







🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
支持向量机( SVM) 是一个功能强大且用途广泛的机器学习模型,能够执行线性或非线性分类、回归甚至异常值检测。它是机器学习中最受欢迎的模型之一,任何对机器学习感兴趣的人都应该在他们的工具箱中拥有它。SVM 特别适用于复杂的中小型数据集的分类。
本章将解释 SVM 的核心概念、如何使用它们以及它们是如何工作的。
线性 SVM 分类
这SVM 背后的基本思想最好用一些图片来解释。图 5-1显示了在第 4 章末尾介绍的 iris 数据集的一部分。这两个类可以很容易地用一条直线分开(它们是线性可分的)。左图显示了三个可能的线性分类器的决策边界。用虚线表示决策边界的模型非常糟糕,以至于它甚至没有正确地分离类。其他两个模型在这个训练集上工作得很好,但是它们的决策边界非常接近实例,以至于这些模型可能不会在新实例上表现得那么好。相比之下,右图中的实线表示 SVM 分类器的决策边界;这条线不仅将两个类分开,而且尽可能远离最近的训练实例。您可以将 SVM 分类器视为适合类之间最宽的街道(由平行虚线表示)。这个称为大边距分类。
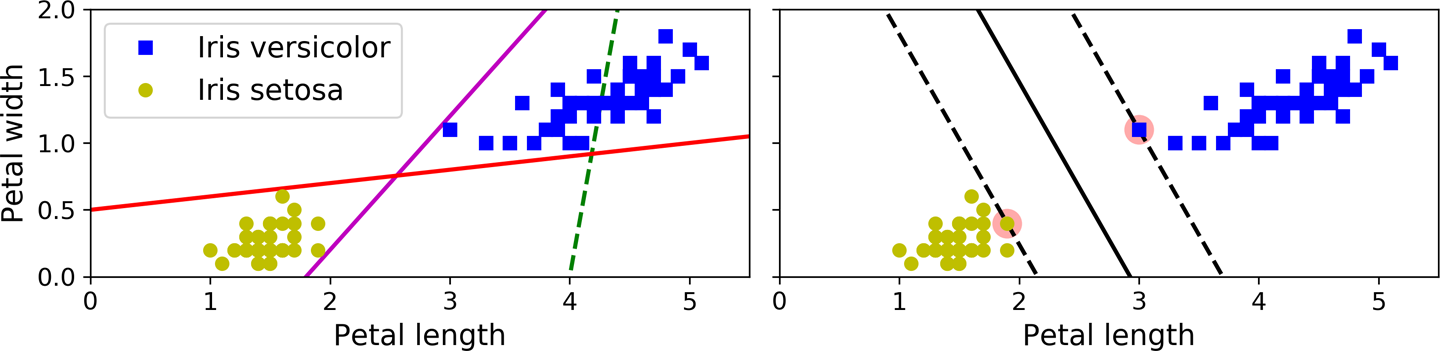
图 5-1。大余量分类
注意在“街外”添加更多训练实例根本不会影响决策边界:它完全由位于街道边缘的实例确定(或“支持”)。这些实例被称为支持向量(它们在图 5-1中被圈出)。

图 5-2。对特征尺度的敏感性
警告
SVM 对特征尺度很敏感,如图 5-2 所示:在左图中,垂直尺度远大于水平尺度,因此尽可能宽的街道接近水平。后特征缩放(例如,使用 Scikit-Learn 的
StandardScaler),右图中的决策边界看起来要好得多。
软保证金分类
如果我们严格要求所有实例都必须远离街道和右侧,这称为硬边距分类。硬边距分类有两个主要问题。首先,它只有在数据是线性可分的情况下才有效。其次,它对异常值很敏感。图 5-3显示了只有一个额外异常值的 iris 数据集:在左侧,无法找到硬边距;在右边,决策边界最终与我们在图 5-1中看到的没有异常值的边界非常不同,而且它可能也无法泛化。
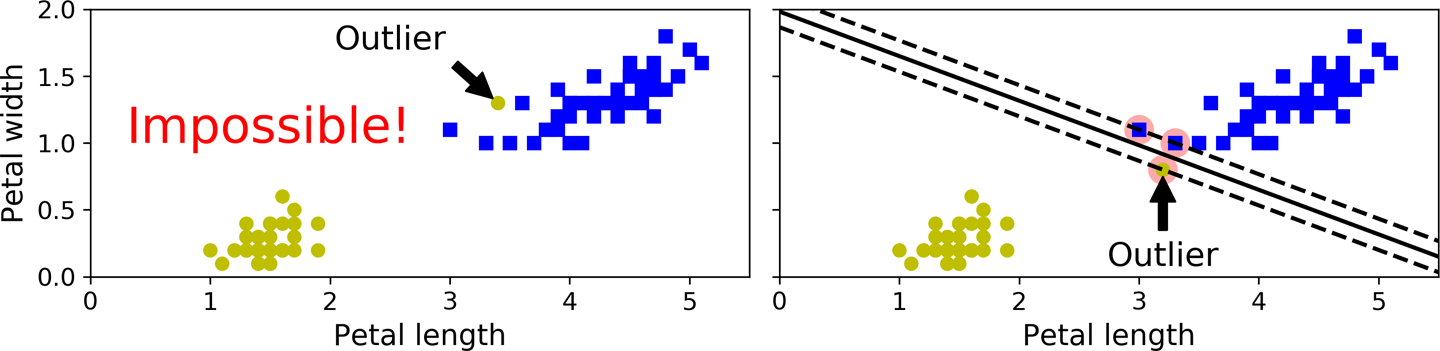
图 5-3。对异常值的硬边距敏感性
至避免这些问题,使用更灵活的模型。目标是在保持街道尽可能大和限制边界违规(即,最终出现在街道中间甚至错误一侧的实例)之间找到良好的平衡。这称为软边距分类。
什么时候使用 Scikit-Learn 创建 SVM 模型,我们可以指定许多超参数。C是这些超参数之一。如果我们将其设置为较低的值,那么我们最终会得到图 5-4左侧的模型。具有很高的价值,我们得到了右边的模型。违反保证金是不好的。通常最好少一些。然而,在这种情况下,左边的模型有很多边距违规,但可能会更好地概括。
图 5-4。较大的边距(左)与较少的边距违规(右)
小费
如果您的 SVM 模型过拟合,您可以尝试通过减少
C.
