







 《DeepRebirth: A General Approach for Accelerating Deep Neural Network Execution on Mobile Devices》提出了一种针对移动设备加速深度神经网络的新方法。文章指出,传统的压缩和加速方法对现代网络效果有限,因为它们主要关注全连接层。DeepRebirth通过StreamLine Merging和Branch Merging两种融合技术,减少non-tensor layers的时间消耗,特别是针对GoogLeNet的Inception结构。实验结果显示,这种方法可以显著提高网络执行速度,最高可达2-3倍。
《DeepRebirth: A General Approach for Accelerating Deep Neural Network Execution on Mobile Devices》提出了一种针对移动设备加速深度神经网络的新方法。文章指出,传统的压缩和加速方法对现代网络效果有限,因为它们主要关注全连接层。DeepRebirth通过StreamLine Merging和Branch Merging两种融合技术,减少non-tensor layers的时间消耗,特别是针对GoogLeNet的Inception结构。实验结果显示,这种方法可以显著提高网络执行速度,最高可达2-3倍。
这里介绍2017ICLR OpenReview中的一篇有关网络加速的文章《DeepRebirth: A General Approach for Accelerating Deep Neural Network Execution on Mobile Devices》。 看文章标题觉得高大上,看方法细节觉得卧槽好水,看自己的验证结果好像还有点用。
