







从一次面试说起
昨天下午接到的国内一家比较大的游戏公司面试通知,晚上打印好新的简历,今天早上7点半起床从B城赶到C城,海上雾很大。提前十分钟到达面试的地点。等了会,技术总监直接出来面试。下面是一些基本没答上来的题目。
语言相关
什么是displacement new?
placement new是重载operator new的一个标准、全局的版本,它不能被自定义的版本代替(不像普通的operator new和operator delete能够被替换成用户自定义的版本)。
它的原型如下:
void *operator new( size_t, void *p ) throw() { return p; }
首先我们区分下几个容易混淆的关键词:new、operator new、placement new
new和delete操作符我们应该都用过,它们是对堆中的内存进行申请和释放,而这两个都是不能被重载的。要实现不同的内存分配行为,需要重载operator new,而不是new和delete。
看如下代码:
class MyClass {…};
MyClass * p=new MyClass;
这里的new实际上是执行如下3个过程:
1调用operator new分配内存;
2调用构造函数生成类对象;
3返回相应指针。
operator new就像operator+一样,是可以重载的,但是不能在全局对原型为void operator new(size_t size)这个原型进行重载,一般只能在类中进行重载。如果类中没有重载operator new,那么调用的就是全局的::operator new来完成堆的分配。同理,operator new[]、operator delete、operator delete[]也是可以重载的,一般你重载了其中一个,那么最好把其余三个都重载一遍。
placement new是operator new的一个重载版本,只是我们很少用到它。如果你想在已经分配的内存中创建一个对象,使用new是不行的。也就是说placement new允许你在一个已经分配好的内存中(栈或堆中)构造一个新的对象。原型中void*p实际上就是指向一个已经分配好的内存缓冲区的的首地址。
我们知道使用new操作符分配内存需要在堆中查找足够大的剩余空间,这个操作速度是很慢的,而且有可能出现无法分配内存的异常(空间不够)。placement new就可以解决这个问题。我们构造对象都是在一个预先准备好了的内存缓冲区中进行,不需要查找内存,内存分配的时间是常数;而且不会出现在程序运行中途出现内存不足的异常。所以,placement new非常适合那些对时间要求比较高,长时间运行不希望被打断的应用程序。
使用方法如下:
1. 缓冲区提前分配
可以使用堆的空间,也可以使用栈的空间,所以分配方式有如下两种:
class MyClass {…};
char *buf=new char[N*sizeof(MyClass)+ sizeof(int) ] ; 或者char buf[N*sizeof(MyClass)+ sizeof(int) ];
2. 对象的构造
MyClass * pClass=new(buf) MyClass;
3. 对象的销毁
一旦这个对象使用完毕,你必须显式的调用类的析构函数进行销毁对象。但此时内存空间不会被释放,以便其他的对象的构造。
pClass->~MyClass();
4. 内存的释放
如果缓冲区在堆中,那么调用delete[] buf;进行内存的释放;如果在栈中,那么在其作用域内有效,跳出作用域,内存自动释放。
注意:
1) 在C++标准中,对于placement operator new []有如下的说明: placement operator new[] needs implementation-defined amount of additional storage to save a size of array. 所以我们必须申请比原始对象大小多出sizeof(int)个字节来存放对象的个数,或者说数组的大小。
2) 使用方法第二步中的new才是placement new,其实是没有申请内存的,只是调用了构造函数,返回一个指向已经分配好的内存的一个指针,所以对象销毁的时候不需要调用delete释放空间,但必须调用析构函数销毁对象。
new 或者malloc最多能申请多大的内存?
32位程序不可能申请大于4G的内存,linux在X86系统下,理论上用户态可以申请3G内存(有1G的地址空间留给内核),内核态可以申请4G内存,windows你需要查一查其系统规范。
linux下用top命令显示有内存空间,但malloc一个64mbuffer的时候失败了,什么原因,为啥会出现这种情况?试着malloc一个1m的buffer可能成功么?
内存碎片,无法找出连续的地址空间。空闲内存以小而不连续方式出现在不同的位置。由于分配方法决定内存碎片是否是一个问题,因此内存分配器在保证空闲资源可用性方面扮演着重要的角色。
内存碎片存在的方式有两种:a.内部碎片 b.外部碎片 。
内部碎片的产生:因为所有的内存分配必须起始于可被 4、8 或 16 整除(视处理器体系结构而定)的地址或者因为MMU的分页机制的限制,决定内存分配算法仅能把预定大小的内存块分配给客户。假设当某个客户请求一个 43 字节的内存块时,因为没有适合大小的内存,所以它可能会获得 44字节、48字节等稍大一点的字节,因此由所需大小四舍五入而产生的多余空间就叫内部碎片。
外部碎片的产生: 频繁的分配与回收物理页面会导致大量的、连续且小的页面块夹杂在已分配的页面中间,就会产生外部碎片。假设有一块一共有100个单位的连续空闲内存空间,范围是0~99。如果你从中申请一块内存,如10个单位,那么申请出来的内存块就为0~9区间。这时候你继续申请一块内存,比如说5个单位大,第二块得到的内存块就应该为10~14区间。如果你把第一块内存块释放,然后再申请一块大于10个单位的内存块,比如说20个单位。因为刚被释放的内存块不能满足新的请求,所以只能从15开始分配出20个单位的内存块。现在整个内存空间的状态是0~9空闲,10~14被占用,15~24被占用,25~99空闲。其中0~9就是一个内存碎片了。如果10~14一直被占用,而以后申请的空间都大于10个单位,那么0~9就永远用不上了,变成外部碎片。
可能会成功。
使用全局对象有什么缺点,内存是如何分配与回收的,
全局类变量会在进入main()函数之前被构造好,且是在退出main()函数后才被析构。
注意:在使用了标准C++的头文件时,如果全局对象的析构函数中使用了cout,则会看不到想要输出的字符串信息,自己误以为析构函数未被调用。
解释:首先析构函数的确被系统调用了,这一点可以在析构函数中加断点,调试证实。未产生输出的原因是cout其实是一个ostream对象,所以它也会析构,且在这里它比你定义的全局对象先析构,应该在退出main函数前析构,所以用cout输出的语句已经不具备意义了
说一下进程和线程的堆栈内存管理。
线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源.