这以下 Scikit-Learn 代码加载 iris 数据集,缩放特征,然后训练线性 SVM 模型(使用带有的LinearSVC类C=1和铰链损失函数,稍后描述)来检测Iris virginica花:
import numpy as np
from sklearn import datasets
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
iris = datasets.load_iris()
X = iris["data"][:, (2, 3)] # petal length, petal width
y = (iris["target"] == 2).astype(np.float64) # Iris virginica
svm_clf = Pipeline([
("scaler", StandardScaler()),
("linear_svc", LinearSVC(C=1, loss="hinge")),
])
svm_clf.fit(X, y)生成的模型如图 5-4左侧所示。
然后,像往常一样,您可以使用该模型进行预测:
>>> svm_clf.predict([[5.5, 1.7]])
array([1.])笔记
与逻辑回归分类器不同,SVM 分类器不输出每个类的概率。
LinearSVC我们可以使用SVC带有线性内核的类,而不是使用类。创建 SVC 模型时,我们将编写SVC(kernel="linear", C=1). 或者我们可以使用SGDClassifier类,带有SGDClassifier(loss="hinge", alpha=1/(m*C)). 这应用常规随机梯度下降(见第 4 章)来训练线性 SVM 分类器。它的收敛速度不如LinearSVC类快,但它可以用于处理在线分类任务或不适合内存的大型数据集(核外训练)。
小费
该类
LinearSVC对偏差项进行了正则化,因此您应该首先通过减去其均值来使训练集居中。如果您使用 缩放数据,这是自动的StandardScaler。还要确保loss将超参数设置为"hinge",因为它不是默认值。最后,为了获得更好的性能,你应该dual将超参数设置为False,除非有比训练实例更多的特征(我们将在本章后面讨论对偶性)。
非线性 SVM 分类
虽然线性 SVM 分类器在许多情况下非常有效并且工作得非常好,许多数据集甚至不接近线性可分。处理非线性数据集的一种方法是添加更多特征,例如多项式特征(就像您在第 4 章中所做的那样);在某些情况下,这可能会产生线性可分的数据集。考虑图 5-5中的左图:它表示一个只有一个特征x 1的简单数据集。如您所见,该数据集不是线性可分的。但是,如果您添加第二个特征x 2 = ( x 1 ) 2,则生成的 2D 数据集是完全线性可分的。
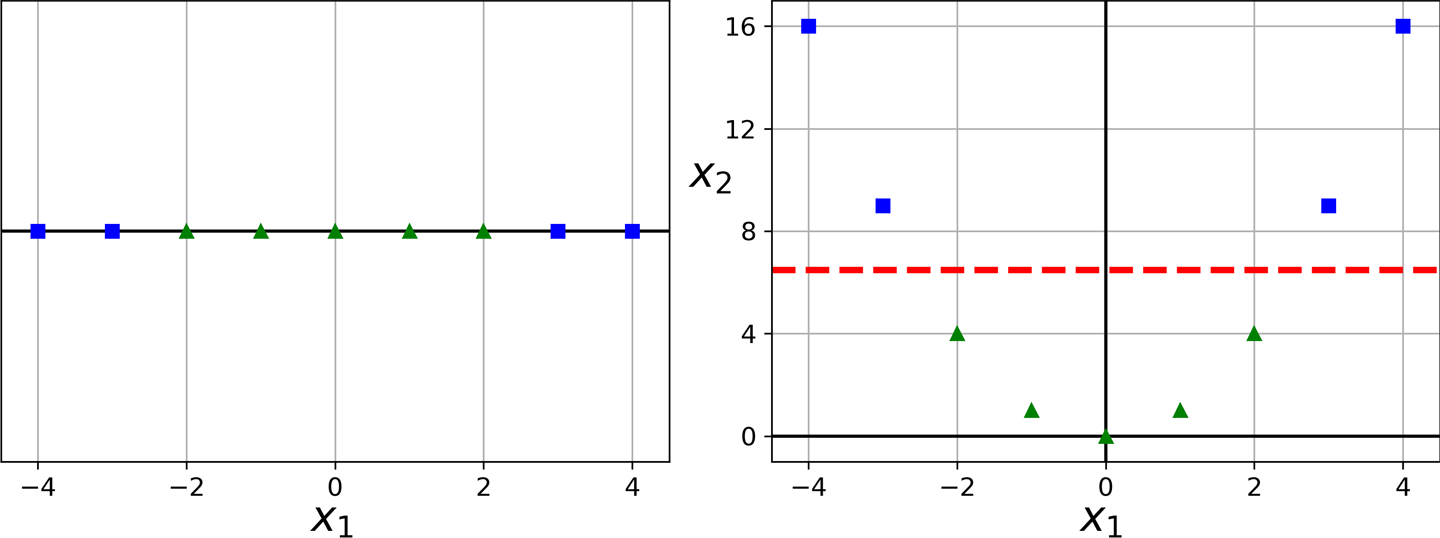
图 5-5。添加特征以使数据集线性可分
要使用 Scikit-Learn 实现这个想法,请创建一个Pipeline包含一个PolynomialFeatures转换器(在“多项式回归”中讨论),然后是 aStandardScaler和 a LinearSVC。让我们在 moons 数据集上进行测试:这是一个用于二进制分类的玩具数据集,其中数据点的形状为两个交错的半圆(见图 5-6)。make_moons()您可以使用以下函数生成此数据集:
from sklearn.datasets import make_moons
