







目录
一、前情提要
上篇文章我们讨论了什么是抽象数据类型,线性表的线性存储和链式存储。并给出了线性储存的代码。本篇将围绕链式储存的概念,给出介绍和代码分析。可能有人会想,为啥线性表还有(下)这一篇。。主要是后面还有什么静态链表、循环链表、双向链表等等会在下一篇介绍也会给出代码。这一篇主要讲链式储存中单链表的概念和代码。
二、单链表——最简单的链式存储结构
在学C语言的时候大家应该接触过链表这个东西,简单的来说就是用指针将两个不同的结点链接起来。类似于一根链子连接两个不同的物体。
上面是链表的概念,何为单链表呢?单链表顾名思义就是单向的,遍历链表只能一个方向遍历,因为指针是有方向的(A->B)。后面的双链表就是既可以从左往右遍历也可以从右向左遍历(A->B&&B->A)。
(一)单链表的结构
单链表是由结点组成的,每个结点里会存在两个部分:指针域和数据域。
为了表示每个数据元素Ai与其后继数据元素A(i+1)之间的逻辑关系,对于数据元素Ai来说,除了存储本身的信息之外,还要存储一个“指示其直接后继的信息”(即直接后继的存储位置)。
我们把存储数据元素信息的域称为数据域。把存储直接后继位置的域称为指针域。
由这两部分组成数据元素Ai,称之为结点(Node)
————《大话数据结构》
上面一段话我摘自一本书中,我觉得解释的很清楚直接贴上去了。
n个结点连结成一个链表,即为线性表(A1,A2,A3...,An)的链式存储结构。由于链表中只有1个指针域,所以只能单向的遍历,所以叫单链表。
(二)结点与头指针
对于线性表来说,总会有头有尾。单链表就是最简单的线性表,所以肯定有个头。
我们把链表中第一个结点的存储位置叫做头指针 。所以说知道头指针就掌握了整个单链表。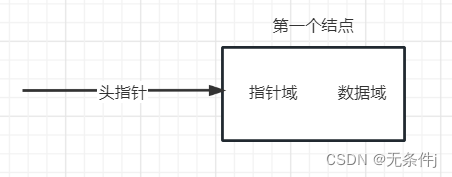
注意:第一个结点里的指针域和头指针不是一个玩意,没有任何的联系。指针域是指向下一个节点的指针,头指针是指向第一个结点的指针。
说完了头再说一下尾。最后一个结点一样有两个区域,一个数据域储存数据,另一个是指针域指向为“空”(NULL),因为它没有后继了嘛。
(三)头结点与首元结点
头结点和首元结点是两个不同的概念。
头结点:头指针指向的结点,它的数据域中不存在数据。如果有数据他就是首元结点,如果没有数据他就是头结点。
首元结点:第一个数据域中有数据的结点。如果存在头结点,那么首元结点就是头结点后面的第一个结点。
从上面定义就可以看出来,头结点并不是必需的,它可以没有头结点,头指针直接指向首元结点。这么做确实没问题。逻辑上行得通。但计算机里面存在一定有它的道理。为什么存在理由如下。
我们先看有头结点的单链表

这是有头结点的单链表,此时我要插入两个结点。这俩结点肯定是插到头结点后面,因为头结点后面的结点才有意义。
具体步骤是:
1.先创建新的结点。
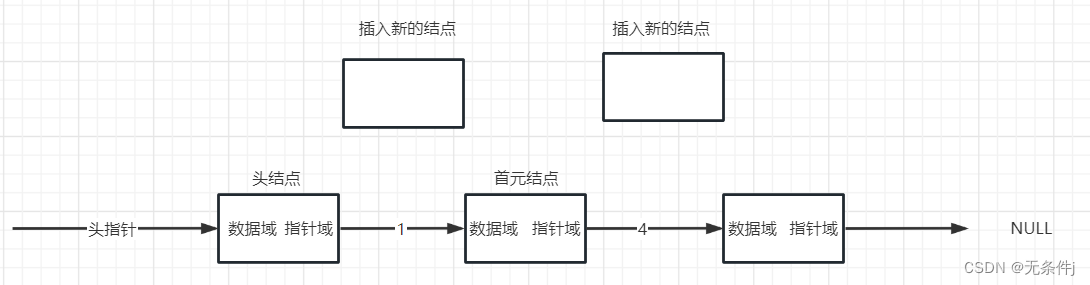
2.然后将新的结点中指针域指向要插入的那个位置上的结点。
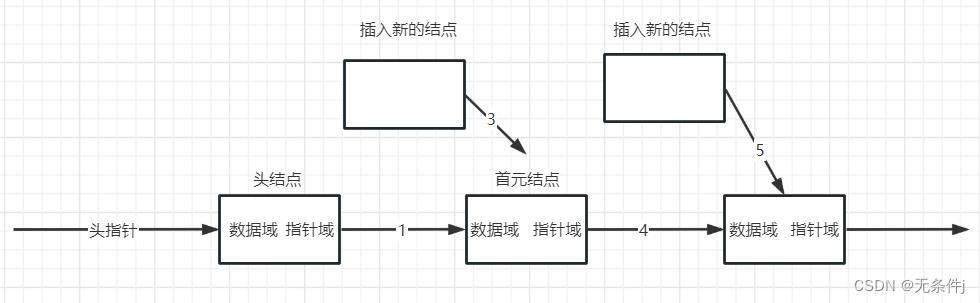
3.再将上一个位置结点的指针域修改成指向新的结点