堆:是大家共有的空间,分全局堆和局部堆。全局堆就是所有没有分配的空间,局部堆就是用户分配的空间。堆在操作系统对进程初始化的时候分配,运行过程中也可以向系统要额外的堆,但是记得用完了要还给操作系统,要不然就是内存泄漏。
栈:是个线程独有的,保存其运行状态和局部自动变量的。栈在线程开始的时候初始化,每个线程的栈互相独立,因此,栈是thread safe的。
使用malloc申请对象指针内存,然后编译,是否会通过,在什么时候会出错?对其使用free的话会出现什么错误?
看一段测试代码:
- #include<iostream>
- #include<stdlib.h>
- using namespace std;
- class Object
- {
- public:
- Object(int i):id(i)
- {
- cout<<"Constructor"<<endl;
- }
- ~Object()
- {
- cout<<"Destructor"<<endl;
- }
- void sayHi()
- {
- cout<<"Hi,I am No."<<id<<endl;
- }
- private:
- int id;
- };
- int main()
- {
- Object *p;
- p = new Object(10);
- p->sayHi();
- delete p;
- //free(p);
- return 1;
- }
编译运行,结果是:

将delete p换成free(p):

没有执行析构函数,如果在object的析构函数种有释放内存的操作将不会被调用,造成内存泄漏。
再看一段代码
- #include<iostream>
- #include<stdlib.h>
- using namespace std;
- class Object
- {
- public:
- Object(int i):id(i)
- {
- buffer = new double[10];
- cout<<"Constructor"<<endl;
- }
- ~Object()
- {
- delete[] buffer;
- cout<<"Destructor"<<endl;
- }
- void sayHi()
- {
- cout<<"Hi,I am No."<<id<<endl;
- }
- private:
- int id;
- double *buffer;
- };
- int main()
- {
- Object *p;
- p = (Object*)malloc(sizeof(Object));
- p->sayHi();
- delete p;
- return 1;
- }
运行结果:

首先是编译没有问题,运行也正常,程序无崩溃。
首先是用malloc分配内存,然后用类型转换转换城(Object *)类型,成员变量为0;
delete的时候,会调用对应的析构函数,当尝试delete在构造函数中的buffer的时候,这个时候buffer是NULL,而delete NULL什么都不会发生。
static 对象何时析构?
静态成员变量的构造和初始化是在程序进入点《main函数》之前
析构在main()函数退出之前
至于顺序,我想和各个文件的编译顺序有关。
说一下函数调用堆栈,保存现场保存了哪些变量?
在c语言程序的入口其实不是main函数,在main函数之前c标准库的代码首先被执行,这段代码设置程序运行环境包括函数调用栈。对于每一次调用(包括调用main函数)的大致流程如下:
1、push ebp 将esp入栈
2、movl esp, ebp 将esp赋值到ebp
3、sub esp, XXX 在栈上分配XXX字节的临时空间
4、push XXX 保存名为XXX的寄存器
对于没有使用局部变量的函数第三步是可选的,第四步也是可选的用于保证调用前后XXX寄存器的值不变。
函数返回的流程大致如下:
1、pop XXX 恢复寄存器XXX的值
2、mov esp, ebp 回收之前分配的临时空间
3、pop ebp 恢复ebp之前的值(重新指向上一个函数的堆栈)
4、ret 栈中弹出返回地址,返回调用者
扩展
malloc/free和new/delete的本质区别
malloc/free是C/C++语言的标准库函数,new/delete是C++的运算符。
对于用户自定义的对象而言,用maloc/free无法满足动态管理对象的要求。对象在创建的同时要自动执行构造函数,对象在消亡之前要自动执行析构函数。由于malloc/free是库函数而不是运算符,不在编译器控制权限之内,不能够把执行构造函数和析构函数的任务强加于malloc/free。因此C++需要一个能完成动态内存分配和初始化工作的运算符new,以及一个能完成清理与释放内存工作的运算符delete。
c++代码编译城可执行文件的过程
1.编译预处理:宏定义指令、条件编译指令、头文件包含指令;
2.编译、优化阶段: 编译程序所要作得工作就是通过词法分析和语法分析,在确认所有的指令都符合语法规则之后,将其翻译成等价的中间代码表示或汇编代码。
3.汇编过程:把汇编语言代码翻译成目标机器指令的过程。
4.链接程序:静态链接和动态链接。
编译阶段将源程序(*.c)转换成为目标代码(,一般是obj文件,至于具体过程就是上面说的那些阶段),连接阶段是把源程序转换成的目标代码(obj文件)与你程序里面调用的库函数对应的代码连接起来形成对应的可执行文件(exe文件)就可以了
数据结构相关
限长优先级队列的实现
通常优先级队列用在操作系统中的多任务调度,任务优先级越高,任务优先执行(类似于出队列),后来的任务如果优先级比以前的高,则需要调整该任务到合适的位置,以便于优先执行,整个过程总是使得队列中的任务的第一任务的优先级最高。
优先级队列有两种:最大优先级队列和最小优先级队列,这两种类别分别可以用最大堆和最小堆实现。。一个最大优先级队列支持的操作如下操作:
INSERT(S,x):把元素x插入到集合S.
