









🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
在本章中,您将熟练掌握决策树,这是构建 XGBoost 模型的主要机器学习算法。您还将获得超参数微调的科学和艺术方面的第一手经验。由于决策树是 XGBoost 模型的基础,因此您在本章中学习的技能对于构建稳健的 XGBoost 模型至关重要。
在本章中,您将构建和评估决策树分类器和决策树回归器,根据方差和偏差可视化和分析决策树,并微调决策树超参数。此外,您会将决策树应用于预测患者心脏病的案例研究。
本章涵盖以下主要主题:
-
使用 XGBoost 引入决策树
-
探索决策树
-
对比方差和偏差
-
调整决策树超参数
-
预测心脏病——案例研究
使用 XGBoost 引入决策树
XGBoost 是一种ensemble 方法, 意味着它由不同的结合在一起工作的机器学习模型。在 XGBoost 中构成集成的单个模型是称为基础学习者。
决策树是最常用的 XGBoost 基础学习器,在机器学习领域是独一无二的。决策树不是像线性回归和逻辑回归(第 1 章,机器学习领域)那样将列值乘以数值权重,而是通过询问有关列的问题来拆分数据。事实上,构建决策树就像玩 20 个问题的游戏。
例如,决策树可能有一个温度列,该列可以分为两组,一组温度高于 70 度,另一组温度低于 70 度。下一次拆分可能基于季节,如果是夏天,则跟随一个分支,否则跟随另一个分支。现在数据已被分成四个独立的组。这种通过分支将数据分成新组的过程一直持续到算法达到所需的准确度。
决策树可以创建数千个分支,直到它将每个样本唯一地映射到训练集中的正确目标。这意味着训练集可以有 100% 的准确率。然而,这样的模型不能很好地推广到新数据。
决策树容易过度拟合 d阿塔。换句话说,决策树可能过于接近训练数据,本章稍后将探讨方差和偏差方面的问题。超参数微调是防止过拟合。另一种解决方案是聚合许多树的预测,随机森林和 XGBoost 采用的一种策略。
虽然随机森林和 XGBoost 将是后续章节的重点,但我们现在深入了解决策树。
探索决策树
决策树工作通过将数据拆分为分支。分支被跟踪到进行预测的叶子。通过一个实际示例,了解如何创建树枝和树叶会容易得多。在深入细节之前,让我们构建我们的第一个决策树模型。
第一个决策树模型
我们首先构建一个使用第 1 章机器学习领域的人口普查数据集预测某人是否赚了超过 5 万美元的决策树:
-
首先,打开一个新的 Jupyter Notebook 并从以下导入开始:
import pandas as pd import numpy as np import warnings warnings.filterwarnings('ignore') -
