






🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
数据泛滥已不再是新闻。每天,人和设备都在创建大量数据。文本数据绝对是人类产生的主要数据类型之一。人们每天撰写数百万条评论、产品评论、Reddit 消息和推文。这些数据对于研究和商业来说都非常有价值。由于创建这些数据的规模,我们使用它的方法已经改变。
NLP 的大部分原始研究都是在包含数百或数千个文档的小型数据集上完成的。您可能认为构建 NLP 应用程序会更容易,因为我们有更多的文本数据可以用来构建更好的模型。然而,这些文本具有不同的语用和种类,因此从数据科学的角度来看,利用它们更加复杂。从软件工程的角度来看,大数据带来了许多挑战。结构化数据具有可预测的大小和组织,这使得更容易有效地存储和分发。文本数据的一致性要差得多。这使得并行化和分配工作变得更加重要,并且可能更加复杂。Spark 等分布式计算框架帮助我们应对这些挑战和复杂性。
在本章中,我们将讨论 Apache Spark 和 Spark NLP。首先,我们将介绍一些有助于我们理解分布式计算的基本概念。然后,我们将简要谈谈分布式计算的历史。我们将讨论 Spark 中的一些重要模块——Spark SQL和MLlib。这将为我们提供详细讨论 Spark NLP 所需的背景和背景。
现在,我们将介绍一些有助于理解 Spark 工作原理的技术概念。解释将是高级别的。如果您对最大化性能感兴趣,我建议您更多地研究这些主题。对于普通读者,我希望本材料能够为您提供必要的直觉,帮助您在设计和构建基于 Spark 的应用程序时做出决策。
并行、并发、分布式计算
让我们从定义一些术语开始。一个进程可以被认为是一个正在运行的程序。进程使用分配的内存部分(也称为内存空间)执行其代码。线程是操作系统可以调度的进程中的一系列执行步骤。在进程之间共享数据通常需要在不同的内存空间之间复制数据。当 Java 或 Scala 程序运行时,Java 虚拟机 (JVM)就是进程。进程的线程共享对同一内存空间的访问,它们同时访问。
数据的并发访问可能很棘手。例如,假设我们要生成字数。如果有两个线程在这个进程上工作,我们就有可能得到错误的计数。考虑以下程序(用伪 Python 编写)。在这个程序中,我们将使用一个线程池。线程池是一种将分区工作与调度分开的方法。我们分配了一定数量的线程,然后我们通过我们的数据为池请求线程。然后操作系统可以安排工作。
def word_count(tokenized_documents): # 标记列表列表
word_counts = {}
thread_pool = ThreadPool()
i = 0
for thread in thread_pool
run thread:
while i < len(tokenized_documents):
doc = tokenized_documents[i]
i += 1
for token in doc:
old_count = word_counts.get(token, 0)
word_counts[token] = old_count + 1
return word_counts这看起来很合理,但是我们看到下面的代码run thread引用了共享内存空间中的数据,例如iand word_counts。表 3-1显示了这个程序的执行,从第 6 行开始有两个threads 。ThreadPool
表 3-1。两个threads 在ThreadPool
| time | thread1 | thread2 | i | valid_state |
|---|---|---|---|---|
| 0 | while i < len(tokenized_documents) | 0 | yes | |
| 1 | while i < len(tokenized_documents) | 0 | yes | |
| 2 | doc = tokenized_documents[i] | 0 | yes | |
| 3 | doc = tokenized_documents[i] | 0 | NO |
在时间 3,thread2将检索tokenized_documents[0],而thread1已经设置为处理第一个文档。这个程序有一个竞争条件,根据不同线程中完成的操作顺序,我们可能会得到不正确的结果。避免这些问题通常涉及编写对并发访问安全的代码。例如,我们可以暂停直到完成更新thread2thread1 锁定tokenized_documents。_ 如果您查看代码,还有另一个竞争条件 on i。如果thread1获取最后一个文档,tokenized_documents[N-1],thread2开始其 while 循环检查,thread1更新i,然后thread2使用i。我们将访问tokenized_documents[N]不存在的 。所以让我们锁定i。
def word_count(tokenized_documents): # list of lists of tokens
word_counts = {}
thread_pool = ThreadPool()
i = 0
for thread in thread_pool:
run thread:
while True:
lock i:
if i < len(tokenized_documents)
doc = tokenized_documents[i]
i+= 1
else:
break
for token in doc:
lock word_counts:
old_count = word_counts.get(token, 0)
word_counts[token] = old_count + 1
return word_counts现在,我们正在锁定i并检查i循环。我们还锁定,word_counts这样如果两个线程想要更新同一个单词的计数,它们就不会意外拉出一个陈旧的值old_count。表 3-2显示了从第 7 行开始执行的程序。
表 3-2。锁定i和word_counts
| time | thread1 | thread2 | i | valid state |
|---|---|---|---|---|
| 0 | lock i | 0 | yes | |
| 1 | if i < len(tokenized_documents) | blocked | 0 | yes |
| 2 | doc = tokenized_documents[i] | blocked | 0 | yes |
| 3 | i += 1 | blocked | 0 | yes |
| 4 | lock i | 1 | yes | |
| 5 | lock word_counts | 1 | yes | |
| 6 | if i < len(tokenized_documents) | 1 | yes | |
| 7 | old_count = word_counts.get(token, 0) | 1 | yes | |
| 8 | doc = tokenized_documents[i] | 1 | yes | |
| 9 | word_counts[token] = old_count + 1 | 1 | yes | |
| 10 | i += 1 | 1 | yes | |
| 11 | lock word_counts | 2 | yes | |
| 12 | old_count = word_counts.get(token, 0) | blocked | 2 | yes |
| 13 | word_counts[token] = old_count + 1 | blocked | 2 | yes |
| 14 | lock word_counts | 2 | yes | |
| 15 | blocked | old_count = word_counts.get(token, 0) | 2 | yes |
| 16 | blocked | word_counts[token] = old_count + 1 | 2 | yes |
我们解决了这个问题,但代价是经常阻塞其中一个线程。这意味着我们从并行性中获得的优势越来越少。最好设计我们的算法,使线程不共享状态。当我们谈论 MapReduce 时,我们将看到一个这样的例子。
有时,在一台机器上并行化是不够的,所以我们将工作分布在集群中的多台机器上. 当所有工作都在机器上完成时,我们将数据(在内存或磁盘上)带到代码中,但在分配工作时,我们将代码带到数据中。跨集群分配程序的工作意味着我们有新的担忧。我们无法访问共享内存空间,因此我们需要在设计算法时更加深思熟虑。尽管不同机器上的进程不共享公共内存空间,但我们仍然需要考虑并发性,因为集群给定机器上的进程线程仍然共享公共(本地)内存空间。幸运的是,像 Spark 这样的现代框架主要解决了这些问题,但在设计程序时牢记这一点仍然是件好事。