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
X, y = make_moons(n_samples=100, noise=0.15)
polynomial_svm_clf = Pipeline([
("poly_features", PolynomialFeatures(degree=3)),
("scaler", StandardScaler()),
("svm_clf", LinearSVC(C=10, loss="hinge"))
])
polynomial_svm_clf.fit(X, y)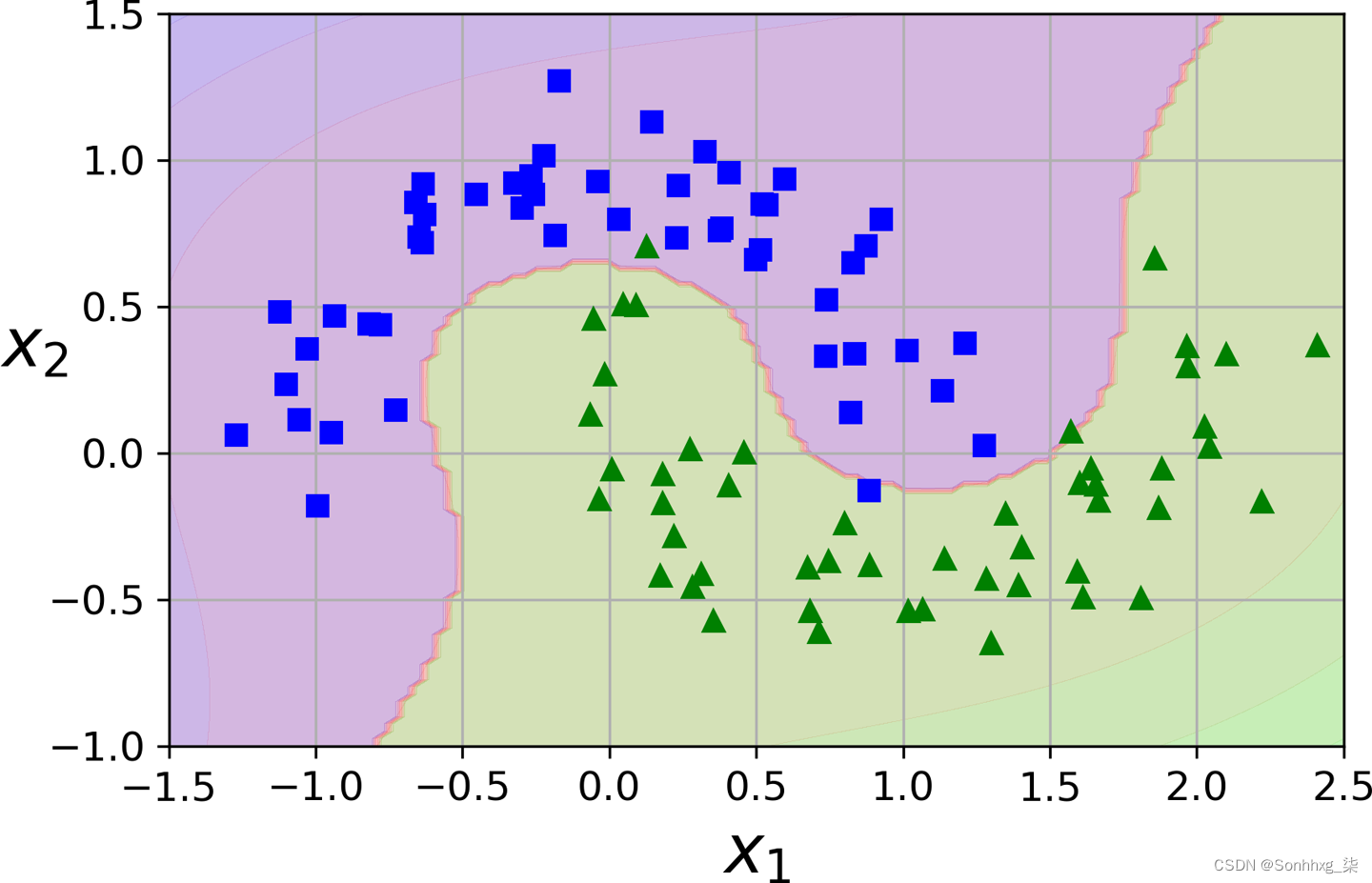 图 5-6。使用多项式特征的线性 SVM 分类器
图 5-6。使用多项式特征的线性 SVM 分类器
多项式核
添加多项式特征易于实现,并且可以很好地与各种机器学习算法(不仅仅是 SVM)配合使用。也就是说,在多项式度较低的情况下,该方法无法处理非常复杂的数据集,而在多项式度数较高的情况下,它会创建大量特征,从而使模型变得太慢。
幸运的是,当使用 SVM,您可以应用一种称为内核技巧的几乎神奇的数学技术(稍后会解释)。内核技巧可以得到与添加许多多项式特征相同的结果,即使是非常高次的多项式,也无需实际添加它们。所以没有特征数量的组合爆炸,因为你实际上并没有添加任何特征。这个技巧是由SVC类实现的。让我们在卫星数据集上对其进行测试:
from sklearn.svm import SVC
poly_kernel_svm_clf = Pipeline([
("scaler", StandardScaler()),
("svm_clf", SVC(kernel="poly", degree=3, coef0=1, C=5))
])
poly_kernel_svm_clf.fit(X, y)此代码使用三次多项式内核训练 SVM 分类器。它在图 5-7的左侧表示。右边是另一个使用 10 次多项式内核的 SVM 分类器。显然,如果您的模型过度拟合,您可能需要降低多项式次数。相反,如果它是欠拟合的,你可以尝试增加它。超参数coef0控制模型受高次多项式与低次多项式影响的程度。
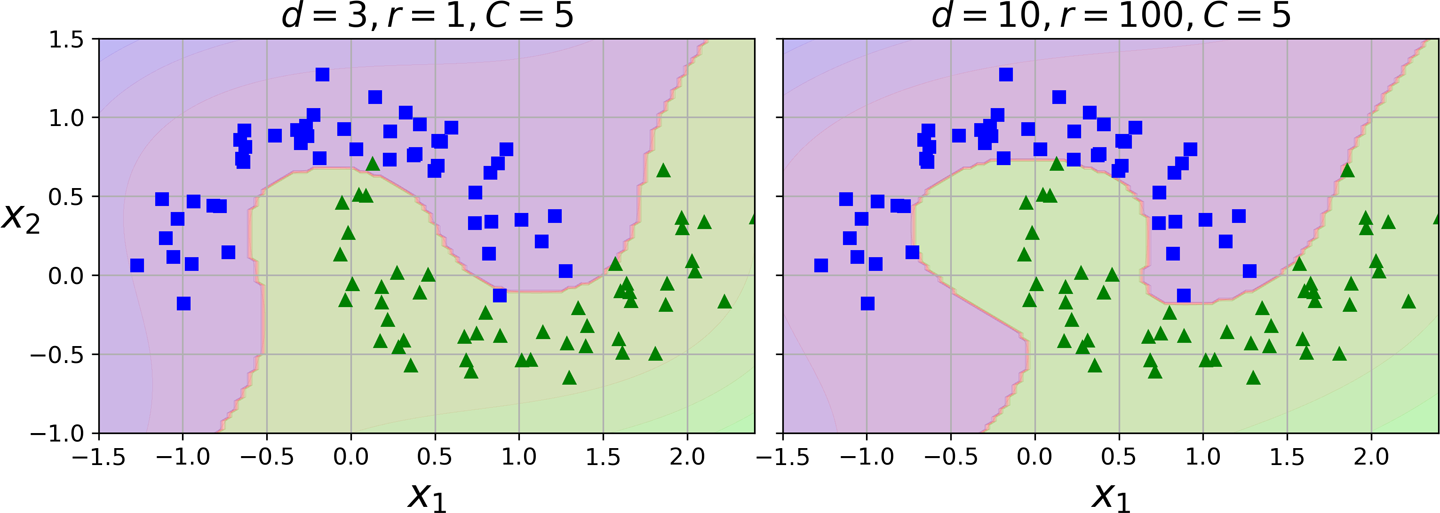
图 5-7。具有多项式内核的 SVM 分类器
小费
找到正确的超参数值的一种常用方法是使用网格搜索(参见第 2 章)。首先进行非常粗略的网格搜索,然后围绕找到的最佳值进行更精细的网格搜索,通常会更快。很好地了解每个超参数的实际作用也可以帮助您在超参数空间的正确部分进行搜索。
相似特征
另一种技术解决非线性问题的方法是添加使用相似函数计算的特征,该函数测量每个实例与特定地标的相似程度。例如,让我们使用前面讨论过的一维数据集,并在x 1 = –2 和x 1 = 1 处添加两个地标(参见图 5-8中的左图)。接下来,我们来定义相似度函数为γ = 0.3的高斯径向基函数(RBF) (参见公式 5-1)。
公式 5-1。高斯 RBF
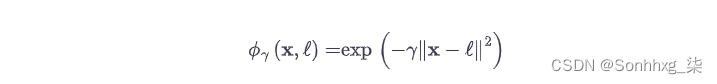
这是一个从 0(离地标很远)到 1(在地标处)变化的钟形函数。现在我们准备好计算新特征了。例如,让我们看一下实例x 1 = –1:它与第一个地标的距离为 1,与第二个地标的距离为 2。因此它的新特征是x 2 = exp(–0.3 × 1 2 ) ≈ 0.74 和x 3 = exp(–0.3 × 2 2 ) ≈ 0.30。图 5-8右侧的图显示了转换后的数据集(删除了原始特征)。如您所见,它现在是线性可分的。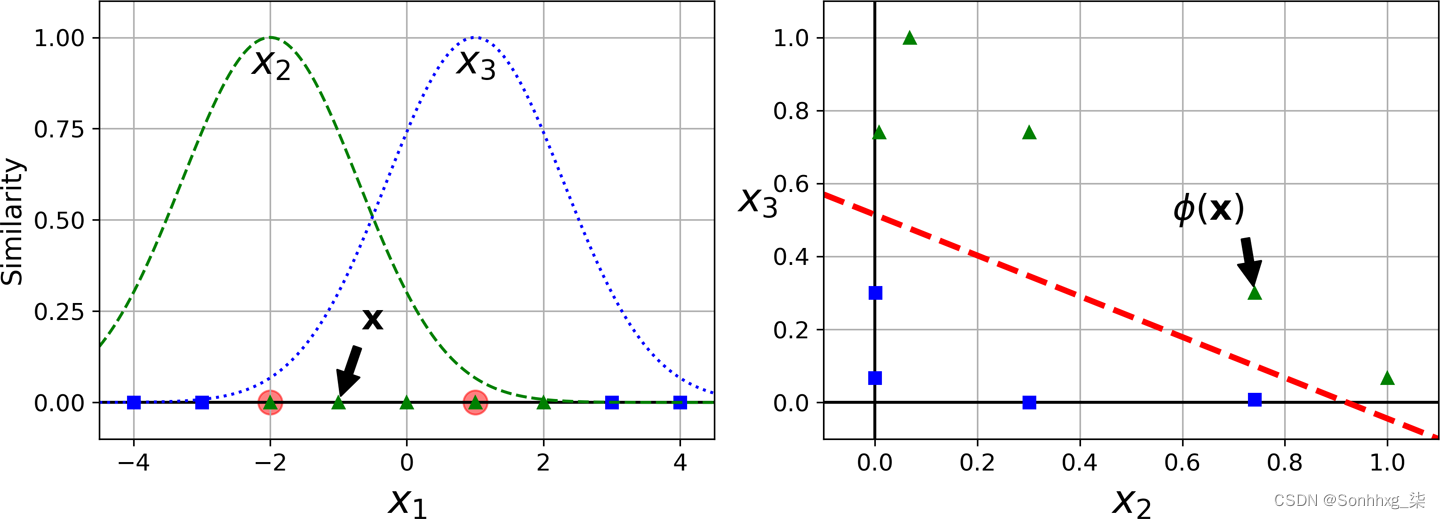