接下来,打开已在https://github.com/PacktPublishing/Hands-On-Gradient-Boosting-with-XGBoost-and-Scikit-learn/tree/master/Chapter02为您上传的文件“census_cleaned.csv” . 如果您按照前言中的建议从 Packt GitHub 页面下载了本书的所有文件,您可以在启动 Anaconda 后,按照导航到其他章节的相同方式导航到第 2 章,深度决策树。否则,请访问我们的 GitHub 页面并立即克隆文件:
df_census = pd.read_csv('census_cleaned.csv') -
将数据上传到 DataFrame 后,将预测变量和目标列X和y声明为如下:
X = df_census.iloc[:,:-1] y = df_census.iloc[:,-1] -
接下来,导入train_test_split将数据拆分为random_state=2的训练集和测试集,以确保结果一致:
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=2)与其他机器学习分类器一样,在使用决策树时,我们初始化模型,将其拟合到训练集上,并使用accuracy_score对其进行测试。
accuracy_score确定正确预测的 数量除以预测的总数。如果 20 个预测中有 19 个是正确的,accuracy_score为 95%。
首先,导入DecisionTreeClassifier和accuracy_score:
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score接下来,我们使用标准步骤构建决策树分类器:
-
使用random_state=2初始化机器学习模型以确保结果一致:
clf = DecisionTreeClassifier(random_state=2) -
在训练集上拟合模型:
clf.fit(X_train, y_train) -
对测试集进行预测:
y_pred = clf.predict(X_test) -
accuracy_score(y_pred, y_test)accuracy_score如下:
0.8131679154894976
81% 的准确度与第 1 章机器学习领域中相同数据集的逻辑回归的准确度相当。
现在您已经了解了如何构建决策树,让我们来看看内部。
决策树内部
这是来自人口普查数据集的决策树,只有两个拆分:
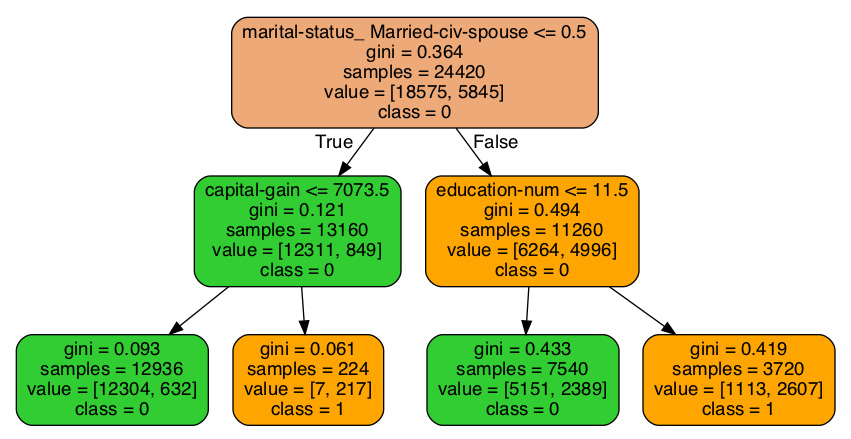
图 2.1 – 人口普查数据集决策树
树的顶部是根,True / False箭头是分支,数据点是节点。在树的末端,节点被分类为叶子。让我们深入研究前面的图表。
根