处理文本数据的程序通常会发现某种形式的并行化很有帮助,因为将文本处理成结构化数据通常是程序中最耗时的阶段。大多数 NLP 管道最终都会输出结构化的数字数据,这意味着加载的数据(文本)通常会比输出的数据大得多。不幸的是,由于 NLP 算法的复杂性,分布式框架中的文本处理通常仅限于基本技术。幸运的是,我们有 Spark NLP,我们将在稍后讨论。
Apache Hadoop 之前的并行化
HTCondor是威斯康星大学麦迪逊分校于 1988 年开始开发的框架。它拥有令人印象深刻的使用目录。它被 NASA、人类基因组计划和大型强子对撞机使用。从技术上讲,它不仅仅是一个分配计算的框架——它还可以管理资源。事实上,它可以与其他框架一起用于分布式计算。它的构建理念是集群中的机器可能由不同的用户拥有,因此可以根据可用资源安排工作。这是从计算机集群不可用的时候开始的。
GNU parallel和pexec是 UNIX 工具,可用于在单台机器上以及跨机器上并行工作。这要求工作的可分发部分从命令行运行。这些工具允许我们跨机器利用资源,但它无助于并行化我们的算法。
MapReduce 和 Apache Hadoop
我们可以用两个操作来表示分布式计算:map和reduce。该map操作可用于转换、过滤或排序数据。该reduce操作可用于对数据进行分组或汇总。让我们回到我们的字数统计示例,看看我们如何将这两个操作用于基本的 NLP 任务。
def map(docs):
for doc in docs:
for token in doc:
yield (token, 1)
def reduce(records):
word_counts = {}
for token, count in records:
word_counts[token] = word_counts.get(token, 0) + count
for word, count in word_counts.items():
yield (word, count)数据被加载到分区中,一些文档进入mapper集群上的每个进程。mapper每台机器可以有多个s。每个人都在他们的文档上mapper运行该map函数并将结果保存到磁盘。在所有的mappers 完成后,来自 mapper 阶段的数据被打乱,所有具有相同键(word在这种情况下)的记录都在同一个分区中。现在对这些数据进行排序,以便在一个分区内,所有记录都按键排序。最后,加载排序后的数据,并reduce为每个分区reducer过程调用该步骤,并结合所有计数。在阶段之间,数据被保存到磁盘。
MapReduce 可以表达大多数分布式算法,但在这个框架中有些算法很难或非常笨拙。这就是为什么 MapReduce 的抽象开发得相当快的原因。
Apache Hadoop是 MapReduce 的流行开源实现以及分布式文件系统,Hadoop 分布式文件系统 (HDFS)。要编写 Hadoop 程序,您需要选择或定义输入格式、映射器、reducer 和输出格式。已经有许多库和框架允许更高级别的程序实现。
Apache Pig是一个用于在过程代码中表达 MapReduce 程序的框架。它的程序性质使得实现提取、转换、加载 (ETL)程序非常方便和直接。但是,其他类型的程序,例如模型训练程序,难度要大得多。Apache Pig 使用的语言称为Pig Latin。与 SQL 有一些重叠,所以如果有人熟悉 SQL,学习 Pig Latin 很容易。
Apache Hive是一个最初建立在 Hadoop 之上的数据仓库框架。Hive 允许用户编写使用 MapReduce 执行的 SQL。现在,Hive 可以使用除 Hadoop 之外的其他分布式框架运行,包括 Spark。
Apache Spark
Spark是由 Matei Zaharia 发起的一个项目。Spark 是一个分布式计算框架。Spark 和 Hadoop 处理数据的方式存在重要差异。Spark 允许用户针对分布式数据编写任意代码。目前,在 Scala、Java、Python 和 R 中有 Spark 的官方 API。Spark 不会将中间数据保存到磁盘。通常,基于 Spark 的程序会将数据保存在内存中,尽管这可以通过配置进行更改以利用磁盘。这允许更快的处理,但可能需要更多的横向扩展(更多的机器)或更多的纵向扩展(具有更多内存的机器)。
让我们看一下word_countSpark。
Apache Spark 的架构
Spark 围绕运行程序的驱动程序、管理资源和分配工作的主服务器以及执行计算的工作人员进行组织。有许多可能的主人。Spark 附带了自己的 master,这是在独立和本地模式下使用的。您还可以使用 Apache YARN 或 Apache Mesos。根据我的经验,Apache YARN 是企业系统最常见的选择。
让我们更详细地了解一下 Spark 的架构。
物理架构
我们在提交申请的提交机器上启动我们的程序。此驱动程序在客户端计算机上运行应用程序并将作业发送到火花大师要分发给工人。spark master 可能不是完全独立的机器。那台机器也可能在集群上工作,因此也可能是工作人员。此外,您可能正在 spark master 上运行程序,因此它也可能是客户端计算机。
您可以使用两种模式来启动 Spark 应用程序:集群模式和客户端模式。如果提交应用程序的机器与运行应用程序的机器是同一台机器,则您处于客户端模式,因为您是从客户端机器提交的。否则,您处于集群模式。通常,如果您的机器在集群内,则使用客户端模式,如果不在集群内,则使用集群模式(参见图3-1和 3-2)。
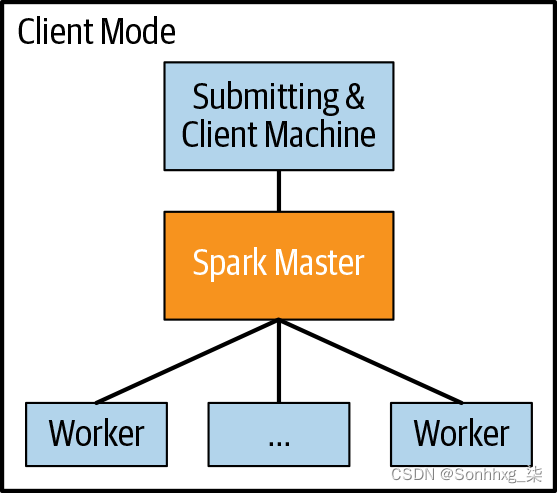
图 3-1。物理架构(客户端模式)
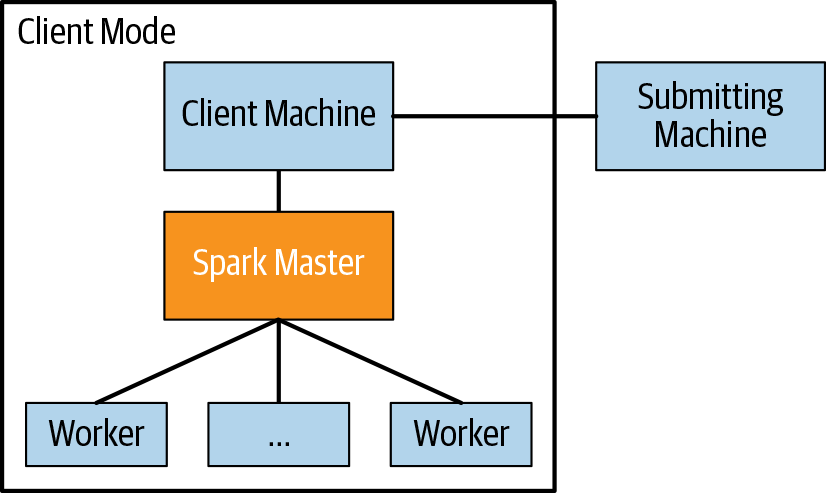
图 3-2。物理架构(集群模式)
您还可以在本地模式下运行 Spark,顾名思义,客户端机器、spark master 和 worker 都是同一台机器。这对于开发和测试 Spark 应用程序非常有用。如果您想在一台机器上并行工作,它也很有用。
现在我们已经了解了物理架构,让我们看看逻辑架构。
逻辑架构
在查看 Spark 的逻辑架构时,我们将客户端机器、spark master 和 worker 视为不同的机器(见图 3-3)。驱动程序是将工作提交给 spark master 的 JVM 进程。如果程序是 Java 或 Scala 程序,那么它也是运行程序的进程。如果程序是 Python 或 R 语言,则驱动程序进程是与运行程序的进程不同的进程。
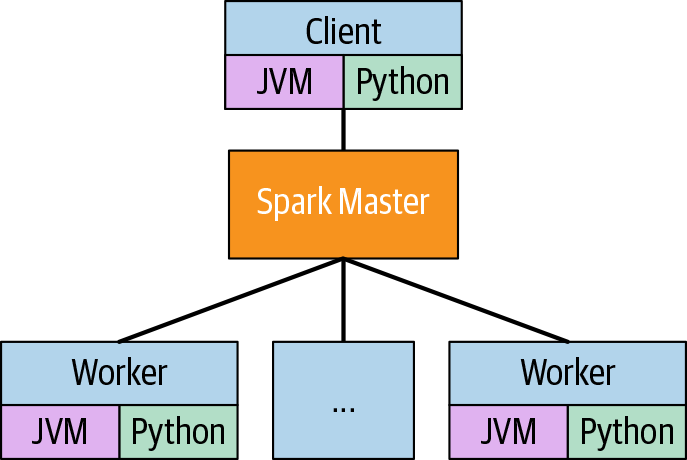
图 3-3。逻辑架构
worker 上的 JVM 进程称为executors。要完成的工作在驱动程序上定义并提交给 spark master,由它协调 executor 来完成工作。了解 Spark 的下一步是了解数据的分布方式。
分区
在 Spark 中,数据在集群中进行分区。分区通常比执行者多。这允许使用每个执行程序上的每个线程。Spark 会将RDD整个集群中的数据平均分配到默认数量的分区中。我们可以指定分区的数量,我们可以指定一个字段来分区。当您的算法需要一定程度的局部性时,这可能非常有用——例如,拥有来自单个用户的所有推文。
序列化
发送到数据的任何代码都应该只引用可序列化的对象。NotSerializableException错误很常见,对于 Spark 新手来说几乎是难以理解的。当我们映射 a 时RDD,我们正在创建 aFunction并将其与数据一起发送到机器。函数是定义它的代码,以及定义中所需的数据。第二部分称为函数的闭包。确定一个函数需要哪些对象是一项复杂的任务,有时可以捕获无关的对象。如果您在可序列化方面遇到问题,有几个可能的解决方案。以下问题可以帮助您找到正确的解决方案:
- 您是否使用自己的自定义类?确保它们是可序列化的。
- 你在加载资源吗?也许您的分布式代码应该延迟加载它,以便将其加载到每个执行程序上,而不是加载到驱动程序上并运送到执行程序。
- Spark 对象 (
SparkSession,RDDs) 是否在闭包中被捕获?当您匿名定义函数时,可能会发生这种情况。如果你的函数是匿名定义的,也许你可以在别处定义它。
这些提示可以帮助查找常见错误,但解决此问题的方法只能根据具体情况确定。
订购
处理分布式数据时,数据中的项目不一定有保证的顺序。编写代码时,请记住数据存在于整个集群的分区中。
这并不是说我们不能定义一个顺序。我们可以通过索引在分区上定义顺序。在这种情况下,“第一个”元素RDD将是第一个分区的第一个元素。此外,假设我们RDD[Int]要按值排序。使用我们对分区的排序,我们可以打乱数据,使得 partition 中的所有元素i都小于partition 中的所有元素i+1。从这里,我们可以对每个分区进行排序。现在我们有一个排序的RDD. 然而,这是一项昂贵的操作。
输出和记录
在编写用于转换数据的函数时,打印语句或最好记录语句以查看函数中变量的状态通常很有用。在分布式环境中,这更复杂,因为函数与程序不在同一台机器上运行。访问日志stdout通常取决于集群的配置以及您使用的主服务器。在某些情况下,以本地模式在一小部分数据上运行程序可能就足够了。