图 5-8。使用高斯 RBF 的相似性特征
您可能想知道如何选择地标。最简单的方法是在数据集中每个实例的位置创建一个地标。这样做会创建许多维度,从而增加转换后的训练集线性可分的机会。缺点是具有m个实例和n 个特征的训练集被转换为具有m个实例和m个特征的训练集(假设您删除了原始特征)。如果你的训练集非常大,你最终会得到同样多的特征。
高斯 RBF 内核
就像多项式特征方法一样,相似特征方法可用于任何机器学习算法,但计算所有附加特征可能在计算上很昂贵,尤其是在大型训练集上。内核技巧再次发挥了 SVM 的魔力,使得获得类似的结果成为可能,就好像您添加了许多相似特征一样。让我们尝试SVC使用高斯 RBF内核的类:
rbf_kernel_svm_clf = Pipeline([
("scaler", StandardScaler()),
("svm_clf", SVC(kernel="rbf", gamma=5, C=0.001))
])
rbf_kernel_svm_clf.fit(X, y)该模型在图 5-9的左下方表示。gamma其他图显示了使用不同超参数值( γ ) 和训练的模型C。增加gamma会使钟形曲线变窄(参见图 5-8中的左图)。结果,每个实例的影响范围更小:决策边界最终变得更加不规则,围绕单个实例摆动。相反,较小的gamma值会使钟形曲线更宽:实例的影响范围更大,决策边界更平滑。所以γ就像一个正则化超参数:如果你的模型过拟合,你应该减少它;如果它是欠拟合的,你应该增加它(类似于C超参数)。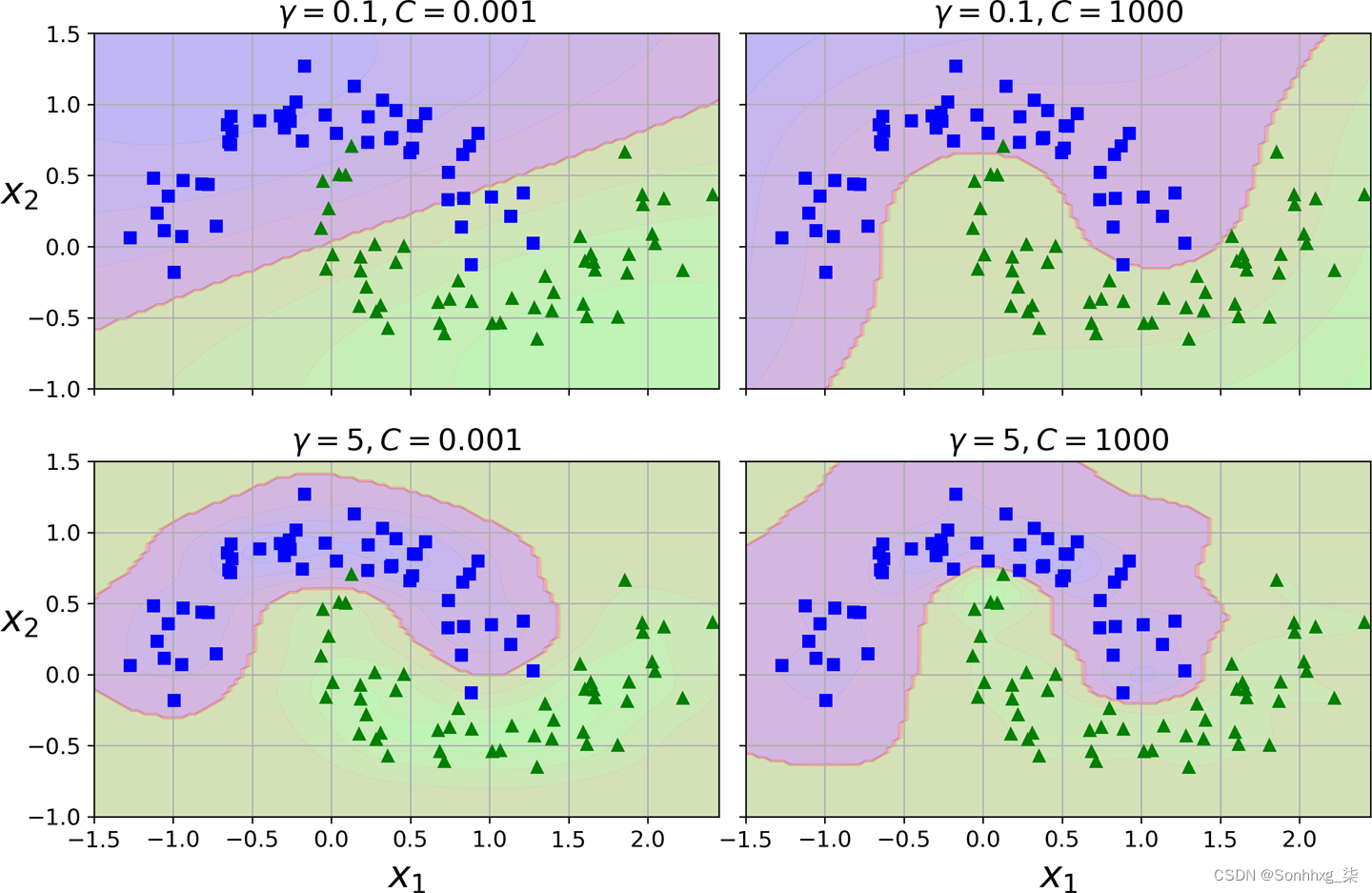
图 5-9。使用 RBF 内核的 SVM 分类器
其他内核存在但很少使用。一些内核专门用于特定的数据结构。有时在对文本文档或 DNA 序列进行分类时使用字符串内核(例如,使用字符串子序列内核或基于Levenshtein 距离的内核)。
小费
有这么多内核可供选择,您如何决定使用哪一个?根据经验,您应该始终首先尝试线性内核(记住它
LinearSVC比 快得多SVC(kernel="linear")),尤其是在训练集非常大或具有大量特征的情况下。如果训练集不是太大,也应该试试高斯RBF核;它在大多数情况下运行良好。然后,如果你有空闲时间和计算能力,你可以尝试其他几个内核,使用交叉验证和网格搜索。如果有专门针对您的训练集数据结构的内核,您会想要进行这样的实验。
计算复杂度
LinearSVC班级_基于该liblinear库,该库实现了线性 SVM 的优化算法。1它不支持核技巧,但它几乎与训练实例的数量和特征的数量呈线性关系。它的训练时间复杂度大约为O ( m × n )。
这如果您需要非常高的精度,算法需要更长的时间。这由容差超参数ϵ(tol在 Scikit-Learn 中调用)控制。在大多数分类任务中,默认容差很好。
SVC班级_基于libsvm库,它实现了支持内核技巧的算法。2训练时间复杂度通常在O ( m 2 × n ) 和O ( m 3 × n ) 之间。不幸的是,这意味着当训练实例的数量变大(例如,数十万个实例)时,它会变得非常慢。该算法非常适合复杂的中小型训练集。它随着特征的数量很好地扩展,尤其是稀疏特征(即,当每个实例具有很少的非零特征时)。在这种情况下,该算法大致与每个实例的非零特征的平均数量进行缩放。表 5-1比较了 Scikit-Learn 的 SVM 分类类别。