树的根是在顶部。第一行是marital-status_Married-civ-spouse <=5。marital-status是一个二进制列,因此所有值都是0(负)或1(正)。第一个分裂是基于某人是否已婚。树的左侧是True分支,表示用户未婚,右侧是False分支,表示用户已婚。
基尼标准
第二行根读取gini=0.364。这是决策树用来决定如何进行拆分的错误方法。目标是找到导致误差最小的拆分。基尼指数为 0 意味着 0 个错误。基尼指数为 1 意味着所有错误。基尼指数为 0.5,表示元素分布均等,这意味着预测并不比随机猜测好。越接近 0,误差越小。从根本上说,0.364 的 gini 意味着训练集与 36.4% 的类 1 不平衡。
基尼指数的公式如下:

图 2.2 – 基尼指数方程
![]() 是拆分产生正确值的概率,c 是类的总数:2 在前面的例子。另一种看待这一点的方式是,
是拆分产生正确值的概率,c 是类的总数:2 在前面的例子。另一种看待这一点的方式是, ![]() 集合中具有正确输出标签的项目的比例。
集合中具有正确输出标签的项目的比例。
样本、值、类
的根源树指出有 24,420 个样本。这是总数训练集中的样本数。以下行读取[18575 , 5845]。排序是 0 然后 1,因此 18,575 个样本的值为 0(它们的值小于 50K),5,845 个的值为 1(它们的值大于 50K)。
真/假节点
继第一个分支,您会在左侧看到True ,在左侧看到False正确的。真左假右的格局继续延续在树上。
在第二行的左侧节点中,将拆分的capital_gain <= 7073.5应用于后续节点。其余信息来自上一个分支上方的拆分。在 13,160 名未婚人士中,12,311 人的收入低于 5 万,而 849 人的收入低于收入超过50K。基尼指数0.121是一个非常好成绩。
树桩
有可能有一棵只有一次分裂的树。这样的树叫做树桩。虽然树桩本身并不是强大的预测器,当用作助推器时,树桩可以变得强大,如第 4 章从梯度提升到 XGBoost 中所述。
树叶
最左叶的基尼指数为0.093,正确预测了 12,938 例中的 12,304 例,即 95%。我们有 95% 的信心认为,资本收益低于 7,073.50 的未婚用户的收入不会超过 50K。
其他叶子可以类似地解释。
现在让我们看看这些预测哪里出错了。
对比方差和偏差
想象一下你将数据点显示在下图中。您的任务是拟合一条线或曲线,以便您对新点进行预测。
这是随机点的图表: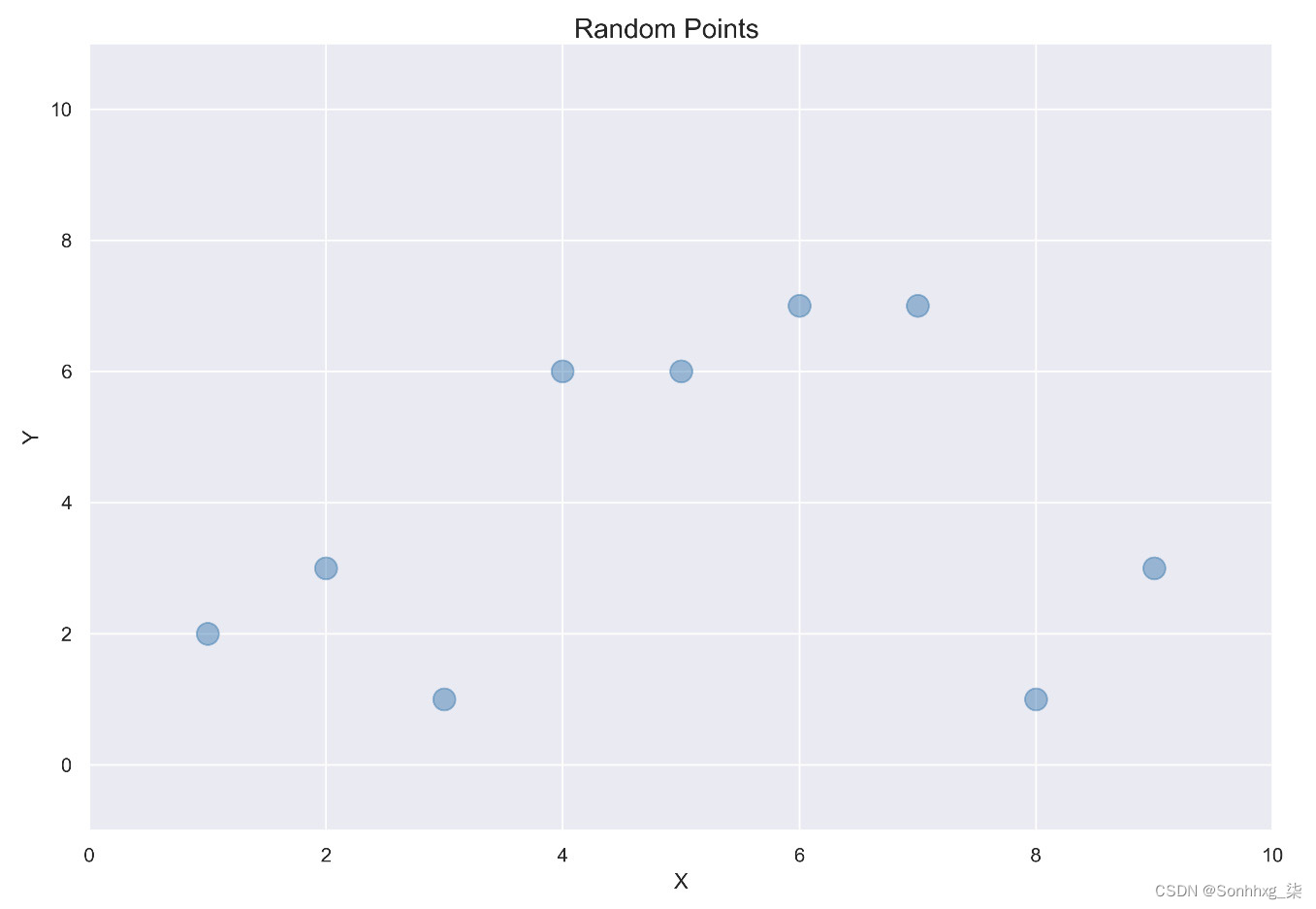
图 2.3 – 随机点图
一个想法是使用线性回归,它最小化每个点与线之间距离的平方,如下图所示: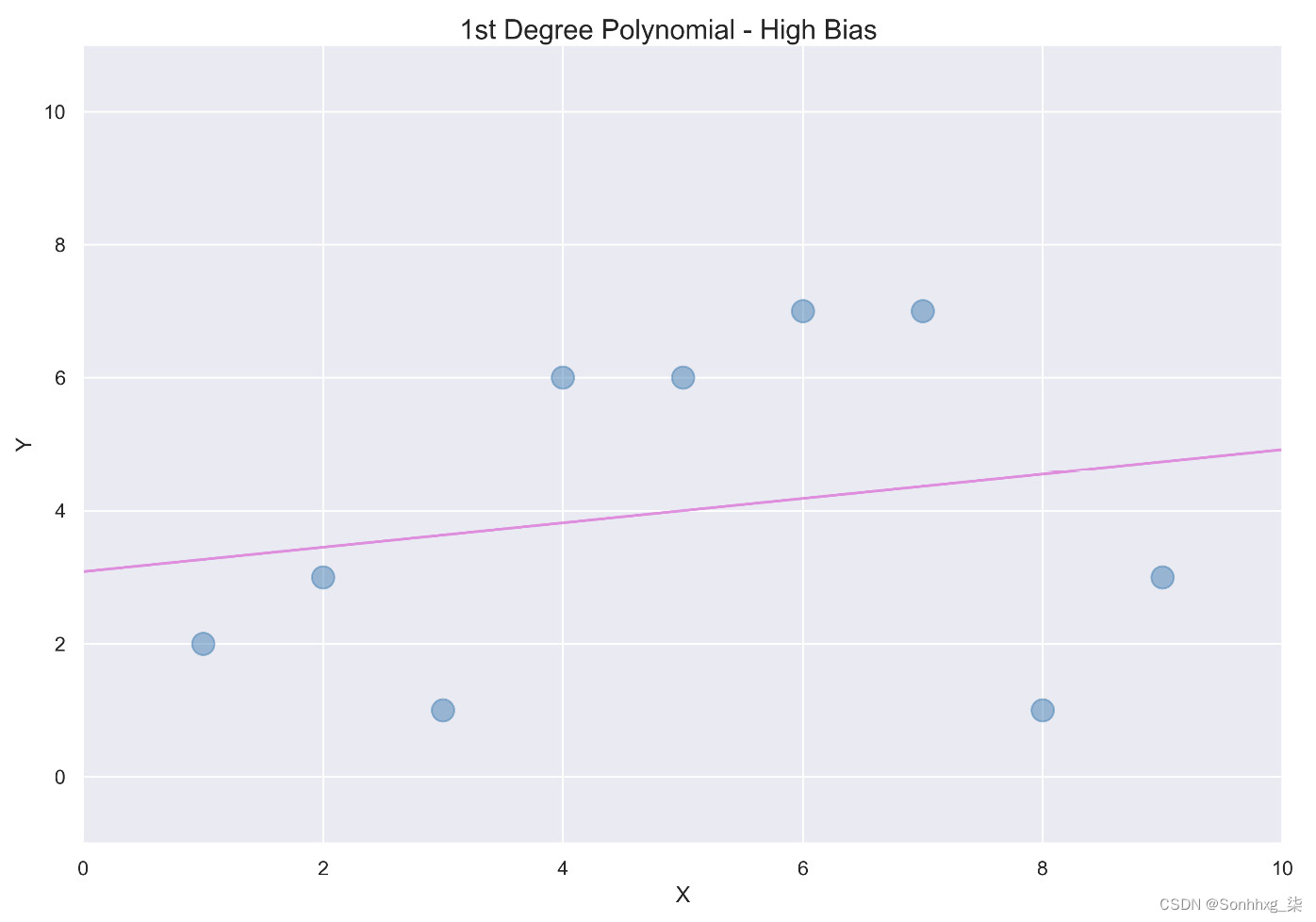
图 2.4 – 使用线性回归最小化距离
