







10,PyTorch与线性代数
范数:
- 在泛函分析中,它定义在赋范线性空间中,并满足一定的条件,即:非负性,齐次性,三角不等式
- 常被用来度量某个向量空间(或矩阵)中的每个向量的长度或大小
零范数/1范数/2范数(欧氏距离)/p范数/核范数:
- torch.dist(input, other, p=2) #计算p范数
- torch.norm() #计算2范数
- 定义loss,正则化约束模型参数

11,矩阵分解:
常见矩阵分解方法:
LU分解:讲矩阵A分解成L(下三角)矩阵和U(上三角)矩阵的乘积
QR分解:将原矩阵分解成一个正交矩阵Q和一个上三角矩阵R的乘积
EVD分解:特征值分解(如:PCA-无监督)
SVD分解:奇异值分解(如:LDA-引入学习-有监督)
特征值分解:
将矩阵分解为由其特征值和特征向量表示的矩阵之积的方法(线性代数)
满足被分解矩阵可相似对角化(满秩,方阵)EVD
不满足满秩条件或者不是方阵的就是奇异矩阵,要用SVD分解
PCA与特征值分解:
- PCA:将n维特征映射到k维上,这k维是全新的正交特征也被称为主成分,是在原有n维特征的基础上重新构造出来的k维特征
- B(k×n).dot(A(n×m))=A'(k×m) 从n维映射到k维,m表示样本数,k就是主成分
- PCA算法的目标就是:降维后同一纬度的方差最大;不同维度之间的相关性为0;协方差矩阵
- 方差越大,特征越丰富;向量间相关性越低,信息冗余度越低;采用的方法是协方差矩阵
A=Q∑(Q逆) Q矩阵向量间正交,构建成新的特征空间;这里的Q虽然是n×n的,但是当把Q的特征值从大到小排列会发现里边有些数是非常小的,这些维度的能量小,很可能是造成,这些特征就可以丢弃,达到降维的目的。
奇异值分解:
- A=U∑(V.T) (A是mxn,U是mxm,V.T是nxn,∑是mxn)U和V分别是左右奇异矩阵
- LDA与奇异值分解:同类间距尽可能小,不同类样本间隔尽可能大,从而样本表现出数据簇
优化函数:

其中分子是类间间隔,分母是类内间隔,详情见西瓜书。
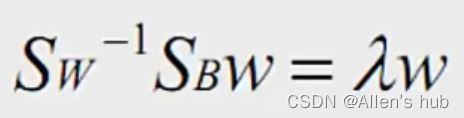
EVD与SVD区别:
- EVD要求矩阵是方阵且满秩(可对角化)
- 矩阵分解不等于特征值降维
- 协方差矩阵描述方差和相关性(建模时候考虑各种约束,类间类内,稀疏,低秩等)
- PyTorch中的奇异值分解:torch.svd()
12,Tensor的裁剪运算
对张量中元素的范围进行过滤
- 对范围约束,减少解空间,可达到类似正则化效果,减少过拟合;
- loss计算中会遇到梯度爆炸和梯度消失的现象,梯度裁剪使梯度保持在合理范围内;
- 方便进行定点/量化
- a.clamp(2,10) #约束范围
13,Tensor的索引和数据筛选
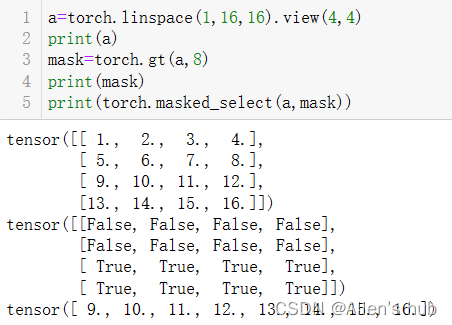
where利用阈值对Tensor进行二值化:

依次输出a的第1,4,3行:
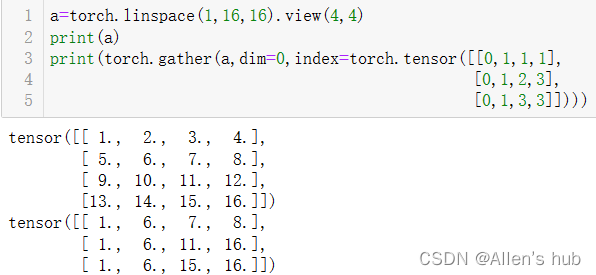
index是对应生成tensor的索引:
dim=0, out [ I, j, k ] = input [ index [ I, j, k ], j, k ]
dim=1, out [ I, j, k ] = input [ I, index [ I, j, k ], k ]
dim=2, out [ I, j, k ] = input [ I, j, index [ I, j, k ] ]
按照布尔张量输出的是一维向量形式:
输出拉成向量后的索引值(view=np.reshape):