附:2017ICLR openreview http://openreview.net/group?id=ICLR.cc/2017/conference
———————— 引言 ————————
纵观之前的大部分压缩和加速方法都是在打全连接层的注意,比如分解、量化、剪枝等,但是目前的主流网络比如GoogLeNet和ResNet等,都尽可能的用大量小核卷积层和pooling层来取代全连接层。因此,以往的很多方法都不是很适合。
首先,作者将层分为:non-tensor layers 和 tensor layers,前者指不带参数的层,比如pooling、LRN、BatchNorm、softmax层等,后者则指Convolution、InnerProduct这些带参数的层。
然后作者统计了几个流行网络中,这些non-tensor layers 所消耗的时间,如下图。这些层,没有参数还占用空间和时间,作者觉得应该搞掉他们。
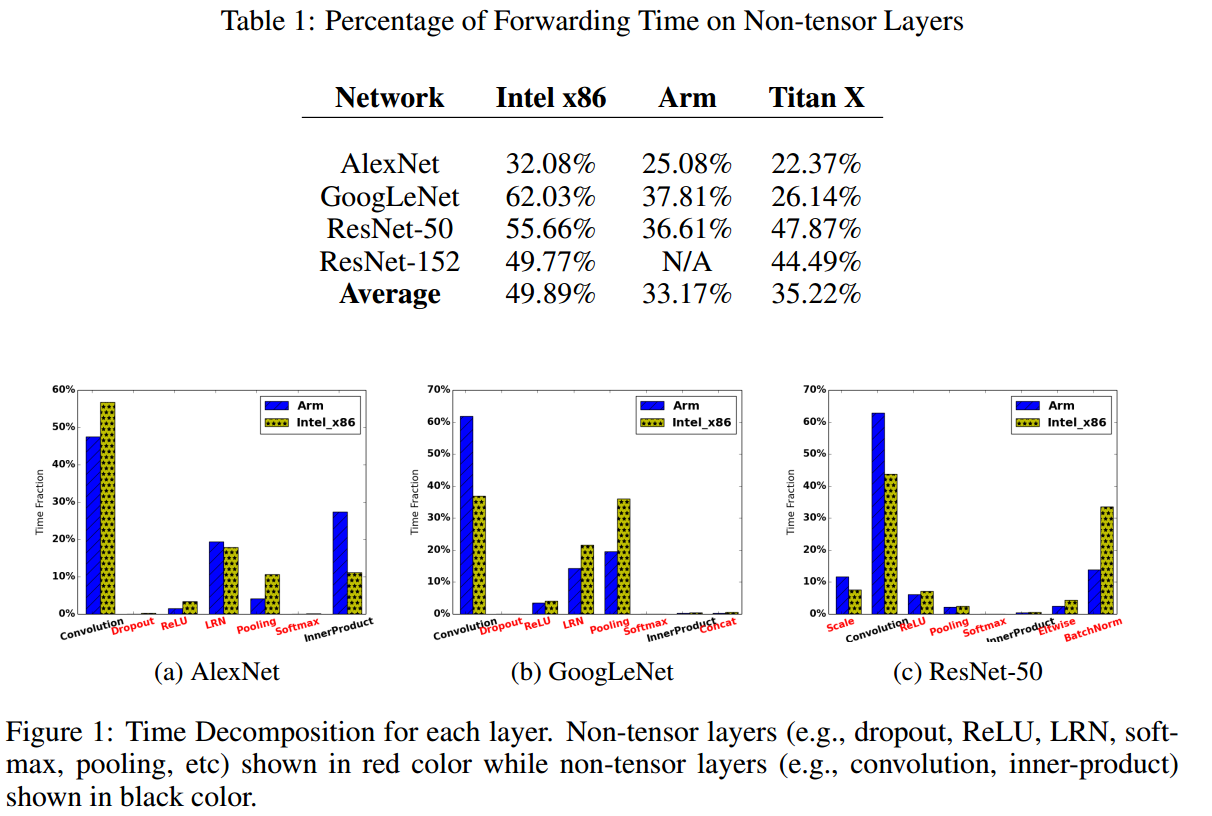
———————— 方法:DeepRebirth ————————
为了降低non-tensor layers的消耗,作者的方法就是融合,这里一共给出了2种融合的情况。
———————— StreamLine Merging ————————
思路非常简单,如下图:
左边是原始网络的一部分,我们用右边的等价结构来代替它,然后重新finetune网络。finetune的时候,新结构的学习率设为其他层的10倍。