MAXIMUM(S):返回S中具有最大关键字的元素.
EXTRACT_MAX(S):去掉并返回S中的具有最大关键字的元素.
INCREASE_KEY(S,x,k):将元素x的关键字的值增加到k,这里k值不能小于x的原关键字的值。
堆的实现就是一棵平衡二叉树,性质为:让二叉树中的每一个节点的key(也就是优先级)值比该节点的子节点的key值大。
让这棵二叉树总是保持为完全二叉树(且不破坏大根堆特性),这样树高就会是lgn,那么入队和出队操作的时间复杂度就是O(lgn)。这就比较理想了。
另外,考虑到这个树要保证的性质只有大根堆特性,那么可以让这棵二叉树总是保持为完全二叉树(且不破坏性质A),这样树高就会是lgn,那么入队和出队操作的时间复杂度就是O(lgn)。这就比较理想了。
对于一棵完全二叉树,我们可以用数组(而不是链表)方式来实现。因为对于数组实现的完全二叉树,index为i的节点,它的父节点的index是i/2,左子节点的index是i*2,右子节点的index是i*2+1。乘2和除2都是可以通过位移来实现的,效率上很好。而且通过保存元素个数,可以O(1)时间只找到处于树的最未的那个元素。用数组来实现还有一个好处,就是不需要在数据结构中再实现对父、子节点的指针存储,这样也省下了不少空间。这些特点都非常适合(也很好地改善了)优先级队列的实现。
Hash表和map的区别
其实就是比较哈希表和红黑树。
构造函数。hash_map需要hash函数,等于函数;map只需要比较函数(小于函数).
存储结构。hash_map采用hash表存储,map一般采用红黑树(RB Tree)实现。因此其memory数据结构是不一样的。
适用情况:
总 体来说,hash_map 查找速度会比map快,而且查找速度基本和数据量大小无关,属于常数级别;而map的查找速度是log(n)级别。并不一定常数就比log(n) 小,hash还有hash函数的耗时,明白了吧,如果你考虑效率,特别是在元素达到一定数量级时,考虑考虑hash_map。但若你对内存使用特别严格,希望程序尽可能少消耗内存,那么一定要小心,hash_map可能会让你陷入尴尬,特别是当你的hash_map对象特别多时,你就更无法控制了,而且 hash_map的构造速度较慢。
权衡三个因素: 查找速度, 数据量, 内存使用。
Android相关
Android系统层次
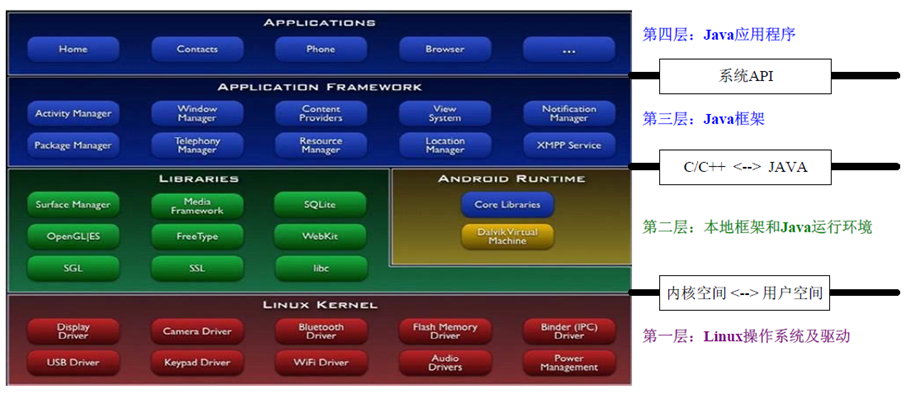
Android root原理,是否可以还原?
Android的内核就是Linux,所以Android获取root其实和Linux获取root权限是一回事儿。
你想在Linux下获取root权限的时候就是执行sudo或者su,接下来系统会提示你输入root用户的密码,密码正确就获得root权限了。Android本身就不想让你获得Root权限,大部分手机出厂的时候根本就没有su这个程序。所以你想获得Android的root权限,第一步就是要把编译好的su文件拷贝到Android手机的/system/bin或者/system/xbin/目录下。我们先假设你可以把su放在xbin下,接下来你可以在Android手机的adb shell或者串口下输入su了。
Linux下su以后输入密码就可以root了,但Android里的su和Linux里的su是不一样的,Android里的su不是靠验证密码的,而是看你原来的权限是什么。意思就是如果你是root,那你可以通过su切换到别的用户,比如说shell,wifi,audio什么的。但如果你是root之外的其他用户,就不能切换回root了,会提示你permission denied。
其实Android系统的破解的根本原理就是替换掉系统中的su程序,因为系统中的默认su程序需要验证实际用户权限(只有root和 shell用户才有权运行系统默认的su程序,其他用户运行都会返回错误)。而破解后的su将不检查实际用户权限,这样普通的用户也将可以运行su程序, 也可以通过su程序将自己的权限提升。手机Root后,最重要的是,给手机安装了su程序和superuser apk。 su一般被安装在/system/xbin 或者 /system/bin 下面。
可以理解成root 破解就是在你系统中植入“木马su”,说它是“木马”一点儿都不为过,假如恶意程序在系统中运行也可以通过su来提升自己的权限的这样的结果将会是灾难性 的。所以一般情况下root过手机都会有一个SuperUser应用程序来让用户管理允许谁获得root权限,也算是给系统加了一层保险吧!
还原的话讲原来的su替换即可。
android中system和root用户有什么区别?
