







今天,仔细查阅了一份关于AIGC(人工智能生成内容)的研报,其中展示了一个令人印象深刻的案例。
大模型在小说领域的应用。
引用一句话: AI对于创作,就像辅助驾驶,但不是自动驾驶。要给作家提供更多辅助工具,帮助作家迸发出更多好创作。
AI当然只能辅助,有血有肉的小说,是需要作家用心去创作的。 AI可以提供灵感和建议,帮助整理结构,甚至生成初稿,但它无法真正理解人类的情感、复杂的社会关系以及深层次的人性。

小说不仅仅是文字的堆砌,更是作家对世界的独特观察、对生活的深刻感悟以及对人性多维度的思考。 只有作家才能赋予角色真实的生命,让故事充满温度与共鸣。 因此,AI只能作为工具,真正的创作灵魂仍需作家来塑造。
一、小说大模型架构
在之前,咱们详细探讨了大模型的应用架构设计。该架构采用了层次化的结构,确保了系统的模块化和可扩展性。 其中,智能体(Agent) 作为整个架构的核心服务层,扮演着至关重要的角色。
智能体不仅负责底层的数据处理、模型推理和决策支持,还为上层的业务逻辑层提供了强大的支撑。 通过这种分层设计,业务逻辑层可以专注于具体的应用场景和用户需求,而无需过多关注底层的技术细节,从而实现了高效、灵活的系统集成与应用开发。
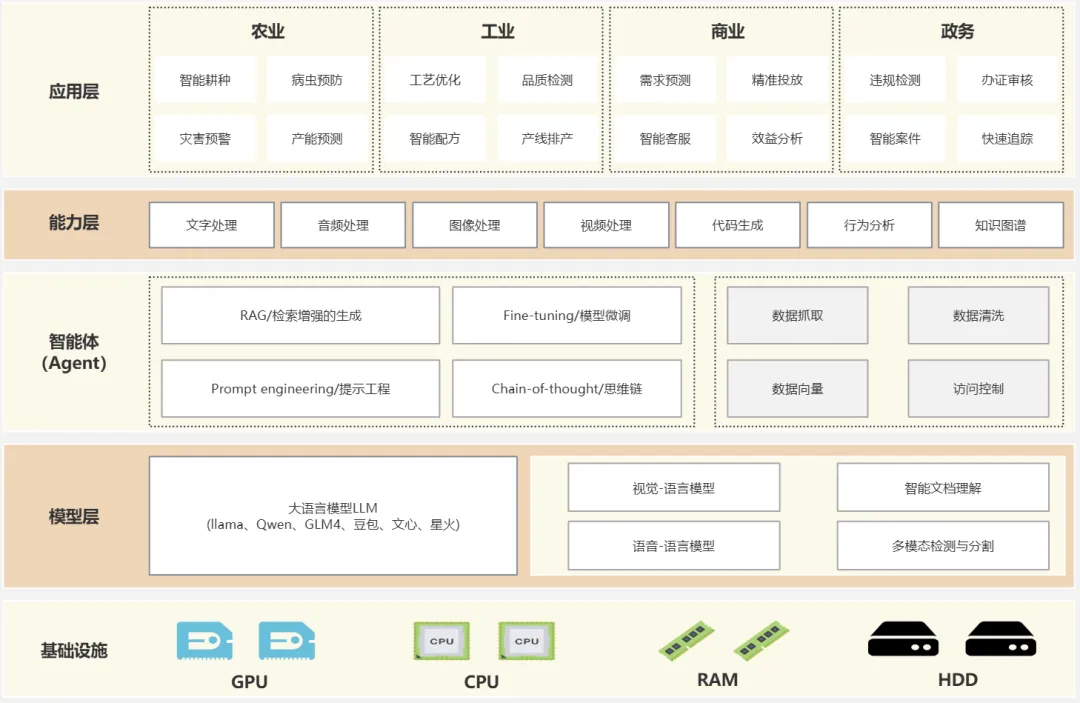
在这样的体系中,顶层的应用程序可以通过标准化接口获取必要的能力,实现高效且灵活的开发与运维流程。
但是,这里是小说大模型架构,针对的是小说的数据训练。可以简单的说是一个小说大模型的垂直微调。
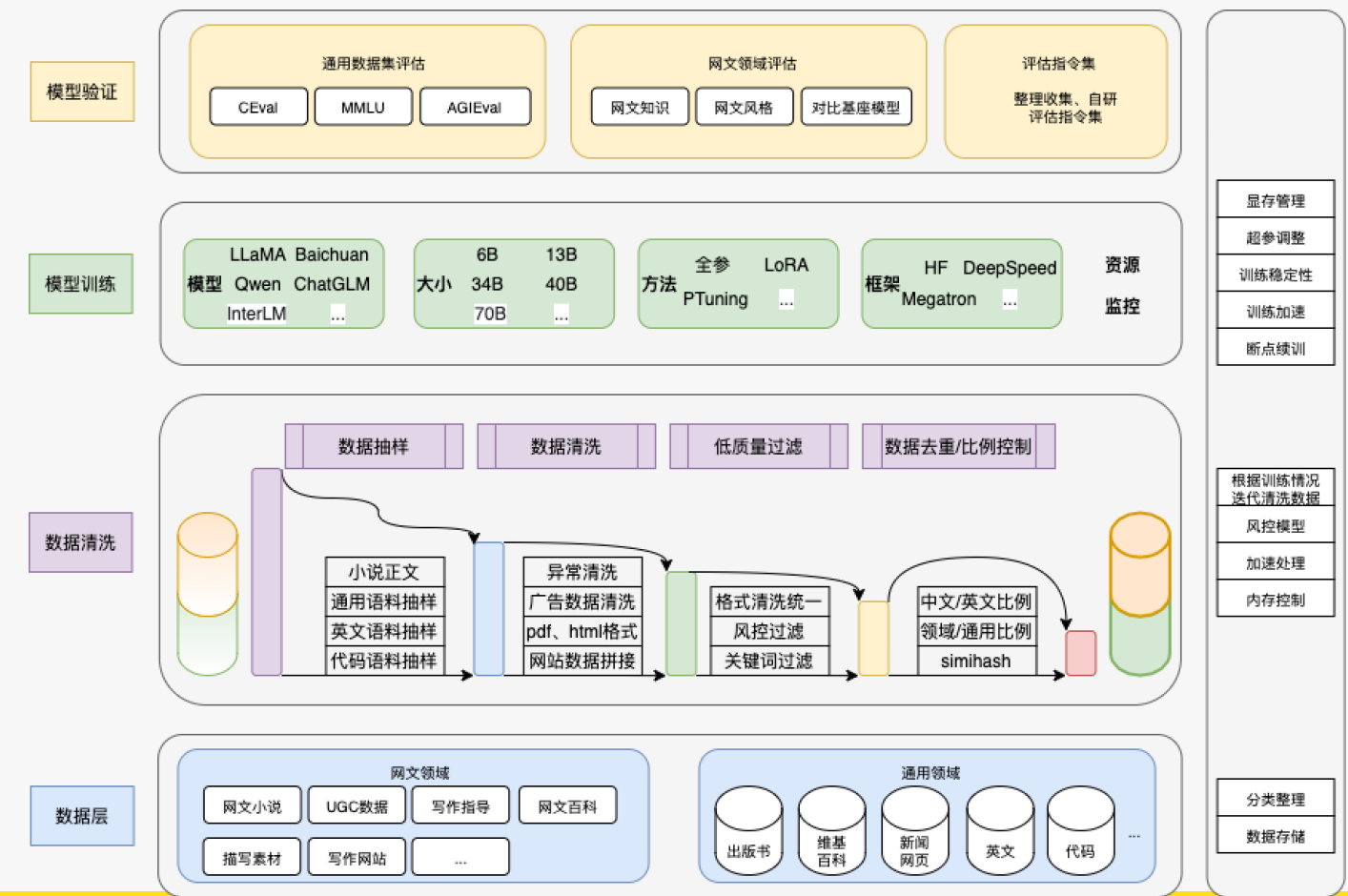
一个数据处理和模型微调训练的流程,分为以下几个层级:
(1)数据层:这是流程的起点,包含原始数据来源,如网文领域和通用领域的数据。
(2)数据清洗:在数据层之上,对原始数据进行处理,包括数据抽样、清洗、去重、过滤等步骤。
(2)模型训练:使用清洗后的数据进行模型的训练,包括不同的模型和训练方法。
(3)模型验证:在模型训练之后,对模型进行验证,确保其性能和准确性。
(4)资源监控:在整个流程中,对资源使用情况进行监控,以优化训练过程。
在数据层,数据清洗层这里都只是做高质量的微调数据,因为高质量的微调数据决定了模型的上限。
这种“预训练+微调大模型”的模式具有显著优势,它通过预训练模型将通用语言知识迁移到下游任务,减少了训练时间和数据需求。微调过程能够快速优化模型以适应特定任务,降低部署难度。此外,这种模式具有高可扩展性,方便应用于多种自然语言处理任务。
二、小说垂直大模型训练过程
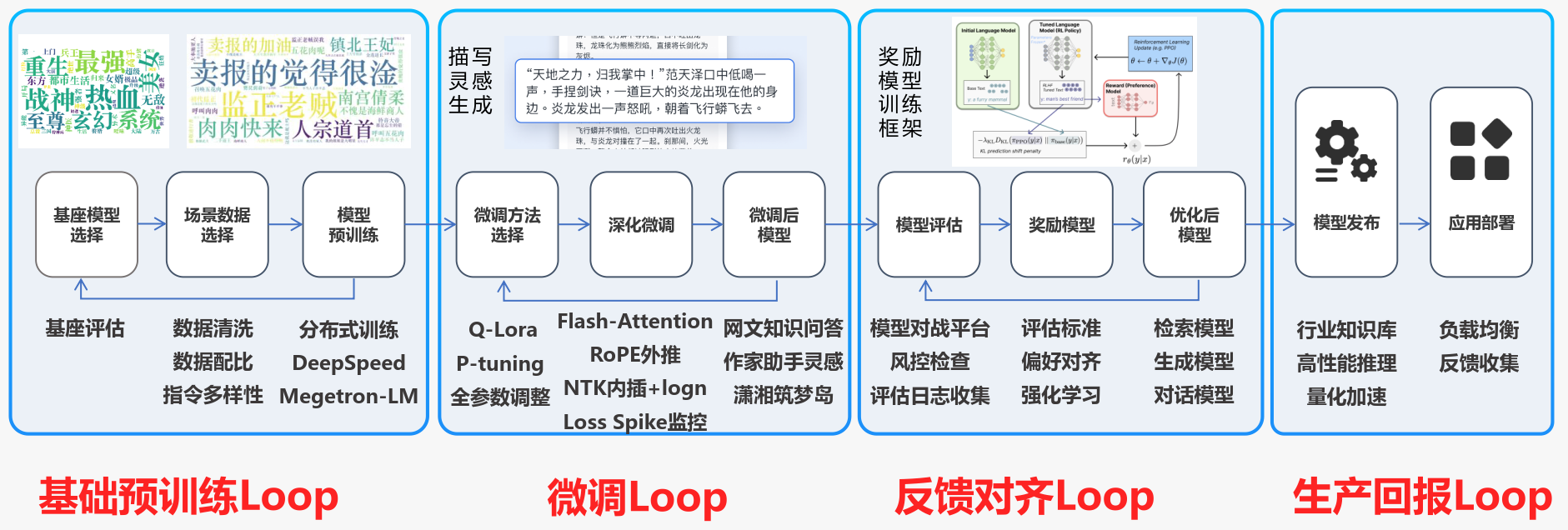
2.1 基础预训练
基础预训练这里,融入垂直的网文数据。在这个阶段,模型通过基础预训练来学习语言的通用特征和知识。
【流程设计】:
- 基座模型选择:选择合适的预训练模型作为基础,这决定了模型的起点能力。
- 场景数据选择:根据应用场景选择数据,确保模型学习到与应用相关的特征。
- 模型预训练:通过数据清洗、配比、指令多样性等方法,提高数据质量,使模型能够学习到更广泛的语言模式。
- DeepSpeed和Megatron-LM:使用这些技术可以加速训练过程并支持大规模模型的训练。
2.2 深化微调
在基础预训练之后,通过微调来定制模型以适应特定的细分场景。
【流程设计】:
- 微调方法选择:根据任务需求选择合适的微调技术,如Q-LoRA、Flash-Attention等,这些技术可以提高微调的效率和效果。