| 班级 | 时间复杂度 | 核外支持 | 需要缩放 | 内核技巧 |
|---|---|---|---|---|
|
| O(m × n) | 不 | 是的 | 不 |
|
| O(m × n) | 是的 | 是的 | 不 |
|
| O ( m ² × n ) to O ( m ³ × n ) | 不 | 是的 | 是的 |
支持向量机回归
作为前面提到,SVM 算法用途广泛:不仅支持线性和非线性分类,还支持线性和非线性回归。要使用 SVM 进行回归而不是分类,诀窍是颠倒目标:与其尝试拟合两个类别之间的最大可能街道同时限制边距违规,SVM 回归尝试在街道上拟合尽可能多的实例同时限制边距违规行为(即,街头事件)。街道的宽度由超参数ϵ控制。图 5-10显示了两个在一些随机线性数据上训练的线性 SVM 回归模型,一个具有较大的边距 ( ϵ= 1.5) 和另一个小边距 ( ϵ = 0.5)。
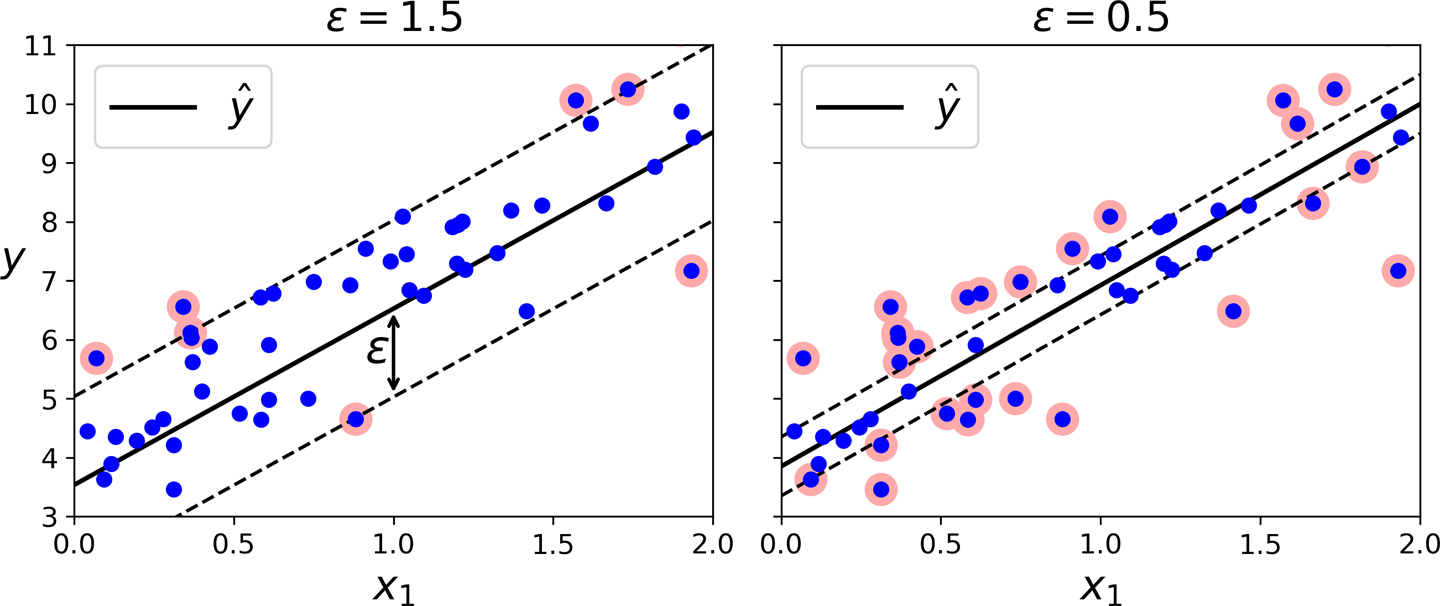
图 5-10。支持向量机回归
在边距内添加更多的训练实例不会影响模型的预测;因此,该模型被称为对ε 不敏感。
您可以使用 Scikit-Learn 的LinearSVR类来执行线性 SVM 回归。以下代码生成图 5-10左侧表示的模型(应首先对训练数据进行缩放和居中):
from sklearn.svm import LinearSVR
svm_reg = LinearSVR(epsilon=1.5)
svm_reg.fit(X, y)要处理非线性回归任务,您可以使用核化 SVM 模型。图 5-11显示了使用二次多项式核对随机二次训练集进行 SVM 回归。左图中的正则化很少(即,较大的C值),而右图中的正则化更多(即,较小的C值)。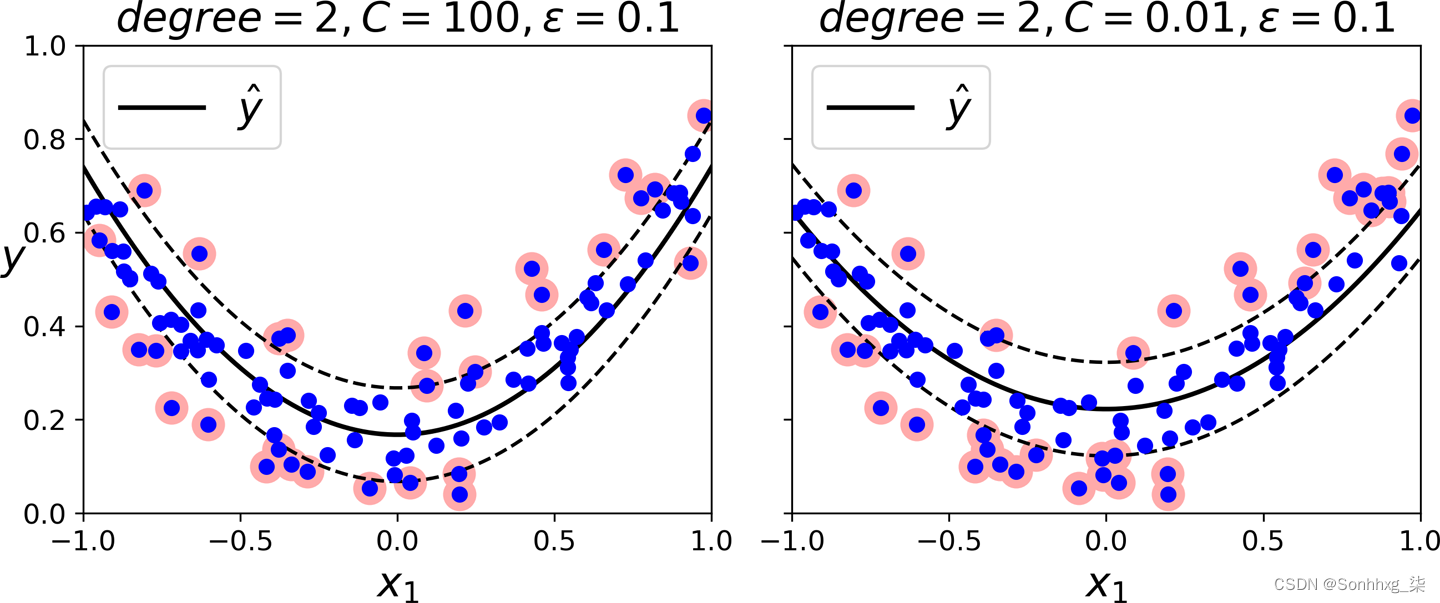
图 5-11。使用二次多项式内核的 SVM 回归
下面的代码使用 Scikit-Learn 的类(它支持内核技巧)来生成图 5-11SVR左侧所示的模型:
from sklearn.svm import SVR
svm_poly_reg = SVR(kernel="poly", degree=2, C=100, epsilon=0.1)
svm_poly_reg.fit(X, y)SVR类是类的回归等价物,类SVC是LinearSVR类的回归等价物LinearSVC。类随着训练集的LinearSVR大小线性扩展(就像LinearSVC类),而SVR当训练集变大时,类变得太慢(就像SVC类)。
笔记
SVM 也可用于异常值检测;有关更多详细信息,请参阅 Scikit-Learn 的文档。
引擎盖下
本节介绍 SVM 如何进行预测以及它们的训练算法如何工作,从线性 SVM 分类器开始。如果你刚开始学习机器学习,你可以安全地跳过它,直接进入本章末尾的练习,稍后当你想更深入地了解 SVM 时再回来。
首先,一句话关于符号。在第 4 章中,我们使用了将所有模型参数放在一个向量θ中的惯例,包括偏置项θ 0和输入特征权重θ 1到θ n,并向所有实例添加偏置输入x 0 = 1。在本章中,我们将使用在处理 SVM 时更方便(也更常见)的约定:偏置项将称为b,而特征权重向量将称为w。不会向输入特征向量添加偏差特征。
决策函数和预测
这线性 SVM 分类器模型通过简单地计算决策函数w ⊺ x + b = w 1 x 1 +⋯ + w n x n + b来预测新实例x的类别。如果结果为正,则预测类ŷ为正类(1),否则为负类(0);见公式 5-2。