直线通常具有高偏差。在机器学习中,偏差是一个数学术语,来自将模型应用于实际问题时估计误差。直线的偏差很大,因为预测仅限于直线并且无法考虑数据的变化。
在许多情况下,直线不够复杂,无法做出准确的预测。发生这种情况时,我们说机器学习模型对具有高偏差的数据进行了欠拟合。
第二种选择是用Eight-degree多项式拟合这些点。由于只有九个点,八次多项式将完美拟合数据,如下图所示: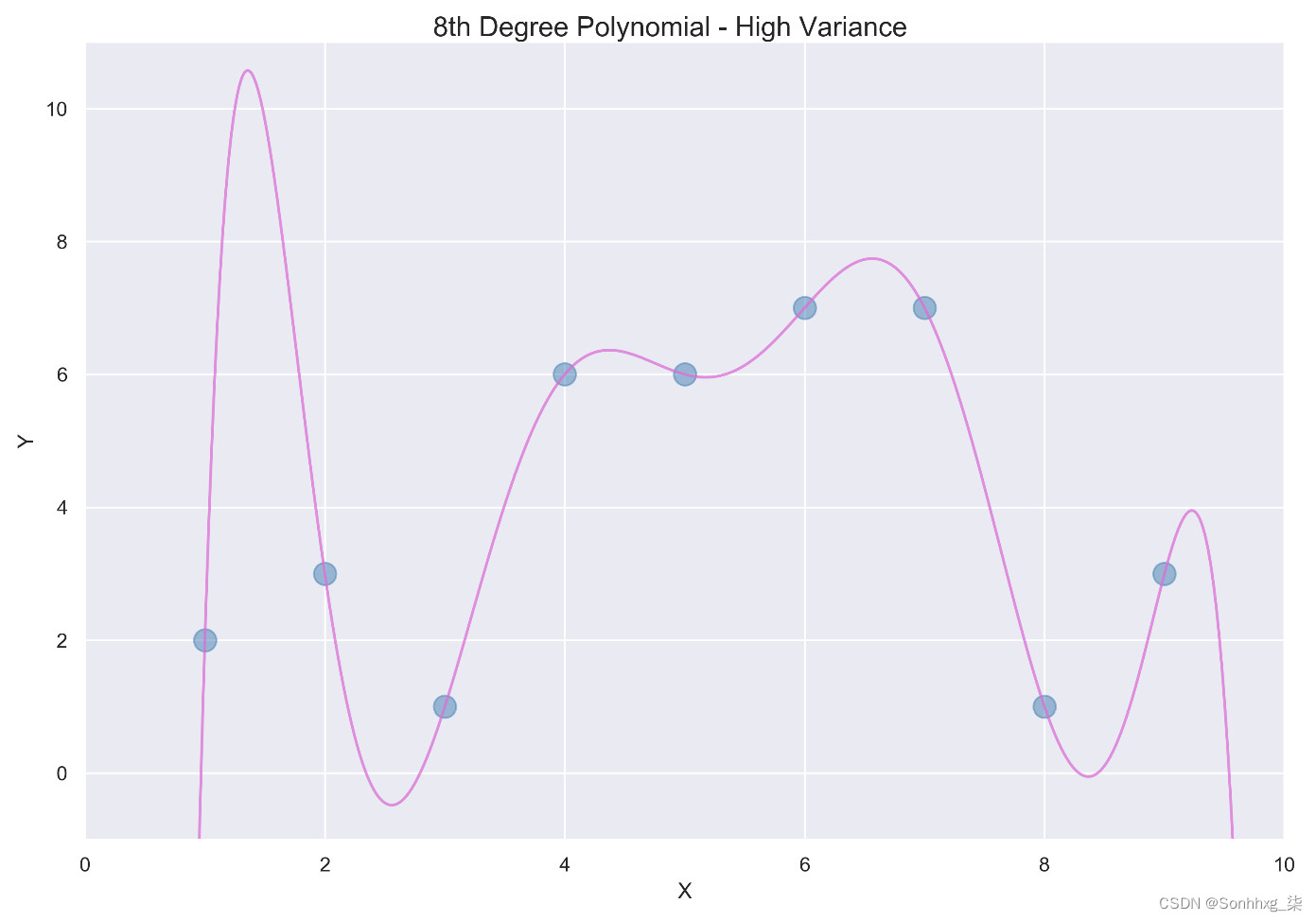
图 2.5 – Eight-degree多项式
该模型具有高方差。在机器学习中,方差是一个数学术语,表示在给定不同的训练数据集的情况下模型会发生多大的变化。形式上,方差是随机变量与其均值之间的平方偏差的度量。鉴于九训练集中的不同数据点,八次多项式会完全不同,导致高方差。
具有高方差的模型通常会过度拟合数据。这些模型不能很好地泛化到新数据点,因为它们与训练数据的拟合过于紧密。
在大数据的世界里,过拟合是一个大问题。更多的数据会产生更大的训练集,而决策树等机器学习模型也能很好地拟合训练数据。
作为最后一个选项,考虑一个适合数据点的三次多项式,如下图所示:
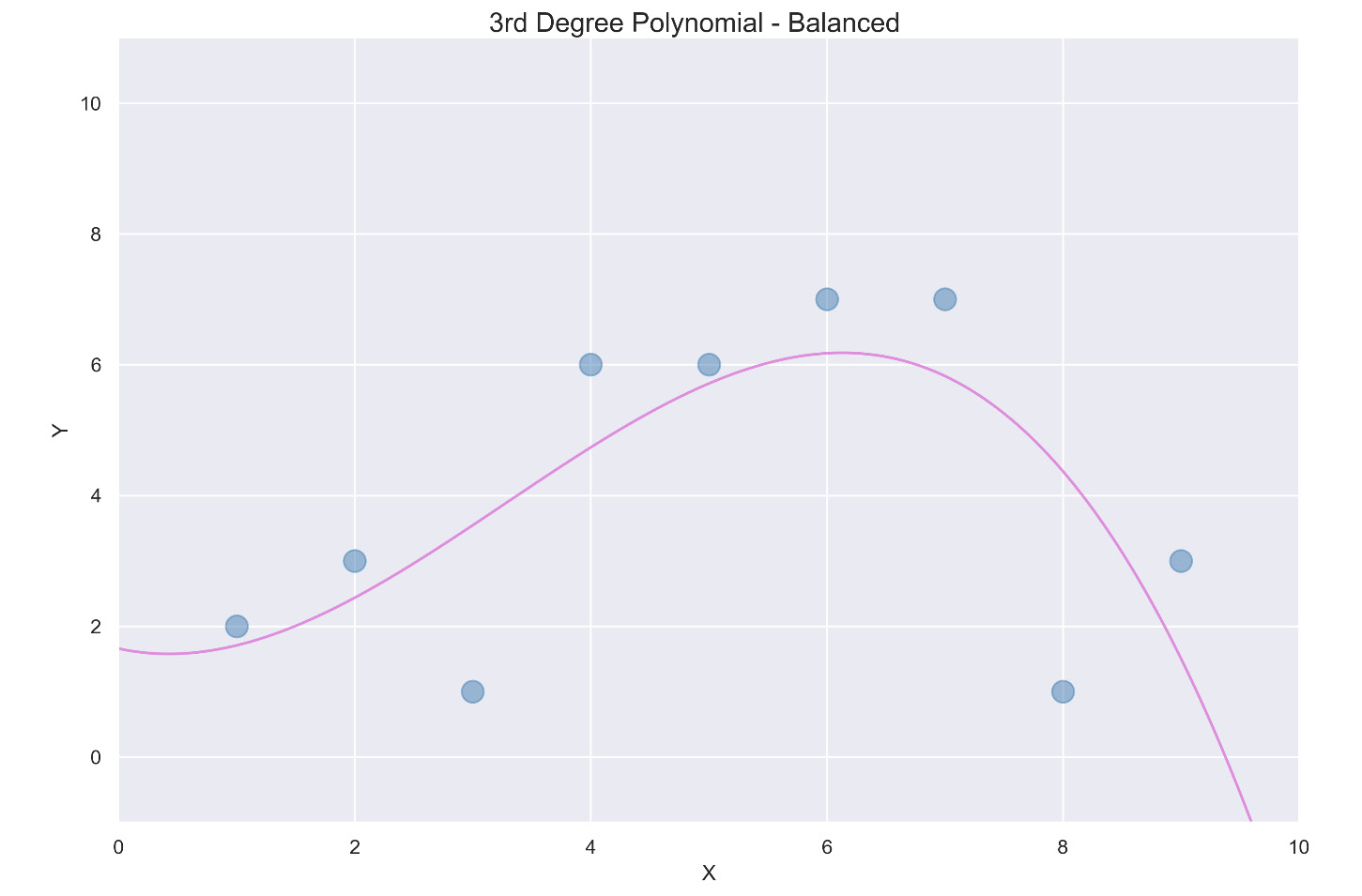
图 2.6 – 三阶多项式
这个三级多项式在方差和偏差之间提供了很好的平衡,通常遵循曲线,但适应变化。低方差意味着不同的训练集不会导致曲线相差很大。低偏差表示将此模型应用于实际情况时的误差不会太高。在机器学习中,低方差和低偏差的组合是理想的。
在方差和偏差之间取得良好平衡的最佳机器学习策略之一是微调超参数。
调整决策树超参数
在机器学习中,在调整模型时会调整参数。例如,线性回归和逻辑回归中的权重是在构建阶段调整的参数,以最大限度地减少错误。相比之下,超参数是在构建阶段之前选择的。如果未选择超参数,则使用默认值。
决策树回归器
最好的学习方式关于超参数是通过实验。尽管选择的超参数范围背后有理论,但结果胜过理论。不同的数据集通过不同的超参数值看到改进。
在选择超参数之前,让我们首先使用DecisionTreeRegressor和cross_val_score查找基线分数,步骤如下:
-
下载“bike_rentals_cleaned”数据集并将其拆分为X_bikes(预测列)和y_bikes(训练列):
df_bikes = pd.read_csv('bike_rentals_cleaned.csv') X_bikes = df_bikes.iloc[:,:-1]y_bikes = df_bikes.iloc[:,-1] -
导入DecisionTreeRegressor和 cross_val_score:
from sklearn.tree import DecisionTreeRegressor from sklearn.model_selection import cross_val_score -
