







贝叶斯及相关分布
贝叶斯关心参数空间里的“每一个值”,因为他们觉得我们又没有上帝视角,怎么可能知道哪个值是正确的呢?所以参数空间里的每个值都有可能是真实模型使用的值,区别只是概率不同而已。最好诠释这种差别的例子就是想象如果你的后验分布是双峰的,
贝叶斯公式

每一项表示如下:
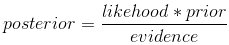
式中,X为结果样本,
θ
\theta
θ为环境对应的参数,P(X)为我们抽到该样本的概率,有时被称为"证据",仅仅是归一化因子,如果不关心后验概率P(θ|X)的具体值,只考察θ取何值时后验概率P(θ|X)最大,则可将分子P(X)省略
先验分布(prior probability/distribution)
参数的先验概率,一般是根据人的先验知识来得出的。比如人们倾向于认为抛硬币实验会符合先验分布:beta分布。当我们选择beta分布的参数时,代表人们认为抛硬币得到正反面的概率都是0.5。
后验分布(posterior probability/distribution)
通过样本X得到参数的概率分布,也就是后验概率分布。 在抽取样本X之前,人们对未知参数θ有个了解,即先验分布P(θ)。抽取样本X,得到样本信息,即似然函数P(X|θ),由于样本中包含未知参数θ的信息,所以样本信息可以修正抽样之前的先验分布P(θ)。P(θ|X)为参数θ的后验分布,即抽样加入新的信息后,对先验分布P(θ)进行修正,后验分布综合运用了先验分布P(θ)和样本信息P(X|θ)。
似然函数(likehood function )
通过参数得到样本X的概率,似然函数,通常就是我们的数据集的表现。在数理统计学中,似然函数是一种关于统计模型中的参数的函数,表示模型参数中的似然性。似然函数的详细分析----似然函数的本质意义(参照博文:似然函数)
概率描述的是在一定条件下某个事件发生的可能性,概率越大说明这件事情越可能会发生;而似然描述的是结果已知的情况下,该事件在不同条件下发生的可能性,似然函数的值越大说明该事件在对应的条件下发生的可能性越大。
最大似然估计(Maximum likelihood estimation)
最大似然估计(通过例子理解)(参照博文:最大似然)部分摘录如下:
L
(
θ
∣
X
)
=
P
(
X
∣
θ
)
L(\theta|X)=P(X|\theta)
L(θ∣X)=P(X∣θ)
P
(
X
∣
θ
)
\color {blue}{P(X|\theta)}
P(X∣θ) 是条件概率表示方法,θ是前置条件,理解为在θ 的前提下,事件 x 发生的概率。
L
(
θ
∣
X
)
\color {blue}{L(\theta|X)}
L(θ∣X) 已知结果为 x ,参数为θ (似然函数里θ 是变量,这里说的参数是相对与概率而言的)对应的概率。
两者在数值上相等,但意义并不相同,
L
(
θ
∣
X
)
\color {blue}{L(\theta|X)}
L(θ∣X) 是关于
θ
\theta
θ的函数,而
P
(
X
∣
θ
)
\color {blue}{P(X|\theta)}
P(X∣θ) 是关于X的函数,两者从不同的角度描述一件事情。
evidence
p ( X ) p(X) p(X)= ∫ \large\smallint ∫ p ( X ∣ θ ) p ( θ ) d ( θ ) p(X|\theta)p(\theta)d(\theta) p(X∣θ)p(θ)d(θ),样本X发生的概率,是各种条件下发生的概率的积分。有时被称为"证据",仅仅是归一化因子,如果不关心后验概率P(θ|X)的具体值,只考察θ取何值时后验概率P(θ|X)最大,则可将分子P(X)省略
共轭分布(conjugacy)
在贝叶斯概率理论中,如果后验概率P(θ|X)和先验概率P(θ)满足同样的分布律(形式相同,参数不同)。那么,先验分布和后验分布被叫做共轭分布,同时,先验分布叫做似然函数的共轭先验分布。
共轭分布总是针对分布中的某个参数θ而言。之所以采用共轭先验的原因是可以使得先验分布和后验分布的形式相同,但是参数不同。

参考:
https://blog.csdn.net/xbmatrix/article/details/63253177
https://blog.csdn.net/baidu_15238925/article/details/81291281
https://blog.csdn.net/huhuo123456/article/details/81186922
















 7980
7980











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