公式 5-2。线性 SVM 分类器预测
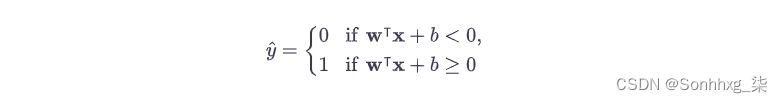
图 5-12显示了对应于图 5-4右侧模型的决策函数:它是一个 2D 平面,因为该数据集有两个特征(花瓣宽度和花瓣长度)。决策边界是决策函数等于0的点的集合:它是两个平面的交点,是一条直线(用粗实线表示)。3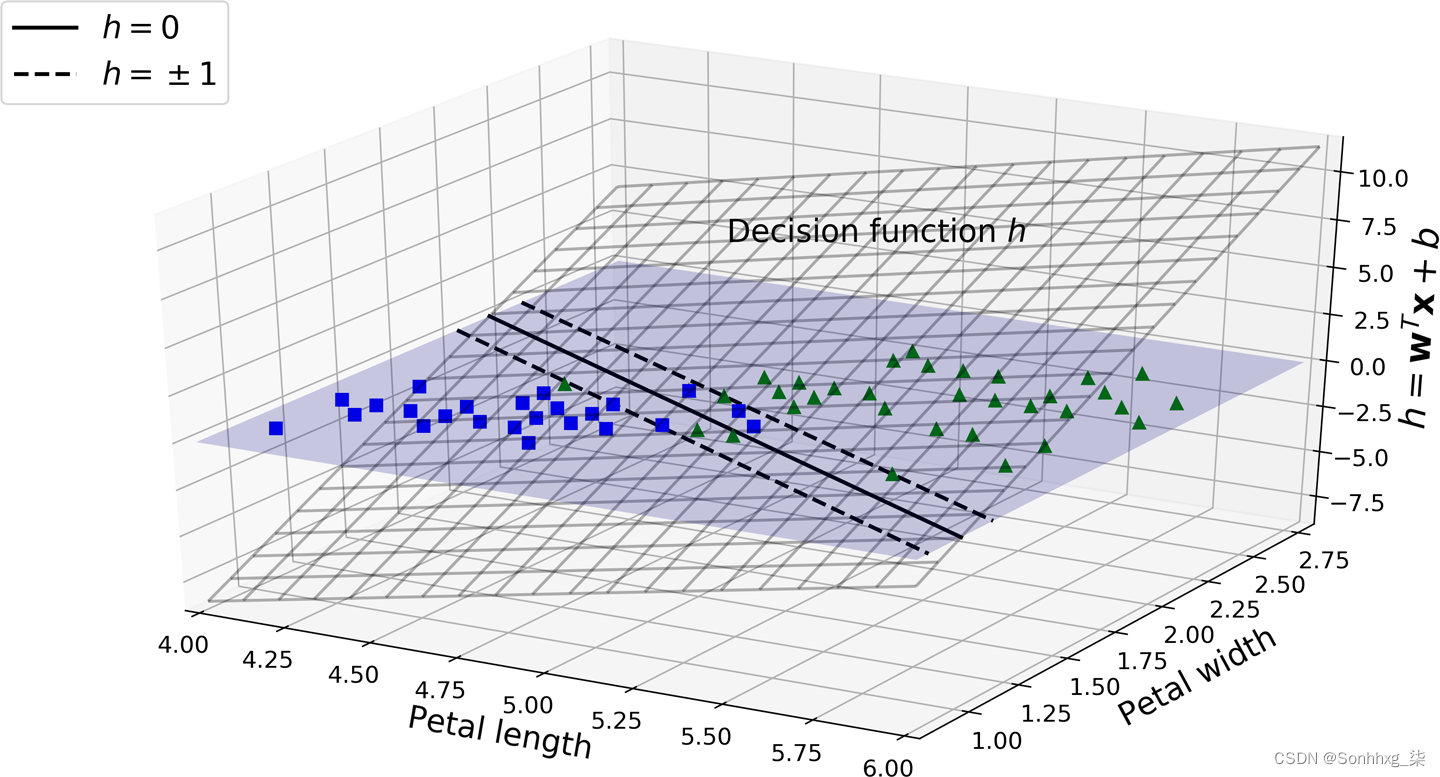
图 5-12。鸢尾花数据集的决策函数
虚线表示决策函数等于 1 或 –1 的点:它们与决策边界平行且距离相等,并且在决策边界周围形成一个边距。训练线性 SVM 分类器意味着找到w和b的值,使该边距尽可能宽,同时避免边距违规(硬边距)或限制它们(软边距)。
培训目标
考虑决策函数的斜率:它等于权向量的范数,∥ w ∥。如果我们将此斜率除以 2,则决策函数等于 ±1 的点距离决策边界的距离将是两倍。换句话说,将斜率除以 2 将使边距乘以 2。这在 2D 中可能更容易可视化,如图 5-13所示。权重向量w越小,边距越大。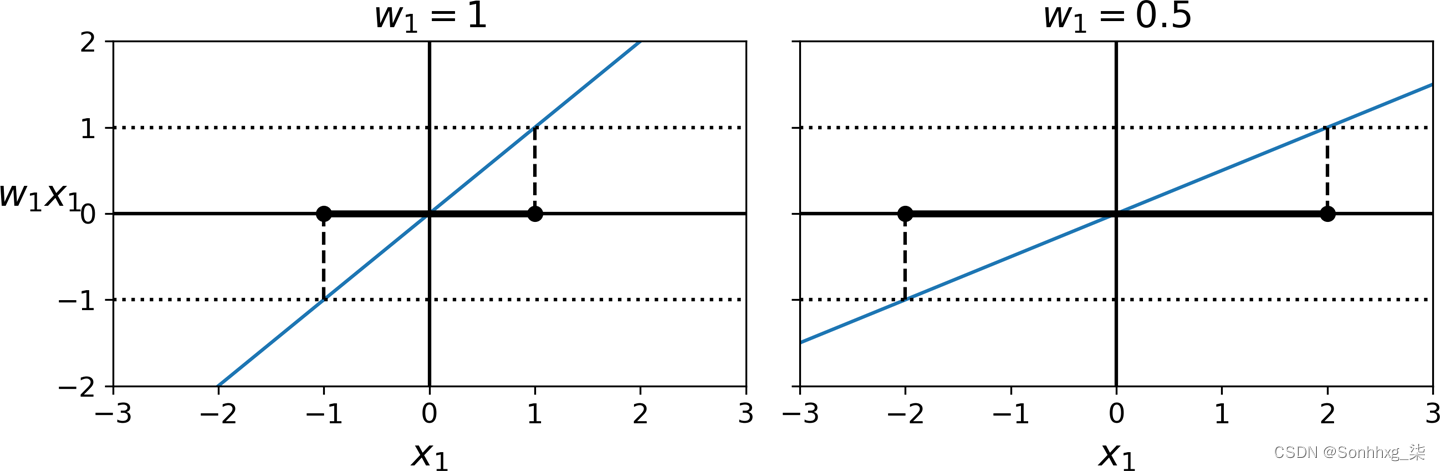
图 5-13。较小的权重向量导致较大的边距
所以我们要最小化 ∥ w ∥ 以获得较大的余量。如果我们还想避免任何边距违规(硬边距),那么我们需要决策函数对于所有正训练实例大于 1,对于负训练实例小于 –1。如果我们为负实例定义t ( i ) = –1(如果y ( i ) = 0),为正实例定义t ( i ) = 1(if y(i) = 0),那么我们可以将此约束表示为t(i)(w⊺ x(i) + b)对于所有实例。
我们因此可以将硬边距线性 SVM 分类器目标表示为方程 5-3中的约束优化问题。
公式 5-3。硬边距线性 SVM 分类器目标
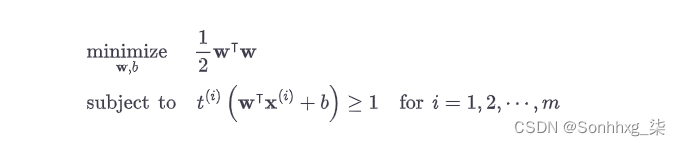
笔记
我们正在最小化 ½ w ⊺ w,它等于 ½∥ w ∥ 2,而不是最小化 ∥ w ∥。实际上,½∥ w ∥ 2有一个很好的简单导数(它只是w),而 ∥ w ∥ 在w = 0时不可微。优化算法在可微函数上工作得更好。
为了获得软边距目标,我们需要为每个实例引入一个松弛变量 ζ ( i ) ≥ 0: 4 ζ ( i )测量允许第i个实例违反边距的程度。我们现在有两个相互冲突的目标:使松弛变量尽可能小以减少边际违规,并使 ½ w ⊺ w尽可能小以增加边际。这就是C超参数的用武之地:它允许我们定义这两个目标之间的权衡。这给了我们方程 5-4中的约束优化问题。
公式 5-4。软边距线性 SVM 分类器目标
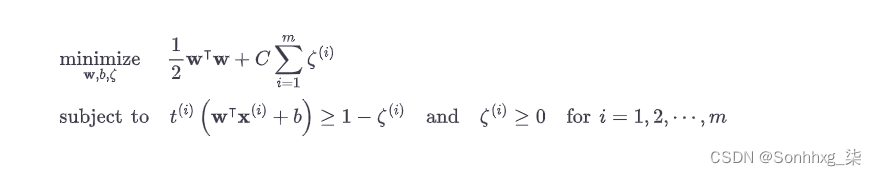
二次规划
硬边距和软边距问题都是具有线性约束的凸二次优化问题。这样的问题被称为二次规划(QP)问题。许多现成的求解器可以通过使用本书范围之外的各种技术来解决 QP 问题。5
一般问题公式由公式 5-5给出。
公式 5-5。二次规划问题

您可以很容易地验证,如果您按以下方式设置 QP 参数,您将获得硬边距线性 SVM 分类器目标:
-
n p = n + 1,其中n是特征的数量(+1 表示偏差项)。
-
n c = m,其中m是训练实例的数量。
-
H是n p × n p单位矩阵,除了左上角单元格中的零(忽略偏置项)。
-
f = 0,一个n p维向量,全为 0。
-
b = –1,一个充满 –1 的n c维向量。
-
a(i) = –t(i) x˙(i), 其中X˙( i )等于x ( i )具有额外的偏差特征X˙0 = 1.