初始化DecisionTreeRegressor并在cross_val_score中拟合模型:
reg = DecisionTreeRegressor(random_state=2) scores = cross_val_score(reg, X_bikes, y_bikes, scoring='neg_mean_squared_error', cv=5) -
rmse = np.sqrt(-scores) print('RMSE mean: %0.2f' % (rmse.mean()))结果如下:
RMSE mean: 1233.36
RMSE 为 1233.36。这比第 1 章机器学习景观中的线性回归得到的972.06和XGBoost得到的 887.31 差。
模型是否因为方差太高而过度拟合数据?
这个问题可以通过查看决策树单独对训练集做出预测的程度来回答。以下代码在对测试集进行预测之前检查训练集的错误:
reg = DecisionTreeRegressor()
reg.fit(X_train, y_train)y_pred = reg.predict(X_train)
from sklearn.metrics import mean_squared_error
reg_mse = mean_squared_error(y_train, y_pred)
reg_rmse = np.sqrt(reg_mse)reg_rmse结果如下:
0.0
RMSE 为0.0意味着该模型完全适合每个数据点!这个完美的分数与1233.36的交叉验证误差相结合,证明决策树过度拟合具有高方差的数据。训练集完美匹配,但测试集严重缺失。
超参数可能会纠正这种情况。
一般的超参数
超参数可以在 scikit-learn 的官方文档页面上查看所有 scikit-learn 模型的详细信息。
这是摘录来自 DecisionTreeRegressor 网站 ( sklearn.tree.DecisionTreeRegressor — scikit-learn 1.1.2 documentation )。
笔记
sklearn是scikit-learn 的缩写。
图 2.7。DecisionTreeRegressor 官方文档页面摘录
官方文档解释了超参数背后的含义。请注意,这里的Parameters是hyperparameters的缩写。自己工作时,查看官方文档是您最可靠的资源。
让我们一次一个地检查超参数。
最大深度
max_depth 定义树的深度,确定通过拆分的次数。默认情况下, max_depth没有限制,因此可能有成百上千的分割导致过拟合。通过将 max_depth限制 为较小的数字,可以减少方差,并且模型可以更好地泛化到新数据。
如何为max_depth选择最佳数字?
