







目录
前言
去年打比赛期间,深入学习了mmdetection框架,今年有个项目着急看效果,在A100服务器上重新安装了mm,发现已经是3.X版本了,改动了一些函数,故重新记录一下。
安装mmcv
pip install -U openmim
mim install mmengine
mim install "mmcv>=2.0.0"
安装mmdetection
git clone https://github.com/open-mmlab/mmdetection.git
cd mmdetection
pip install -v -e .
# "-v" means verbose, or more output
# "-e" means installing a project in editable mode,
# thus any local modifications made to the code will take effect without reinstallation.
验证安装
mim download mmdet --config rtmdet_tiny_8xb32-300e_coco --dest .
python demo/image_demo.py demo/demo.jpg rtmdet_tiny_8xb32-300e_coco.py --weights rtmdet_tiny_8xb32-300e_coco_20220902_112414-78e30dcc.pth --device cpu
出现下图,则证明安装成功

数据集
数据集采用的是布匹瑕疵检测的数据集,
转为COCO
首先将下载后的标签文件转为COCO格式
import json
from tqdm import tqdm
import cv2, os
from glob import glob
from collections import defaultdict
base_dirs = ['/home/xray/guangdong1_round1/', ]
mp = {"破洞": 1, "水渍": 2, "油渍": 2, "污渍": 2, "三丝": 3, "结头": 4, "花板跳": 5, "百脚": 6, "毛粒": 7,
"粗经": 8, "松经": 9, "断经": 10, "吊经": 11, "粗维": 12, "纬缩": 13, "浆斑": 14, "整经结": 15, "星跳": 16, "跳花": 16,
"断氨纶": 17, "稀密档": 18, "浪纹档": 18, "色差档": 18, "磨痕": 19, "轧痕": 19, "修痕":19, "烧毛痕": 19, "死皱": 20,
"云织": 20, "双纬": 20, "双经": 20, "跳纱": 20, "筘路": 20, "纬纱不良": 20
}
def make_coco_traindataset(images2annos, name='train'):
idx = 1
image_id = 20190000000
images = []
annotations = []
for im_name in tqdm(images2annos):
# im = cv2.imread(base_dir + 'defect_Images/' + im_name)
# h, w, _ = im.shape
h, w = 1000, 2446
image_id += 1
image = {'file_name': im_name, 'width': w, 'height': h, 'id': image_id}
images.append(image)
annos = images2annos[im_name]
for anno in annos:
bbox = anno[:-1]
seg = [bbox[0], bbox[1], bbox[0], bbox[3],
bbox[2], bbox[3], bbox[2], bbox[1]]
bbox = [bbox[0], bbox[1], bbox[2] - bbox[0], bbox[3] - bbox[1]]
anno_ = {'segmentation': [seg], 'area': bbox[2] * bbox[3], 'iscrowd': 0, 'image_id': image_id,
'bbox': bbox, 'category_id': anno[-1], 'id': idx, 'ignore': 0}
idx += 1
annotations.append(anno_)
ann = {}
ann['type'] = 'instances'
ann['images'] = images
ann['annotations'] = annotations
category = [{'supercategory':'none', 'id': id, 'name': str(id)} for id in range(1, 21)]
ann['categories'] = category
json.dump(ann, open(base_dir + '{}.json'.format(name),'w'))
for idx, base_dir in enumerate(base_dirs, 1):
annos = json.load(open(base_dir + 'Annotations/anno_train.json'))
images2annos = defaultdict(list)
for anno in annos:
images2annos[anno['name']].append(anno['bbox'] + [mp[anno['defect_name']]])
make_coco_traindataset(images2annos, 'train' + str(idx))
划分训练集、验证集及测试集
采用的是paddleX工具进行划分,比例为7:2:1
安装PaddlePaddle
python -m pip install paddlepaddle-gpu==2.2.2 -i https://mirror.baidu.com/pypi/simple