由上面的步骤我们可以看出来,添加的这两个结点,步骤完全相同,可以用同一份代码完成。
反观没有头结点的单链表

此时我要添加两个新的结点进去。我选择一个放在首元结点前面,这样新的结点就变成了首元结点,另外一个放在首元结点后面。
我们再按上面步骤来一遍。
1.先创建新的结点。
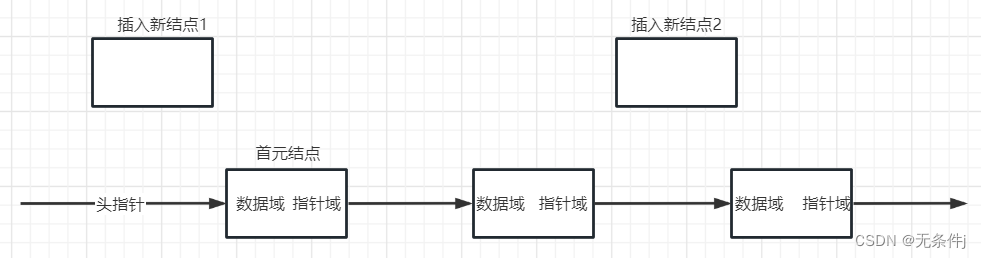
2.然后将新的结点中指针域指向要插入的那个位置上的结点。
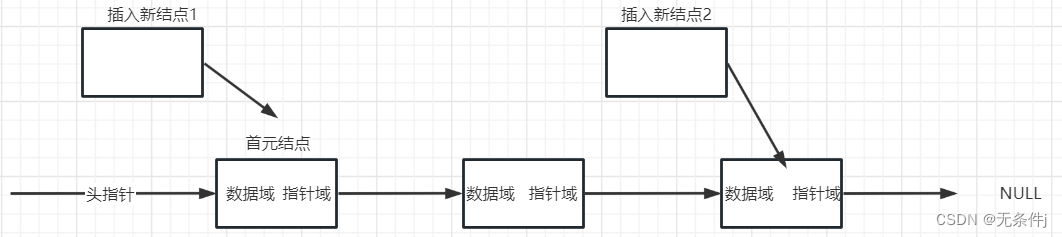
3.再将上一个位置结点的指针域修改成指向新的结点
到了这一步,咱就发现问题了。新插入的结点2按照步骤完全没问题。
但是新插入的结点1是在首元结点前面,首元结点上一个位置不存在结点,要想插入只能改变头指针。
综上所述,我们可以看出新插入的结点1和新插入的结点2,所需要的步骤不一样,要两份不同的代码。这就很蛋疼。所以一般情况下,为了一致性我们都会去采用带有头结点的单链表。
三、单链表的相关操作
不论哪种存储方式相关操作都差不多,比如:输出表中数据(PrintList),清空表中数据(MakeEmpty),查找数据(Find),插入元素(Insert),删除元素(Delete),返回某个位置上的元素(FindKth)。
直接上代码吧,光说有点抽象,注释我尽量写的详细。
其中有几个操作得细细品味一下,自己动手操作。
#include <stdio.h>
#include <stdlib.h>
//此处Node和LinkList的区别,Node是结点,LinkList就是头指针。
typedef struct NodeList
{
int data;
struct NodeList* Next;
}Node,*LinkList;
LinkList InitList()
{
LinkList Ptr=(Node*)malloc(sizeof(Node));//声明头指针,并开辟一块内存。这块地方就是头结点。
if(Ptr==NULL)
{
printf("申请内存失败\n");
}
else
{
Ptr->Next=NULL;//先开始只有头结点,头结点后面指向空。
}
return Ptr;
}
//输出该链表上所有元素
void PrintList(LinkList Ptr)//传入头指针。
{
if(Ptr->Next==NULL)
{
printf("该链表没有结点\n");
return;
}
for(Node* i=Ptr->Next;i!=NULL;i=i->Next) //循环遍历就好
{
printf("%d ",i->data);
}
printf("\n");
}
//查找对应的元素
Node* Find(LinkList Ptr,int x)
{
for(Node* i=Ptr;i!=NULL;i=i->Next) //从头结点开始遍历,一直到最后指针域指向NULL
{
if(i->data==x) //判断一下
{
printf("已找到对应元素所对应结点\n");
return i; //i是地址,是所对应结点的地址。
}
}
printf("未找到对应元素所对应结点\n");//都遍历完了还没有return回去,说明没找到。
return NULL;
}
//头插 ,在头结点之后插一个结点
void HeadInsert(LinkList Ptr,int x)
{
Node* New_Node=(Node*)malloc(sizeof(Node)); //为新的结点开辟一块内存
if(New_Node==NULL)
{
printf("开辟内存失败\n");
return;
}
New_Node->data=x; //给新的结点赋值
New_Node->Next=Ptr->Next; //新的结点Next指针指向头结点指向的地方。
Ptr->Next=New_Node; //头指针的Next指针指向新结点的地方。
}
//尾插
void TailInsert(LinkList Ptr,int x)
{
Node* New_Node=(Node*)malloc(sizeof(Node));//为新的结点开辟内存
if(New_Node==NULL)
{
printf("开辟内存失败\n");
return;
}
for(Node* i=Ptr;i!=NULL;i=i->Next)//由于是单链表找到末尾必须从头遍历
{
if(i->Next==NULL) //找到之后
{