您总是可以尝试max_depth=1,然后是 max_depth=2,然后是 max_depth=3,依此类推,但这个过程会很累。相反,您可以使用名为GridSearchCV的出色工具。
GridSearchCV
GridSearchCV搜索一个超参数网格使用交叉验证来提供最佳结果。
GridSearchCV的功能与任何机器学习算法一样,这意味着它适合训练集,并在测试集上评分。主要区别在于GridSearchCV在最终确定模型之前检查所有超参数。
GridSearchCV的关键是建立一个超参数值字典。没有要尝试的正确值集。一种策略是选择一个最小值和最大值,它们之间的数字间隔均匀。由于我们试图减少过度拟合,因此总体思路是在max_depth的下侧尝试更多值。
导入GridSearchCV并为max_depth定义一个超参数列表,如下所示:
from sklearn.model_selection import GridSearchCV
params = {'max_depth':[None,2,3,4,6,8,10,20]}params字典包含一个键,' max_depth',写成一个字符串,和一个值,我们选择的数字列表。请注意,None是默认值,这意味着max_depth没有限制。
小费
一般来说,减少最大超参数和增加最小超参数将减少变化并防止过度拟合。
接下来,初始化一个DecisionTreeRegressor,并将其与参数和评分指标一起放在GridSearchCV中:
reg = DecisionTreeRegressor(random_state=2)
grid_reg = GridSearchCV(reg, params, scoring='neg_mean_squared_error', cv=5, n_jobs=-1)
grid_reg.fit(X_train, y_train)现在GridSearchCV已经适合数据,您可以查看最佳超参数,如下所示:
best_params = grid_reg.best_params_print("Best params:", best_params)结果如下:
Best params: {'max_depth': 6}
尽你所能看,max_depth值为6导致训练集中的最佳交叉验证分数。
可以使用best_score属性显示训练分数:
best_score = np.sqrt(-grid_reg.best_score_)
print("Training score: {:.3f}".format(best_score))分数如下:
Training score: 951.938
考试成绩可能显示如下:
best_model = grid_reg.best_estimator_
y_pred = best_model.predict(X_test)
rmse_test = mean_squared_error(y_test, y_pred)**0.5
print('Test score: {:.3f}'.format(rmse_test))Test score: 864.670
差异已大大减少。
min_samples_leaf
min_samples_leaf 提供限制通过增加叶子可能具有的样本数量。与max_depth 一样,min_samples_leaf旨在减少过度拟合。
当没有限制时, min_samples_leaf=1是默认值,这意味着叶子可能由唯一的样本组成(容易过度拟合)。增加min_samples_leaf 会减少方差。如果 min_samples_leaf=8,所有叶子必须包含八个或更多样本。
测试min_samples_leaf的一系列值 需要经历与以前相同的过程。我们没有复制和粘贴,而是编写了一个函数,使用GridSearchCV显示最佳参数、训练分数和测试分数,并将DecisionTreeRegressor(random_state=2)作为默认参数分配给reg :
def grid_search(params, reg=DecisionTreeRegressor(random_state=2)):
grid_reg = GridSearchCV(reg, params,
scoring='neg_mean_squared_error', cv=5, n_jobs=-1):
grid_reg.fit(X_train, y_train)
best_params = grid_reg.best_params_
print("Best params:", best_params)
best_score = np.sqrt(-grid_reg.best_score_)
print("Training score: {:.3f}".format(best_score))
y_pred = grid_reg.predict(X_test)
rmse_test = mean_squared_error(y_test, y_pred)**0.5
print('Test score: {:.3f}'.format(rmse_test))小费
在编写自己的函数时,包含默认关键字参数是有利的。默认关键字参数是具有默认值的命名参数,可以更改以供以后使用和测试。默认关键字参数极大地增强了 Python 的功能。
在选择超参数的范围时,了解构建模型的训练集的大小会很有帮助。Pandas 提供了一个不错的方法 .shape,它返回的行和列数据:
X_train.shape数据的行和列如下:
(548, 12)
由于训练集有548行,这有助于确定 min_samples_leaf的合理值。让我们尝试[1, 2, 4, 6, 8, 10, 20, 30]作为我们grid_search的输入:
grid_search(params={'min_samples_leaf':[1, 2, 4, 6, 8, 10, 20, 30]})分数如下:
Best params: {'min_samples_leaf': 8}
Training score: 896.083
Test score: 855.620
由于测试分数优于训练分数,因此减少了方差。
当我们将 min_samples_leaf 和 max_depth 放在一起会发生什么?让我们来看看:
grid_search(params={'max_depth':[None,2,3,4,6,8,10,20],
'min_samples_leaf':[1,2,4,6,8,10,20,30]})分数如下:
Best params: {'max_depth': 6, 'min_samples_leaf': 2}
Training score: 870.396
Test score: 913.000
结果可能出人意料。尽管训练分数提高了,但测试分数却没有。min_samples_leaf 从8减少到2,而 max_depth 保持不变。
小费
这是超参数调优的宝贵经验:不应孤立地选择超参数。
至于减前面的差异例如,将 min_samples_leaf限制为大于 3 的值可能会有所帮助:
grid_search(params={'max_depth':[6,7,8,9,10],
'min_samples_leaf':[3,5,7,9]})分数如下:
Best params: {'max_depth': 9, 'min_samples_leaf': 7}
Training score: 888.905
Test score: 878.538如您所见,考试成绩有所提高。
我们现在将探索剩余的决策树超参数,无需单独测试。
max_leaf_nodes
max_leaf_nodes 是相似的到 min_samples_leaf。它不是指定每个叶子的样本数,而是指定叶子的总数。因此,max_leaf_nodes=10意味着模型的叶子不能超过 10 个。它可能会更少。
最大特征
max_features 是一个有效超参数减少方差。它不是考虑拆分的每个可能的特征,而是从每轮的选定数量的特征中进行选择。
使用以下选项查看 max_features是标准的:
-
'auto' 是默认值,没有任何限制。
-
'sqrt'是特征总数的平方根。
-
“log2”是基数为 2 的特征总数的对数。32 列解析为 5,因为 2 ^5 = 32。
min_samples_split
其他拆分技术是 min_samples_split。作为名称表明, min_samples_split 限制了在进行拆分之前所需的样本数量。默认值为2,因为两个样本可以分别拆分为一个样本,以单叶结尾。如果限制增加到5,则不允许对具有五个或更少样本的节点进行进一步拆分。
分离器