Spark jobs
基于 Spark 的程序将有一个SparkSession,这是驱动程序与主设备对话的方式。在 Spark 版本 2.x 之前,SparkContext用于此目的。仍然存在SparkContext,但它是SparkSession现在的一部分。这SparkSession代表App.App提交给jobs主人。被jobs分成stages,它们是 中工作的逻辑分组job。被stages分成tasks,代表每个分区上要完成的工作(见图 3-4)。
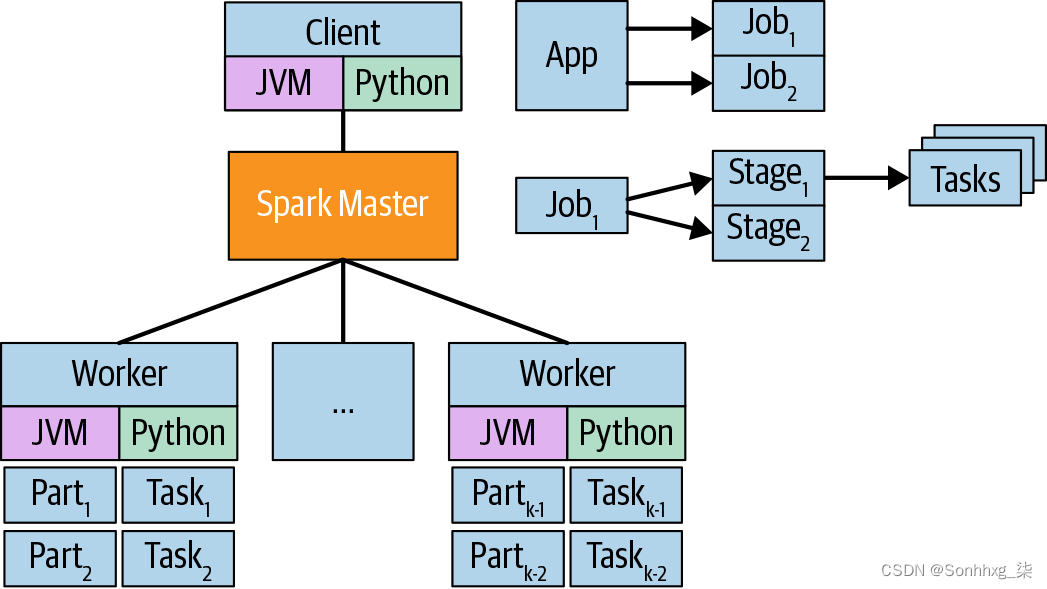
图 3-4。Spark jobs
并非对数据的每个操作都会启动一项工作。Spark 是懒惰的——以一种很好的方式。仅在需要结果时才执行。这允许将完成的工作组织到执行计划中以提高效率。某些操作,有时称为操作,会立即导致执行。这些是返回特定值的操作,例如aggregate. 还有一些操作在计算之前无法进行进一步的执行计划,例如zipWithIndex。
这个执行计划通常被称为有向无环图(DAG)。Spark 中的数据由其 DAG 定义,其中包括其源以及为生成它而运行的任何操作。这允许 Spark 根据需要从内存中删除数据,而不会丢失对数据的引用。如果稍后引用生成和删除的数据,它将重新生成。这可能很耗时。幸运的是,如果需要,我们可以指示 Spark 保留数据。
Persisting (坚持)
在 Spark 中持久化数据的基本方式是使用persist方法。这将创建一个检查点。您还可以使用该cache方法并提供选项来配置数据的持久化方式。数据仍然会懒惰地生成,但是一旦生成,就会被保留。
让我们看一个例子:
from operator import concat, itemgetter, methodcaller
import os
from time import sleep
import pyspark
from pyspark import SparkConf
from pyspark.sql import SparkSession
from pyspark.sql import functions as fun
from pyspark.sql.types import *
packages = ','.join([
"com.johnsnowlabs.nlp:spark-nlp_2.11:2.4.5",
])
def has_moon(text):
if 'moon' in text:
sleep(1)
return True
else:
return False
# RDD containing filepath-text pairs
path = os.path.join('data', 'mini_newsgroups', 'sci.space')
text_pairs = spark.sparkContext\
.wholeTextFiles(path)
texts = text_pairs.map(itemgetter(1))
lower_cased = texts.map(methodcaller('lower'))
moon_texts = texts.filter(has_moon).persist()
print('This appears quickly because the previous operations are '
'all lazy')
print(moon_texts.count())
print('This appears slowly since the count method will call '
'has_moon which sleeps')
print(moon_texts.reduce(concat)[:100])
print('This appears quickly because has_moon will not be '
'called due to the data being persisted')This appears quickly because the previous operations are all lazy
11
This appears slowly since the count method will call has_moon which
sleeps
Newsgroups: sci.space
Path: cantaloupe.srv.cs.cmu.edu!das-news.harvard.edu!noc.near.net!
uunet!zaphod
This appears quickly because has_moon will not be called due to the
data being persisted现在我们已经了解了 Spark 的工作原理,让我们回到我们的字数问题。
from collections import Counter
from operator import add
from nltk.tokenize import RegexpTokenizer
# RDD 包含文件路径-文本对
texts = spark.sparkContext.wholeTextFiles(path)
print('\n\nfilepath-text pair of first document')
print(texts.first())
tokenizer = RegexpTokenizer(r'\w+', gaps=False)
tokenized_texts = texts.map(
lambda path_text: tokenizer.tokenize(path_text[1]))
print('\n\ntokenized text of first document')
print(tokenized_texts.first())
# 这是之前实现的等效位置
# 开始
document_token_counts = tokenized_texts.map(Counter)
print('\n\ndocument-level counts of first document')
print(document_token_counts.first().most_common(10))
word_counts = token_counts = document_token_counts.reduce(add)
print('\n\nword counts')
print(word_counts.most_common(10))filepath-text pair of first document
('file:/.../spark-nlp-book/data/mini_news...')
tokenized text of first document
['Xref', 'cantaloupe', 'srv', 'cs', 'cmu', ..., 'cantaloupe', 'srv']
document-level counts of first document
[('the', 13), ('of', 7), ('temperature', 6), ..., ('nasa', 4)]
word counts
[('the', 1648), ('of', 804), ..., ('for', 305), ('cmu', 288)]如您所见,我们在这里使用mapandreduce方法。Spark 允许您实现 MapReduce 风格的程序,但您也可以通过许多其他方式实现。
Python 和 R
Spark 主要在 Scala 中实现。Java API 允许更多地道的 Java 使用 Spark。还有一个 Python API (PySpark) 和一个 R API (SparkR)。在 Scala 或 Java 中实现的基于 Spark 的程序在作为驱动程序的同一 JVM 上运行。在 PySpark 或 SparkR 中实现的程序分别在 Python 和 R 进程中运行,SparkSession最终在不同的进程中。这通常不会影响性能,除非我们使用 Python 或 R 中定义的函数。
从前面的示例中可以看出,当我们对计数进行标记、计数和组合时,我们正在调用 Python 代码来处理我们的数据。这是通过 JVM 进程将数据序列化并将数据传送到 Python 进程来完成的,然后对 Python 进程进行反序列化、处理、序列化并传送回 JVM 进行反序列化。这给我们的工作增加了很多额外的工作。使用 PySpark 或 SparkR 时,尽可能使用内部 Spark 函数会更快。
在使用 s 时,不使用 Python 或 R 中的自定义函数似乎有限制RDD,但最有可能的是,您的工作将使用DataFrames DataSets,我们将在下一节中讨论.
