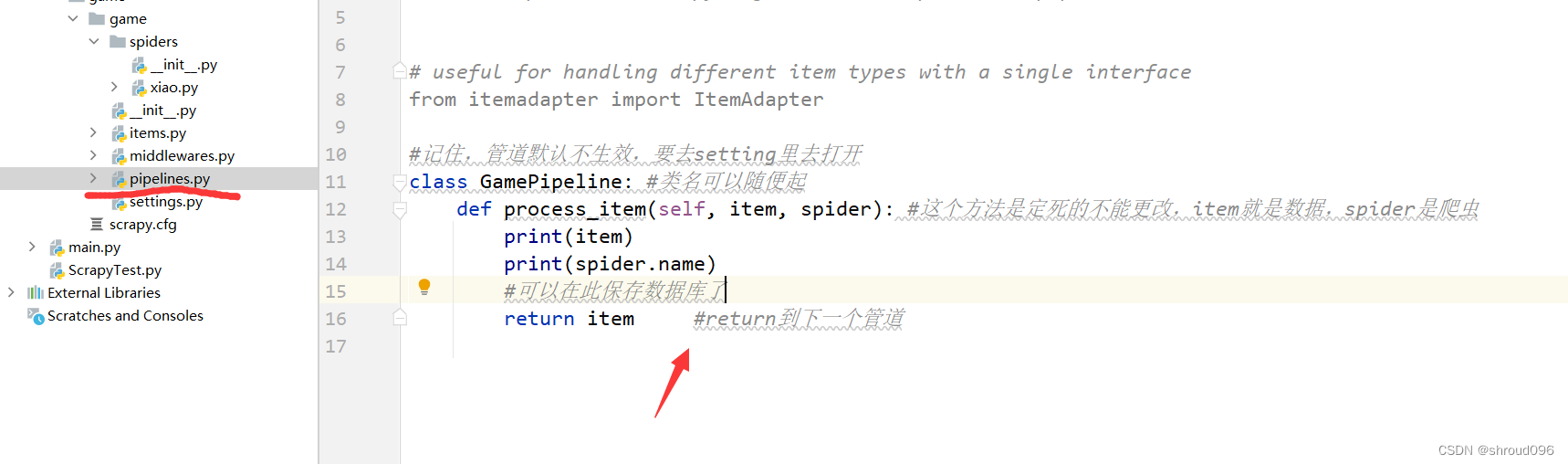
6.在pipline中完成数据存储
class 类名:
def process_item(self, item, spider):
item:数据
spider:爬虫
return item #必须要ruturn东西,不然下一个管道收不到
7.设置settings.py文件将pipeline进行生效设置
ITEM_PIPELINES = {
#key是管道的路径,value是管道的优先级,数越小,优先级越高,默认300
"game.pipelines.GamePipeline": 300,
}
8.运行爬虫
scrapy crawl 爬虫名字















 59万+
59万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