那里有两个splitter、'random'和'best' 的选项。分路器告诉模型如何选择特征来分割每个分支。“最佳”选项(默认值)选择导致最大信息增益的特征。相比之下,“随机”选项随机选择拆分。
将拆分器更改为“随机”是防止过度拟合和使树多样化的好方法。
标准
分裂的 标准决策树回归器和分类器不同。该 标准提供了机器学习模型用来确定应该如何进行拆分的方法。这是拆分的计分方法。对于每个可能的拆分,该 标准 计算一个可能拆分的数字并将其与其他选项进行比较。得分最高的分组获胜。
决策树回归器的选项是 mse (均方误差)、 friedman_mse(包括弗里德曼调整)和 mae (平均绝对误差)。默认值为mse。
对于分类器,gini,其中前面已经描述过,熵通常会给出类似的结果。
min_impurity_decrease
之前已知与 min_impurity_split 一样, 当杂质大于或等于该值时, min_impurity_decrease会导致拆分。
杂质是衡量每个节点的预测有多纯的量度。具有 100% 准确度的树的杂质为 0.0。具有 80% 准确率的树的杂质为 0.20。
杂质是决策树中的一个重要概念。在整个造树过程中,杂质应该不断减少。为每个节点选择导致杂质减少最大的分裂。
默认值为0.0。可以增加此数字,以便在达到某个阈值时停止建造树木。
min_weight_fraction_leaf
min_weight_fraction_leaf 是所需总重量的最小加权分数成为一片叶子。根据文档,当未提供 sample_weight 时,样本具有相同的权重。
出于实际目的, min_weight_fraction_leaf 是另一个减少ces 方差并防止过拟合。默认值为 0.0。假设权重相同,1% 的限制,即 0.01,将要求 500 个样本中至少有 5 个是叶子。
ccp_alpha
ccp_alpha超参数此处不再讨论,因为它是为在树已经建成。有关完整的讨论,请查看最小成本复杂性修剪:https ://scikit-learn.org/stable/modules/tree.html#minimal-cost-complexity-pruning 。
把它们放在一起
在微调超参数时,有几个因素起作用:
-
分配的时间
-
超参数的数量
-
所需精度的小数位数
花费的时间、微调的超参数数量和所需的准确性取决于您、数据集和手头的项目。由于超参数是相互关联的,因此不需要全部修改。微调较小的范围可能会导致更好的结果。
现在您已经了解了决策树和决策树超参数的基础知识,是时候应用您所学的知识了。
小费
决策树超参数太多,无法始终使用它们。根据我的经验,max_depth、max_features、min_samples_leaf、max_leaf_nodes、min_impurity_decrease和min_samples_split通常就足够了。
预测心脏病——案例研究
你已经一家医院要求使用机器学习来预测心脏病。您的工作是开发一个模型并突出显示医生和护士可以专注于改善患者健康的两到三个重要特征。
您决定使用带有微调超参数的决策树分类器。建立模型后,您将使用feature_importances_解释结果,这是一个属性决定了预测心脏病的最重要特征。
心脏病数据集
心脏病数据集已作为 heart_disease.csv上传到 GitHub 。这是对 UCI 机器学习存储库 ( https ://archive.ics.uci. edu/ml/index.php)为您的方便清理了空值。
上传文件并显示前五行如下:
df_heart = pd.read_csv('heart_disease.csv')
df_heart.head()上述代码生成下表:
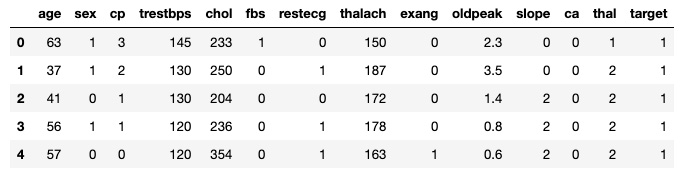
图 2.8 – heart_disease.csv 输出
方便地标记为“目标”的目标列是二进制的,1表示患者患有心脏病,0表示他们没有。
以下是预测变量列的含义,取自之前链接的数据源:
-
age:年龄
-
sex:性别(1 = 男性;0 = 女性)
-
cp:胸痛类型(1 = 典型心绞痛,2 = 非典型心绞痛,3 = 非心绞痛,4 = 无症状)
-
chol : 血清胆固醇 mg/dl 6 fbs: (空腹血糖 > 120 mg/dl) ( 1 = true; 0 = false)
-
fbs:空腹血糖 > 120 mg/dl(1 = 真;0 = 假)
-
restecg:静息心电图结果(0 = 正常,1 = ST-T 波异常(T 波倒置和/或 ST 抬高或压低 > 0.05 mV),2 = 显示根据 Estes 标准可能或确定的左心室肥大)
-
thalach : 达到的最大心率
-
exang:运动诱发的心绞痛(1 = 是;0 = 否)
-
oldpeak : 相对于休息,运动引起的 ST 压低
-
slope:峰值运动 ST 段的坡度(1 = 上坡,2 = 平坦,3 = 下坡)
-
ca : 通过透视着色的主要血管数 (0-3)
-
thal:3 = 正常;6 = 固定缺陷;7 = 可逆缺陷
将数据拆分为训练集和测试集,为机器学习做准备:
X = df_heart.iloc[:,:-1]y = df_heart.iloc[:,-1]
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=2)您现在可以进行预测了。
决策树分类器
将cross_val_score与DecisionTreeClassifier一起使用,如下所示:
model = DecisionTreeClassifier(random_state=2)
scores = cross_val_score(model, X, y, cv=5)
print('Accuracy:', np.round(scores, 2))
print('Accuracy mean: %0.2f' % (scores.mean()))
#Accuracy: [0.74 0.85 0.77 0.73 0.7 ]结果如下:
Accuracy mean: 0.76
初始准确率为 76%。让我们看看通过超参数微调可以获得哪些收益。
RandomizedSearch CLF 函数
微调时很多超参数,GridSearchCV可能会花费太多时间。scikit-learn 库提供了RandomizedSearchCV作为一个很好的选择。RandomizedSearchCV的工作方式与GridSearchCV相同,但不是尝试所有超参数,而是尝试随机数量的组合。这并不意味着详尽无遗。它旨在在有限的时间内找到最佳组合。
这是一个使用RandomizedSearchCV返回最佳模型和分数的函数。输入是params(要测试的超参数字典)、runs(要检查的超参数组合的数量)和DecisionTreeClassifier:
def randomized_search_clf(params, runs=20, clf=DecisionTreeClassifier(random_state=2)):
rand_clf = RandomizedSearchCV(clf,params, n_iter=runs,cv=5, n_jobs=-1, random_state=2)
rand_clf.fit(X_train, y_train)
best_model = rand_clf.best_estimator_
best_score = rand_clf.best_score_
print("Training score: {:.3f}".format(best_score))
y_pred = best_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print('Test score: {:.3f}'.format(accuracy))
return best_model选择超参数
没有单一的选择超参数的正确方法。实验是游戏的名称。这是一个初始列表,位于random_search_clf 函数中。选择这些数字的目的是减少差异并尝试扩大范围:
randomized_search_clf(params={'criterion':['entropy', 'gini'],
'splitter':['random', 'best'],
'min_weight_fraction_leaf':[0.0, 0.0025, 0.005, 0.0075, 0.01],
'min_samples_split':[2, 3, 4, 5, 6, 8, 10],
'min_samples_leaf':[1, 0.01, 0.02, 0.03, 0.04],
