






在当今的人工智能领域,大型预训练模型如 GPT、BERT 等已成为解决自然语言处理(NLP)任务的强大工具3。然而,要让这些模型更好地适应特定任务或领域,往往需要进行微调3。以下是 7 种主流的大模型微调方法:
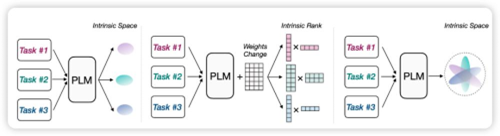
1. LoRA(Low - Rank Adaptation)
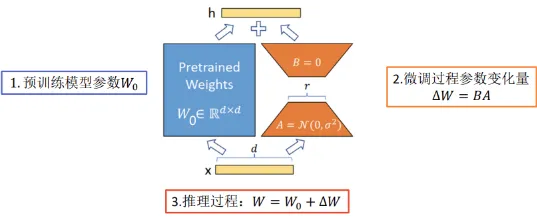
- 原理1:在模型的决定性层次中引入小型、低秩的矩阵来实现模型行为的微调,而无需对整个模型结构进行大幅度修改。确定需要微调的权重矩阵,一般位于模型的多头自注意力和前馈神经网络部分。引入两个维度较小的低秩矩阵 A 和 B,通过它们的乘积 AB 生成一个新矩阵,其秩远小于原始权重矩阵的秩,最后将新生成的低秩矩阵 AB 叠加到原始权重矩阵上。
- 优点1:在不显著增加额外计算负担的前提下,能够有效地微调模型,同时保留模型原有的性能水准。
- 应用场景3:当需要将一个通用语言模型微调至特定领域,如医疗健康领域时,LoRA 可以显著减少调整成本,同时保持模型的高效性。
2. QLoRA(Quantized Low - Rank Adaptation)
- 原理2:结合了 LoRA 方法与深度量化技术,将预训练模型量化为 4 位,极大地减少了模型存储需求,同时保持了模型精度的最小损失。在训练期间,先以 4 - bit 格式加载模型,训练时将数值反量化到 bf16 进行训练,大幅减少了训练所需的显存。
- 优点3:在资源有限的环境下,如边缘计算或移动设备中,能够显著减少内存和计算需求,提供了一种有效的解决方案。
- 应用场景3:适用于需要高效部署和训练模型的场景,像对资源要求较高的移动应用或物联网设备中的模型微调。
3. 适配器调整(Adapter Tuning)
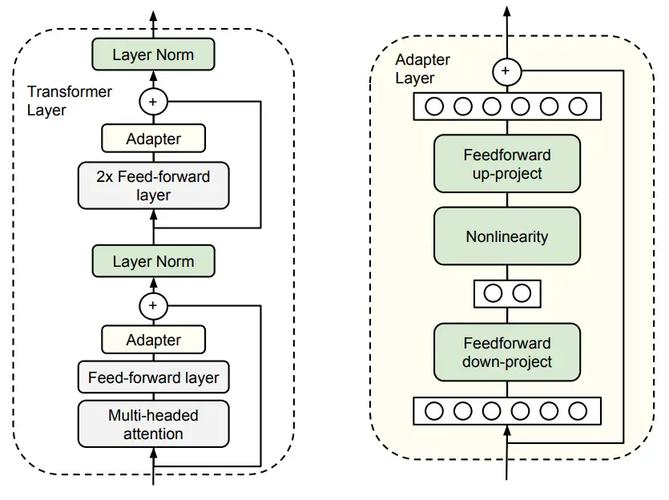
- 原理9:在模型的每个层或选定层之间插入小型神经网络模块,即 “适配器”。在微调过程中,原有的预训练模型参数保持不变,仅适配器的参数在微调过程中更新。适配器模块先把输入的 d 维特征向量通过下投影前馈层投影为 r 维向量,应用非线性层,再通过上投影前馈层投影回一个 d 维向量。
- 优点9:能让模型迅速适应新任务,同时保持其他部分的通用性能,在资源有限的情况下更容易进行模型调整,且能在特定任务上保留更多的预训练知识。