- 深化微调:通过更深入的微调,模型可以更好地理解和生成特定场景下的文本。
- 微调后模型:经过微调的模型能够更准确地响应特定任务。
2.3 模型评估与反馈对齐
评估模型的性能,并通过反馈来优化模型。
【流程设计】:
- 奖励模型训练框架:通过奖励模型来评估模型的输出,这有助于模型学习如何产生更符合预期的响应。
- 模型评估:通过模型对战平台、风控检查等方法来评估模型的性能。
- 奖励模型:根据评估结果调整奖励模型,以更好地引导模型学习。
- 优化后模型:通过反馈和奖励机制,模型能够不断优化,提高性能。
2.4 领域落地与生产环境部署
目的:将模型部署到实际应用中,并确保其在生产环境中的稳定性和效率。
【流程设计】:
- 模型发布:将经过训练和评估的模型发布到生产环境。
- 应用部署:在实际应用中部署模型,如搜索引擎、生成模型、对话模型等。
- 负载均衡与反馈收集:确保模型在高负载下稳定运行,同时收集用户反馈以进一步优化模型。
- 量化加速:通过量化技术提高模型的运行效率,使其更适合在资源受限的环境中运行。
三、Dify的长篇小说案例
对于许多小伙伴来说,获取小说数据并进行清理是一项技术性较强且耗时的工作,而具备基础硬件设备来进行模型的预训练和微调更是难上加难。
但是,即使没有这些资源和能力,大家仍然可以通过Dify的工作流模式来体验长篇小说的生成。
Dify提供了一个简便的界面和流程,让用户无需深入了解复杂的编程或硬件配置,就能轻松生成高质量的小说内容,享受创作的乐趣。


















 7994
7994

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