New_Node->Next=i->Next; //新的结点指针指向该结点后面的地方。
New_Node->data=x; //给新结点赋值
i->Next=New_Node; //该结点指针指向新结点
return;
}
}
}
//在值为k的结点后面插
void FindInsert(LinkList Ptr,int k,int x)
{
Node* Tar_Node=Find(Ptr,k);//找到目标结点
if(Tar_Node==NULL)
{
printf("不存在该结点\n");
return;
}
Node* New_Node=(Node*)malloc(sizeof(Node)); //步骤和上面一样
New_Node->data=x;
New_Node->Next=Tar_Node->Next;
Tar_Node->Next=New_Node;
}
//删除值为k的结点
void Delete(LinkList Ptr,int k)
{
if(Ptr->Next==NULL)
{
printf("该表为空\n");
return;
}
Node* Tar_Node=Find(Ptr,k); //找到与之对应的结点,并记录为目标结点Tar_Ptr
if(Tar_Node==NULL) //如果没找到就返回
{
printf("没有匹配的节点\n");
return;
}
Node* Pre_Node=Ptr; //删除的时候需要找到要删除结点的上一个结点。因为我们的想法是A->B->C,使之变成A->C。
//可以看出要删除B必须找到A的结点,改变结点的Next指针
while(Pre_Node!=NULL&&Pre_Node->Next!=Tar_Node)//利用循环找到目标结点的上一个结点
{
Pre_Node=Pre_Node->Next;
}
Pre_Node->Next=Tar_Node->Next; //上一个结点的Next指针指向改变成目标结点的下一个。就是绕过目标节点
free(Tar_Node); //最后释放掉要删除节点的内存
Tar_Node=NULL;
}
//清空表中数据
void MakeEmpty(LinkList Ptr)
{
if(Ptr->Next==NULL) //先判断是否为空
{
printf("此表为空\n");
return;
}
Node* Last=Ptr->Next;
Node* Front; //先定义两个Node*的指针。一前一后
while(Last!=NULL) //先开始Last指向首元结点,然后进入循环。
{ //然后Front指向Last的Next结点。
Front=Last->Next; //这一步的原因是,我们要保证删除节点之后,还能找下一个节点。
free(Last); //然后删除Last所指结点,解决完这一个,就开始下一个。
Last=Front; //最后Last指针指向Front所在结点,这一步对应的上面Front=Last->Next。
} //只有Front在之前记录Last下一个结点的位置,这样free(Last)之后Last才能定位到下一个位置上。
Ptr->Next=NULL; //一直循环直到表中除了头结点都为空。最后将头指针的Next指向NULL。
} //千万别忘了最后一步,如果忘了,头指针的Next指向的是一块被释放过的区域。
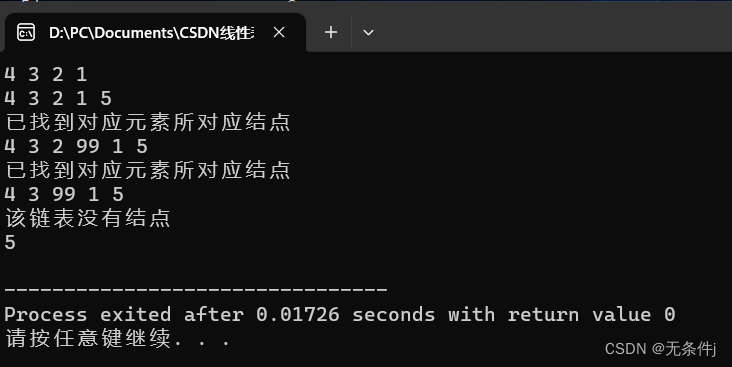
int main()
{
LinkList Pointer=InitList();
HeadInsert(Pointer,1);
HeadInsert(Pointer,2);
HeadInsert(Pointer,3);
HeadInsert(Pointer,4);
PrintList(Pointer);
TailInsert(Pointer,5);
PrintList(Pointer);
FindInsert(Pointer,2,99);
PrintList(Pointer);
Delete(Pointer,2);
PrintList(Pointer);
MakeEmpty(Pointer);
PrintList(Pointer);
HeadInsert(Pointer,5);
PrintList(Pointer);
return 0;
} 















 181
181











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