Spark SQL 和 Spark MLlib
自 Spark 2 发布以来,在 Spark 中处理数据的主要预期方式是通过Dataset. Dataset[T]是一个允许我们将分布式数据视为表格的对象。type 参数T是用来表示表格行的类型。有一种特殊Dataset的类型,其中行的类型是Row,它允许我们在不定义新类的情况下拥有表格数据——这确实是以失去一些类型安全为代价的。我们将使用的示例通常与DataFrames 一起使用,因为它们是在 PySpark 中处理数据的最佳方式。
和在 Spark SQL 模块Dataset中DataFrame定义,因为最大的好处之一是能够用 SQL 表达许多操作。预构建的用户定义函数 (UDF)在所有 API 中都可用。这使我们能够以与使用 Scala 或 Java 相同的效率在非 JVM 语言中进行大多数类型的处理。
在开始讨论 Spark NLP 之前,我们需要介绍的另一个模块是 MLlib。MLlib是用于在 Spark 上进行机器学习的模块。在 Spark 2 之前,所有的 MLlib 算法都是在RDDs 上实现的。从那时起,使用Datasets 和DataFrames 定义了一个新版本的 MLlib。MLlib 在设计上与其他机器学习库在高层次上相似,具有转换器、模型和管道的概念。
在我们讨论 MLlib 之前,让我们将一些数据加载到 aDataFrame中,因为 MLlib 是使用DataFrames 构建的。我们将使用Iris 数据集,该数据集通常用作数据科学中的示例。它体积小,易于理解,可用于聚类和分类示例。它是结构化数据,因此它不会为我们提供任何可使用的文本数据。类表结构通常是围绕结构化数据设计的,因此这些数据将帮助我们在开始使用 Spark 处理文本之前探索 API。
该iris.data文件没有标题,因此我们必须在加载时告诉 Spark 列是什么。让我们构建一个模式。架构是DataFrame. _ 最常见的任务是建立一个模型,根据其萼片和花瓣预测鸢尾花的类别(I. virginica、I. setosa 或 I. versicolor)。
from pyspark.sql.types import *
schema = StructType([
StructField('sepal_length', DoubleType(), nullable=False),
StructField('sepal_width', DoubleType(), nullable=False),
StructField('petal_length', DoubleType(), nullable=False),
StructField('petal_width', DoubleType(), nullable=False),
StructField('class', StringType(), nullable=False)
])现在我们已经创建了模式,我们可以加载我们的 CSV。表 3-3显示了数据的汇总。
iris = spark.read.csv('./data/iris/iris.data', schema=schema)
iris.describe().toPandas()| summary | sepal_length | sepal_width | petal_length | petal_width | class | |
|---|---|---|---|---|---|---|
| 0 | count | 150 | 150 | 150 | 150 | 150 |
| 1 | mean | 5.843 | 3.054 | 3.759 | 1.199 | None |
| 2 | stddev | 0.828 | 0.434 | 1.764 | 0.763 | None |
| 3 | min | 4.3 | 2.0 | 1.0 | 0.1 | Iris-setosa |
| 4 | max | 7.9 | 4.4 | 6.9 | 2.5 |
让我们从查看数据中的类别(鸢尾花的种类)开始(参见表 3-4)。
iris.select('class').distinct().toPandas()| class | |
|---|---|
| 0 | Iris-virginica |
| 1 | Iris-setosa |
| 2 | Iris-versicolor |
让我们首先查看Iris setosa类的一些摘要统计信息,如表 3-5所示。
iris.where('class = "Iris-setosa"').drop('class').describe().toPandas()| summary | sepal_length | sepal_width | petal_length | petal_width | |
|---|---|---|---|---|---|
| 0 | count | 50 | 50 | 50 | 50 |
| 1 | mean | 5.006 | 3.418 | 1.464 | 0.244 |
| 2 | stddev | 0.352 | 0.381 | 0.174 | 0.107 |
| 3 | min | 4.3 | 2.3 | 1.0 | 0.1 |
| 4 | max | 5.8 | 4.4 | 1.9 | 0.6 |
我们可以注册一个DataFrame,这将允许我们纯粹通过 SQL 与它进行交互。我们将注册我们DataFrame的临时表。这意味着该表将仅在 our 的生命周期内存在App,并且只能通过 our 获得App(SparkSession参见表3-6)。
iris.registerTempTable('iris')spark.sql('''
SELECT *
FROM iris
LIMIT 5
''').toPandas()| 萼片长度 | 萼片宽度 | 花瓣长度 | 花瓣宽度 | class | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
让我们看一下表 3-7中按类分组的一些字段。
spark.sql('''
SELECT
class,
min(sepal_length), avg(sepal_length), max(sepal_length),
min(sepal_width), avg(sepal_width), max(sepal_width),
min(petal_length), avg(petal_length), max(petal_length),
min(petal_width), avg(petal_width), max(petal_width)
FROM iris
GROUP BY class
''').toPandas()| 班级 | Iris-virginica | Iris-setosa | Iris-versicolor |
|---|---|---|---|
| min(sepal_length) | 4.900 | 4.300 | 4.900 |
| avg(sepal_length) | 6.588 | 5.006 | 5.936 |
| max(sepal_length) | 7.900 | 5.800 | 7.000 |
| min(sepal_width) | 2.200 | 2.300 | 2.000 |
| mean(sepal_width) | 2.974 | 3.418 | 2.770 |
| max(sepal_width) | 3.800 | 4.400 | 3.400 |
| min(petal_length) | 4.500 | 1.000 | 3.000 |
| mean(petal_length) | 5.552 | 1.464 | 4.260 |
| max(petal_length) | 6.900 | 1.900 | 5.100 |
| min(petal_length) | 1.400 | 0.100 | 1.000 |
| mean(petal_length) | 2.026 | 0.244 | 1.326 |
| max(petal_length) | 2.500 | 0.600 | 1.800 |
Transformers
ATransformer是一种无需从数据中学习或拟合任何内容即可转换数据的逻辑。理解转换器的一个好方法是,它们代表我们希望映射到数据上的函数。管道的所有阶段都有参数,因此我们可以确保将转换应用于正确的字段并具有所需的配置。让我们看几个例子。
SQLTransformer
SQLTransformer仅有一个参数——这statement是将针对我们的DataFrame. 让我们使用 anSQLTransformer来执行我们之前执行的 group-by。结果如表 3-8所示。
from pyspark.ml.feature import SQLTransformer
statement = '''
SELECT
class,
min(sepal_length), avg(sepal_length), max(sepal_length),
min(sepal_width), avg(sepal_width), max(sepal_width),
min(petal_length), avg(petal_length), max(petal_length),
min(petal_width), avg(petal_width), max(petal_width)
FROM iris
GROUP BY class
'''
sql_transformer = SQLTransformer(statement=statement)sql_transformer.transform(iris).toPandas()| class | Iris-virginica | Iris-setosa | Iris-versicolor |
|---|---|---|---|
| min(sepal_length) | 4.900 | 4.300 | 4.900 |
| mean(sepal_length) | 6.588 | 5.006 | 5.936 |
| max(sepal_length) | 7.900 | 5.800 | 7.000 |
| ... |
我们得到与运行 SQL 命令时相同的输出。
SQLTransformer当您需要在管道中的其他步骤之前对数据执行预处理或重组时,它非常有用。现在让我们看一个转换器,它在一个字段上工作并返回带有新字段的原始数据。
Binarizer
将阈Binarizer值Transformer应用于数值字段,将其转换为0s(低于阈值时)和1s(高于阈值时)。它需要三个参数:
inputCol :要二值化的列
outputCol :包含二值化值的列
threshold :我们将应用的阈值
表 3-9显示了结果。
from pyspark.ml.feature import Binarizer
binarizer = Binarizer(
inputCol='sepal_length',
outputCol='sepal_length_above_5',
threshold=5.0
)binarizer.transform(iris).limit(5).toPandas()| 萼片长度 | ... | class | sepal_length_above_5 | |
|---|---|---|---|---|
| 0 | 5.1 | ... | Iris-setosa | 1.0 |
| 1 | 4.9 | ... | Iris-setosa | 0.0 |
| 2 | 4.7 | ... | Iris-setosa | 0.0 |
| 3 | 4.6 | ... | Iris-setosa | 0.0 |
| 4 | 5.0 | ... | Iris-setosa | 0.0 |
与 不同的是SQLTransformer,Binarizer返回输入的修改版本DataFrame。几乎所有Transformer的 s 都以这种方式行事。
Binarizer用于将实值属性转换为类时。例如,如果我们想将社交媒体帖子标记为“病毒”和“非病毒”,我们可以Binarizer在 views 属性上使用 a。
向量汇编器
另一个进口Transformer是VectorAssembler. 它采用数值列和向量值列的列表并构造单个向量。这很有用,因为所有 MLlib 的机器学习算法都需要一个单一的向量值输入列来表示特征。VectorAssembler接受两个参数:
inputCols :要组装的列列表
outputCol :包含新向量的列
from pyspark.ml.feature import VectorAssembler
assembler = VectorAssembler(
inputCols=[
'sepal_length', 'sepal_width',
'petal_length', 'petal_width'
],
outputCol='features'
)让我们持久化这些数据(见表 3-10)。
iris_w_vecs = assembler.transform(iris).persist()
iris_w_vecs.limit(5).toPandas()| 萼片长度 | 萼片宽度 | 花瓣长度 | 花瓣宽度 | class | features | |
|---|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa | [5.1, 3.5, 1.4, 0.2] |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa | [4.9, 3.0, 1.4, 0.2] |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa | [4.7, 3.2, 1.3, 0.2] |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa | [4.6, 3.1, 1.5, 0.2] |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | 虹膜丝滑 | [5.0, 3.6, 1.4, 0.2] |
