










🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
目录
如果您曾经看过任何未来派科幻电影,那么您很可能会看到人类与机器人交谈。基于机器的智能一直是小说作品中的一个长期特征。然而,由于 NLP 和深度学习的最新进展,与计算机的对话不再是幻想。虽然我们可能距离真正的智能还有很多年,计算机能够以与人类相同的方式理解语言的含义,但机器至少能够进行基本的对话并给出关于智能的初步印象。
在上一章中,我们研究了如何构建序列到序列模型来将句子从一种语言翻译成另一种语言。能够进行基本交互的会话聊天机器人的工作方式大致相同。当我们与聊天机器人交谈时,我们的句子成为模型的输入。输出是聊天机器人选择回复的任何内容。因此,我们不是训练我们的聊天机器人来学习如何解释我们的输入句子,而是教它如何回应。
我们将扩展上一章中的序列到序列模型,在我们的模型中添加一些称为注意力的东西。这种对序列到序列模型的改进意味着我们的模型学习输入句子中的哪个位置来获取所需的信息,而不是使用整个输入句子决策。这种改进使我们能够创建具有最先进性能的更高效的序列到序列模型。
在本章中,我们将研究以下主题:
- 神经网络中的注意力理论
- 在神经网络中实现注意力以构建聊天机器人
神经网络中的注意力理论
在上一章中,在我们用于句子翻译的序列到序列模型中(没有实现注意力),我们同时使用了编码器和解码器。编码器得到一个输入句子的隐藏状态,这是我们句子的表示。然后解码器使用这个隐藏状态来执行翻译步骤。一个基本的图形说明如下: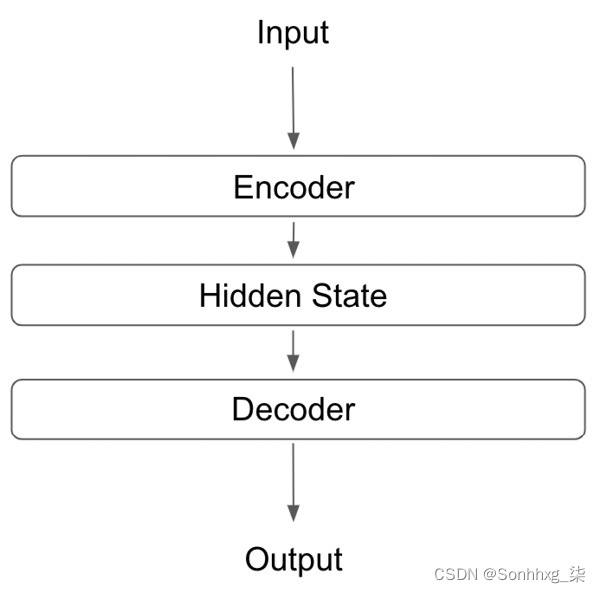
图 8.1 – 序列到序列模型的图形表示
然而,对整个隐藏状态进行解码不一定是使用此任务的最有效方式。这是因为隐藏状态代表了整个输入句子;但是,在某些任务中(例如预测句子中的下一个单词),我们不需要考虑输入句子的整体,只需要考虑与我们试图做出的预测相关的部分。我们可以通过在我们的序列到序列神经网络中使用注意力来证明这一点。我们可以教我们的模型只查看输入的相关部分以进行预测,从而产生更有效和更准确的模型。
考虑以下示例:
我将于 3 月 2 日前往法国首都巴黎。我的航班从伦敦希思罗机场起飞,大约需要一小时。
假设我们正在训练一个模型来预测句子中的下一个单词。我们可以先输入句子的开头:
法国的首都是____。
在这种情况下,我们希望我们的模型能够检索单词Paris 。如果我们要使用基本的序列到序列模型,我们会将整个输入转换为一个隐藏状态,然后我们的模型将尝试从中提取相关信息。这包括有关航班的所有无关信息。您可能会注意到,我们只需要查看输入句子的一小部分,即可识别完成句子所需的相关信息:
我将于3 月 2 日前往法国首都巴黎。我的航班从伦敦希思罗机场起飞,大约需要一小时。
因此,如果我们可以训练我们的模型只使用输入句子中的相关信息,我们就可以做出更准确和相关的预测。我们可以在我们的网络中实施注意力以实现这一目标。
我们可以实现两种主要类型的注意力机制:局部注意力和全局注意力。
比较本地和全球关注度
这两种形式的注意力,我们可以在我们的网络中实施的是非常相似,但有细微的关键差异。我们将从查看本地注意力开始。