输出非零元素的坐标,用于稀疏表示,只记录非零元素和他的索引,节省空间:

14,Tensor的组合/拼接

cat拼接前后的维度是一样的,在现有的维度上合并数据,叠猫猫~
stack是堆叠的意思,会形成全新的维度
栗子:


关于怎么堆叠:
- 这里说的dim维度和机器学习中的维度不太一样,机器学习中的维度是指样本中有n个特征那么就有n个维度,而真正数据的维度dim其实是空间的维度。比如一个彩色的三通道图像就是三维的。
例如,对于形状为[b,c,h,w]的张量,在不同位置通过stack操作插入新维度,dim参数对应的插入位置如图:
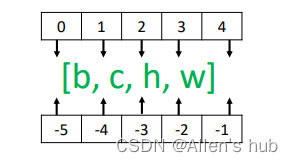
- 比如三通道图像A,形状是[3,32,32]和相同形状的图像B,在dim=0上stack结果是:size=[2,3,32,32],在dim=-1上stack结果是size=[3,32,32,2]。
15,Tensor的切片(切蛋糕)
- torch.chunk(tensor,chunks,dim=0)按照某个维度平均分块(最后一个可能小于平均值)按照哪个维度均分蛋糕
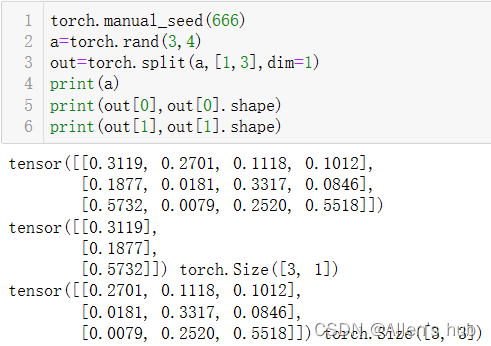
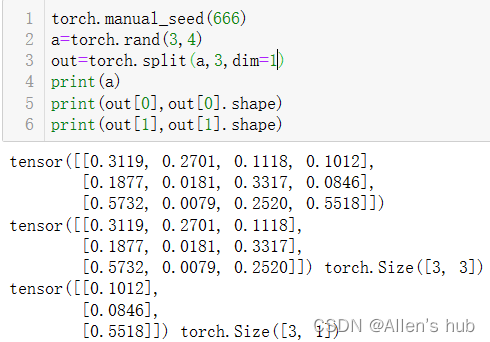
- torch.split(tensor,split_size_or_sections,dim=0)按照某个维度依照第二个参数给出的list或者int进行分割tensor。从哪里分蛋糕


16,Tensor的变形操作

squeeze就是把 [2,1,3]压缩成 [2,3],unsqueeze反过来
17,Tensor的填充操作
定义Tensor,并填充指定的数值
- torch.full((2,3),3.14)

- torch.tensor([[ 3.14,3.14,3.14],[3.14,3.14,3.14 ]] )

18,Tensor的频谱操作与傅里叶变换

用在信号处理
19,模型的保存和加载
- torch.saves(state, dir) 保存/序列化,一般保存模型的训练参数
- torch.load(dir) 加载模型的训练参数等
并行化:
加快图像处理速度
- torch.get_num_threads(): 获得用于并行化CPU操作的OpenMP线程数
- torch.set_num_threads(int): 设定用于并行化CPU操作的OpenMP线程数
分布式:
- python在默认情况下只使用一个GPU,在多个GPU的情况下要使用PyTorch提供的DataParallel
- 单机多卡
- 多机多卡
Tensor on GPU
用.to()可以将Tensor在CPU和GPU之间相互转移

Tensor的相关配置

此处不展开
Tensor与Numpy的相互转化
- torch.from_numpy(ndarry)
- a.numpy()