估计器和模型
Estimators 允许我们创建由我们的数据通知的转换。分类模型(例如,决策树)和回归模型(例如,线性回归)是突出的例子,但一些预处理算法也是如此。例如,需要首先了解整个词汇表的预处理将是Estimators. Estimator适合 aDataFrame并返回 a ,它Model是一种Transformer。Model由分类器和回归创建的Estimators 是PredictionModels。
这是与scikit-learn类似的设计,不同之处在于在 scikit-learn 中,当我们调用时,fit我们会改变估计器而不是创建新对象。就像在辩论可变性时一样,这有利也有弊。惯用的 Scala 非常喜欢不变性。
让我们看一些Estimators 和Models 的例子。
最小最大缩放器
这MinMaxScaler允许我们将数据缩放到0和之间1。它需要四个参数:
inputCol :要缩放的列
outputCol :包含缩放值的列
max :新的最大值(可选,默认 = 1)
min :新的最小值(可选,默认 = 0)
结果如表3-11所示。
from pyspark.ml.feature import MinMaxScaler
scaler = MinMaxScaler(
inputCol='features',
outputCol='petal_length_scaled'
)scaler_model = scaler.fit(iris_w_vecs)
scaler_model.transform(iris_w_vecs).limit(5).toPandas()| ... | 花瓣长度 | 花瓣宽度 | class | 特征 | 花瓣长度缩放 | |
|---|---|---|---|---|---|---|
| 0 | ... | 1.4 | 0.2 | Iris-setosa | [5.1, 3.5, 1.4, 0.2] | [0.22, 0.63, 0.06... |
| 1 | ... | 1.4 | 0.2 | Iris-setosa | [4.9, 3.0, 1.4, 0.2] | [0.17, 0.42, 0.06... |
| 2 | ... | 1.3 | 0.2 | Iris-setosa | [4.7, 3.2, 1.3, 0.2] | [0.11, 0.5, 0.05... |
| 3 | ... | 1.5 | 0.2 | Iris-setosa | [4.6, 3.1, 1.5, 0.2] | [0.08, 0.46, 0.08... |
| 4 | ... | 1.4 | 0.2 | Iris-setosa | [5.0, 3.6, 1.4, 0.2] | [0.19, 0.667, 0.06... |
请注意,该petal_length_scaled列现在的值介于0和之间1。这可以帮助一些训练算法,特别是那些难以组合不同尺度特征的算法。
字符串索引器
让我们建立一个模型!我们将尝试从其他特征中预测类别,我们将使用决策树。不过,首先,我们必须将目标转换为索引值。
这StringIndexer Estimator会将我们的类值转换为索引。我们希望这样做是为了简化一些下游处理。假设目标是一个数字,实现大多数训练算法会更简单。StringIndexer接受四个参数:
inputCol :要索引的列
outputCol :包含索引值的列
handleInvalid :模型应如何处理估计器未看到的值的策略(可选,default = error)
stringOrderType :如何对值进行排序以使索引具有确定性(可选,default = frequencyDesc)
我们还想要一个IndexToString Transformer. 这将让我们将我们的预测(即索引)映射回字符串值。IndexToString接受三个参数:
inputCol :要映射的列
outputCol :包含映射值的列
labels :从索引到值的映射,通常由StringIndexer
from pyspark.ml.feature import StringIndexer, IndexToString
indexer = StringIndexer(inputCol='class', outputCol='class_ix')
indexer_model = indexer.fit(iris_w_vecs)
index2string = IndexToString(
inputCol=indexer_model.getOrDefault('outputCol'),
outputCol='pred_class',
labels=indexer_model.labels
)iris_indexed = indexer_model.transform(iris_w_vecs)现在我们准备好训练我们的DecisionTreeClassifier. 这Estimator有很多参数,所以我建议您熟悉 API。它们都在PySpark API 文档中有详细记录。表 3-12显示了我们的结果。
from pyspark.ml.classification import DecisionTreeClassifier
dt_clfr = DecisionTreeClassifier(
featuresCol='features',
labelCol='class_ix',
maxDepth=5,
impurity='gini',
seed=123
)dt_clfr_model = dt_clfr.fit(iris_indexed)
iris_w_pred = dt_clfr_model.transform(iris_indexed)
iris_w_pred.limit (5) .toPandas ()| ... | class | 特征 | class_ix | 原始预测 | 可能性 | 预言 | |
|---|---|---|---|---|---|---|---|
| 0 | ... | Iris-setosa | [5.1, 3.5, 1.4, 0.2] | 0.0 | [50.0, 0.0, 0.0] | [1.0, 0.0, 0.0] | 0.0 |
| 1 | ... | Iris-setosa | [4.9, 3.0, 1.4, 0.2] | 0.0 | [50.0, 0.0, 0.0] | [1.0, 0.0, 0.0] | 0.0 |
| 2 | ... | Iris-setosa | [4.7, 3.2, 1.3, 0.2] | 0.0 | [50.0, 0.0, 0.0] | [1.0, 0.0, 0.0] | 0.0 |
| 3 | ... | Iris-setosa | [4.6, 3.1, 1.5, 0.2] | 0.0 | [50.0, 0.0, 0.0] | [1.0, 0.0, 0.0] | 0.0 |
| 4 | ... | Iris-setosa | [5.0, 3.6, 1.4, 0.2] | 0.0 | [50.0, 0.0, 0.0] | [1.0, 0.0, 0.0] | 0.0 |
IndexToString现在我们需要使用我们的(见表 3-13 )将预测的类映射回它们的字符串形式。
iris_w_pred_class = index2string.transform(iris_w_pred)
iris_w_pred_class.limit(5).toPandas()| ... | 班级 | 特征 | class_ix | 原始预测 | 可能性 | 预言 | pred_class | |
|---|---|---|---|---|---|---|---|---|
| 0 | ... | 虹膜丝滑 | [5.1, 3.5, 1.4, 0.2] | 0.0 | [50.0, 0.0, 0.0] | [1.0, 0.0, 0.0] | 0.0 | 虹膜丝滑 |
| 1 | ... | 虹膜丝滑 | [4.9, 3.0, 1.4, 0.2] | 0.0 | [50.0, 0.0, 0.0] | [1.0, 0.0, 0.0] | 0.0 | 虹膜丝滑 |
| 2 | ... | 虹膜丝滑 | [4.7, 3.2, 1.3, 0.2] | 0.0 | [50.0, 0.0, 0.0] | [1.0, 0.0, 0.0] | 0.0 | 虹膜丝滑 |
| 3 | ... | 虹膜丝滑 | [4.6, 3.1, 1.5, 0.2] | 0.0 | [50.0, 0.0, 0.0] | [1.0, 0.0, 0.0] | 0.0 | 虹膜丝滑 |
| 4 | ... | 虹膜丝滑 | [5.0, 3.6, 1.4, 0.2] | 0.0 | [50.0, 0.0, 0.0] | [1.0, 0.0, 0.0] | 0.0 | 虹膜丝滑 |
Evaluators
与 scikit-learn 等库相比,MLlib 中的评估选项仍然有限,但如果您希望创建一个易于运行的计算指标的训练管道,它们会很有用。
在我们的示例中,我们正在尝试解决多类预测问题,因此我们将使用MulticlassClassificationEvaluator.
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
evaluator = MulticlassClassificationEvaluator(
labelCol='class_ix',
metricName='accuracy'
)evaluator.evaluate(iris_w_pred_class)1.0
这似乎太好了。如果我们过拟合怎么办?也许我们应该尝试使用交叉验证来评估我们的模型。在我们这样做之前,让我们将阶段组织成一个管道。
管道
Pipelines是一种特殊的类型,它接受一个s 和sEstimator的列表,并允许我们将它们作为一个单独使用(参见表 3-14)。TransformerEstimatorEstimator
from pyspark.ml import Pipeline
pipeline = Pipeline(
stages=[assembler, indexer, dt_clfr, index2string]
)pipeline_model = pipeline.fit(iris)
pipeline_model.transform(iris).limit(5).toPandas()| ... | class | 特征 | class_ix | 原始预测 | 可能性 | 预言 | pred_class | |
|---|---|---|---|---|---|---|---|---|
| 0 | ... | Iris-setosa | [5.1, 3.5, 1.4, 0.2] | 0.0 | [50.0, 0.0, 0.0] | [1.0, 0.0, 0.0] | 0.0 | Iris-setosa |
| 1 | ... | Iris-setosa | [4.9, 3.0, 1.4, 0.2] | 0.0 | [50.0, 0.0, 0.0] | [1.0, 0.0, 0.0] | 0.0 | Iris-setosa |
| 2 | ... | Iris-setosa | [4.7, 3.2, 1.3, 0.2] | 0.0 | [50.0, 0.0, 0.0] | [1.0, 0.0, 0.0] | 0.0 | Iris-setosa |
| 3 | ... | Iris-setosa | [4.6, 3.1, 1.5, 0.2] | 0.0 | [50.0, 0.0, 0.0] | [1.0, 0.0, 0.0] | 0.0 | Iris-setosa |
| 4 | ... | Iris-setosa | [5.0, 3.6, 1.4, 0.2] | 0.0 | [50.0, 0.0, 0.0] | [1.0, 0.0, 0.0] | 0.0 | Iris-setosa |
交叉验证
现在我们有了 aPipeline和 anEvaluator我们可以创建一个CrossValidator. 本身CrossValidator也是一个. Estimator当我们调用fit时,它将适合我们pipeline的每一折数据,并计算由我们确定的指标Evaluator。CrossValidator接受五个参数:
estimator :待Estimator调
estimatorParamMaps :在超参数网格搜索中尝试的超参数值
evaluator :计算Evaluator指标的
numFolds :将数据拆分成的折叠数
seed :使分裂可重复的种子
我们将在这里制作一个简单的超参数网格,因为我们只对估计我们的模型在它未见过的数据上的表现感兴趣。
from pyspark.ml.tuning import CrossValidator, ParamGridBuilder
param_grid = ParamGridBuilder().\
addGrid(dt_clfr.maxDepth, [5]).\
build()
cv = CrossValidator(
estimator=pipeline,
estimatorParamMaps=param_grid,
evaluator=evaluator,
numFolds=3,
seed=123
)cv_model = cv.fit(iris)现在,我们可以看到模型在三分之二的训练和三分之一的评估时的表现。avgMetricsin包含测试的超参数网格中每个点的折叠指定度量的cv_model平均值。在我们的例子中,网格中只有一个点。
cv_model.avgMetrics[0.9588996659642801]
请记住,95% 的准确率比 100% 更可信。
还有很多其他Transformer的s、Estimators、Models。随着我们的继续,我们将研究更多,但现在,我们还需要讨论一件事——保存我们的管道。
模型序列化
MLlib 允许我们保存Pipelines 以便我们以后可以使用它们。我们也可以保存单个Transformer的 s 和Models,但我们经常希望将 a 的所有阶段保存Pipeline在一起。一般来说,我们使用单独的程序来构建模型和使用模型.