Root是Linux等类UNIX系统中的超级管理员用户帐户,该帐户拥有整个系统至高无上的权利,所有对象他都有可以操作的权利,所以很多黑客在入侵系统的时候,都要把权限提升到Root权限,也就是将自己的非法帐户添加到Root用户组。类比于Administrator是Windows NT内核系统中的超级管理员用户帐户,也拥有最高的权限。但不同的是,在WINDOWS下Administrator的资源和别的用户资源是共享的,简单的说,别的用户可以访问Administrator的文件。而Linux中,别的用户是不能访问Root用户的家目录(/root)下文件的。因此,Linux比Windows更安全。
由于Root权限对于系统具有最高的统治权,便可方便的对于系统的部件进行删除或更改。
system也是Linux的一个用户名,常见的情形为在未破解的Android手机上,当你链接真机在PC上执行adb shell时,adb 是以system的用户规则进行操作的。system与普通的App区别在于为了整个Android系统的运行在"/"目录下有一些"system"生成的目录及文件。
从操作系统的角度描述Android运行一个app。
每一个Android应用程序进程都有一个Dalvik虚拟机实例。这样做的好处是Android应用程序进程之间不会相互影响,也就是说,一个Android应用程序进程的意外中止,不会影响到其它的Android应用程序进程的正常运行。
每一个Android应用程序进程都是由一种称为Zygote的进程fork出来的。Zygote进程是由init进程启动起来的,也就是在系统启动的时候启动的。Zygote进程在启动的时候,会创建一个虚拟机实例,并且在这个虚拟机实例将所有的Java核心库都加载起来。每当Zygote进程需要创建一个Android应用程序进程的时候,它就通过复制自身来实现,也就是通过fork系统调用来实现。这些被fork出来的Android应用程序进程,一方面是复制了Zygote进程中的虚拟机实例,另一方面是与Zygote进程共享了同一套Java核心库。这样不仅Android应用程序进程的创建过程很快,而且由于所有的Android应用程序进程都共享同一套Java核心库而节省了内存空间。
Android系统如何保护app种的sql数据不被篡改?
未曾Root过的手机,每个App只能访问自己的data文件夹下的数据库,没有访问其他app/data文件夹的权限,所以无法随意修改其他应用的sqlite数据。
Root过的手机都可以进入到/data/data/<package_name>/databases目录下面,在这里就可以查看到数据库中存储的所有数据。如果是一般的数据还好,但是当涉及到一些账号密码,或者聊天内容的时候,我们的程序就会面临严重的安全漏洞隐患。
其他
看你搞过网站的东西,会Node.js么?
“有听过,但没弄过。”
会网络编程么?
“不会。”
那今天就面到这里,后面有需要的话我们会联系你。
“嗯。”
最后
现在回想起来,基本只答出来了一半不到,幸亏之前有看了一些C++的书,不然可能就是15分钟就88了。
基础不好是根本原因,缺乏面试的经验也是一方面。
借同学的一句话,“幸亏你面的不是XX游戏开发,不然你幼小的心理将会受到毁灭性的打击。”
现在的感觉就是10分钟单中的冥界亚龙,数据是0杀1死0助攻,装备是草鞋三树枝,兜里有400块。买一个圆盾,一个回城,继续飞中。
嗯,节奏很差。
现在能做的只能是补好每一个兵,稳扎稳打,然后抓住每一个机会,把局势掌握在自己手里。
网上弄到的一份题,不是很完整,边猜边做。
1.写出运行结果
char array[] = “abcde”; char* s = array;
cout<<sizeof(array)<<strlen(array)<<sizeof(s)<<strlen(s);
6585
2.什么是用户级线程和内核级线程?区别。
内核级线程:(1)线程的创建、撤销和切换等,都需要内核直接实现,即内核了解每一个作为可调度实体的线程。
(2)这些线程可以在全系统内进行资源的竞争。
(3)内核空间内为每一个内核支持线程设置了一个线程控制块(TCB),内核根据该控制块,感知线程的存在,并进行控制。
在一定程度上类似于进程,只是创建、调度的开销要比进程小。有的统计是1:10
用户级线程:
(1)用户级线程仅存在于用户空间。——>对比内核(3)
(2)内核并不能看到用户线程。——>重要的区别
(3)内核资源的分配仍然是按照进程进行分配的;各个用户线程只能在进程内进行资源竞争。
3.从C++文件到生成exe 文件经过哪三个步骤?
预编译,编译优化,汇编,链接
4.有个二维数组 A(6*8),每个元素占 6 字节,起始地址为 1000,请问最后一个元素 A[5][7]的起始地址为??? 数组A占内存大小为??? 假设以行优先,则A[1][4]起始地址为???
1)1000 + 6*6*8 - 8 = 11282; 2)6*6*8=288; 3)A[1][4]位置为5行2列,1000+6*(8*1+4) = 1272.