训练硬边距线性 SVM 分类器的一种方法是使用现成的 QP 求解器并将前面的参数传递给它。结果向量p将包含偏置项b = p 0和特征权重w i = p i对于i = 1, 2,⋯, n。同样,您可以使用 QP 求解器来解决软边距问题(参见本章末尾的练习)。
为了使用核技巧,我们将研究一个不同的约束优化问题。
双重问题
给定一个有约束的优化问题,称为原始问题,可以表达一个不同但密切相关的问题,称为它的对偶问题。对偶问题的解决方案通常会给出原始问题的解决方案的下界,但在某些情况下,它可以具有与原始问题相同的解决方案。幸运的是,SVM 问题恰好满足这些条件,6所以你可以选择解决原始问题或对偶问题;两者都有相同的解决方案。公式 5-6显示了线性 SVM 目标的对偶形式(如果您有兴趣了解如何从原始问题导出对偶问题,请参阅附录 C)。
公式 5-6。线性 SVM 目标的对偶形式
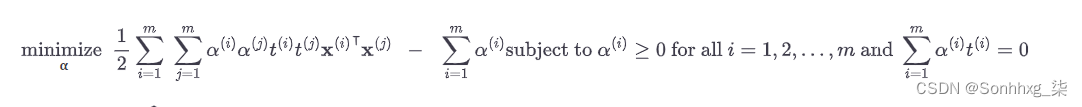
一旦找到向量 𝛂一个^最小化这个方程(使用 QP 求解器),使用方程 5-7计算在^和b^最小化原始问题。
公式 5-7。从对偶解到原解
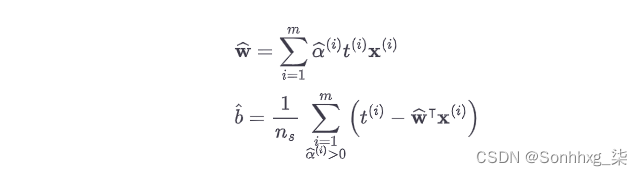
其中n s是支持向量的数量。
当训练实例的数量小于特征的数量时,对偶问题比原始问题更快解决。更重要的是,对偶问题使内核技巧成为可能,而原始问题则不然。那么这个内核技巧到底是什么?
内核化 SVM
认为您想对二维训练集(例如卫星训练集)应用二次多项式变换,然后在变换后的训练集上训练线性 SVM 分类器。公式 5-8显示了您要应用的二次多项式映射函数φ 。
公式 5-8。二阶多项式映射
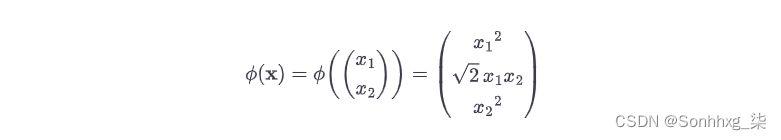
请注意,转换后的向量是 3D 而不是 2D。现在让我们看看如果我们应用这个二阶多项式映射,然后计算变换后的向量的点积7 ,那么两个二维向量a和b会发生什么(参见公式 5-9)。
公式 5-9。二次多项式映射的内核技巧
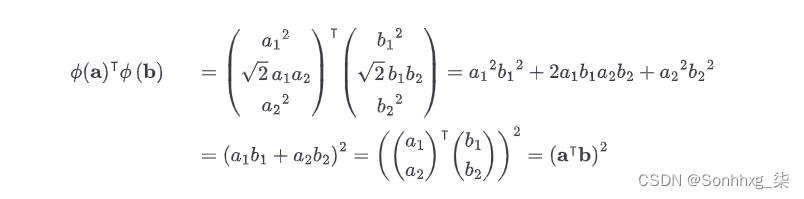
那个怎么样?变换向量的点积等于原始向量点积的平方:φ ( a ) ⊺ φ ( b ) = ( a ⊺ b ) 2。
以下是关键见解:如果您将变换φ应用于所有训练实例,那么对偶问题(参见公式 5-6)将包含点积φ ( x ( i ) ) ⊺ φ ( x ( j ) )。但是如果φ是公式 5-8中定义的二次多项式变换,那么您可以简单地替换这个变换向量的点积为(X(一世)⊺X(j))2. 因此,您根本不需要转换训练实例;只需用公式 5-6中的平方替换点积即可。结果将与您经历了转换训练集然后拟合线性 SVM 算法的麻烦完全相同,但是这个技巧使整个过程的计算效率更高。
函数K ( a , b ) = ( a ⊺ b ) 2是 a二阶多项式核。在机器学习中,内核是一个能够仅基于原始向量a和b计算点积φ ( a ) ⊺ φ ( b ) 的函数,而无需计算(甚至知道)变换φ。公式 5-10列出了一些最常用的内核。
公式 5-10。常用内核
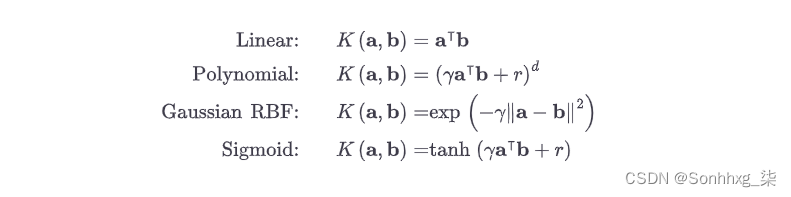
默瑟定理
根据根据Mercer 定理,如果函数K ( a , b ) 遵守一些称为Mercer 条件的数学条件(例如,K在其参数中必须是连续且对称的,因此K ( a , b ) = K ( b , a ) 等.),那么存在一个将a和b映射到另一个空间(可能具有更高维度)的函数φ ,使得K ( a , b ) = φ ( a) ⊺ φ ( b )。您可以使用K作为内核,因为您知道ϕ存在,即使您不知道ϕ是什么。在高斯 RBF 内核的情况下,可以证明φ将每个训练实例映射到无限维空间,因此您不需要实际执行映射是一件好事!
