







堆排序简介
堆排序可以看作是简单选择排序的一种的改进方法,平均复杂度为 \(O(n\log n)\),因此应用场合较多。
其原理同简单选择排序相似:将数据分为已排序和未排序的两部分,并且不断的从未排序数据中选取最大(或最小)数据加入到已排序集合中。不同之处在于, 堆排序采用了一种特殊的二叉堆结构来快速的寻找最大值。(如下图,首先建立二叉堆,然后进行选择排序)
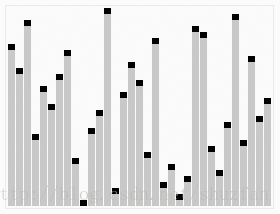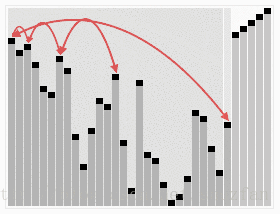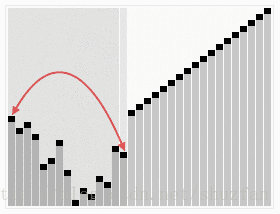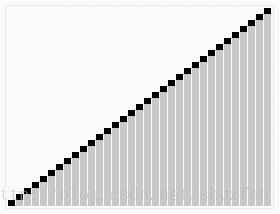
二叉堆简介
二叉堆是完全二叉树或者近似完全二叉树结构。
二叉堆有两种:
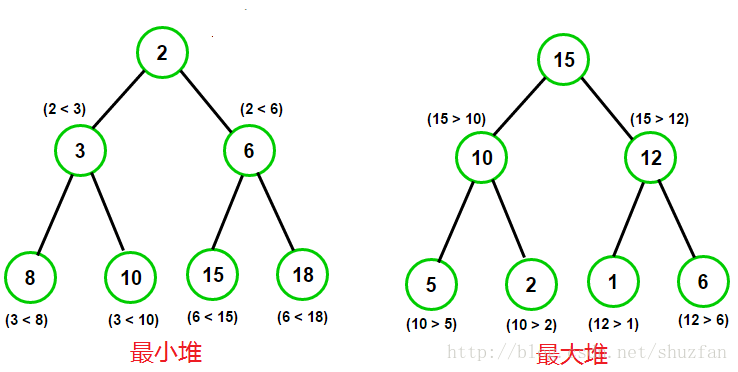
最小堆:父结点的键值总是小于或等于任何一个子节点的键值。
最大堆:父结点的键值总是大于或等于任何一个子节点的键值;
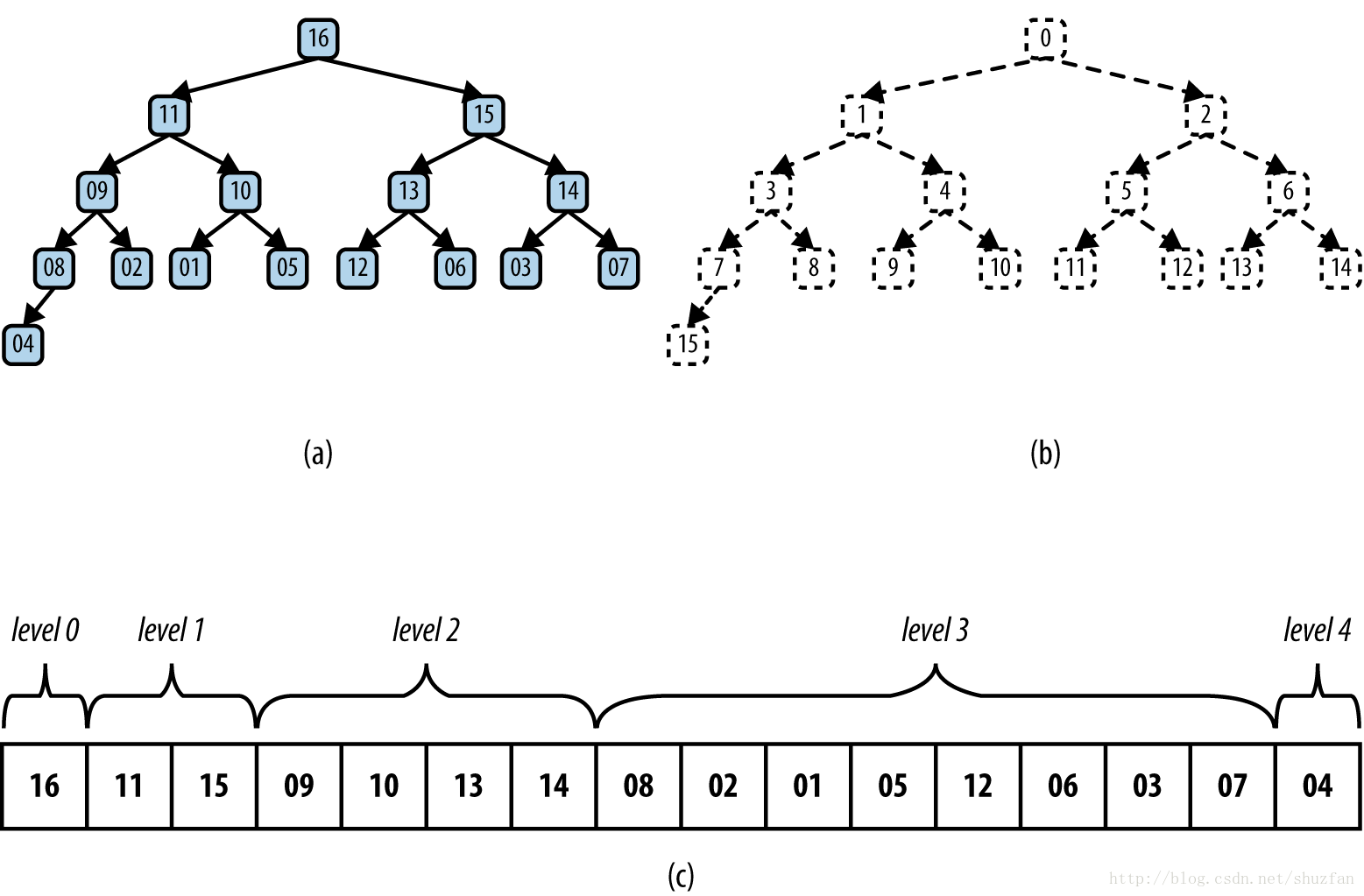
二叉堆的存储可以采用数组形式,如下图:
二叉堆的建立流程如下:(最大堆)
- (1). 在堆的根部插入一个新的节点;
- (2). 将该节点的值与其父亲节点的值进行比较,如果父亲节点的值比较小则进行数值交换;
- (3). 重复第2步知道整个堆满足最大堆;
- (4). 重复1、2、3步直至处理完毕所有数据。