如果给出结构体,考虑到字节对齐的话就要另外考虑了。

5.用C语言把双向链表中的两个结点交换位置,考虑各种边界问题。
考虑三种情况:第一个结点在头,第一个结点在中间,第一个结点在尾巴。
- struct Node{
- Node* prev;
- Node* next;
- void* data;
- };
- struct LinkedList{
- Node* head;
- Node* tail;
- Node* cur;
- int size;
- };
- bool exchange(LinkedList* list,Node *node1,Node *node2)
- {
- if(node1== NULL || node2==NULL)
- return false;
- Node *p,*q;
- //node1 on the front
- if(list->head->next == node1)
- {
- //node2 on the last
- if(list->tail->next == node2)
- {
- p = node2->prev;
- //Cope with node2
- list->head->next = node2;
- node2->prev = list->head;
- node2->next = node1->next;
- node2->next->pre = node2;
- //Cope with node1
- list->tail->prev = node1;
- node1->next = list->tail;
- node1->prev = p;
- p->next = node1;
- return true;
- }
- //node2 not on the last
- else
- {
- p = node2->prev;
- q = node2->next;
- //Cope with node2
- list->head->next = node2;
- node2->prev = list->head;
- node2->next = node1->next;
- node2->next->prev = node2;
- //Cope with node1
- p->next = node1;
- node1->prev = p;
- node1->next = q;
- q->prev = node1;
- return true;
- }
- }
- //node1 on the last
- else if(list->tail->next == node1)
- {
- //node2 on the front
- if(list->head->next == node2)
- {
- p = node1->prev;
- //Cope with node1
- list->head->next = node1;
- node1->prev = list->head;
- node1->next = node2->next;
- node1->next->prev = node1;
- //Cope with node2
- list->tail->prev = node2;
- node2->next = list->tail;
- node2->prev = p;
- p->next = node2;
- return true;
- }
- //node2 not on the front
- else
- {
- p = node2->prev;
- q = node2->next;
- //Cope with node2
- list->tail->next = node2;
- node2->prev = list->tail;
- node2->next = node1->next;
- node2->next->prev = node2;
- //Cope with node1
- p->next = node1;
- node1->prev = p;
- node1->next = q;
- q->prev = node1;
- return true;
- }
- }
- //node1 on the middle
- else
- {
- //node2 on the front
- if(list->head->next == node2)
- {
- p = node1->prev;
- q = node1->next;
- node1->prev = list->head;
- list->head->next = node1;
- node1->next = node2->next;
- node2->next->prev = node1;
- node2->prev = p;
- p->next = node2;
- node2->next = q;
- q->prev = node2;
- }
- //node2 on the last
- else if(list->tail->next == node2)
- {
- p = node1->prev;
- q = node1->next;
- node1->prev = node2->prev;
- node2->prev->next = node1;
- node1->next = list->tail;
- list->tail->prev = node1;
- node2->prev = p;
- p->next = node2;
- node2->next = q;
- q->prev = node2;
- }
- //both in the middle
- else
- {
- p = node2->prev;
- q = node2->next;
- //Cope with node2
- node2->prev = node1->prev;
- node1->prev->next = node2;
- node2->next = node1->next;
- node1->next->prev = node2;
- //Cope with node1
- p->next = node1;
- node1->prev = p;
- node1->next = q;
- q->prev = node1;
- return true;
- }
- }
- }
6.*.dll,*.lib,*.exe 文件分别是什么,有什么区别?
lib是静态的库文件,dll是动态的库文件。
所谓静态就是link的时候把里面需要的东西抽取出来安排到你的exe文件中,以后运行exe的时候不再需要lib。
所谓动态就是exe运行的时候依赖于dll里面提供的功能,没有这个dll,exe无法运 行。
lib, dll, exe都算是最终的目标文件,是最终产物。而c/c++属于源代码。源代码和最终 目标文件中过渡的就是中间代码obj,实际上之所以需要中间代码,是你不可能一次得到目 标文件。比如说一个exe需要很多的cpp文件生成。而编译器一次只能编译一个cpp文件。这 样编译器编译好一个cpp以后会将其编译成obj,当所有必须要的cpp都编译成obj以后,再统 一link成所需要的exe,应该说缺少任意一个obj都会导致exe的链接失败.
7.附加题(20):使用八叉树算法把24位真彩色转化成 256色。24位真彩色包括 R,G,B颜色,每种颜色8 位。
在计算机中像素的计算单位一般是二进制的,256色,即2的8次方,因此我们也把256色图形叫做8位图;16位图,它可以表达2的16次方即65536种颜色;还有24位彩色图,可以表达16,777,216种颜色。
算法参考:http://blog.csdn.net/zuzubo/article/details/1597985
8.有 11 盆花,围成一圈,要求每次组合时,每盆花相邻的两盆花与上次不同,请问有多少排列方法?
待解答。
9.2 只宠物合成,1只有 5技能,1 只有4 技能,每个技能有 a%概率遗传,请问刚好有7 个技能遗传成功的概率是?
只有
第一只5个技能 + 第二只2个技能:(a%)^7*C(4,2)
第一只4个技能 + 第二只3个技能:(a%)^7*C(5,4)*C(4,3)
第一只3个技能 + 第二只4个技能:(a%)^7*C(5,3)
加起来就可以了。
10.输出结果为?
- #include <iostream>
- using namespace std;
- class A
- {
- public:
- A(){cout<<"1";}
- A(A &a){cout <<"2";}
- virtual ~A() {cout<<"3";}
- };
- class B:public A
- {
- public:
- B(){cout<<"4";}
- B(B &b){cout<<"5";}
- ~B(){cout<<"6";}
- };
- int main()
- {
- A* pa = new B();
- delete pa;
- return 0;
- }
1463
子类构造之前首先调用基类的构造函数,然后是子类的构造函数,析构的时候相反,注意基类的析构函数声明为virtual才可以.
第一部分(必做):计算机基础类(25分)
(所有选择题都是多项选择)
1.(2分)假设进栈次序是e1,e2, e3, e4,那可能的出栈次序是()
A、e2, e4, e3, e1 B、e2, e3, e4, e1 C、e3, e2, e4, e1 D、e1, e2, e4, e3.