pipeline_model.write().overwrite().save('pipeline.model')! ls pipeline.model/*pipeline.model/metadata:
part-00000 _SUCCESS
pipeline.model/stages:
0_VectorAssembler_45458c77ca2617edd7f6
1_StringIndexer_44d29a3426fb6b26b2c9
2_DecisionTreeClassifier_4473a4feb3ff2cf54b73
3_IndexToString_4157a15742628a489a18自然语言处理库
功能库
功能库是为特定 NLP 任务和技术构建的功能集合。通常,这些函数是在不假设首先使用其他函数的情况下构建的。这意味着像词性 (POS) 标记这样的功能也将执行标记化。这些库非常适合研究,因为实现新功能通常要容易得多。另一方面,由于没有统一的设计,这些库的性能一般比注解库差很多。
自然语言工具包 (NLTK)是一个很棒的功能库。它最初是由 Edward Loper 创建的。具有里程碑意义的 NLP 书籍Natural Language Processing with Python (O'Reilly) 由 Steven Bird、Ewan Klein 和 Edward Loper 撰写。我强烈推荐这本书给任何学习 NLP 的人。NLTK 中有许多有用且有趣的模块。它是并且可能仍然是用于教授 NLP 的最佳 NLP 库。这些功能的实现不一定要考虑运行时性能或其他生产化问题。如果您正在从事研究项目并使用可在单台机器上管理的数据集,您应该考虑使用 NLTK。
注释库
注释库是所有功能都围绕文档注释模型构建的库。注释库需要记住三个对象:文档、注释和注释器。注释库背后的想法是用我们的 NLP 函数的结果来扩充传入的数据。
文档
文档是我们希望处理的一段文本的表示。自然,文档必须包含文本。此外,我们通常希望有一个与每个文档相关联的标识符,以便我们可以将增强数据存储为结构化数据。如果我们正在处理的文本有标题,这个标识符通常是一个标题。
注解 (Annotation)
注释是我们 NLP 函数输出的表示。对于注解,我们需要有一个类型,以便以后的处理知道如何解释注解。注释还需要在文档中存储它们的位置。例如,假设单词“pacing”出现在文档中的 134 个字符中。它将以 134 作为开始,以 140 作为结束。“pacing”的引理注释将具有位置。一些注释库还具有没有位置的文档级注释的概念。将有其他字段,具体取决于类型。像标记这样的简单注释通常没有额外的字段。词干注释通常具有为文本范围提取的词干。
注释器 (Annotator)
注释器是包含使用 NLP 功能的逻辑的对象。注释器通常需要配置或外部数据集。此外,还有基于模型的注释器。注释库的好处之一是注释者可以利用以前的注释者所做的工作。这自然产生了注释器管道的概念。
spaCy
spaCy是一个“工业实力”的 NLP 库。我将给出一个简短的描述,但我鼓励你去阅读他们出色的文档。spaCy 将刚刚描述的文档模型与正在处理的语言(英语、西班牙语等)模型相结合,这使得 spaCy 能够以一种易于开发人员使用的方式支持多种语言。它的大部分功能都是在 Python 中实现的,以达到本机代码的速度。如果您在仅使用 Python 的环境中工作,并且不太可能运行分布式进程,那么 spaCy 是一个不错的选择。
其他库中的 NLP
有一些非 NLP 库具有一些 NLP 功能。它通常在机器学习库中支持对文本数据的机器学习。
scikit-learn
一个 Python 机器学习库,具有从文本中提取特征的功能。此功能通常属于词袋类型的处理。这些流程的构建方式使他们能够轻松利用更多以 NLP 为重点的库。
Lucene
一个 Java 文档搜索框架,具有构建搜索引擎所必需的一些文本处理功能。稍后我们将在讨论信息检索时使用 Lucene。
Gensim
一个主题建模库(它执行其他分布式语义技术)。与 spaCy 一样,它在 Cython 中部分实现,并且与 scikit-learn 一样,它允许在其 API 中进行即插即用的文本处理。
Spark自然语言处理
Spark NLP库最初于 2017 年初设计为 Spark 原生的注释库,以充分利用 Spark SQL 和 MLlib 模块。灵感来自尝试使用 Spark 分发其他 NLP 库,这些库通常没有考虑到并发或分布式计算。
注释库
Spark NLP 与任何其他注释库具有相同的概念,但存储注释的方式不同。大多数注释库将注释存储在文档对象中,但 Spark NLP 为不同类型的注释创建列。
注释器被实现为Transformers、Estimators 和Models。让我们看一些例子。
阶段
Spark NLP 的设计原则之一是与 MLlib 中现有算法的轻松互操作性。因为 MLlib 中没有文档或注释的概念,所以有转换器用于将文本列转换为文档并将注释转换为 vanilla Spark SQL 数据类型。通常的使用模式如下:
- 使用 Spark SQL 加载数据。
- 创建文档列。
- 使用 Spark NLP 进行处理。
- 将感兴趣的注释转换为 Spark SQL 数据类型。
- 运行额外的 MLlib 阶段。
我们已经了解了如何使用 Spark SQL 加载数据以及如何使用标准 Spark 库中的 MLlib 阶段,所以现在我们将看看中间的三个阶段。首先,我们将看看DocumentAssembler(阶段 2)。
Transformers
探索这五个阶段我们将再次使用mini_newsgroups数据集(见表 3-15)。
from sparknlp import DocumentAssembler, Finisher# RDD 包含文件路径-文本对
texts = spark.sparkContext.wholeTextFiles(path)
schema = StructType([
StructField('path', StringType()),
StructField('text', StringType()),
])
texts = spark.createDataFrame(texts, schema=schema)texts.limit(5).toPandas()| 小路 | 文本 | |
|---|---|---|
| 0 | file:/.../spark-nlp-book/data/... | Xref: cantaloupe.srv.cs.cmu.edu sci.astro:3522... |
| 1 | file:/.../spark-nlp-book/data/... | Newsgroups: sci.space\nPath: cantaloupe.srv.cs... |
| 2 | file:/.../spark-nlp-book/data/... | Xref: cantaloupe.srv.cs.cmu.edu sci.space:6146... |
| 3 | file:/.../spark-nlp-book/data/... | Path: cantaloupe.srv.cs.cmu.edu!rochester!udel... |
| 4 | file:/.../spark-nlp-book/data/... | Newsgroups: sci.space\nPath: cantaloupe.srv.cs... |
文档汇编器
DocumentAssembler需要五个参数(见表3-16):
inputCol :包含文档文本的列
outputCol :包含新建文档的列的名称
idCol :包含标识符的列的名称(可选)
metadataCol :Map表示文档元数据的 -type 列的名称(可选)
trimAndClearNewLines-> :确定是否删除换行符和修剪字符串(可选,默认 = True)
document_assembler = DocumentAssembler()\
.setInputCol('text')\
.setOutputCol('document')\
.setIdCol('path')docs = document_assembler.transform(文本)
docs.limit(5).toPandas()表 3-16。DocumentAssembler 的输出
| path | text | document | |
|---|---|---|---|
| 0 | file:/.../spark-nlp-book/data/... | Xref: cantaloupe.srv.cs.cmu.edu sci.astro:3522... | [(document, 0, 1834, Xref: cantaloupe.srv.cs.c... |
| 1 | file:/.../spark-nlp-book/data/... | Newsgroups: sci.space\nPath: cantaloupe.srv.cs... | [(document, 0, 1804, Newsgroups: sci.space Pat... |
| 2 | file:/.../spark-nlp-book/data/... | Xref: cantaloupe.srv.cs.cmu.edu sci.space:6146... | [(document, 0, 1259, Xref: cantaloupe.srv.cs.c... |
| 3 | file:/.../spark-nlp-book/data/... | Path: cantaloupe.srv.cs.cmu.edu!rochester!udel... | [(document, 0, 8751, Path: cantaloupe.srv.cs.c... |
| 4 | file:/.../spark-nlp-book/data/... | Newsgroups: sci.space\nPath: cantaloupe.srv.cs... | [(document, 0, 1514, Newsgroups: sci.space Pat... |
docs.first()['document'][0].asDict(){'annotatorType': 'document',
'begin': 0,
'end': 1834,
'result': 'Xref: cantaloupe.srv.cs.cmu.edu sci.astro:...',
'metadata': {
'id': 'file:/.../spark-nlp-book/data/mini_newsg...'