安装PaddleX
pip install paddlex -i https://mirror.baidu.com/pypi/simple
划分数据集
paddlex --split_dataset --format COCO --dataset_dir D:/MyDataset --val_value 0.2 --test_value 0.1
修改对应文件
修改coco.py
路径 /mmdetection/mmdet/dataset/coco.py
将类别修改为自己的类别名称。
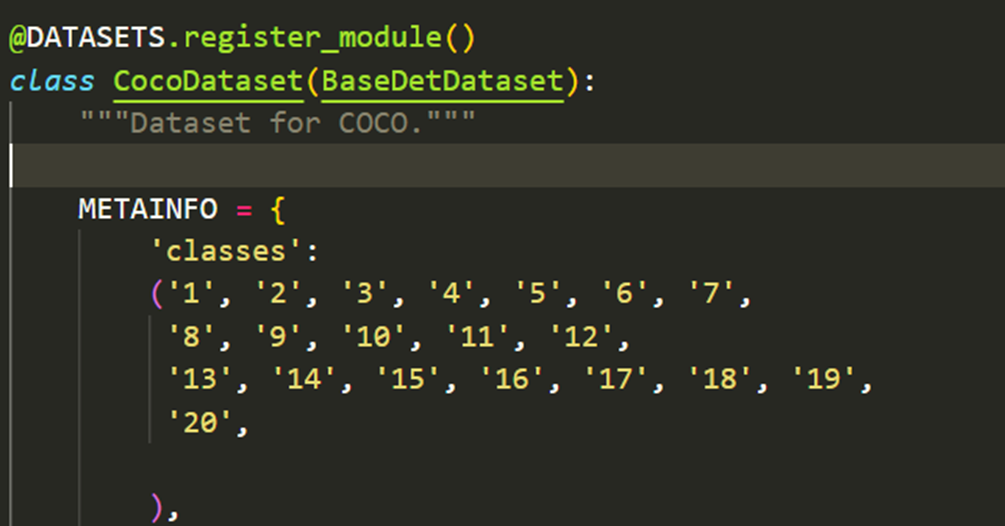
重新安装
重新执行下述命令,修改才会生效。
pip install -v -e .
修改模型文件
ctrl+F 查找 num_classes, 改为自己数据集的类别数量,不需要加背景
训练
python tools/train.py \
${CONFIG_FILE} \
[optional arguments]
测试
测试带真值的图像
将测试结果保存到文件夹中
python tools/test.py \
configs/rtmdet/rtmdet_l_8xb32-300e_coco.py \
checkpoints/rtmdet_l_8xb32-300e_coco_20220719_112030-5a0be7c4.pth \
--show-dir faster_rcnn_r50_fpn_1x_results
测试不带真值的图像
批量测试
Todo
错误集锦
验证安装提示错误:‘NoneType’ object has no attribute ‘copy’
File “/home/yrx/miniconda3/envs/openmmlab/lib/python3.8/site-packages/mmengine/dist/utils.py”, line 401, in wrapper
return func(*args, **kwargs)
File “/home/yrx/miniconda3/envs/openmmlab/lib/python3.8/site-packages/mmengine/visualization/visualizer.py”, line 551, in draw_texts
self.ax_save.text(
File “/home/yrx/miniconda3/envs/openmmlab/lib/python3.8/site-packages/matplotlib/cbook/deprecation.py”, line 358, in wrapper
return func(*args, **kwargs)
File “/home/yrx/miniconda3/envs/openmmlab/lib/python3.8/site-packages/matplotlib/axes/_axes.py”, line 770, in text
t.update(effective_kwargs)
File “/home/yrx/miniconda3/envs/openmmlab/lib/python3.8/site-packages/matplotlib/text.py”, line 177, in update
super().update(kwargs)
File “/home/yrx/miniconda3/envs/openmmlab/lib/python3.8/site-packages/matplotlib/artist.py”, line 1006, in update
ret = [_update_property(self, k, v) for k, v in props.items()]
File “/home/yrx/miniconda3/envs/openmmlab/lib/python3.8/site-packages/matplotlib/artist.py”, line 1006, in
ret = [_update_property(self, k, v) for k, v in props.items()]
File “/home/yrx/miniconda3/envs/openmmlab/lib/python3.8/site-packages/matplotlib/artist.py”, line 1003, in _update_property
return func(v)
File “/home/yrx/miniconda3/envs/openmmlab/lib/python3.8/site-packages/matplotlib/text.py”, line 1224, in set_fontproperties
self._fontproperties = fp.copy()
AttributeError: ‘NoneType’ object has no attribute ‘copy’
解决方案:
pip uninstall matplotlib
重新安装最新版的
pip install matplotlib
ValueError: need at least one array to concatenate
解决方案: 修改coco.py文件对应的类别
Downgrade the protobuf package
If you cannot immediately regenerate your protos, some other possible workarounds are: 1. Downgrade the protobuf package to 3.20.x or lower. 2. Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and will be much slower).
解决方案:
卸载原有的
重新安装低版本的
pip uninstall protobuf
pip install protobuf==3.20.0















 719
719











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