解析:随手画一下就可以找到答案。
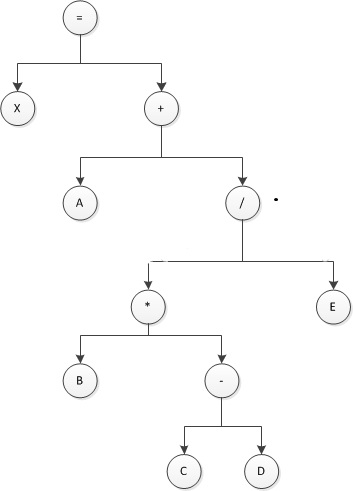
2.(2分)表达式X=A+B*(C-D)/E的后缀表示形式可以是()
A、XAB+CDE/-*= B、XA+BC-DE/*= C、XABCD-*E/+= D、XABCDE+*/=
解析:前缀表达式(Prefix Notation)是指将运算符写在前面操作数写在后面的不包含括号的表达式,也叫做波兰表达式,对应于二叉树的前序遍历。
后缀表达式(Postfix Notation)与之相反,是指运算符写在操作数后面的不包含括号的算术表达式,也叫做逆波兰表达式,对应于二叉树的中序遍历 。
中缀表达式(Infix Notation)就是常用的将操作符放在操作数中间的算术表达式。前缀表达式和后缀表达式相对于中缀表达式最大的不同就是去掉了表示运算符优先级的括号,二叉树的后序遍历。
所以这道题的做法就是先根据表达式写出树的结构,然后写出二叉树的后续遍历。
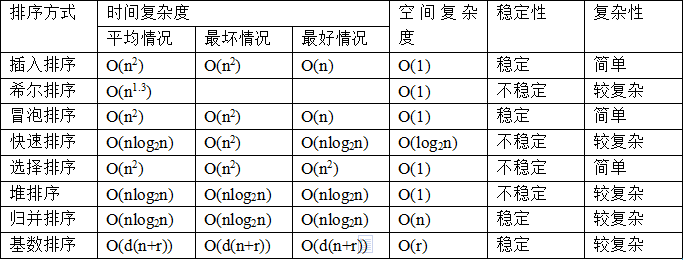
3.(2分)以下排序算法是非稳定排序的是()
A、冒泡排序 B、归并排序 C、快速排序 D、堆排序 E、希尔排序
解析:排序算法稳定性:保证排序前两个相等的数据其在序列中的先后位置顺序与排序后它们两个先后位置顺序相同。然后就是下面的这个表。
4.(2分)一个包含n个结点的四叉树,每一个节点都有4个指向孩子节点的指针,这4n个指针有(3n+1)个空指针。
解析:一共4n个指针,除去根节点,其它节点都要有指针指,则空指针有 4n - (n-1) = 3n+1。
5.(2分)
- int func(unsigned int i)
- {
- unsigned int temp = i;
- temp = (temp & 0x55555555) + ((temp & 0xaaaaaaaa)>>1);
- temp = (temp & 0x33333333) + ((temp & 0xcccccccc)>>2);
- temp = (temp & 0x0f0f0f0f) + ((temp & 0xf0f0f0f0)>>4);
- temp = (temp & 0xff00ff) + ((temp & 0xff00ff00)>>8);
- temp = (temp & 0xffff) + ((temp & 0xffff0000)>>16);
- return temp;
- }
请问func(0x7f530829)的返回值是()
A、15 B、16 C、17 D、18
解析:求数的二进制表示中1的个数的“平行算法”,思路就是先将n写成二进制形式,然后相邻位相加,重复这个过程,直到只剩下一位。
0x7f530829写成二进制是0111 1111 0101 0011 0000 1000 0010 1001,数一下。
6.(2分)进程和线程的差别有()
A、操作系统只调度进程,不调度线程
B、线程共享内存地址空间,进程不共享
C、线程可以共享内存数据,但进程不可以
D、进程间可以通过IPC通信,但线程不可以
解析:在操作系统设计上,从进程演化出线程,进程和线程都可以调度;线程之间的通信只有通过读写同一个地址空间的内存来完成,进程间也可以用共享内存来通信。
7.(2分)关于段页式管理中,地址映像表是()
A、每个进程一张段表,一张页表 B、进程的每个段一张段表,一张页表
C、每个进程一张段表,每段一张页表 D、每个进程一张页表,每段一张段表
解析:段页式内存管理是基本分段存储管理方式和基本分页存储管理方式原理的结合,即先将用户程序分成若干个段,再把每个段分成若干个页,并为每一个段赋予一个段名。
8.(2分)关于TCP协议,下面哪种说法是错误的()
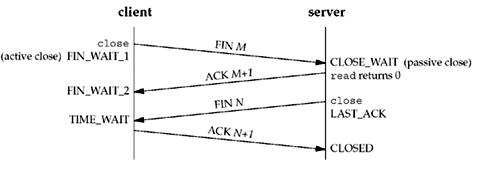
A、TCP关闭连接过程中,两端的socket都会经过TIME_WAIT状态
B、对一个Established状态的TCP连接,调用shutdown函数可以让主动调用的一方进入半关闭状态
C、TCP协议默认保证了当TCP的一端发生意外崩溃(当机、网线断开或路由器故障),另一端能自动检测到连接失效
D、在成功建立连接的TCP上,只有在Established状态才能收发数据,其他状态都不可以。
解析:A不对,只有sever端才会出现TIME_WAIT状态,如下图:
C不对,当TCP连接发生一些物理上的意外情况时,例如网线断开,linux上的TCP实现会依然认为该连接有效,而windows则会在一定时间后返回错误信息。
9.(2分)关于主键PrimaryKey和索引index的说法哪些是错误的?()
A、唯一索引的列允许为NULL值
B、一个关系表中的外键必定是另一表中的主键
C、一个表中只能有一个唯一性索引
D、索引主要影响查询过程,对数据的插入影响不大
解析:B不对,一定是主键或者唯一键;
C不对,关于主键和唯一索引:
1.主键一定是唯一性索引,唯一性索引并不一定就是主键;
2.一个表中可以有多个唯一性索引,但只能有一个主键;
3.主键列不允许空值,而唯一性索引列允许空值。
10.(2分)数据库的事务隔离级别一般分为4个级别,其中可能发生“不可重复读”的事务级别有()
A、SERIALIZABLE
B、READ COMMITTED
C、READ UNCOMMITTED
D、REPEATABLE READ
解析:四个级别