在局部注意力中,我们的模型只查看来自编码器的几个隐藏状态。例如,如果我们正在执行一个句子翻译任务并且我们是计算我们翻译中的第二个词,模型可能希望只查看与编码器相关的隐藏状态输入句子中的第二个单词。这意味着我们的模型需要从我们的编码器 ( h2 )中查看第二个隐藏状态,但也可以查看它之前的隐藏状态 ( h1 )。
在下图中,我们可以在实践中看到这一点:
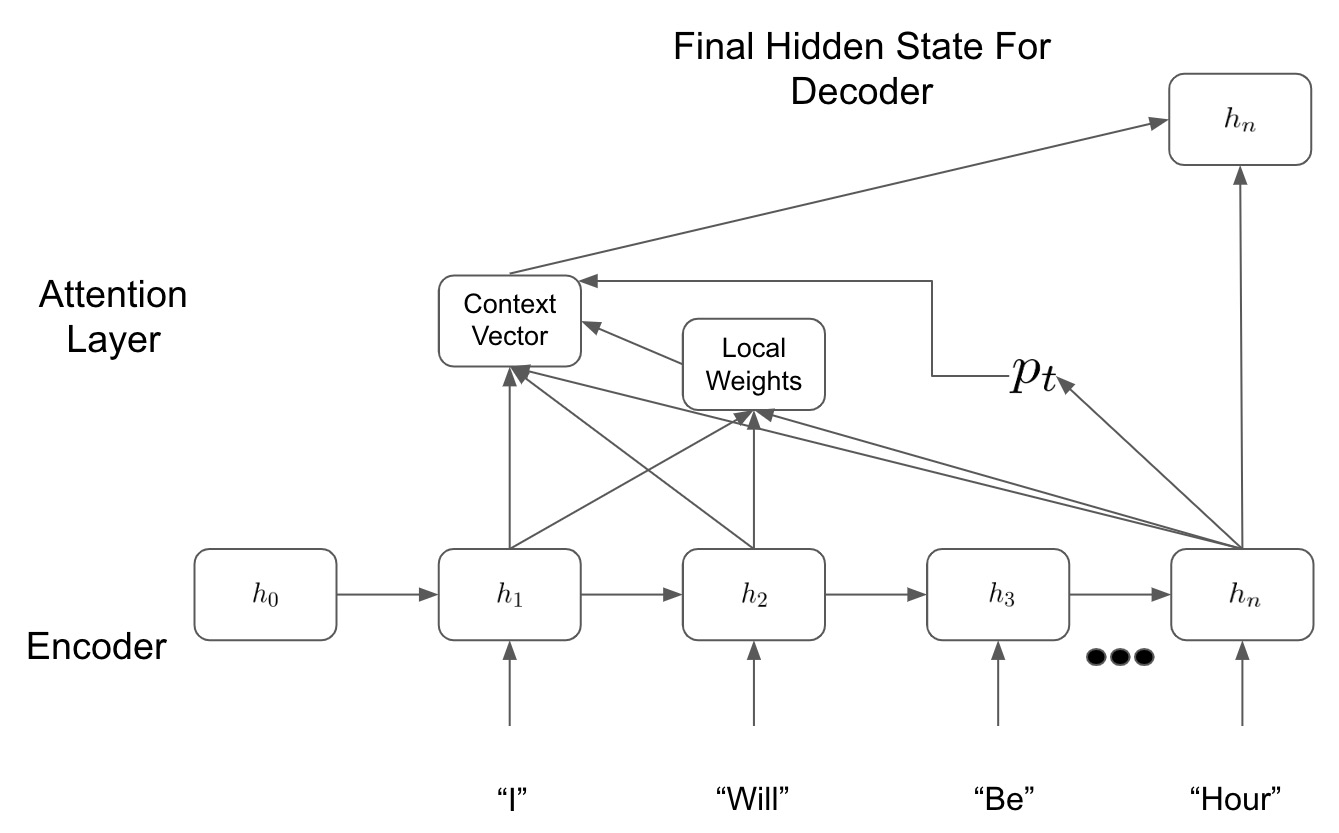
图 8.2 – 局部注意力模型
我们首先从最终隐藏状态h n计算对齐位置p t。这告诉我们需要查看哪些隐藏状态才能做出预测。然后我们计算我们的本地权重并将它们应用于我们的隐藏状态以确定我们的上下文向量。这些权重可能会告诉我们要多注意最相关的隐藏状态 ( h 2 ),但较少关注前面的隐藏状态 ( h 1 )。
然后我们获取上下文向量并将其传递给我们的解码器以进行预测。在我们的基于非注意力的序列到序列模型中,我们只会向前传递最终的隐藏状态h n,但我们在这里看到,相反,我们只考虑我们的模型认为必要的相关隐藏状态以使其预言。
全局注意力模型有效以非常相似的方式。然而,我们想要查看模型的所有隐藏状态,而不是只查看几个隐藏状态——因此得名全局。我们可以在这里看到全局注意力层的图形说明: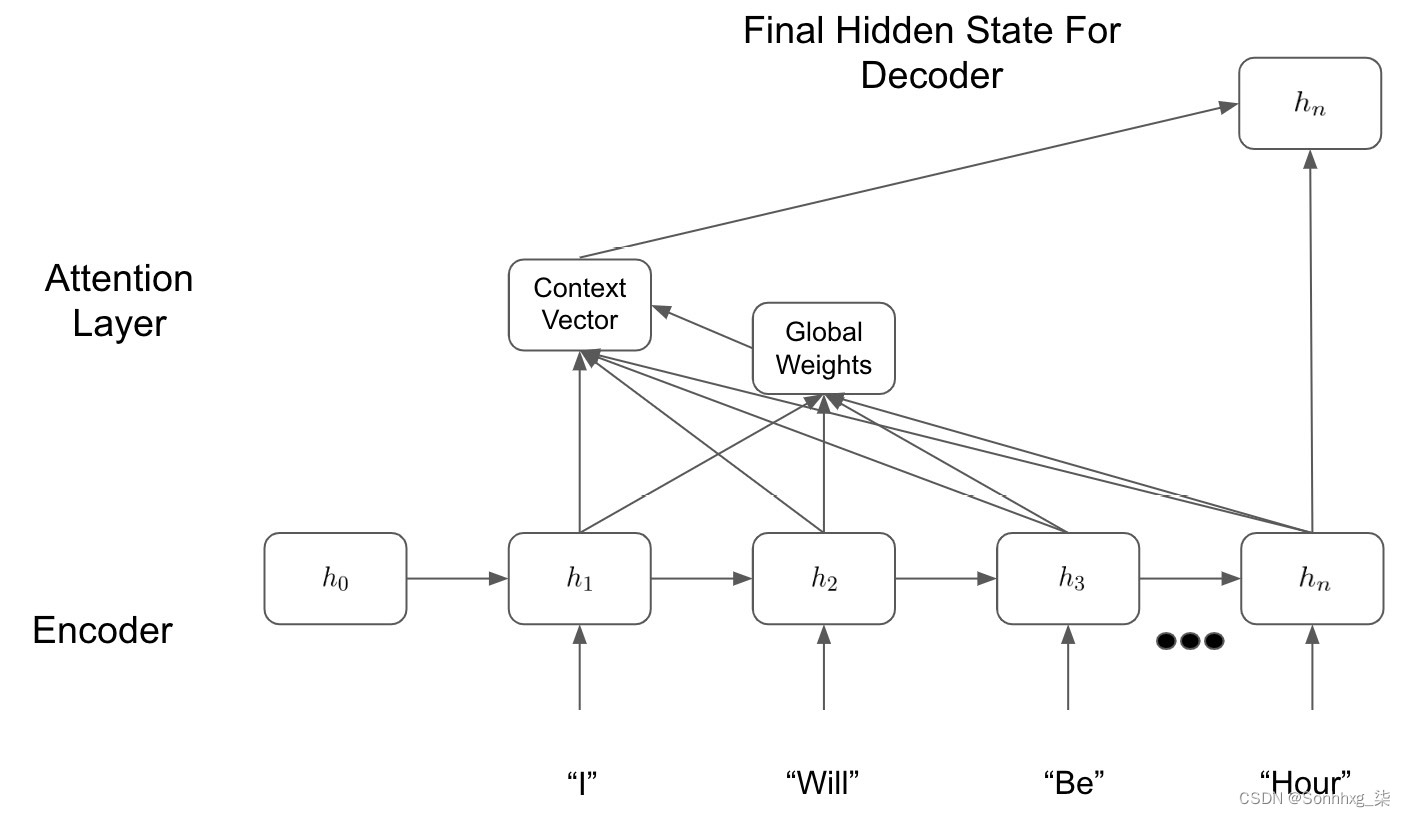
图 8.3 – 全局注意力模型
我们在上图中可以看到,虽然这看起来与我们的局部注意力非常相似在框架中,我们的模型现在正在查看所有隐藏状态并计算所有隐藏状态的全局权重。这允许我们的模型可以查看它认为相关的输入句子的任何给定部分,而不是局限于由局部注意力方法确定的局部区域。我们的模型可能希望只查看一个小的局部区域,但这在模型的能力范围内。考虑全局注意力框架的一种简单方法是,它本质上是在学习一个仅允许通过与我们的预测相关的隐藏状态的掩码:
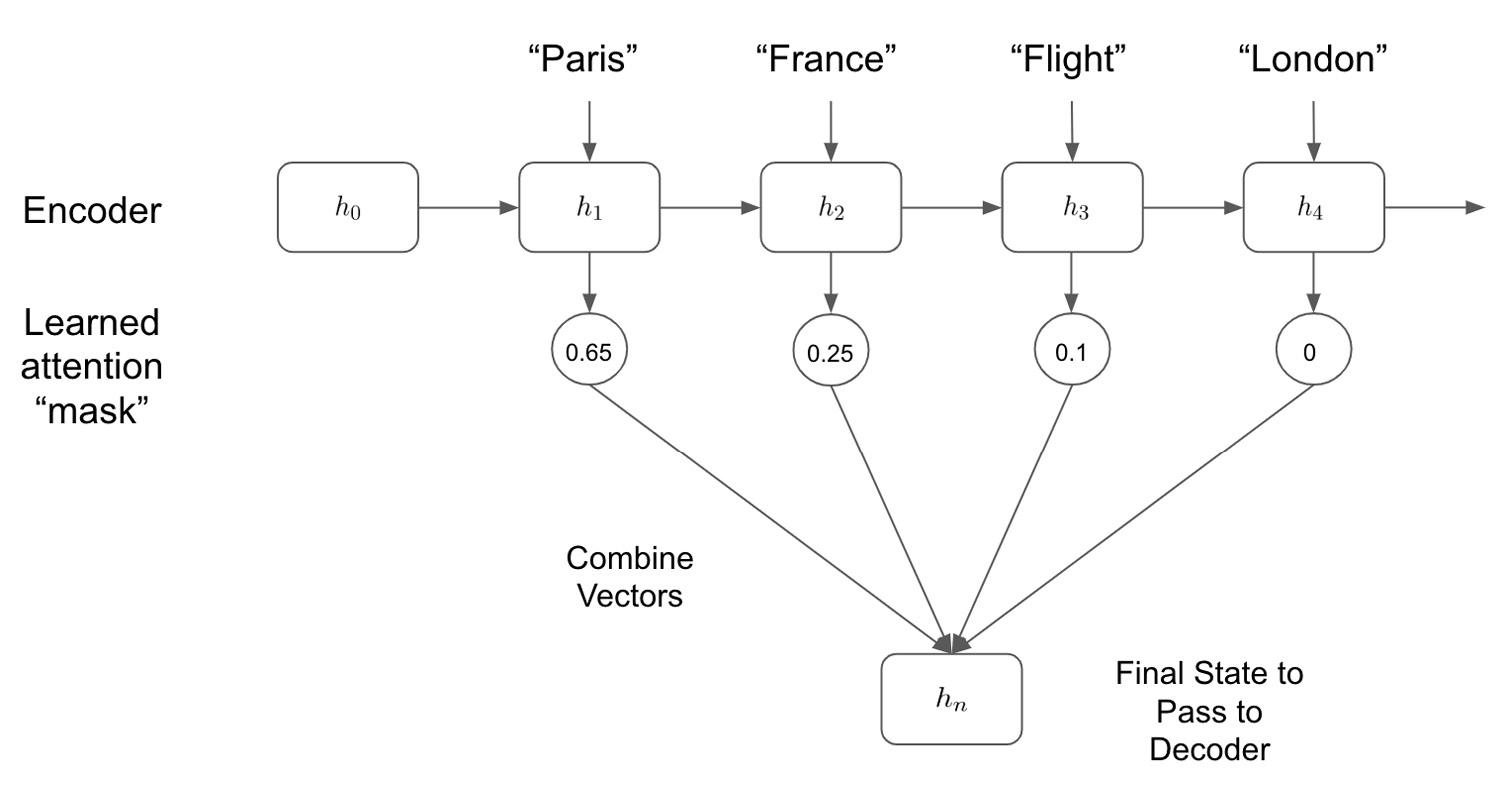
图 8.4 – 组合模型
我们在上图中可以看到,通过学习要注意哪些隐藏状态,我们的模型控制哪些状态用于解码步骤以确定我们的预测输出。一旦我们决定要关注哪些隐藏状态,我们就可以使用多种不同的方法将它们组合起来——通过连接或采用加权点积。
使用带注意力的序列到序列神经网络构建聊天机器人
这最简单的方法来准确说明如何在我们的神经网络中实现注意力网络是通过一个例子来工作的。现在,我们将完成使用应用了注意力框架的序列到序列模型从头开始构建聊天机器人所需的步骤。
与我们所有的其他 NLP 模型,我们的第一步是获取和处理数据集用来训练我们的模型。
获取我们的数据集
为了训练我们的聊天机器人,我们需要一个对话数据集,我们的模型可以通过该数据集学习如何响应。我们的聊天机器人将接受人类输入的一行,并用生成的句子对其进行响应。因此,一个理想的数据集将由多行以适当的反应进行对话。像这样的任务的完美数据集将是来自两个人类用户之间对话的实际聊天日志。不幸的是,这些数据包含私人信息,在公共领域很难获得,因此对于这项任务,我们将使用电影剧本数据集。
电影剧本由两个或多个角色之间的对话组成。虽然这些数据自然不是我们希望的格式,但我们可以轻松地将其转换为我们需要的格式。以两个角色之间的简单对话为例:
- Line 1: Hello Bethan.