注意,原结构是 “3x3卷积 stride=1” + “LRN” + “3x3pooing stride=2”,替换后的结构则简化为 “3x3卷积 stride=2”
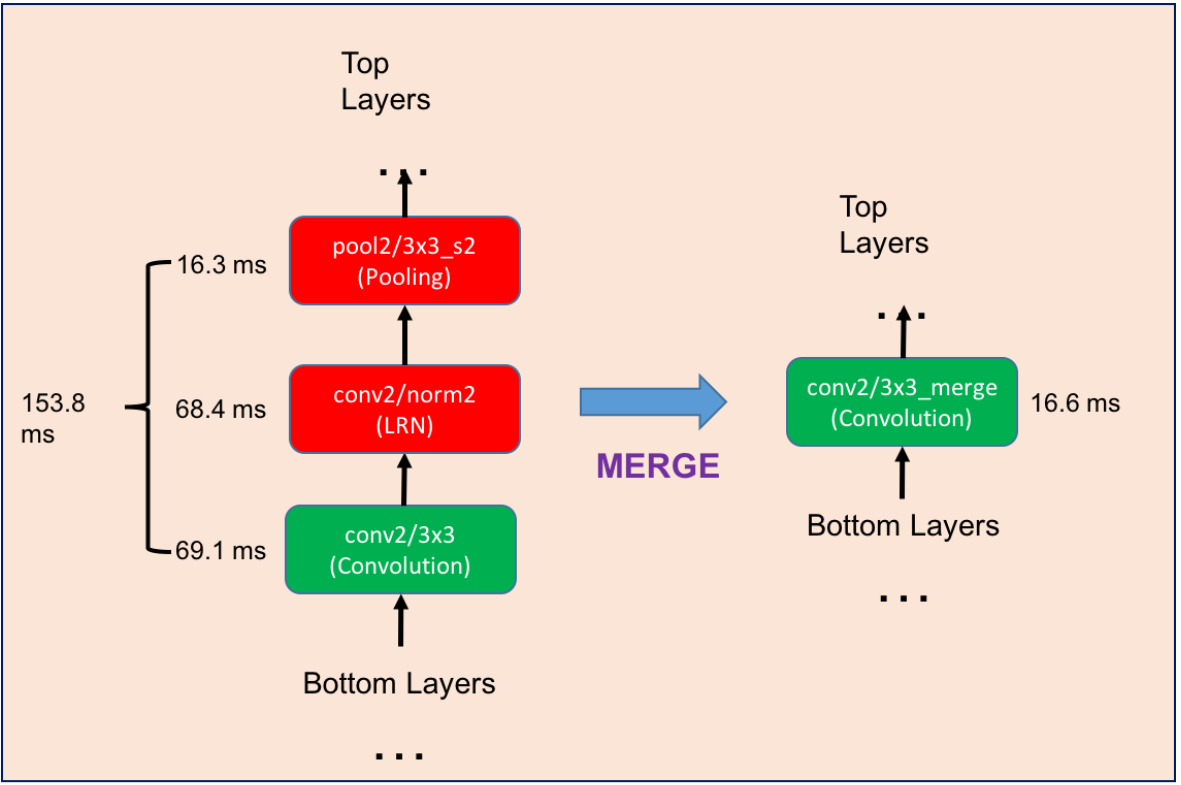
———————— Branch Merging ————————
这种融合主要针对GoogLeNet中的Inception结构。GoogLeNet虽然参数比较少,但由于层很多,所以速度并没有特别快。
如下图,作者融合掉了单独的1x1卷积分支以及pooling分支,同时为了保证融合后的结构可以和其他部分衔接,融合后的卷积层的num_output也要做出适当调整。
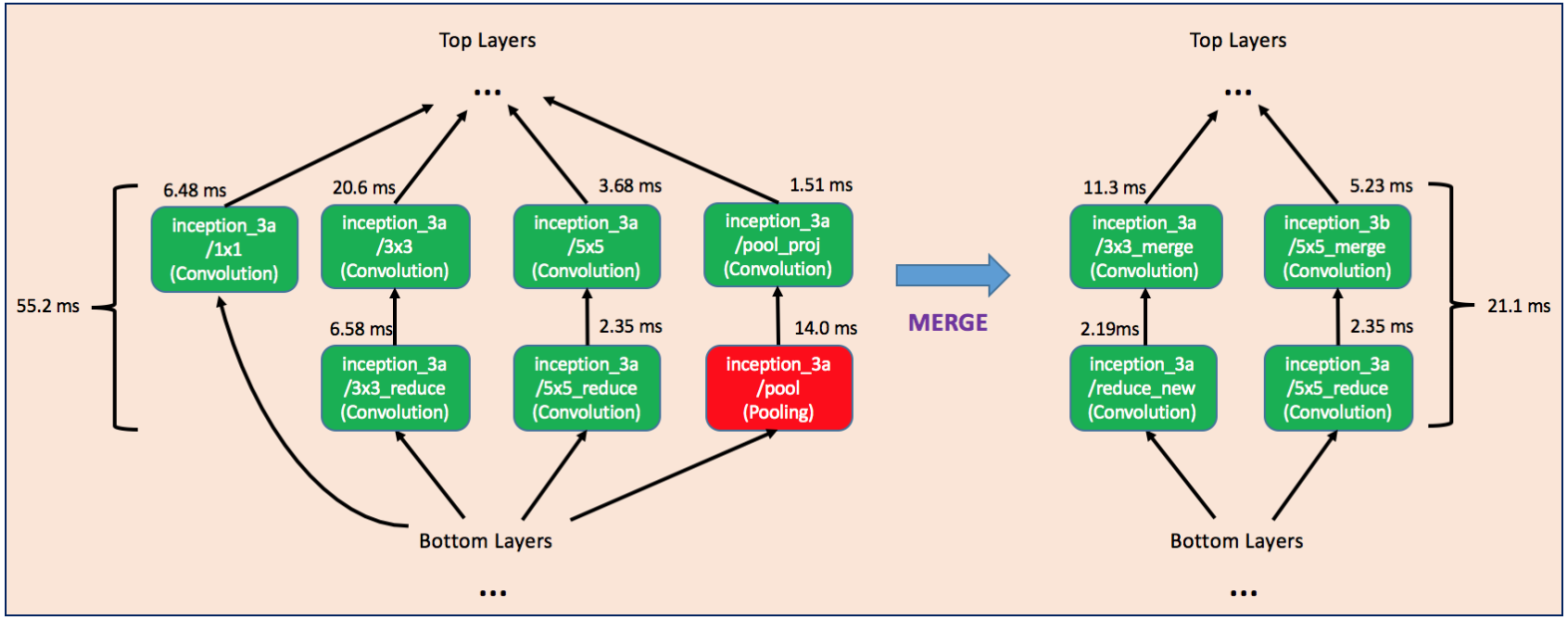
———————— 实验结果 ————————
这里只给出GoogLeNet的结果。下图是性能损失差异:
其中 Tucker Decomposition 是《Compression of deep convolutional neural networks for fast and low power mobile applications》 中提出的一种压缩分解方法。

下面是速度提高对比:能加速2-3倍,我已经很满意了。T_T
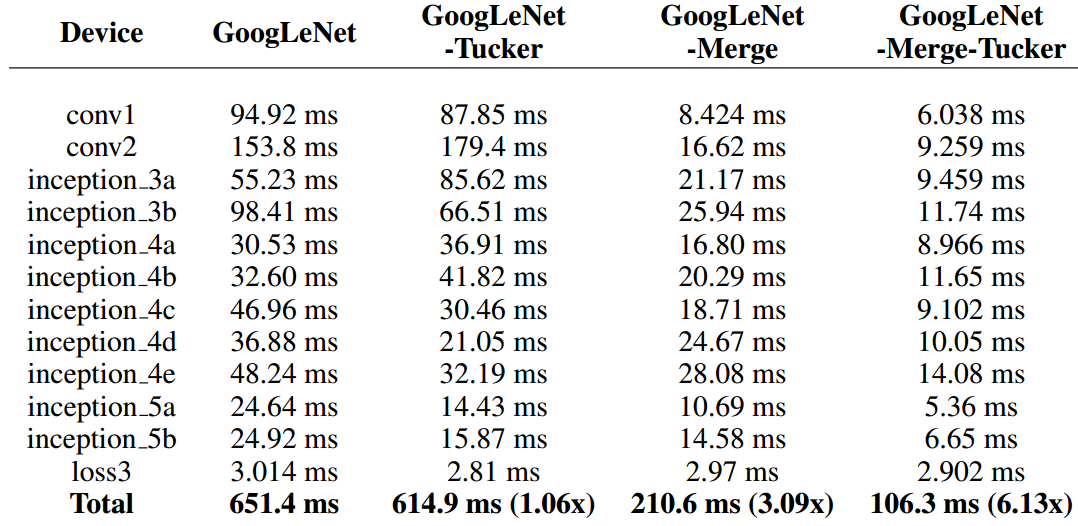















 9255
9255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