串行化(SERIALIZABLE):所有事务都一个接一个地串行执行,这样可以避免幻读(phantom reads)。对于基于锁来实现并发控制的数据库来说,串行化要求在执行范围查询(如选取年龄在10到30之间的用户)的时候,需要获取范围锁(range lock)。如果不是基于锁实现并发控制的数据库,则检查到有违反串行操作的事务时,需要滚回该事务。
可重复读(REPEATABLE READ):所有被Select获取的数据都不能被修改,这样就可以避免一个事务前后读取数据不一致的情况。但是却没有办法控制幻读,因为这个时候其他事务不能更改所选的数据,但是可以增加数据,因为前一个事务没有范围锁。
读已提交(READ COMMITED):被读取的数据可以被其他事务修改。这样就可能导致不可重复读。也就是说,事务的读取数据的时候获取读锁,但是读完之后立即释放(不需要等到事务结束),而写锁则是事务提交之后才释放。释放读锁之后,就可能被其他事物修改数据。该等级也是SQL Server默认的隔离等级。
读未提交(READ UNCOMMITED):这是最低的隔离等级,允许其他事务看到没有提交的数据。这种等级会导致脏读(Dirty Read)。
11.(5分)如果F(n)为该数列的第n项,那么这句话可以写成如下形式:
F(1)=1,F(2)=1,F(n)=F(n-1)+F(n-2)(n>=3)
请实现该函数F(n)的求解,并给出算法复杂度,要求算法复杂度小于O(n^2)。
解析:肯定不能呢个用递归了~那个算法基本是每个Fibnac数求解了一遍又一遍,下面是最简单的迭代实现。
- int Fib(int index)
- {
- if(index<1)
- {
- return-1;
- }
- int a1=1,a2=1,a3=1;
- for(int i=0;i<index-2;i++)
- {
- a3=a1+a2;
- a1=a2;
- a2=a3;
- }
- return a3;
- }
第二部分(必做):程序设计(25分)
1.(2分)下面的程序的输出是什么?
- #include<stdio.h>
- int main()
- {
- int n;
- char y[10] = “ntse”;
- char*x = y;
- n= strlen(x);
- *x= x[n];
- x++;
- printf(“x=%s\n”,x);
- printf(“y=%s\n”,y);
- }
x=tse
y=
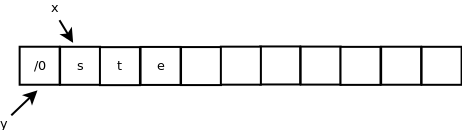
解析:char *x = y之后,x和y都只想一个10字节的内存空间,前4个字节中放的是ntse,第五个字节放的是/0,后面都是空的。n = strlen(x),得到n=4。*x=x[n],将数组第一个元素换为x[4],即/0,x++,x指向的是数组的第二个空间。内存布局如下:
2.(2分)请给出下面程序的输出结果,并说明原因。
- #include<vector>
- #include<iostream>
- using namespace std;
- template<class t>
- class array{
- public:
- array(int size);
- size_t getVectorSize() {return _data.size();}
- size_t getSize() {return _size;}
- public:
- vector<t> _data;
- size_t _size;
- }
- template<class t>
- array<t>::array(int size):_size(size),_data(_size)
- { }
- int main()
- {
- array<int>*arr= new array<int>(3);
- cout<<arr->getVectorSize()<<endl;
- cout<<arr->getSize()<<endl;
- return0;
- }
3,3
解析:主要考察构造函数列表,首先是_size赋值为3,然后用_size作为参数构造vector.等于
// 1. Create a vector v1 with 3 elements of default value 0
std::vector<int> v1(3);
3.(2分)CAS(CompareAndSwap),是用来实现lock-free编程的重要手段之一,多数处理器都支持这一原子操作,其用伪代码描述如下:
- template bool CAS(T* addr, T expected, Tvalue)
- {
- if(*addr== expected){
- *addr= value;
- return true;
- }
- return false;
- }
请完成下面填空,实现全局计数器的原子递增操作。
- int count = 0;
- void count_atomic_inc(int *addr)
- {
- int oldval = 0;
- int newval = 0;
- do{
- oldval= *addr;
- newval= + 1;
- }until CAS( , , )
- }
解析:CAS的原理是,将旧值与一个期望值进行比较,如果相等,则更新旧值,类型T = {char, short, int, __int64, ...}等,以及指针(pointer to any type)。
until 等价于while(!XX)
详解无锁的数据结构(Lock-Free)及CAS(Compare-and-Swap)机制
4.(2分)下面的程序会输出几个“-”?