堆排序
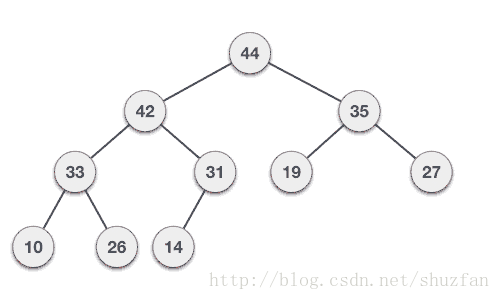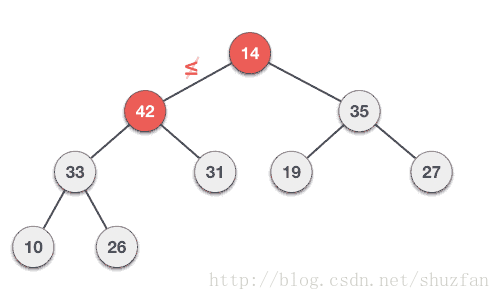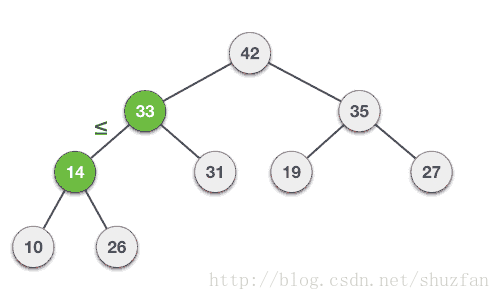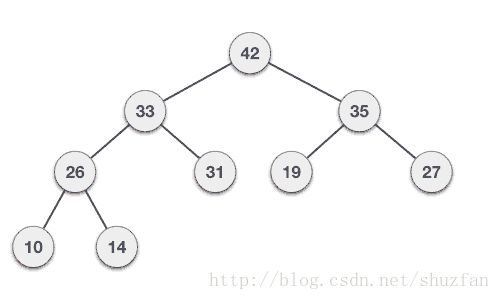
以上面的最大堆为例,尽管其数组表示形式不一定是排好序的,但我们总能保证根节点的数据是最大值。
于是,二叉堆的核心:每次取走最大值用于选择排序,重排剩下的堆保证其仍为最大堆。
二叉堆取值重排策略:(最大堆)
- (1). 取走根节点的值(最大值),并将整个堆的最后一个元素移动到根节点;
- (2). 将孩子节点的值与其父亲节点的值进行比较,如果父亲节点的值比较小则进行数值交换;
- (3). 重复第2步知道整个堆满足最大堆;
总结
堆排序不是稳定排序,平均复杂度为 \(O(n\log n)\),虽然堆排序在很多机器上没有快速排序高效,但是堆排序在最差情况下的运行时间要优于快排。
参考资料:
(1)WIKI 堆排序:https://en.wikipedia.org/wiki/Heapsort
(2)排序算法:https://www.safaribooksonline.com/library/view/algorithms-in-a/9781491912973/ch04.html
(3)WIKI 二叉堆:https://en.wikipedia.org/wiki/Binary_heap
(4)堆结构: https://www.tutorialspoint.com/data_structures_algorithms/heap_data_structure.htm















 278
278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