- Line 2: Hello Tom, how are you?
- Line 3: I'm great thanks, what are you doing this evening?
- Line 4: I haven't got anything planned.
- Line 5: Would you like to come to dinner with me?
现在,我们需要将其转换为调用和响应的输入和输出对,其中输入是脚本中的一行(调用),预期输出是脚本的下一行(响应)。我们可以将n行的脚本转换为n-1对输入/输出:
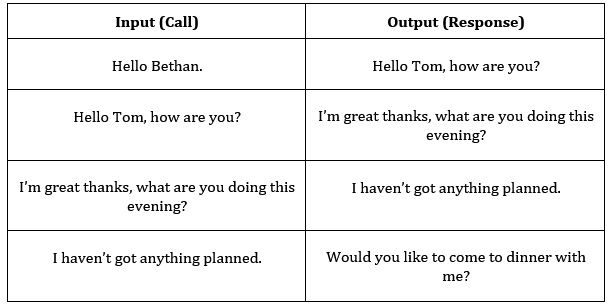
图 8.5 – 输入和输出表
我们可以使用这些输入/输出对来训练我们的网络,其中输入是人工输入的代理,输出是我们期望从模型中得到的响应。
构建模型的第一步是读取这些数据并执行所有必要的预处理步骤。
处理我们的数据集
幸运的是,为此示例提供的数据集已经被格式化,因此每一行表示单个输入/输出对。我们可以先读取数据并检查一些行:
语料库 =“电影语料库”
corpus = "movie_corpus"
corpus_name = "movie_corpus"
datafile = os.path.join(corpus, "formatted_movie_lines.txt")
with open(datafile, 'rb') as file:
lines = file.readlines()
for line in lines[:3]:
print(str(line) + '\n')这将打印以下结果:
图 8.6 – 检查数据集
您首先会注意到我们的行与预期的一样,因为第一行的后半部分变成了下一行的前半部分。我们还可以注意到,每行的调用和响应部分由制表符分隔符 ( /t ) 分隔,并且我们的每一行都由新的行分隔符 ( /n ) 分隔。当我们处理我们的数据集时,我们将不得不考虑这一点。
第一步是创建一个词汇表或语料库,其中包含我们数据集中所有独特的单词。
创建词汇
过去,我们的语料库由几个词典组成,其中包含我们的语料库和单词和索引之间的查找。但是,我们可以通过创建一个包含所有必需元素的词汇类以更优雅的方式做到这一点:
- 我们首先创建我们的词汇类。我们用空字典初始化这个类—— word2index和word2count。我们还初始化index2word字典为我们的填充标记以及我们的句子开始( SOS ) 和句子结尾( EOS ) 标记提供占位符。我们保持对我们词汇表中单词数量的运行计数(从 3 开始,因为我们的语料库已经包含提到的三个标记)。这些是空词汇表的默认值;但是,当我们读取数据时,它们将被填充:
PAD_token = 0 SOS_token = 1 EOS_token = 2 class Vocabulary: def __init__(self, name): self.name = name self.trimmed = False self.word2index = {} self.word2count = {} self.index2word = {PAD_token: "PAD", SOS_token:"SOS", EOS_token: "EOS"} self.num_words = 3 - 接下来,我们创建将用于填充词汇表的函数。addWord将一个单词作为输入。如果这是一个尚未出现在我们的词汇表中的新词,我们添加这个词添加到我们的索引中,将这个词的计数设置为 1,并将我们词汇表中的单词总数加 1。如果有问题的词已经在我们的词汇表中,我们只需将这个词的计数加 1:
def addWord(self, w): if w not in self.word2index: self.word2index[w] = self.num_words self.word2count[w] = 1 self.index2word[self.num_words] = w self.num_words += 1 else: self.word2count[w] += 1 - 我们还使用addSentence函数将addWord函数应用于给定句子中的所有单词:
def addSentence(self, sent): for word in sent.split(' '): self.addWord(word)为了加快模型的训练,我们可以做的一件事是减少词汇量。这意味着任何嵌入层都将小得多,并且我们模型中学习参数的总数可以更少。一个简单的方法来做到这一点是从我们的词汇表中删除任何低频词。在我们的数据集中只出现一次或两次的任何单词都不太可能具有巨大的预测能力,因此将它们从我们的语料库中删除并在我们的最终模型中用空白标记替换它们可以减少我们的模型训练和减少过度拟合所需的时间,而无需对我们模型的预测产生很大的负面影响。
- 为了从我们的词汇表中删除低频词,我们可以实现一个修剪功能。该函数首先遍历单词计数字典,如果单词的出现大于所需的最小计数,则将其附加到新列表中:
def trim(self, min_cnt): if self.trimmed: return self.trimmed = True words_to_keep = [] for k, v in self.word2count.items(): if v >= min_cnt: words_to_keep.append(k) print('Words to Keep: {} / {} = {:.2%}'.format( len(words_to_keep), len(self.word2index), len(words_to_keep) / len(self.word2index))) - 最后,我们的索引是从新的words_to_keep列表重建的。我们将所有索引设置为它们的初始空值,然后通过使用addWord函数遍历我们保留的单词来重新填充它们:
self.word2index = {} self.word2count = {} self.index2word = {PAD_token: "PAD",\ SOS_token: "SOS",\ EOS_token: "EOS"} self.num_words = 3 for w in words_to_keep: self.addWord(w)
我们现在有定义了一个词汇类,可以很容易地用我们的输入句子填充。接下来,我们实际上需要加载我们的数据集来创建我们的训练数据。
加载数据
- 读取数据的第一步是执行任何必要的步骤来清理数据并使其更易于阅读。我们首先将其从 Unicode 转换为 ASCII 格式。我们可以很容易地使用一个函数来做到这一点:
def unicodeToAscii(s): return ''.join( c for c in unicodedata.normalize('NFD', s) if unicodedata.category(c) != 'Mn') - 接下来,我们要处理我们的输入字符串,使它们都是小写的,并且不包含任何尾随空格或标点符号,除了最基本的字符。我们可以通过使用一系列正则表达式来做到这一点:
def cleanString(s): s = unicodeToAscii(s.lower().strip()) s = re.sub(r"([.!?])", r" \1", s) s = re.sub(r"[^a-zA-Z.!?]+", r" ", s) s = re.sub(r"\s+", r" ", s).strip() return s - 最后,我们在更广泛的函数readVocs中应用这个函数。此函数将我们的数据文件读入行,然后将cleanString函数应用于每一行。它还创建了我们之前创建的Vocabulary类的一个实例,这意味着该函数同时输出我们的数据和词汇:
def readVocs(datafile, corpus_name): lines = open(datafile, encoding='utf-8').\ read().strip().split('\n') pairs = [[cleanString(s) for s in l.split('\t')] for l in lines] voc = Vocabulary(corpus_name) return voc, pairs接下来,我们按最大长度过滤输入对。再次这样做是为了减少我们模型的潜在维度。预测数百个单词长的句子需要非常深的架构。出于训练时间的考虑,我们希望将训练数据限制在输入和输出长度小于 10 个单词的实例中。
- 为此,我们创建了几个过滤器函数。第一个,filterPair,根据当前行的输入和输出长度是否小于最大长度返回一个布尔值。我们的第二个函数filterPairs简单地将这个条件应用于我们数据集中的所有对,只保留满足这个条件的那些:
def filterPair(p, max_length): return len(p[0].split(' ')) < max_length and len(p[1].split(' ')) < max_length def filterPairs(pairs, max_length): return [pair for pair in pairs if filterPair(pair, max_length)] - 现在,我们只需要创建一个应用所有先前函数的最终函数我们已经将它放在一起并运行它来创建我们的词汇和数据对:
def loadData(corpus, corpus_name, datafile, save_dir, max_length): voc, pairs = readVocs(datafile, corpus_name) print(str(len(pairs)) + " Sentence pairs") pairs = filterPairs(pairs,max_length) print(str(len(pairs))+ " Sentence pairs after trimming") for p in pairs: voc.addSentence(p[0]) voc.addSentence(p[1]) print(str(voc.num_words) + " Distinct words in vocabulary") return voc, pairs max_length = 10 voc, pairs = loadData(corpus, corpus_name, datafile,max_length)我们可以看到我们的输入数据集包含超过 200,000 对。当我们将其过滤到输入和输出长度都小于 10 个单词的句子时,这将减少到仅包含 18,000 个不同单词的 64,000 对:

图 8.7 – 数据集中句子的值
- 我们可以打印我们处理的输入/输出对的选择,以验证我们的功能是否都正常工作:
print("Example Pairs:") for pair in pairs[-10:]: print(pair)

图 8.8 – 处理的输入/输出对
看来我们已经成功地将数据集拆分为输入和输出对,我们可以在这些对上训练我们的网络。
最后,在我们开始构建模型之前,我们必须从我们的语料库和数据对中删除稀有词。
去除生僻字
如前所述,包括在我们的数据集中仅出现几次的单词将增加模型的维度,增加模型的复杂性和训练模型所需的时间。因此,最好将它们从我们的训练数据中删除,以使我们的模型尽可能地精简和高效。
您可能还记得之前我们在词汇表中构建了一个修剪功能,这将允许我们从词汇表中删除不经常出现的单词。我们现在可以创建一个函数来删除这些稀有词,并从我们的词汇表中调用trim方法作为我们的第一步。您会看到这会从我们的词汇表中删除很大比例的单词,这表明我们词汇表中的大多数单词很少出现。这是预期的,因为任何语言模型中的单词分布都将遵循长尾分布。我们将使用以下步骤删除单词:
- 我们首先计算我们将在模型中保留的单词的百分比:
def removeRareWords(voc, all_pairs, minimum): voc.trim(minimum)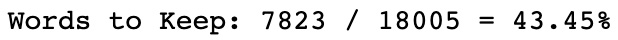
图 8.9 – 要保留的单词百分比
- 在同一个函数中,我们遍历输入和输出句子中的所有单词。如果对于给定的对,输入或输出句子中的单词不在我们的新的修剪语料库,我们从数据集中删除这对。我们打印输出并看到即使我们已经减少了一半以上的词汇量,我们也只减少了大约 17% 的训练对。这再次反映了我们的语料库是如何分布在我们各个训练对上的:
pairs_to_keep = [] for p in all_pairs: keep = True for word in p[0].split(' '): if word not in voc.word2index: keep = False break for word in p[1].split(' '): if word not in voc.word2index: keep = False break if keep: pairs_to_keep.append(p) print("Trimmed from {} pairs to {}, {:.2%} of total".\ format(len(all_pairs), len(pairs_to_keep), len(pairs_to_keep)/ len(all_pairs))) return pairs_to_keep minimum_count = 3 pairs = removeRareWords(voc, pairs, minimum_count)这将产生以下输出:
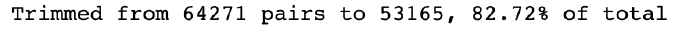
图 8.10 – 构建数据集后的最终值
现在我们有最终的数据集,我们需要构建一些函数,将我们的数据集转换为可以传递给模型的批量张量。
将句子对转换为张量
我们知道我们的模型不会将原始文本作为输入,而是将句子的张量表示。我们也不会一一处理我们的句子,而是小批量。为此,我们需要将输入和输出句子都转换为张量,其中张量的宽度表示我们希望训练的批次的大小:
- 我们首先创建几个辅助函数,我们可以使用它们将我们的对转换为张量。我们首先创建一个indexFromSentence函数,它从词汇表中获取句子中每个单词的索引,并在末尾附加一个 EOS 标记:
def indexFromSentence(voc, sentence): return [voc.word2index[word] for word in\ sent.split(' ')] + [EOS_token] - 其次,我们创建了一个zeroPad函数,它用零填充任何张量,以便张量中的所有句子实际上具有相同的长度:
def zeroPad(l, fillvalue=PAD_token): return list(itertools.zip_longest(*l,\ fillvalue=fillvalue)) - 然后,到生成我们的输入张量,我们应用这两个函数。首先,我们获取输入句子的索引,然后应用填充,然后将输出转换为LongTensor。我们还将获得每个输入句子的长度,并将其作为张量输出:
def inputVar(l, voc): indexes_batch = [indexFromSentence(voc, sentence) for sentence in l] padList = zeroPad(indexes_batch) padTensor = torch.LongTensor(padList) lengths = torch.tensor([len(indexes) for indexesin indexes_batch]) return padTensor, lengths - 在我们的网络中,我们填充的令牌通常应该被忽略。我们不想在这些填充标记上训练我们的模型,所以我们创建一个布尔掩码来忽略这些标记。为此,我们使用getMask函数,将其应用于输出张量。如果输出包含一个单词,则返回1 ,如果输出包含填充标记,则返回0 :
def getMask(l, value=PAD_token): m = [] for i, seq in enumerate(l): m.append([]) for token in seq: if token == PAD_token: m[i].append(0) else: m[i].append(1) return m - 然后我们将其应用于我们的outputVar函数。这与inputVar函数相同,除了索引输出张量和长度张量之外,我们还返回输出张量的布尔掩码。此布尔掩码仅在输出张量中有单词时返回True ,而在输出张量中返回False是一个填充标记。我们还返回输出张量中句子的最大长度:
def outputVar(l, voc): indexes_batch = [indexFromSentence(voc, sentence) for sentence in l] max_target_len = max([len(indexes) for indexes in indexes_batch]) padList = zeroPad(indexes_batch) mask = torch.BoolTensor(getMask(padList)) padTensor = torch.LongTensor(padList) return padTensor, mask, max_target_len - 最后,为了同时创建输入和输出批次,我们遍历批次中的对,并使用我们之前创建的函数为这两个对创建输入和输出张量。然后我们返回所有必要的变量:
def batch2Train(voc, batch): batch.sort(key=lambda x: len(x[0].split(" ")),reverse=True) input_batch = [] output_batch = [] for p in batch: input_batch.append(p[0]) output_batch.append(p[1]) inp, lengths = inputVar(input_batch, voc) output, mask, max_target_len = outputVar(output_batch, voc) return inp, lengths, output, mask, max_target_len - 这个函数应该是我们将训练对转换为张量以训练模型所需的全部内容。我们可以通过执行来验证这是否正常工作我们的batch2Train函数对我们的数据的随机选择的
单次迭代。我们将批量大小设置为5并运行一次:
test_batch_size = 5 batches = batch2Train(voc, [random.choice(pairs) for _ in range(test_batch_size)]) input_variable, lengths, target_variable, mask, max_target_len = batches在这里,我们可以验证我们的输入张量是否已正确创建。注意如何句子以填充(0 个标记)结尾,其中句子长度小于张量的最大长度(在本例中为 9)。张量的宽度也对应于批量大小(在本例中为 5):

图 8.11 – 输入张量
我们还可以验证相应的输出数据和掩码。请注意掩码中的False值如何与输出张量中的填充标记(零)重叠: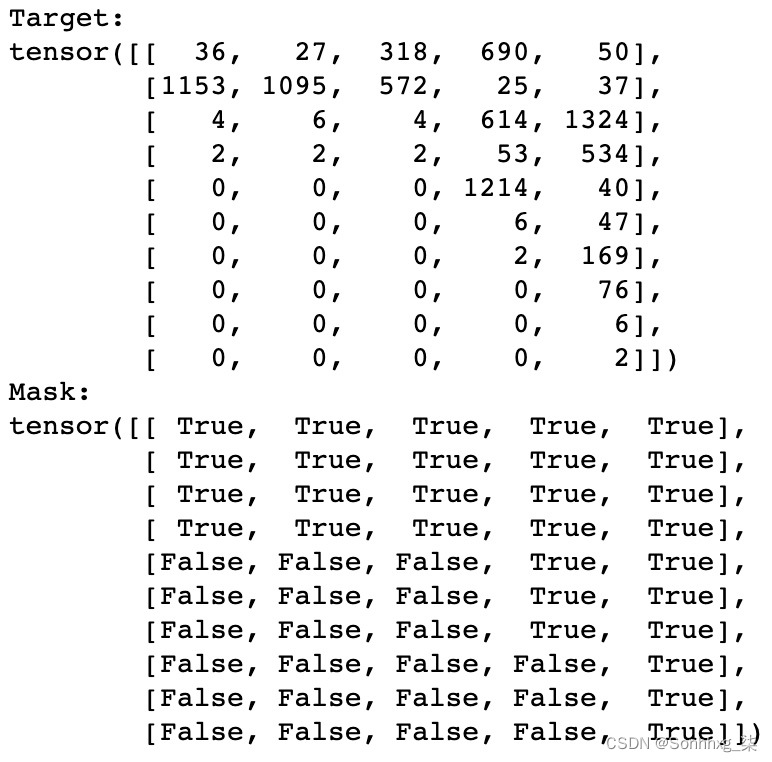