}
}注释器
现在我们来看第 3 阶段——注释器。这是 NLP 工作的核心。因此,让我们看一下AnnotatorSpark NLP 中可用的一些 s。
我们将看一些常用的注释器:
SentenceDetectorTokenizerlemmatizerPerceptronApproach(邮差)
句子检测器
使用受Kevin Dias 的 Ruby 实现SentenceDetector启发的基于规则的算法。它采用以下参数(见表 3-17):
inputCols :要进行句子标记的列列表。
outputCol :新句子列的名称。
useAbbrevations :确定是否在句子检测中应用缩写。
useCustomBoundsOnly :确定是否仅将自定义边界用于句子检测。
explodeSentences :确定是否将每个句子分解成不同的行,以实现更好的并行化。默认为假。
customBounds :用于显式标记句子界限的字符。
from sparknlp.annotator import SentenceDetector
sent_detector = SentenceDetector()\
.setInputCols(['document'])\
.setOutputCol('sentences')sentences = sent_detector.transform(docs)
sentences.limit(5).toPandas()表 3-17。SentenceDetector 的输出
| path | text | document | sentences | |
|---|---|---|---|---|
| 0 | file:/.../spark-nlp-book/data/... | ... | [(document, 0, 1834, Xref: cantaloupe.srv.cs.c... | [(document, 0, 709, Xref: cantaloupe.srv.cs.cm... |
| 1 | file:/.../spark-nlp-book/data/... | ... | [(document, 0, 1804, Newsgroups: sci.space Pat... | [(document, 0, 288, Newsgroups: sci.space Path... |
| 2 | file:/.../spark-nlp-book/data/... | ... | [(document, 0, 1259, Xref: cantaloupe.srv.cs.c... | [(document, 0, 312, Xref: cantaloupe.srv.cs.cm... |
| 3 | file:/.../spark-nlp-book/data/... | ... | [(document, 0, 8751, Path: cantaloupe.srv.cs.c... | [(document, 0, 453, Path: cantaloupe.srv.cs.cm... |
| 4 | file:/.../spark-nlp-book/data/... | ... | [(document, 0, 1514, Newsgroups: sci.space Pat... | [(document, 0, 915, Newsgroups: sci.space Path... |
分词器
ATokenizer是一个基本的Annotator。几乎所有基于文本的数据处理都是从某种形式的标记化开始的。大多数经典的 NLP 算法都期望令牌作为基本输入。正在开发许多将字符作为基本输入的深度学习算法。大多数 NLP 应用程序仍然使用标记化。Spark NLPTokenizer比基于正则表达式的标记器要复杂一些。它有许多参数。以下是一些基本的(结果见表3-18):
inputCols :要标记的列列表。
outputCol :新标记列的名称。
targetPattern :用于识别标记化候选者的基本正则表达式规则。默认为 \S+ 这意味着任何不是空格(可选)。
prefixPattern :正则表达式 (regex) 用于标识出现在标记开头的子标记。正则表达式必须以 \A 开头并且必须包含组 ()。每个组将成为前缀内的一个单独的标记。默认为非字母字符,例如引号或括号(可选)。
suffixPattern :正则表达式来识别位于令牌末尾的子令牌。正则表达式必须以 \z 结尾并且必须包含组 ()。每个组将成为前缀内的一个单独的标记。默认为非字母字符,例如引号或括号(可选)。
from sparknlp.annotator import Tokenizer
tokenizer = Tokenizer()\
.setInputCols(['sentences'])\
.setOutputCol('tokens')\
.fit(sentences)tokens = tokenizer.transform(sentences)
tokens.limit(5).toPandas()表 3-18。分词器的输出
| path | text | document | sentences | tokens | |
|---|---|---|---|---|---|
| 0 | file:/.../spark-nlp-book/data/... | ... | ... | [(document, 0, 709, Xref: cantaloupe.srv.cs.cm... | [(token, 0, 3, Xref, {’sentence’: ’1'}), (toke... |
| 1 | file:/.../spark-nlp-book/data/... | ... | ... | [(document, 0, 288, Newsgroups: sci.space Path... | [(token, 0, 9, Newsgroups, {’sentence’: ’1'}),... |
| 2 | file:/.../spark-nlp-book/data/... | ... | ... | [(document, 0, 312, Xref: cantaloupe.srv.cs.cm... | [(token, 0, 3, Xref, {’sentence’: ’1'}), (toke... |
| 3 | file:/.../spark-nlp-book/data/... | ... | ... | [(document, 0, 453, Path: cantaloupe.srv.cs.cm... | [(token, 0, 3, Path, {’sentence’: ’1'}), (toke... |
| 4 | file:/.../spark-nlp-book/data/... | ... | ... | [(document, 0, 915, Newsgroups: sci.space Path... | [(token, 0, 9, Newsgroups, {’sentence’: ’1'}),... |
有些Annotators 需要额外的资源。有些需要参考数据,例如以下示例,lemmatizer.
词形还原器
lemmatizer找到标记的引理。引理是字典中的词条。例如,“cats”词形还原为“cat”,“oxen”词形还原为“ox”。加载lemmatizer需要字典和以下三个参数:
inputCols :要标记的列列表
outputCol :新令牌列的名称
dictionary :作为引理字典加载的资源
from sparknlp.annotator import Lemmatizer
lemmatizer = Lemmatizer() \
.setInputCols(["tokens"]) \
.setOutputCol("lemma") \
.setDictionary('en_lemmas.txt', '\t', ',')\
.fit(tokens)lemmas = lemmatizer.transform(tokens)
lemmas.limit(5).toPandas()表 3-19显示了结果。
表 3-19。来自 Lemmatizer 的输出
| path | text | document | sentences | tokens | lemma | |
|---|---|---|---|---|---|---|
| 0 | file:/.../spark-nlp-book/data/... | ... | ... | ... | [(token, 0, 3, Xref, {’sentence’: ’1'}), (toke... | [(token, 0, 3, Xref, {’sentence’: ’1'}), (toke... |
| 1 | file:/.../spark-nlp-book/data/... | ... | ... | ... | [(token, 0, 9, Newsgroups, {’sentence’: ’1'}),... | [(token, 0, 9, Newsgroups, {’sentence’: ’1'}),... |
| 2 | file:/.../spark-nlp-book/data/... | ... | ... | ... | [(token, 0, 3, Xref, {’sentence’: ’1'}), (toke... | [(token, 0, 3, Xref, {’sentence’: ’1'}), (toke... |
| 3 | file:/.../spark-nlp-book/data/... | ... | ... | ... | [(token, 0, 3, Path, {’sentence’: ’1'}), (toke... | [(token, 0, 3, Path, {’sentence’: ’1'}), (toke... |
| 4 | file:/.../spark-nlp-book/data/... | ... | ... | ... | [(token, 0, 9, Newsgroups, {’sentence’: ’1'}),... | [(token, 0, 9, Newsgroups, {’sentence’: ’1'}),... |
POS标签
还有一些Annotator需要模型作为资源。例如,词性标注器使用感知器模型,因此称为PerceptronApproach. 有PerceptronApproach五个参数:
inputCols :要标记的列列表
outputCol :新标签列的名称
posCol :Array匹配令牌的 POS 标签列
corpus :POS标签分隔语料库;选项中需要“分隔符”
nIterations :训练中的迭代次数,收敛到更好的准确性
我们将在此处加载一个预训练模型(参见表 3-20),并在第 8 章中研究如何训练我们自己的模型.