- 应用场景3:当需要微调一个大型模型以执行多个不同任务时,适配器调整提供了一种灵活且高效的解决方案。
4. 前缀调整(Prefix Tuning)
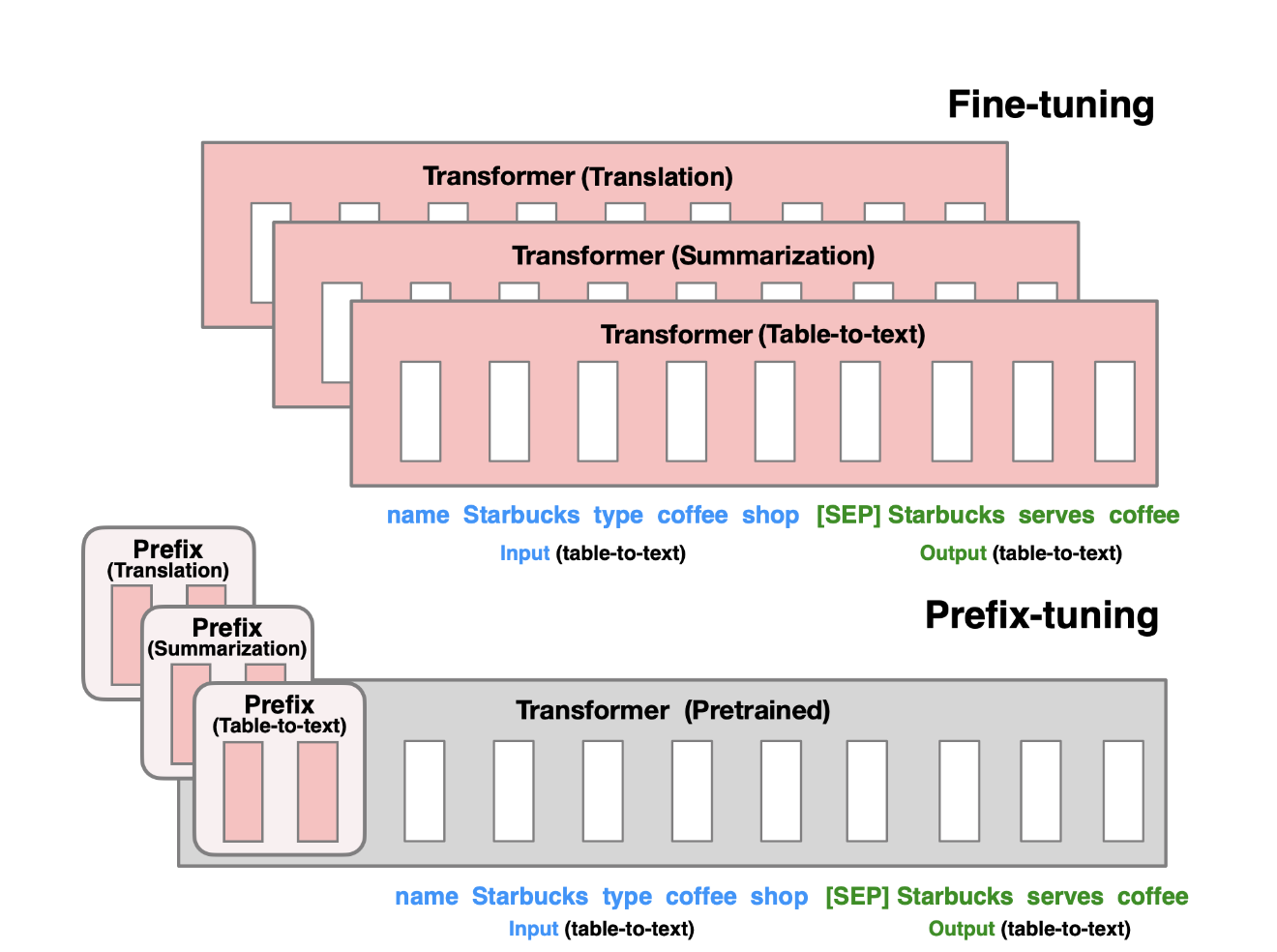
- 原理1:在预训练的语言模型输入序列前添加可训练、任务特定的前缀,从而实现针对不同任务的微调。前缀是一种连续可微的虚拟标记,与离散的 Token 相比,更易于优化并且效果更佳。
- 优点1:不需要调整模型的所有权重,通过在输入中添加前缀来调整模型的行为,节省大量的计算资源,使得单一模型能够适应多种不同的任务。
- 应用场景3:在需要快速适应不同任务而又不希望为每个任务保存一整套微调后模型权重的情况下适用,例如在一些需要频繁切换任务的自然语言处理场景中。
5. 提示调整(Prompt Tuning)
- 原理1:在预训练语言模型输入中引入可学习嵌入向量作为提示,这些可训练的提示向量在训练过程中更新,以指导模型输出更适合特定任务的响应。
- 优点3:模仿自然语言中的提示形式,使用较少的向量来模仿传统的自然语言提示,能通过少量提示信息引导模型生成特定类型的输出。
- 应用场景3:当需要通过少量提示信息引导模型生成特定类型的输出时,比如在文本生成任务中,希望模型按照特定的风格或主题生成内容时可以使用。
6. P - Tuning 及 P - Tuning v2
- 原理:P - Tuning 及其升级版 P - Tuning v2 是在输入序列中添加连续可微提示的微调方法,通过优化提示向量来更好地引导模型输出,同时保持模型的灵活性和通用性3。
- 优点3:在处理复杂 NLP 任务时,能帮助模型更好地理解和生成符合任务要求的输出。
- 应用场景3:适用于各种复杂的自然语言处理任务,如语义理解、文本摘要等,尤其是对于那些需要模型深入理解文本语义和上下文关系的任务。
7. 全面微调(Fine - tuning)
- 原理2:涉及调整模型的所有层和参数,以适配特定任务。此过程通常采用较小的学习率和特定任务的数据,可以充分利用预训练模型的通用特征。
- 优点3:能够全面优化模型性能,在资源充足且对模型性能有严格要求的情况下,可获得最佳的模型性能。
- 应用场景3:适用于对模型性能要求极高的场景,如一些对准确性要求苛刻的医疗诊断、金融风险评估等领域。

















 1128
1128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