图 8.12 – 目标张量和掩码张量
现在我们已经获得、清理和转换了我们的数据,我们准备开始训练基于注意力的模型,该模型将构成我们聊天机器人的基础。
构建模型
我们与我们的其他序列到序列模型一样,首先创建我们的编码器。这会将我们输入句子的初始张量表示转换为隐藏状态。
构建编码器
- 与我们所有的 PyTorch 模型一样,我们首先创建一个继承自nn.Module的Encoder类。这里的所有元素都应该与前几章中使用的元素相似:
class EncoderRNN(nn.Module): def __init__(self, hidden_size, embedding,n_layers=1, dropout=0): super(EncoderRNN, self).__init__() self.n_layers = n_layers self.hidden_size = hidden_size self.embedding = embedding接下来,我们创建我们的循环 神经 网络( RNN ) 模块。在这个聊天机器人中,我们将使用门控循环单元( GRU ),而不是我们之前看到的长 短期 记忆( LSTM ) 模型。GRU 是比 LSTM 稍微简单一些尽管它们仍然通过 RNN 控制信息流,但它们没有像 LSTM 那样单独的忘记和更新门。我们在这种情况下使用 GRU 有几个主要原因:
a) GRU 已被证明具有更高的计算效率,因为要学习的参数更少。这意味着我们的模型使用 GRU 的训练速度比使用 LSTM 的要快得多。
b) GRU 已被证明在短数据序列上具有与 LSTM 相似的性能水平。LSTM 在学习更长的数据序列时更有用。在这种情况下,我们只使用不超过 10 个单词的输入句子,因此 GRU 应该会产生类似的结果。
c) GRU 已被证明在从小数据集学习方面比 LSTM 更有效。由于我们的训练数据的大小相对于我们尝试学习的任务的复杂性来说很小,我们应该选择使用 GRU。
- 我们现在定义我们的 GRU,考虑到我们输入的大小、层数以及我们是否应该实现
self.gru = nn.GRU(hidden_size, hidden_size, n_layers, dropout=(0 if n_layers == 1 else dropout), bidirectional=True)请注意我们如何在模型中实现双向性。你会记得在前面的章节中,双向 RNN 允许我们从句子中学习通过一个句子顺序向前移动,以及顺序向后移动。这使我们能够更好地捕捉句子中每个单词相对于它之前和之后出现的单词的上下文。GRU 中的双向性意味着我们的编码器看起来像这样:
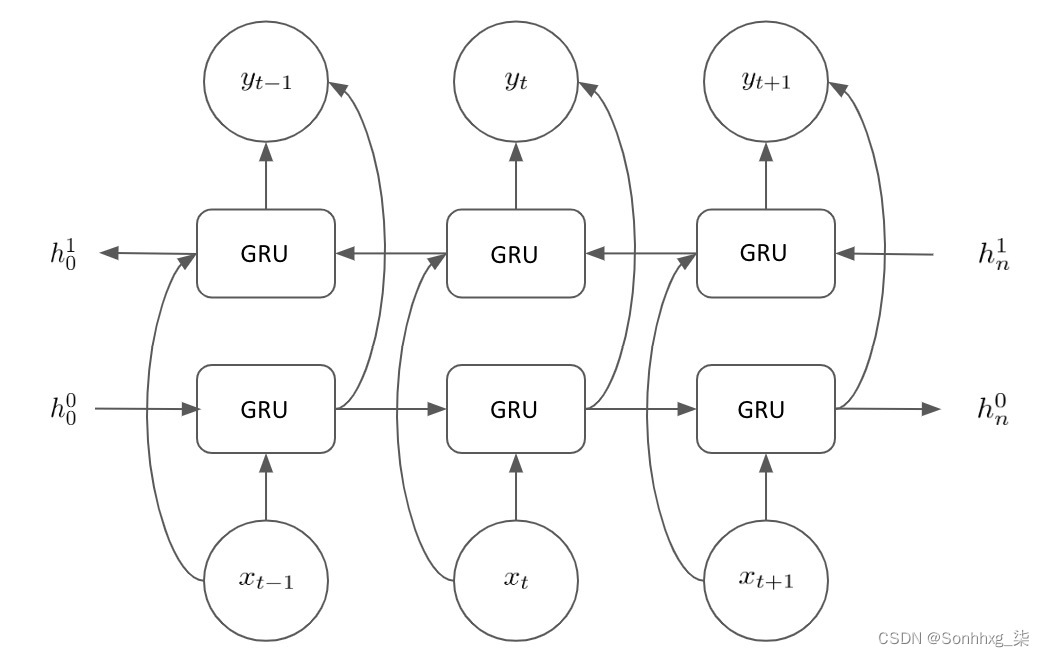
图 8.13 – 编码器布局
我们在输入句子中维护两个隐藏状态以及每一步的输出。
- 接下来,我们需要为我们的编码器创建一个前向传递。为此,我们首先嵌入我们的输入句子,然后在我们的嵌入中使用pack_padded_sequence函数。这个函数“打包”我们的填充序列,以便我们所有的输入都具有相同的长度。然后,我们通过 GRU 传递打包的序列以执行前向传递:
def forward(self, input_seq, input_lengths, hidden=None): embedded = self.embedding(input_seq) packed = nn.utils.rnn.pack_padded_sequence(embedded,input_lengths) outputs, hidden = self.gru(packed, hidden) - 在此之后,我们解包填充并对 GRU 输出求和。然后我们可以返回这个将输出与我们的最终隐藏状态相加,以完成我们的前向传递:
outputs, _ = nn.utils.rnn.pad_packed_sequence(outputs) outputs = outputs[:, :, :self.hidden_size] + a outputs[:, : ,self.hidden_size:] return outputs, hidden
现在,我们将继续在下一节中创建注意力模块。
构建注意力模块
接下来,我们需要构建我们的注意力模块,我们将其应用于我们的编码器,以便我们可以从编码器输出的相关部分中学习。我们将这样做:
- 首先为注意力模型创建一个类:
class Attn(nn.Module): def __init__(self, hidden_size): super(Attn, self).__init__() self.hidden_size = hidden_size - 然后,在此类中创建dot_score函数。这个函数简单地计算我们的编码器输出与我们的编码器的隐藏状态输出的点积。虽然还有其他方法可以将这两个张量转换为单个表示,但使用点积是最简单的方法之一:
def dot_score(self, hidden, encoder_output): return torch.sum(hidden * encoder_output, dim=2) - 然后我们在前向传递中使用这个函数。首先,根据dot_score方法计算注意力权重/能量,然后对结果进行转置,返回经过 softmax 变换的概率分数:
def forward(self, hidden, encoder_outputs): attn_energies = self.dot_score(hidden, encoder_outputs) attn_energies = attn_energies.t() return F.softmax(attn_energies, dim=1).unsqueeze(1)
接下来,我们可以在我们的解码器中使用这个注意力模块来创建一个专注于注意力的解码器。
构造解码器
- 我们首先创建我们的DecoderRNN类,继承自nn.Module并定义初始化参数:
class DecoderRNN(nn.Module): def __init__(self, embedding, hidden_size, output_size, n_layers=1, dropout=0.1): super(DecoderRNN, self).__init__() self.hidden_size = hidden_size self.output_size = output_size self.n_layers = n_layers self.dropout = dropout - 然后我们在这个模块中创建我们的层。我们将创建一个嵌入层和一个相应的 dropout 层。我们再次为解码器使用 GRU;但是,这一次,我们不需要使 GRU 层双向,因为我们将按顺序解码来自编码器的输出。我们还将创建两个线性层——一个用于计算输出的常规层和一个可用于连接的层。该层是常规隐藏层宽度的两倍,因为它将用于两个连接向量,每个向量的长度为hidden_size。我们还初始化了上一节中注意力模块的一个实例,以便能够在我们的解码器类中使用它:
self.embedding = embedding self.embedding_dropout = nn.Dropout(dropout) self.gru = nn.GRU(hidden_size, hidden_size, n_layers, dropout=(0 if n_layers == 1 else dropout)) self.concat = nn.Linear(2 * hidden_size, hidden_size) self.out = nn.Linear(hidden_size, output_size) self.attn = Attn(hidden_size) - 后定义我们所有的层,我们需要为解码器创建一个前向传递。请注意前向传递将如何一次使用一步(单词)。我们首先获取当前输入词的嵌入并通过 GRU 层进行前向传递以获取我们的输出和隐藏状态:
def forward(self, input_step, last_hidden, encoder_outputs): embedded = self.embedding(input_step) embedded = self.embedding_dropout(embedded) rnn_output, hidden = self.gru(embedded, last_hidden) - 接下来,我们使用注意力模块从 GRU 输出中获取注意力权重。然后将这些权重乘以编码器输出,以有效地为我们提供注意力权重和编码器输出的加权和:
attn_weights = self.attn(rnn_output, encoder_outputs) context = attn_weights.bmm(encoder_outputs.transpose(0,1)) - 然后,我们将加权上下文向量与 GRU 的输出连接起来,并应用一个tanh函数来得到最终的连接输出:
rnn_output = rnn_output.squeeze(0) context = context.squeeze(1) concat_input = torch.cat((rnn_output, context), 1) concat_output = torch.tanh(self.concat(concat_input)) - 为了在我们的解码器中的最后一步,我们只需使用这个最终的连接输出来预测下一个单词并应用一个softmax函数。前向传递最终返回这个输出,以及最终的隐藏状态。这个前向传递将被迭代,下一个前向传递使用句子中的下一个单词和这个新的隐藏状态:
output = self.out(concat_output) output = F.softmax(output, dim=1) return output, hidden