- #include<stdio.h>
- #include<sys/types.h>
- #include<unistd.h>
- int main(void)
- {
- int i;
- for(i=0;i<2;i++){
- fork();
- printf(“-”);
- fflush(stdout);
- }
- return 0;
- }
6
解析:把循环展开
- fork();
- printf(“-”);
- fflush(stdout);
- fork();
- printf(“-”);
- fflush(stdout);
假设最开始的进程树是p0
则进程树如下:
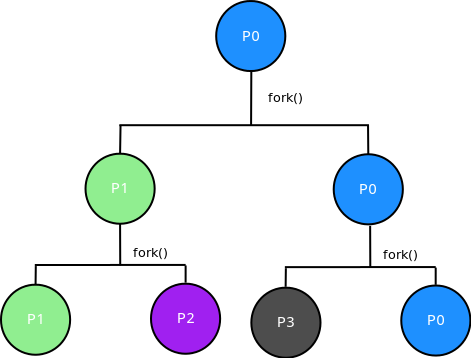
fork之后的代码父进程和子进程都会执行。
注意fflush,没有这句话的情况结果还不同。参考一个fork的面试题。
5.(4分)写程序判断当前CPU是大端CPU还是小端CPU,并做简要说明。
最简单的方式就是利用union的特性,由于联合的大小和最大成员的大小一样,里面的成员是共享存储空间的。
- int checkCPU( ){
- union w {
- int a;
- char b;
- } c;
- c.a = 1;
- return(c.b ==1);
- }
解析:
大端格式:在这种格式中,字数据的高字节存储在低地址中,而字数据的低字节则存放在高地址中,
小端格式:与大端存储格式相反,在小端存储格式中,低地址中存放的是字数据的低字节,高地址存放的是字数据的高字节。
现在主流的CPU,intel系列的是采用的little endian的格式存放数据,而motorola系列的CPU采用的是big endian,ARM则同时支持 big和little,网络编程中,TCP/IP统一采用大端方式传送数据,所以有时我们也会把大端方式称之为网络字节序。
C/C++语言编写的程序里数据存储顺序是跟编译平台所在的CPU相关的,而 JAVA编写的程序则唯一采用big endian方式来存储数据。
6.(5分)利用位运算实现两个整数的加法运算,请代码实现,并做简要说明。
- int Add(int a, int b)
- {
- int sum = a ^ b;
- int carry = a & b;
- while (carry != 0) {
- a = sum;
- b = carry << 1;
- sum = a ^ b;
- carry = a & b;
- }
- return sum;
- }
首先用sum记录a和b二进制中不同的位置为1(异或运算,不同为1),carry记录相同位为1(与运算,相同为1得1),这时候a+b就可以化为sum+(carry<<1),不断将carry右移,当carry为0的时候,sum的值就是最终结果。
参照剑指offer 47不用加减乘除做加法
7.(8分)图深度遍历问题

a) 写出上述图的深度优先遍历的顺序(遍历起点是节点1)
12485367
解析:深度遍历思想
(1)访问初始顶点v并标记顶点v已访问。
(2)查找顶点v的第一个邻接顶点w。
(3)若顶点v的邻接顶点w存在,则继续执行;否则回溯到v,再找v的另外一个未访问过的邻接点。
(4)若顶点w尚未被访问,则访问顶点w并标记顶点w为已访问。
(5)继续查找顶点w的下一个邻接顶点wi,如果v取值wi转到步骤(3)。直到连通图中所有顶点全部访问过为止。
b) 若用邻接矩阵Matrix存储该矩阵,写出该矩阵

解析:设G=(V,E)是具有n个顶点的图,则G的邻接矩阵是具有如下性质的n阶方阵:

c) 若用非递归方式实现深度优先遍历,请叙述大致的实现思想
用一个顺序栈来记录访问过的顶点。
d) 用你熟悉的任何语言实现非递归深度优先遍历
- void DFS( int v)
- {
- cout << " v"<< v ;
- int top = -1 ;
- visited[v] = true ;
- stack[++top] = v ;
- while ( top != -1)
- {
- v = stack[top] ;
- for (int i = 0 ; i < MAX_NODE ; i++)
- {
- if (Matric[v][i] == 1 &&!visited[i])
- {
- cout << " v" << i ;
- visited[i] = true ;
- stack[ ++top ] = i ;
- break ;
- }
- }
- if( i == MAX_NODE)
- {
- top -- ;
- }
- }
- }
第三部分(选做):C++开发工程师必做,其他选做(15分)
1.(6分)给定一个巨大的文本文件,写一个程序随机输出文件任意k行(k不大,k行能放入内存),要求每一行出现概率相等,请给出核心算法,算法复杂度以及简要的算法原理说明。
先选中前k个,从第k+1个元素到最后一个元素为止,以1/i(i = k+1,k+2,...,N)的概率选中第i个元素,并且随机替代掉一个原先选中的元素,这样一直遍历完所有的元素之后,得到k个元素。可以保证最后都是随机获取。
原理:每次都是以 k/i 的概率来选择。
证明:假设n-1时候成立,即前n-1个数据被返回的概率都是1/n-1,当前正在读取第n个数据,以1/n的概率返回它。那么前n-1个数据中数据被返回的概率为:(1/(n-1))*((n-1)/n)= 1/n,假设成立。
参考google蓄水池算法。
2.(9分)Spin Lock是一种较为常见与使用的互斥方法,下面是一种其实现方式:
- typedef int lock_t
- void initlock(void volatile lock_t*lock_status){
- *lock_status= 0;
- }
- void lock(void volatile lock_t* lock_status){
- while(test_and_set(lock_status)== 1);
- }
- void unlock(void volatile lock_t*lock_status){
- *lock_status= 0;
- }
a) volatile关键字的作用
volatile关键词影响编译器编译的结果,用volatile声明的变量表示该变量随时可能发生变化,与该变量有关的运算,不要进行编译优化,以免出错。
b) 怎样优化lock函数(提示:多CPU下如何提高CPUCache效率)
c) 上述代码可能存在的问题(内存模型考虑)
参考 spinlock剖析与改进

















 889
889

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