还有一个松散的结局我们必须解决。公式 5-7显示了在线性 SVM 分类器的情况下如何从对偶解到原始解。但是如果你应用核技巧,你最终会得到包含φ ( x ( i ) ) 的方程。实际上,在^必须具有与φ ( x ( i ) )相同的维数,这可能是巨大的甚至是无限的,因此您无法计算它。但是你怎么能在不知道的情况下做出预测在^? 好消息是你可以插入公式在^从公式 5-7到新实例x ( n )的决策函数中,您会得到一个输入向量之间只有点积的等式。这使得使用内核技巧(公式 5-11)成为可能。
公式 5-11。使用核化 SVM 进行预测
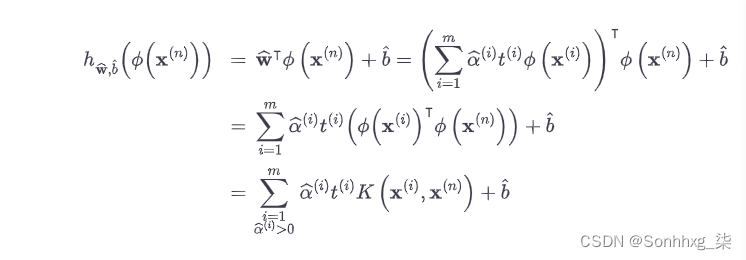
请注意,由于α ( i ) ≠ 0 仅适用于支持向量,因此进行预测涉及计算新输入向量x ( n )与仅支持向量的点积,而不是所有训练实例。当然,您需要使用相同的技巧来计算偏差项b^(公式 5-12)。
公式 5-12。使用核技巧计算偏置项
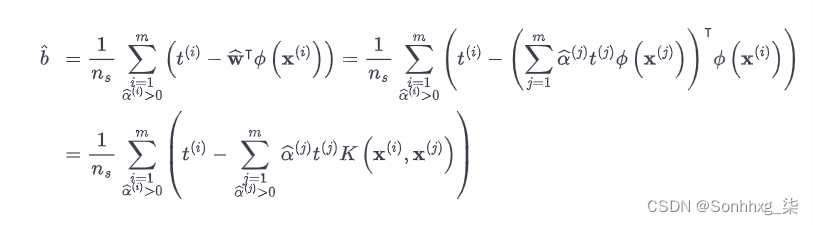
如果您开始头疼,那是完全正常的:这是内核技巧的一个不幸的副作用。
在线支持向量机
前结束本章,让我们快速了解一下在线 SVM 分类器(回想一下,在线学习意味着增量学习,通常是随着新实例的到来)。
对于线性 SVM 分类器,实现在线 SVM 分类器的一种方法是使用梯度下降(例如,使用)来最小化方程 5-13SGDClassifier中的成本函数,该方程源自原始问题。不幸的是,梯度下降的收敛速度比基于 QP 的方法慢得多。
公式 5-13。线性 SVM 分类器成本函数
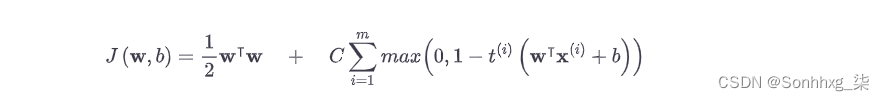
成本函数中的第一个总和将推动模型具有较小的权重向量w,从而导致较大的边际。第二个总和计算所有保证金违规的总数。如果实例位于街道外且在正确的一侧,则实例的边距违规等于 0,否则它与到街道正确一侧的距离成正比。最小化该项可确保模型使边缘违规尽可能小和尽可能少。
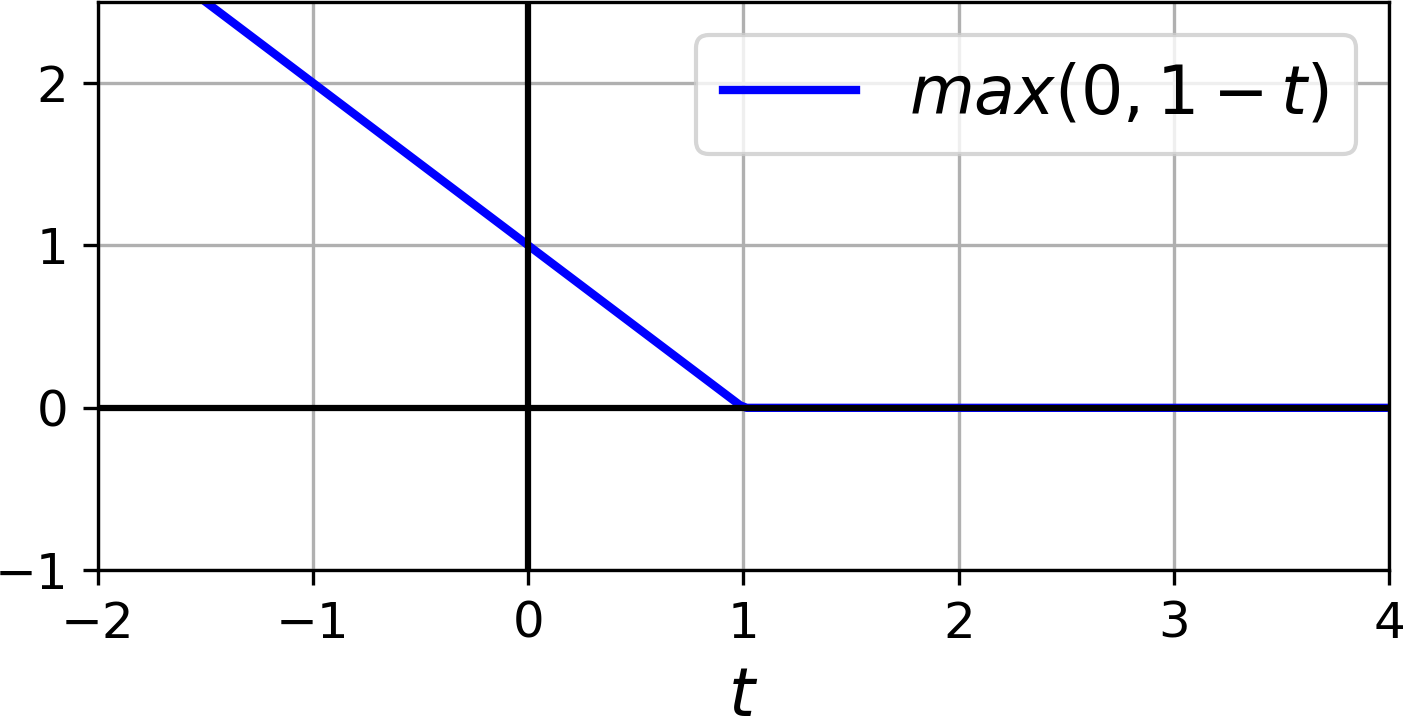
铰链损失
这函数max (0, 1 – t ) 称为铰链损失函数(见下图)。当t ≥ 1 时它等于 0。如果t < 1,它的导数(斜率)等于 –1 ,如果t > 1,它等于0。它在t = 1 时不可微,但就像 Lasso 回归一样(参见“Lasso回归”),您仍然可以使用梯度下降t = 1处的任何微分(即,–1 和 0 之间的任何值)。
还可以实现在线核化 SVM,如论文“增量和减量支持向量机器学习” 8和“具有在线和主动学习的快速核分类器”中所述。9这些内核化 SVM 是在 Matlab 和 C++ 中实现的。对于大规模非线性问题,您可能需要考虑改用神经网络(参见第二部分)。
练习
-
支持向量机背后的基本思想是什么?
-
什么是支持向量?
-
为什么在使用 SVM 时缩放输入很重要?
-
SVM 分类器在对实例进行分类时可以输出置信度分数吗?概率呢?
-
您应该使用 SVM 问题的原始形式还是对偶形式来在具有数百万个实例和数百个特征的训练集上训练模型?
-
假设您使用 RBF 内核训练了 SVM 分类器,但它似乎不适合训练集。你应该增加还是减少γ (
gamma)?怎么样C? -
您应该如何设置 QP 参数(H、f、A和b)以使用现成的 QP 求解器解决软边距线性 SVM 分类器问题?
-
LinearSVC在线性可分数据集上训练 a 。然后在同一个数据集上训练一个SVC和一个。SGDClassifier看看你能不能让他们生产出大致相同的模型。 -
在 MNIST 数据集上训练 SVM 分类器。由于 SVM 分类器是二元分类器,因此您需要使用 one-versus-the-rest 对所有 10 个数字进行分类。您可能希望使用小型验证集来调整超参数以加快该过程。你能达到什么精度?
-
在加利福尼亚住房数据集上训练 SVM 回归器。

















 403
403











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