现在我们已经定义了模型,我们准备定义训练过程
定义训练过程
训练过程的第一步是为我们的模型定义损失度量。作为我们的输入张量可能由填充序列组成,由于我们的输入句子都是不同的长度,我们不能简单地计算真实输出和预测输出张量之间的差异。为了解决这个问题,我们将定义一个损失函数,在我们的输出上应用一个布尔掩码,并且只计算未填充标记的损失:
- 在下面的函数中,我们可以看到我们计算了整个输出张量的交叉熵损失。然而,为了得到总损失,我们只对布尔掩码选择的张量元素进行平均:
def NLLMaskLoss(inp, target, mask): TotalN = mask.sum() CELoss = -torch.log(torch.gather(inp, 1, target.view(-1, 1)).squeeze(1)) loss = CELoss.masked_select(mask).mean() loss = loss.to(device) return loss, TotalN.item() - 对于我们的大部分训练,我们需要两个主要函数——一个函数train()对我们的单批训练数据执行训练,另一个函数trainIters()遍历我们的整个数据集并调用train()在每个单独的批次上。我们首先定义train()以便训练在单批数据上。创建train()函数,然后将梯度设为 0,定义设备选项,并初始化变量:
def train(input_variable, lengths, target_variable,\ mask, max_target_len, encoder, decoder,\ embedding, encoder_optimizer,\ decoder_optimizer, batch_size, clip,\ max_length=max_length): encoder_optimizer.zero_grad() decoder_optimizer.zero_grad() input_variable = input_variable.to(device) lengths = lengths.to(device) target_variable = target_variable.to(device) mask = mask.to(device) loss = 0 print_losses = [] n_totals = 0 - 然后,通过编码器执行输入和序列长度的前向传递,以获得输出和隐藏状态:
encoder_outputs, encoder_hidden = encoder(input_variable, lengths) - 接下来,我们创建初始解码器输入,从每个句子的 SOS 标记开始。然后我们将解码器的初始隐藏状态设置为等于编码器的隐藏状态:
decoder_input = torch.LongTensor([[SOS_token for _ in \ range(batch_size)]]) decoder_input = decoder_input.to(device) decoder_hidden = encoder_hidden[:decoder.n_layers]接下来,我们实施教师强制。如果你回想一下上一章,teacher forcing,当以给定概率生成输出序列时,我们使用真实的先前输出标记而不是预测的先前输出标记来生成输出序列中的下一个单词。使用教师强迫可以帮助我们模型收敛得更快;但是,我们必须注意不要让teacher forcing 比率过高,否则我们的模型将过于依赖teacher forcing,无法学会独立生成正确的输出。
- 确定我们是否应该在当前步骤中使用教师强制:
use_TF = True if random.random() < teacher_forcing_ratio else False - 然后,如果我们确实需要实施教师强制,请运行以下代码。我们通过解码器传递每个序列批次以获得我们的输出。然后我们将下一个输入设置为真正的输出(目标)。最后,我们使用我们的损失函数计算并累积损失并将其打印到控制台:
for t in range(max_target_len): decoder_output, decoder_hidden = decoder( decoder_input, decoder_hidden, encoder_outputs) decoder_input = target_variable[t].view(1, -1) mask_loss, nTotal = NLLMaskLoss(decoder_output, \ target_variable[t], mask[t]) loss += mask_loss print_losses.append(mask_loss.item() * nTotal) n_totals += nTotal - 如果我们不对给定的批次实施教师强制,则过程几乎相同。但是,我们不使用真实输出作为序列的下一个输入,而是使用模型生成的输出:
_, topi = decoder_output.topk(1) decoder_input = torch.LongTensor([[topi[i][0] for i in \ range(batch_size)]]) decoder_input = decoder_input.to(device) - 最后,与我们所有的模型一样,最后的步骤是执行反向传播,实现梯度裁剪,并逐步通过我们的编码器和解码器优化器以使用梯度下降来更新权重。记住我们剪掉了梯度以防止梯度消失/爆炸问题,这在前面的章节中已经讨论过。最后,我们的训练步骤返回我们的平均损失:
loss.backward() _ = nn.utils.clip_grad_norm_(encoder.parameters(), clip) _ = nn.utils.clip_grad_norm_(decoder.parameters(), clip) encoder_optimizer.step() decoder_optimizer.step() return sum(print_losses) / n_totals - 接下来,如前所述,我们需要创建trainIters()函数,该函数重复在不同批次的输入数据上调用我们的训练函数。我们首先使用我们之前创建的batch2Train函数将数据分成批次:
def trainIters(model_name, voc, pairs, encoder, decoder,\ encoder_optimizer, decoder_optimizer,\ embedding, encoder_n_layers, \ decoder_n_layers, save_dir, n_iteration,\ batch_size, print_every, save_every, \ clip, corpus_name, loadFilename): training_batches = [batch2Train(voc,\ [random.choice(pairs) for _ in\ range(batch_size)]) for _ in\ range(n_iteration)] - 然后,我们创建了一些变量,这些变量将允许我们计算迭代次数并跟踪每个 epoch 的总损失:
print('Starting ...') start_iteration = 1 print_loss = 0 if loadFilename: start_iteration = checkpoint['iteration'] + 1 - 接下来,我们定义我们的训练循环。对于每次迭代,我们从批次列表中获得一个训练批次。然后我们从批处理中提取相关字段并运行使用这些参数进行单次训练迭代。最后,我们将此批次的损失添加到我们的整体损失中:
print("Beginning Training...") for iteration in range(start_iteration, n_iteration + 1): training_batch = training_batches[iteration - 1] input_variable, lengths, target_variable, mask, max_target_len = training_batch loss = train(input_variable, lengths, target_variable, mask, max_target_len, encoder, decoder, embedding, encoder_optimizer, decoder_optimizer, batch_size, clip) print_loss += loss - 在每次迭代中,我们还确保打印到目前为止的进度,跟踪我们完成了多少次迭代以及每个 epoch 的损失:
if iteration % print_every == 0: print_loss_avg = print_loss / print_every print("Iteration: {}; Percent done: {:.1f}%; Mean loss: {:.4f}".format(iteration, iteration / n_iteration * 100, print_loss_avg)) print_loss = 0 - 为了完成,我们还需要每隔几个 epoch 保存一次模型状态。这使我们能够重新审视我们训练过的任何历史模型;例如,如果我们的模型开始过拟合,我们可以恢复到更早的迭代:
if (iteration % save_every == 0): directory = os.path.join(save_dir, model_name,\ corpus_name, '{}-{}_{}'.\ format(encoder_n_layers,\ decoder_n_layers, \ hidden_size)) if not os.path.exists(directory): os.makedirs(directory) torch.save({ 'iteration': iteration, 'en': encoder.state_dict(), 'de': decoder.state_dict(), 'en_opt': encoder_optimizer.state_dict(), 'de_opt': decoder_optimizer.state_dict(), 'loss': loss, 'voc_dict': voc.__dict__, 'embedding': embedding.state_dict() }, os.path.join(directory, '{}_{}.tar'.format(iteration, 'checkpoint')))
现在我们已经完成了开始训练模型的所有必要步骤,我们需要创建函数来评估模型的性能。
定义评估过程
评估一个聊天机器人与评估其他序列到序列模型略有不同。在我们的文本翻译任务中,一个英语句子将直接翻译成德语。虽然可能有多个正确的翻译,但在大多数情况下,从一种语言到另一种语言只有一个正确的翻译。
对于聊天机器人,有多种不同的有效输出。从与聊天机器人的一些对话中提取以下三行:
Input: "Hello"
Output: "Hello"
Input: "Hello"
Output: "Hello. How are you?"
Input: "Hello"
Output: "What do you want?"
在这里,我们有三个不同的响应,每个响应都同样有效。因此,在我们与聊天机器人对话的每个阶段,都不会有单一的“正确”响应。因此,评估要困难得多。最直观的测试方式聊天机器人是否产生有效的输出取决于与它的对话!这意味着我们需要以某种方式设置我们的聊天机器人,使我们能够与它进行对话以确定它是否运行良好:
- 我们将从定义一个类开始,该类允许我们解码编码的输入并生成文本。我们的确是这是通过使用所谓的贪婪编码器来实现的。这仅仅意味着在解码器的每一步,我们的模型都将预测概率最高的单词作为输出。我们首先使用预训练的编码器和解码器初始化
class GreedySearchDecoder(nn.Module): def __init__(self, encoder, decoder): super(GreedySearchDecoder, self).__init__() self.encoder = encoder self.decoder = decoder - 接下来,为我们的解码器定义一个前向传递。我们通过我们的编码器传递输入以获得我们的编码器的输出和隐藏状态。我们将编码器的最终隐藏层作为解码器的第一个隐藏输入:
def forward(self, input_seq, input_length, max_length): encoder_outputs, encoder_hidden = \ self.encoder(input_seq, input_length) decoder_hidden = encoder_hidden[:decoder.n_layers] - 然后,使用 SOS 令牌创建解码器输入并初始化张量以将解码后的单词附加到(初始化为单个零值):
decoder_input = torch.ones(1, 1, device=device, dtype=torch.long) * SOS_token all_tokens = torch.zeros([0], device=device, dtype=torch.long) all_scores = torch.zeros([0], device=device) - 之后,遍历序列,一次解码一个单词。我们执行前向传递通过编码器并添加一个max函数以获得最高得分的预测词及其得分,然后我们将其附加到all_tokens和all_scores变量。最后,我们将这个预测的标记用作解码器的下一个输入。在整个序列被迭代之后,我们返回完整的预测句子:
for _ in range(max_length): decoder_output, decoder_hidden = self.decoder\ (decoder_input, decoder_hidden, encoder_outputs) decoder_scores, decoder_input = \ torch.max (decoder_output, dim=1) all_tokens = torch.cat((all_tokens, decoder_input),\ dim=0) all_scores = torch.cat((all_scores, decoder_scores),\ dim=0) decoder_input = torch.unsqueeze(decoder_input, 0) return all_tokens, all_scores所有的部分都开始融合在一起。我们已经定义了训练和评估函数,所以最后一步是编写一个函数,该函数实际上将我们的输入作为文本,将其传递给我们的模型,并从模型中获得响应。这将是我们聊天机器人的“界面”,我们实际上在这里进行对话。
- 我们首先定义一个evaluate()函数,它接受我们的输入函数并返回预测的输出单词。我们首先使用我们的词汇表将输入句子转换为索引。然后我们获得每个句子长度的张量并将其转置:
def evaluate(encoder, decoder, searcher, voc, sentence,\ max_length=max_length): indices = [indexFromSentence(voc, sentence)] lengths = torch.tensor([len(indexes) for indexes \ in indices]) input_batch = torch.LongTensor(indices).transpose(0, 1) - 然后我们将我们的长度和输入张量分配给相关设备。接下来,通过搜索器(GreedySearchDecoder)运行输入以获得预测输出的单词索引。最后,我们将这些单词索引转换回单词标记,然后将它们作为函数输出返回:
input_batch = input_batch.to(device) lengths = lengths.to(device) tokens, scores = searcher(input_batch, lengths, \ max_length) decoded_words = [voc.index2word[token.item()] for \ token in tokens] return decoded_words - 最后,我们创建了一个runchatbot函数,它充当我们聊天机器人的接口。此函数接受人工输入并打印聊天机器人的响应。我们将此函数创建为一个while循环,该循环一直持续到我们终止函数或输入quit作为输入:
def runchatbot(encoder, decoder, searcher, voc): input_sentence = '' while(1): try: input_sentence = input('> ') if input_sentence == 'quit': break - 然后我们获取输入的输入并对其进行规范化,然后将规范化的输入传递给我们的evaluate()函数,该函数从聊天机器人返回预测的单词:
input_sentence = cleanString(input_sentence) output_words = evaluate(encoder, decoder, searcher,\ voc, input_sentence) - 最后,我们在打印聊天机器人的响应之前,获取这些输出字并对其进行格式化,忽略 EOS 和填充标记。因为这是一个while循环,所以我们可以无限期地继续与聊天机器人的对话:
output_words[:] = [x for x in output_words if \ not (x == 'EOS' or x == 'PAD')] print('Response:', ' '.join(output_words))
现在我们已经构建了训练、评估和使用聊天机器人所需的所有功能,是时候开始最后一步了——训练我们的模型并与我们训练有素的聊天机器人进行对话。
训练模型
正如我们已经定义了所有必要的函数,训练模型只是一个案例或初始化我们的超参数并调用我们的训练函数:
- 我们首先初始化我们的超参数。虽然这些只是建议的超参数,但我们的模型的设置方式允许它们适应它们传递的任何超参数。尝试使用不同的超参数来查看哪些超参数会产生最佳模型配置是一种很好的做法。在这里,您可以尝试增加编码器和解码器中的层数,增加或减少隐藏层的大小,或者增加批量大小。所有这些超参数都会影响模型的学习效果,以及许多其他因素,例如训练模型所需的时间:
model_name = 'chatbot_model' hidden_size = 500 encoder_n_layers = 2 decoder_n_layers = 2 dropout = 0.15 batch_size = 64 - 之后,我们可以加载我们的检查点。如果我们之前训练过一个模型,我们可以从以前的迭代中加载检查点和模型状态。这使我们不必每次都重新训练我们的模型:
loadFilename = None checkpoint_iter = 4000 if loadFilename: checkpoint = torch.load(loadFilename) encoder_sd = checkpoint['en'] decoder_sd = checkpoint['de'] encoder_optimizer_sd = checkpoint['en_opt'] decoder_optimizer_sd = checkpoint['de_opt'] embedding_sd = checkpoint['embedding'] voc.__dict__ = checkpoint['voc_dict'] - 之后,我们就可以开始构建我们的模型了。我们首先从词汇表中加载我们的嵌入。如果我们已经训练了一个模型,我们可以加载训练好的嵌入层:
embedding = nn.Embedding(voc.num_words, hidden_size) if loadFilename: embedding.load_state_dict(embedding_sd) - 然后我们对编码器和解码器做同样的事情,使用定义的超参数创建模型实例。同样,如果我们已经训练了一个模型,我们只需将训练好的模型状态加载到我们的模型中:
encoder = EncoderRNN(hidden_size, embedding, \ encoder_n_layers, dropout) decoder = DecoderRNN(embedding, hidden_size, \ voc.num_words, decoder_n_layers, dropout) if loadFilename: encoder.load_state_dict(encoder_sd) decoder.load_state_dict(decoder_sd) - 最后的但同样重要的是,我们为要训练的每个模型指定了一个设备。请记住,如果您希望使用 GPU 训练,这是至关重要的一步:
encoder = encoder.to(device) decoder = decoder.to(device) print('Models built and ready to go!')如果这一切都正常工作并且您的模型已创建且没有错误,您应该看到以下内容:

图 8.14 – 成功输出
现在我们已经创建了编码器和解码器的实例,我们准备开始训练它们。
我们首先初始化一些训练超参数。与我们的模型超参数一样,可以调整这些超参数以影响训练时间和模型的学习方式。Clip 控制渐变剪裁,teacher forcing 控制我们在模型中使用teacher forcing 的频率。请注意我们如何使用教师强制比率 1,以便我们始终使用教师强制。降低教学强迫率意味着我们的模型需要更长的时间才能收敛;然而,从长远来看,它可能会帮助我们的模型更好地生成正确的句子。
- 我们还需要定义模型的学习率和解码器的学习率。你会发现你的模型在解码器携带的时候表现更好在梯度下降期间进行更大的参数更新。因此,我们引入了解码器学习率,以将乘数应用于学习率,从而使解码器的学习率大于编码器的学习率。我们还定义了模型打印和保存结果的频率,以及我们希望模型运行多少个 epoch:
save_dir = './' clip = 50.0 teacher_forcing_ratio = 1.0 learning_rate = 0.0001 decoder_learning_ratio = 5.0 epochs = 4000 print_every = 1 save_every = 500 - 接下来,像往常一样在 PyTorch 中训练模型时,我们将模型切换到训练模式以允许更新参数:
encoder.train() decoder.train() - 接下来,我们为编码器和解码器创建优化器。我们将它们初始化为 Adam 优化器,但其他优化器同样可以正常工作。尝试使用不同的优化器可能会产生不同级别的模型性能。如果您之前已经训练过模型,您还可以根据需要加载优化器状态:
print('Building optimizers ...') encoder_optimizer = optim.Adam(encoder.parameters(), \ lr=learning_rate) decoder_optimizer = optim.Adam(decoder.parameters(), lr=learning_rate * decoder_learning_ratio) if loadFilename: encoder_optimizer.load_state_dict(\ encoder_optimizer_sd) decoder_optimizer.load_state_dict(\ decoder_optimizer_sd) - 这运行训练之前的最后一步是确保将 CUDA 配置为在您希望使用 GPU 训练时调用。为此,我们只需遍历编码器和解码器的优化器状态,并在所有状态下启用 CUDA:
for state in encoder_optimizer.state.values(): for k, v in state.items(): if isinstance(v, torch.Tensor): state[k] = v.cuda() for state in decoder_optimizer.state.values(): for k, v in state.items(): if isinstance(v, torch.Tensor): state[k] = v.cuda() - 最后,我们准备好训练我们的模型。这可以通过简单地调用带有所有必需参数的trainIters函数来完成:
print("Starting Training!") trainIters(model_name, voc, pairs, encoder, decoder,\ encoder_optimizer, decoder_optimizer, \ embedding, encoder_n_layers, \ decoder_n_layers, save_dir, epochs, \ batch_size,print_every, save_every, \ clip, corpus_name, loadFilename)如果这工作正常,您应该会看到以下输出开始打印:
图 8.15 – 训练模型
您的模型正在训练中!根据许多因素,例如您为模型设置了多少个 epoch 以及您是否使用 GPU,您的模型可能需要一些时间来训练。完成后,您将看到以下输出。如果一切正常,您的模型的平均损失将大大低于您开始训练时,表明您的模型学到了一些有用的东西:
图 8.16 – 4,000 次迭代后的平均损失
现在我们的模型已经训练好了,我们可以开始评估过程并开始使用我们的聊天机器人了。
评估模型
现在我们已经成功地创建和训练了我们的模型,是时候评估它的性能了。我们将通过以下步骤来做到这一点:
- 开始评估,我们首先将我们的模型切换到评估模式。与所有其他 PyTorch 模型一样,这样做是为了防止在评估过程中发生任何进一步的参数更新:
encoder.eval() decoder.eval() - 我们还初始化了一个GreedySearchDecoder实例,以便能够执行评估并将预测输出作为文本返回:
searcher = GreedySearchDecoder(encoder, decoder) - 最后,要运行聊天机器人,我们只需调用runchatbot函数,将其传递给encoder、decoder、searcher和voc:
runchatbot(encoder, decoder, searcher, voc)这样做会打开一个输入提示,让您输入文本:

图 8.17 – 用于输入文本的 UI 元素
进入您在此处的文本并按Enter会将您的输入发送到聊天机器人。使用我们训练有素的模型,我们的聊天机器人将创建一个响应并将其打印到控制台:

图 8.18 – 聊天机器人的输出
您可以多次重复此过程,以便与聊天机器人进行“对话”。在简单的对话级别上,聊天机器人可以产生令人惊讶的好结果:

图 8.19 – 聊天机器人的输出
然而,有一次对话变得更加复杂,很明显聊天机器人无法与人类进行相同级别的对话:

图 8.20 – 聊天机器人的局限性
在许多情况下,您的聊天机器人的响应可能是荒谬的:
图 8.21 – 错误的输出
很明显,我们已经创建了一个能够进行简单来回对话的聊天机器人。然而,在我们的聊天机器人能够通过图灵测试并能够让我们相信我们实际上是在与人类交谈之前,我们还有很长的路要走。然而,考虑到我们训练模型的数据集相对较小,使用我们的序列到序列模型中的关注点已经显示出相当好的结果,证明了这些架构的通用性。
虽然最好的聊天机器人是在数十亿个数据点的庞大语料库上训练的,但我们的模型已被证明在一个相对较小的数据点上相当有效。然而,基本注意力网络不再是最先进的,在下一章中,我们将讨论 NL 的一些最新发展P 学习导致了更现实的聊天机器人。
概括
在本章中,我们应用了从循环模型和序列到序列模型中学到的所有知识,并将它们与注意力机制相结合,构建了一个完整的聊天机器人。虽然与我们的聊天机器人交谈与与真人交谈不太可能难以区分,但使用更大的数据集,我们可能希望实现一个更加逼真的聊天机器人。
尽管具有注意力的序列到序列模型在 2017 年是最先进的,但机器学习是一个快速发展的领域,从那时起,对这些模型进行了多项改进。在最后一章中,我们将更详细地讨论其中一些最先进的模型,并涵盖用于 NLP 机器学习的其他几种当代技术,其中许多仍在开发中。

















 213
213











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











