









之所以要手动编写数据生成器是因为我做的工作是图像回归,而不是图像分类。也就是说作为监督学习的标签是连续型变量而不是离散型变量,而据我所知keras自带的ImageDataGenerator类只能用于图像分类。网上已有不少自己写的数据生成器,但如果希望对比训练数据集和测试数据集的效果(如损失函数),在用fit_generator()方法训练模型时参数validation_data支持的数据生成器最好是keras.utils.Sequence的子类,否则validation_steps参数不能为空。查了一遍keras文档,继承Sequence的类并不难写,文档里给了一个简单的例子。
from skimage.io import imread
from skimage.transform import resize
import numpy as np
# 这里,`x_set` 是图像的路径列表
# 以及 `y_set` 是对应的类别
class CIFAR10Sequence(Sequence):
def __init__(self, x_set, y_set, batch_size):
self.x, self.y = x_set, y_set
self.batch_size = batch_size
def __len__(self):
return int(np.ceil(len(self.x) / float(self.batch_size)))
def __getitem__(self, idx):
batch_x = self.x[idx * self.batch_size:(idx + 1) * self.batch_size]
batch_y = self.y[idx * self.batch_size:(idx + 1) * self.batch_size]
return np.array([
resize(imread(file_name), (200, 200))
for file_name in batch_x]), np.array(batch_y)下面是我个人的理解,如果有误请批评指正。继承Sequence类必须重载三个私有方法__init__、__len__和__getitem__,主要是__getitem__。__init__是构造方法,用于初始化数据的,只要能让样本数据集通过形参顺利传进来就行了。__len__基本上不用改写,用于计算样本数据长度。__getitem__用于生成批量数据,喂给神经网络模型训练用,其输出格式是元组。元组里面有两个元素,每个元素各是一个列表,第一个元素是batch data构成的列表,第二个元素是label构成的列表。在第一个列表中每个元素是一个batch,每个batch里面才是图像张量,所有的batch串成一个列表。第二个列表比较普通,每个元素是个实数,表示标签。这点跟生成器不一样,生成器是在执行时通过yield关键字把每个batch数据喂给模型,一次喂一个batch。__getitem__相当于生成器的作用,如同ImageDataGenerator,但注意编写方法时返回数据不要用yield,而要用return,像一个普通函数一样。至于后台怎么迭代调用这个生成器,这是keras后台程序处理好的事,我们不用担心。我这里程序假定样本数据已经转成pickle的形式,是字典构成的列表,字典的键值分别是feature和label,其中feature是图像张量。
from keras.utils import Sequence
import numpy as np
from sklearn.utils import shuffle
class ImageGenerator(Sequence):
def __init__(self, input_sample, batch_size=50, shuffle_flag=True):
#我增加了洗牌功能,以打乱原数据集顺序
self.input_sample = input_sample
self.batch_size = batch_size
self.shuffle = shuffle_flag
self.indexes = np.arange(len(self.input_sample))
def __len__(self):
return int(np.ceil(len(self.input_sample) / float(self.batch_size)))
def __getitem__(self, idx):
if self.shuffle ==True:
data = shuffle(self.input_sample)
else:
data = self.input_sample
batch_x = [i['feature'] for i in data[idx * self.batch_size:(idx + 1) * self.batch_size]]
batch_y = [i['label'] for i in data[idx * self.batch_size:(idx + 1) * self.batch_size]]
np_x = np.array(batch_x)
np_y = np.array(batch_y)
if self.shuffle ==True:
return shuffle(np_x, np_y)
else:
return (np_x, np_y)在图像生成器里可以根据需要增加各种data augmentation的自定义方法用于处理图像,但最终都要通过__getitem__方法输出,这样就完成了图像生成器。github上有人编写了带有数据增强功能的Sequence子类生成器,供参考:
https://github.com/matterport/Mask_RCNN/pull/740/commits/48a7f06230f4452fd48e867152a322373059f975
作为一套完整的程序,还需要编写一个能把数据集拆分成训练数集和测试数集的函数:
def train_test_split(data, test_size=0.2, shuffle_flag=True):
if shuffle_flag==True:
data=shuffle(data)
lengh=int(len(data)*(1-test_size))
train_data=data[:lengh]
test_data=data[lengh:]
return train_data, test_data
train_data, test_data=train_test_split(sample)
train_gen = ImageGenerator(train_data, batch_size=100)
test_gen = ImageGenerator(test_data, batch_size=100)接下来就可以训练模型了。模型的架构设计依具体任务而定,损失函数可以用MSE,metrics可以用MAE。
model.compile(optimizer='adam', loss='MSE', metrics=['mae'])
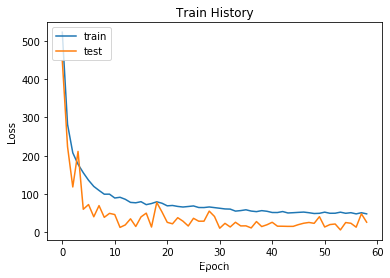
history=model.fit_generator(train_gen, steps_per_epoch=50, epochs=60, validation_data=test_gen, shuffle=True)下面是训练过程中损失的变化曲线。通过观察对比可以发现没有出现明显过拟合,但epoch次数在10次以后测试数据集的损失就不再明显下降。

















 7282
7282

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