20,PyTorch与autograd
什么是导数?
什么是方向导数?平面->超平面
什么是偏导数?多元函数降维时的变化
什么是梯度?某点变化最快的那个方向->梯度下降法->极值,局部最优解
如何计算梯度?链式法则
梯度与机器学习中的最优解
有监督学习,无监督学习,半监督学习(弱标签,伪标签,部分无标签)
样本X,标签y;大写矩阵,小写向量
见python3入门机器学习---->>>五)梯度下降算法
Variable is tensor
- 目前Variable已经与Tensor合并
- 每个tensor通过requires_grad来设置是否计算梯度
- 用来冻结某些层的参数(更新局部层的网络参数)
实例:在多任务的训练网络中,我们要对A块进行训练,那么就需要对B块进行冻结
autograd中的几个重要概念-variable-grad-grad_fn
1, 叶子张量(leaf)
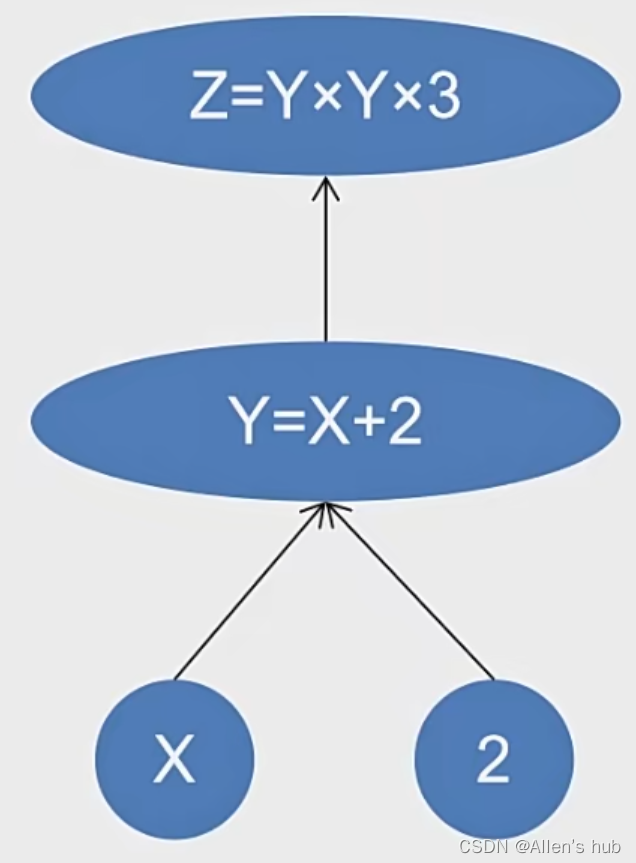
2, grad VS grad_fun
- grad:该Tensor的梯度值,每次在计算backward的时候都需要将前一时刻的梯度归零,否则梯度会一直累加。
- grad_fun:叶子节点通常为None,只有结果节点的grad_fn有效,用于指示梯度函数是哪种类型。
autograd中的几个重要概念-autograd栗子
3, backward函数
torch.autograd.backward(tensors, grad_tensors=None, retain_graph=None, creat_graph=False)
- tensor:用于计算梯度的tensor, torch.autograd.backward(z) 或 z.backward()
- grad_tensor: 在计算矩阵的梯度时会用到,它其实也是一个tensor, shape一般需要和前边的tensor保持一致。
- retain_graph:通常在调用一次backward后,pytorch会自动把计算图销毁,所以要想对某个变量重复调用backward,则需要将该参数设置为True
- creat_graph:如果为True,那么创建一个专门的graph of the derivative,这样可以方便计算高阶微分。(比如对函数二次或多次求导,需要保留第一次求导结果)
4, torch.autograd.grad()函数
def grad(outputs, inputs, grad_outputs=None, retain_graph=None, create_graph=False,
only_inputs=True, allow_unused=False)
- 计算和返回output关于inputs的梯度和
- outputs是函数的因变量,即需要求导的那个函数
- inputs表示函数的自变量
- grad_outputs:同backward
- only_inputs:只计算input的梯度
5,torch.autogtad包中的其他函数
- torch.autograd.enable_grad:启动梯度计算的上下文管理器
- torch.autograd.no_grad:禁止梯度计算的上下文管理器
- torch.autograd.set_grad_enabled(mode):设置是否进行梯度计算的上下文管理器
- ……
autograd中的几个重要概念-function
6, torch.autograd.Function
每一个原始的自动求导实际上是俩个在Tensor上运行的函数
- forward函数计算从输入Tensor获得的输出Tensors
- backward函数接受输出Tensors对于某个标量值的梯度,并且计算输入Tensors相对于该相同标量值的梯度
- 最后,利用apply方法执行相应的运算:定义在Function类的父类_FunctionBase中定义的一个方法
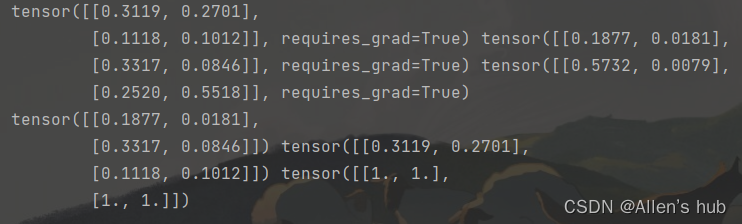
一个栗子:
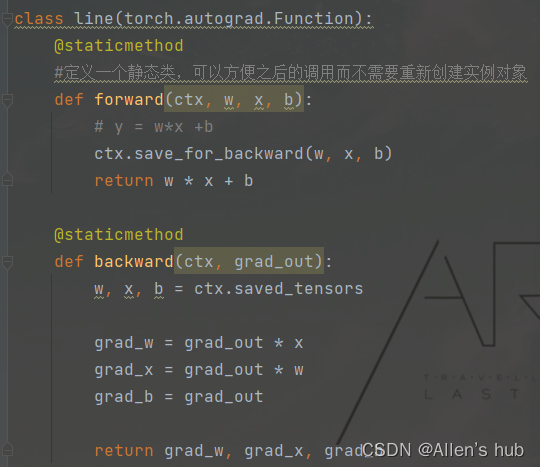
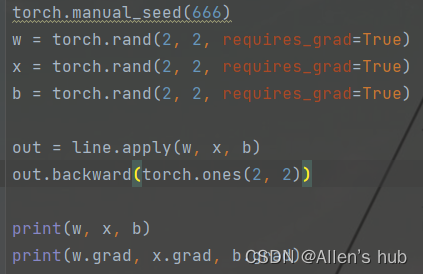
这里自定义line的类,括号中是继承的父类
21,torch.nn库
- torch.nn是专门为神经网络设计的模块化接口
- nn构建于autograd之上,可以用来定义和运行神经网络
常见的一些模块有:
- nn.Parameter
- nn.Linear & nn.conv2d等
- nn.functional
- nn.Module
- nn.Sequential
1,nn.Parameter
定义可训练参数 #模型包括结构和参数,其中参数是用迭代计算的
self.my_param=nn.Parameter(torch.randn(1)) #定义和初始化可训练参数
self.register_parameter #注册可训练参数,把一些参数变得可以训练
nn.ParameterList & nn.ParameterDict #用列表或字典的形式来定义多个可训练的参数


