







PyTorch的基本概念
Tensor
有时遇到的数据是很高维度的,很难使用矩阵或向量来描述,这时就用张量来描述任意维度的物体
Tensor与机器学习的关系
Tensor与机器学习的关系
我们使用tensor来对样本和模型进行描述
Tensor的类型

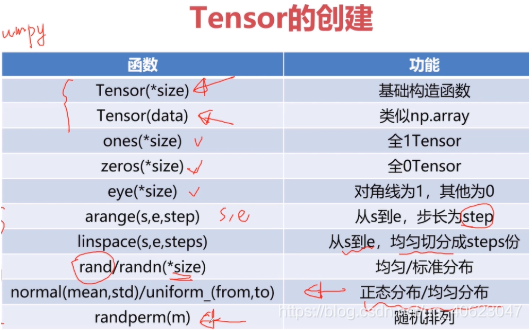
Tensor的创建
Tensor创建编程实例
import torch
import numpy as np
"""
几种特殊的tensor
"""
a = torch.Tensor([[1, 2], [3, 4]])
print(a)
print(a.type())
"""
输出:
tensor([[1., 2.],
[3., 4.]])
torch.FloatTensor
"""
#对比
a1 = np.array([[1, 2], [3, 4]])
print(a1)
"""
输出:
[[1 2]
[3 4]]
"""
b = torch.Tensor(2, 3) # 定义一个2×3的二阶tensor
# 使用shape来定义时,初始值为随机值
print(b)
print(b.type())
"""
输出:
tensor([[9.5461e-01, 4.4377e+27, 1.7975e+19],
[4.6894e+27, 7.9463e+08, 5.0944e-14]])
torch.FloatTensor
"""
c = torch.ones(2, 2) # 定义一个2×2的二阶tensor,值全为“1”
print(c)
print(c.type())
"""
输出:
tensor([[1., 1.],
[1., 1.]])
torch.FloatTensor
"""
d = torch.eye(2, 2) # 定义一个2×2的二阶tensor,对角线值全为“1”,其他为“0”
print(d)
print(d.type())
"""
输出:
tensor([[1., 0.],
[0., 1.]])
torch.FloatTensor
"""
e = torch.zeros(2, 2) # 定义一个2×2的二阶tensor,值全为“0”
print(e)
print(e.type())
"""
输出:
tensor([[0., 0.],
[0., 0.]])
torch.FloatTensor
"""
f = torch.zeros_like(b) # 跟某个tensor拥有相同的shape,且值全为“0”
print(f)
print(f.type())
"""
输出:
tensor([[0., 0., 0.],
[0., 0., 0.]])
torch.FloatTensor
"""
g = torch.ones_like(b) # 跟某个tensor拥有相同的shape,且值全为“1”
print(g)
print(g.type())
print("+++++++++++++++++++++++++++++++++++++++++")
'''
输出:
tensor([[1., 1., 1.],
[1., 1., 1.]])
torch.FloatTensor
'''
'''
随机
'''
h = torch.rand(2, 2) # 随机生成某个shape的tensor
print(h)
print(h.type())
'''
输出:
tensor([[0.9980, 0.0754],
[0.2034, 0.8852]])
torch.FloatTensor
'''
i = torch.normal(mean=0.0, std=torch.rand(5))
# 构造5组不同的高斯分布,均值为“0”和标准差随机
# 生成随机满足正态分布的值
print(i)
print(i.type())
'''
输出:
tensor([-0.5050, -0.6762, -0.9310, 0.9907, -0.1264])
torch.FloatTensor
'''
j = torch.normal(mean=torch.rand(5), std=torch.rand(5))
# 构造5组不同的高斯分布,均值和标准差随机
# 生成随机满足正态分布的值
print(j)
print(j.type())
'''
输出:
tensor([0.9474, 0.6925, 0.1974, 0.1186, 1.5995])
torch.FloatTensor
'''
k = torch.Tensor(2, 2).uniform_(-1, 1)
# 定义均匀分布
# 需要先指定tensor的大小,然后再定义(-1,1)之间的均匀分布
# 生成随机满足均匀分布的值
print(k)
print(k.type())
print("++ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 182
182











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