'min_impurity_decrease':[0.0, 0.0005, 0.005, 0.05, 0.10, 0.15, 0.2],
'max_leaf_nodes':[10, 15, 20, 25, 30, 35, 40, 45, 50, None],
'max_features':['auto', 0.95, 0.90, 0.85, 0.80, 0.75, 0.70],
'max_depth':[None, 2,4,6,8],
'min_weight_fraction_leaf':[0.0, 0.0025, 0.005, 0.0075, 0.01, 0.05]})训练分数:0.798
测试分数:0.855
DecisionTreeClassifier(class_weight=None,
criterion='entropy',
max_depth=8,
max_features=0.8,
max_leaf_nodes=45,
min_impurity_decrease=0.0,
min_impurity_split=None,
min_samples_leaf=0.04,
min_samples_split=10,
min_weight_fraction_leaf=0.05,
presort=False,
random_state=2,
splitter='best')这是一个确定的改进,并且模型在测试集上泛化得很好。让我们看看我们是否可以通过缩小范围做得更好。
缩小范围
例如,使用从最佳模型中选择的 max_depth=8基线,我们可以将范围缩小到7到9。
另一种策略是停止检查默认设置正常的超参数。例如,不建议在'gini'上使用entropy ,因为差异非常小。 min_impurity_split 和 min_impurity_decrease 也可以保留它们的默认值。
这是一个增加了100次运行的新超参数范围:
randomized_search_clf(params={
'max_depth':[None, 6, 7],
'max_features':['auto', 0.78],
'max_leaf_nodes':[45, None],
'min_samples_leaf':[1, 0.035, 0.04, 0.045, 0.05],
'min_samples_split':[2, 9, 10],
'min_weight_fraction_leaf': [0.0, 0.05, 0.06, 0.07],},runs=100)
训练分数:0.802
测试分数:0.868
DecisionTreeClassifier(
class_weight=None,
criterion='gini',
max_depth=7,
max_features=0.78,
max_leaf_nodes=45,
min_impurity_decrease=0.0,
min_impurity_split=None,
min_samples_leaf=0.045,
min_samples_split=9,
min_weight_fraction_leaf=0.06,
presort=False,
random_state=2,
splitter='best')该模型在训练和测试分数上更加准确。
但是,为了获得适当的比较基准,必须将新模型放入 cross_val_clf中。这可以通过复制和粘贴前面的模型来实现:
model = DecisionTreeClassifier(class_weight=None,
criterion='gini', max_depth=7, max_features=0.78,
max_leaf_nodes=45, min_impurity_decrease=0.0,
min_impurity_split=None, min_samples_leaf=0.045,
min_samples_split=9, min_weight_fraction_leaf=0.06,
presort=False, random_state=2, splitter='best')
scores = cross_val_score(model, X, y, cv=5)
print('Accuracy:', np.round(scores, 2))
print('Accuracy mean: %0.2f' % (scores.mean()))
#Accuracy: [0.82 0.9 0.8 0.8 0.78]结果如下:
Accuracy mean: 0.82
这是百分之六点高于默认模型。在预测心脏病方面,更高的准确性可以挽救生命。
feature_importances_
的最后一块谜题是传达机器学习模型最重要的特征。决策树带有一个很好的属性feature_importances_,它就是这样做的。
首先,我们需要确定最佳模型。我们的函数返回了最佳模型,但尚未保存。
测试时,重要的是不要混合和匹配训练集和测试集。然而,在选择了最终模型后,将模型拟合到整个数据集可能是有益的。为什么?因为目标是在从未见过的数据上测试模型,并且在整个数据集上拟合模型可能会导致准确性的额外提高。
让我们使用最佳超参数定义模型并将其拟合到整个数据集:
best_clf = DecisionTreeClassifier(class_weight=None, criterion='gini',
max_depth=9,max_features=0.8, max_leaf_nodes=47,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=8,
min_weight_fraction_leaf=0.05, presort=False,
random_state=2, splitter='best')
best_clf.fit(X, y)为了确定最重要的特征,我们可以在best_clf上运行feature_importances_ 属性:
best_clf.feature_importances_
# array([0.04826754, 0.04081653, 0.48409586, 0.00568635, 0., 0., 0., 0.00859483, 0., 0.02690379, 0., 0.18069065, 0.20494446])解释这些结果并不容易。以下代码将列与最重要的列一起压缩将特征放入字典中,然后以相反的顺序显示它们以获得易于解释的干净输出:
feature_dict = dict(zip(X.columns, best_clf.feature_importances_))
# Import operator import operator
Sort dict by values (as list of tuples)sorted(feature_dict.items(), key=operator.itemgetter(1), reverse=True)[0:3]
[('cp', 0.4840958610240171),
('thal', 0.20494445570568706),
('ca', 0.18069065321397942)]三个最重要的特征如下:
-
'cp':胸痛类型(1 = 典型心绞痛,2 = 非典型心绞痛,3 = 非心绞痛,4 = 无症状)
-
'thalach' : 达到的最大心率
-
'ca' : 通过透视着色的主要血管数 (0-3)
这些数字可以解释为它们对方差的解释,因此“cp”占方差的 48%,比“thal”和“ca”加起来还要多。
您可以告诉医生和护士,您的模型以 82% 的准确率预测患者是否患有心脏病使用胸痛、最大心率和透视作为三个最重要的特征。
概括
在本章中,您通过检查决策树(主要的 XGBoost 基础学习器)在掌握 XGBoost 方面取得了巨大飞跃。您通过使用GridSearchCV和RandomizedSearchCV微调超参数来构建决策树回归器和分类器。您可视化了决策树,并根据方差和偏差分析了它们的错误和准确性。此外,您还了解了一个不可或缺的工具feature_importances_,它用于传达模型中最重要的特征,这也是 XGBoost 的一个属性。
在下一章中,您将学习如何构建随机森林,这是我们的第一个集成方法,也是 XGBoost 的竞争对手。随机森林的应用对于理解 bagging 和 boosting 之间的区别、生成与 XGBoost 相当的机器学习模型以及了解促进 XGBoost 发展的随机森林的局限性非常重要。

















 1200
1200











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