2,其他


dropout在训练和推理时的参数是不一样的,因此训练和推理时要指定不同的参数

nn.Sequential
使用序列的方法完成对网络的定义,串联起来或者采用字典的结构,类似sklearn中的pipline

nn.ModuleList


一个简单栗子:



完成对模型的保存和加载,比如网络要迭代10万次,我们要每1万次保存参数,用以上的方法
22,PyTorch中的可视化工具
visdom
- 调试工具,完成对迭代中间结果的可视化
- 支持数值(折线图,直方图),图像,文本以及视频等
- 支持PyTorch,Torch和Numpy
- 用户可以通过编程的方式组织可视化空间或者通过用户接口为数据打造仪表盘,检查实验结果和调试代码(env: 环境&pane: 窗格)
matplotlib里,用户绘图可以通过plt这个对象来绘图,在visdom中,同样需要一个绘图对象,我们通过vis = Visdom()来获取。具体绘制时,由于我们会一次画好几张图,所以visdom要求用户在绘制时指定当前绘制图像的窗口名字(也就是win这个参数);除此之外,为了到时候显示的分块,用户还需要指定绘图环境env,这个参数相同的图像,最后会显示在同一张页面上。
tensorboardX
也是一种可视化工具,参考以上
23,Pytorch与torchvision
















 121
121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