from sparknlp.annotator import PerceptronModel
pos_tagger = PerceptronModel.pretrained() \
.setInputCols(["tokens", "sentences"]) \
.setOutputCol("pos")
postags = pos_tagger.transform(lemmas)
postags.limit(5).toPandas()| 小路 | ... | 句子 | 代币 | 位置 | |
|---|---|---|---|---|---|
| 0 | 文件:/.../spark-nlp-book/数据/... | ... | [(文档, 0, 709, Xref: cantaloupe.srv.cs.cm... | [(token, 0, 3, Xref, {'sentence': '1'}), (toke... | [(pos, 0, 3, NNP, {'word': 'Xref'}), (pos, 4, ... |
| 1 | 文件:/.../spark-nlp-book/数据/... | ... | [(document, 0, 288, Newsgroups: sci.space Path... | [(token, 0, 9, 新闻组, {'sentence': '1'}),... | [(pos, 0, 9, NNP, {'word': 'Newsgroups'}), (po... |
| 2 | 文件:/.../spark-nlp-book/数据/... | ... | [(文档, 0, 312, Xref: cantaloupe.srv.cs.cm... | [(token, 0, 3, Xref, {'sentence': '1'}), (toke... | [(pos, 0, 3, NNP, {'word': 'Xref'}), (pos, 4, ... |
| 3 | 文件:/.../spark-nlp-book/数据/... | ... | [(文档, 0, 453, 路径: cantaloupe.srv.cs.cm... | [(token, 0, 3, Path, {'sentence': '1'}), (toke... | [(pos, 0, 3, NNP, {'word': 'Path'}), (pos, 4, ... |
| 4 | 文件:/.../spark-nlp-book/数据/... | ... | [(document, 0, 915, Newsgroups: sci.space Path... | [(token, 0, 9, 新闻组, {'sentence': '1'}),... | [(pos, 0, 9, NNP, {'word': 'Newsgroups'}), (po... |
预训练管道
我们之前看到了如何将多个 MLlib 阶段组织成一个Pipeline. UsingPipelines在 NLP 任务中特别有用,因为在加载原始文本和提取结构化数据之间通常有许多阶段。
Spark NLP 具有可用于处理文本的预训练管道。这并不意味着您不需要为应用程序调整管道。但是,开始试验预构建的 NLP 管道并找到需要调整的内容通常很方便。
解释文档 ML 管道
句子分割、标记化BasicPipeline、词形还原、词干提取和词性标注。如果您想快速查看一些文本数据,这是一个很好的管道(参见表 3-21)。
from sparknlp.pretrained import PretrainedPipeline
pipeline = PretrainedPipeline('explain_document_ml', lang='en')
pipeline.transform(texts).limit(5).toPandas()pipeline.transform(texts).limit(5).toPandas()
| ... | 句子 | 令牌 | 拼写 | 引理 | 干 | 位置 | |
|---|---|---|---|---|---|---|---|
| 0 | ... | ... | ... | [(token, 0, 9, 新闻组, {'confidence': '0.0... | ... | [(token, 0, 9, 新闻组, {'confidence': '0.0'... | [(pos, 0, 9, NNP, {'word': 'Newsgroups'}, [], ... |
| 1 | ... | ... | ... | [(token, 0, 3, Path, {'confidence': '1.0'}, []... | ... | [(token, 0, 3, path, {'confidence': '1.0'}, []... | [(pos, 0, 3, NNP, {'word': 'Path'}, [], []), (... |
| 2 | ... | ... | ... | [(token, 0, 9, 新闻组, {'confidence': '0.0... | ... | [(token, 0, 9, 新闻组, {'confidence': '0.0'... | [(pos, 0, 9, NNP, {'word': 'Newsgroups'}, [], ... |
| 3 | ... | ... | ... | [(令牌,0、3,外部参照,{'信心':'0.3333333 ... | ... | [(token, 0, 3, pref, {'confidence': '0.3333333... | [(pos, 0, 3, NN, {'word': 'pref'}, [], []), (p... |
| 4 | ... | ... | ... | [(token, 0, 3, tref, {'信心': '0.3333333... | ... | [(令牌,0、3,外部参照,{'信心':'0.3333333 ... | [(pos, 0, 3, NN, {'word': 'pref'}, [], []), (p... |
您还可以使用该annotate函数在没有 Spark 的情况下处理文档:
text = texts.first()['text']
annotations = pipeline.annotate(text)
list(zip(
annotations['token'],
annotations['stems'],
annotations['lemmas']
))[100:120[('much', 'much', 'much'),
('argument', 'argum', 'argument'),
('and', 'and', 'and'),
('few', 'few', 'few'),
('facts', 'fact', 'fact'),
('being', 'be', 'be'),
('offered', 'offer', 'offer'),
('.', '.', '.'),
('The', 'the', 'The'),
('summaries', 'summari', 'summary'),
('below', 'below', 'below'),
('attempt', 'attempt', 'attempt'),
('to', 'to', 'to'),
('represent', 'repres', 'represent'),
('the', 'the', 'the'),
('position', 'posit', 'position'),
('on', 'on', 'on'),
('which', 'which', 'which'),
('much', 'much', 'much'),
('of', 'of', 'of')]还有许多其他管道,并且还有其他可用信息。
现在让我们谈谈我们将如何执行第 4 步,使用Finisher将注解转换为原生 Spark SQL 类型。
Finisher
注释对于组成 NLP 步骤很有用,但我们通常希望提取一些特定信息进行处理。Finisher处理大多数这些用例。如果您想获得在下游 MLlib 阶段使用的令牌(或词干,或您拥有的)列表,Finisher可以执行此操作(参见表 3-22)。我们来看看参数:
inputCols :输入注释列的名称
outputCols :装订器输出列的名称
valueSplitSymbol :字符分隔注释
annotationSplitSymbol :字符分隔注释
cleanAnnotations :确定是否删除注释列
includeMetadata :注释元数据格式
outputAsArray :FinisherArray用结果而不是字符串生成一个
finisher = Finisher()\
.setInputCols(['tokens', 'lemma'])\
.setOutputCols(['tokens', 'lemmata'])\
.setCleanAnnotations(True)\
.setOutputAsArray(True)custom_pipeline = Pipeline(stages=[
document_assembler,
sent_detector,
tokenizer,
lemmatizer,
finisher
]).fit(texts)
custom_pipeline.transform(texts).limit(5).toPandas()
| 小路 | 文本 | 代币 | 主题 | |
|---|---|---|---|---|
| 0 | ... | ... | [新闻组,:,sci.space,路径,:,哈密瓜... | [新闻组,:,sci.space,路径,:,哈密瓜... |
| 1 | ... | ... | [路径,:, cantaloupe.srv.cs.cmu.edu!rochester!... | [路径,:, cantaloupe.srv.cs.cmu.edu!rochester!... |
| 2 | ... | ... | [新闻组,:,sci.space,路径,:,哈密瓜... | [新闻组,:,sci.space,路径,:,哈密瓜... |
| 3 | ... | ... | [外部参照,:,cantaloupe.srv.cs.cmu.edu,sci.space... | [外部参照,:,cantaloupe.srv.cs.cmu.edu,sci.space... |
| 4 | ... | ... | [外部参照,:, cantaloupe.srv.cs.cmu.edu, sci.astro... | [外部参照,:, cantaloupe.srv.cs.cmu.edu, sci.astro... |
现在我们将使用StopWordsRemoverSpark MLlib 中的转换器。结果见表3-23。
from pyspark.ml.feature import StopWordsRemoverstopwords = StopWordsRemover.loadDefaultStopWords('english')larger_pipeline = Pipeline(stages=[
custom_pipeline,
StopWordsRemover(
inputCol='lemmata',
outputCol='terms',
stopWords=stopwords)
]).fit(texts)larger_pipeline.transform(texts).limit(5).toPandas()| ... | 主题 | 条款 | |
|---|---|---|---|
| 0 | ... | [新闻组,:,sci.space,路径,:,哈密瓜... | [新闻组,:,sci.space,路径,:,哈密瓜... |
| 1 | ... | [路径,:, cantaloupe.srv.cs.cmu.edu!rochester!... | [路径,:, cantaloupe.srv.cs.cmu.edu!rochester!... |
| 2 | ... | [新闻组,:,sci.space,路径,:,哈密瓜... | [新闻组,:,sci.space,路径,:,哈密瓜... |
| 3 | ... | [外部参照,:,cantaloupe.srv.cs.cmu.edu,sci.space... | [外部参照,:,cantaloupe.srv.cs.cmu.edu,sci.space... |
| 4 | ... | [外部参照,:, cantaloupe.srv.cs.cmu.edu, sci.astro... | [外部参照,:, cantaloupe.srv.cs.cmu.edu, sci.astro... |
现在我们已经回顾了 Spark 和 Spark NLP,我们几乎可以开始构建 NLP 应用程序了。学习注释库还有一个额外的好处——它可以帮助您了解如何为 NLP 构建管道。即使您使用其他技术,这些知识也将适用。
练习:构建主题模型
开始探索数据集时,您可以做的最简单的事情之一就是创建主题模型。为此,我们需要将文本转换为数字向量。我们将在本书的下一部分对此进行更多讨论。现在,让我们构建一个处理文本的管道。
首先,我们需要将文本拆分成句子。其次,我们需要代币化。接下来,我们需要使用 alemmatizer和 normalizer 来规范化我们的单词。在此之后,我们需要完成我们的管道并删除停用词。(到目前为止,Normalizer本章已经演示了除了 之外的所有内容。)之后,我们将把信息传递到我们的主题建模管道中。
查看在线文档以获取有关规范器的帮助。
# document_assembler = ???
# sent_detector = ???
# tokenizer = ???
# lemmatizer = ???
# normalizer = ???
# finisher = ???
# sparknlp_pipeline = ???# stopwords = ???
# stopword_remover = ??? # use outputCol='terms'
#text_processing_pipeline = ??? # first stage is sparknlp_pipeline# from pyspark.ml.feature import CountVectorizer, IDF
# from pyspark.ml.clustering import LDA
# tf = CountVectorizer(inputCol='terms', outputCol='tf')
# idf = IDF(inputCol='tf', outputCol='tfidf')
# lda = LDA(k=10, seed=123, featuresCol='tfidf')
# pipeline = Pipeline(stages=[
# text_processing_pipeline,
# tf,
# idf,
# lda
# ])# model = pipeline.fit(texts)# tf_model = model.stages[-3]
# lda_model = model.stages[-1]# topics = lda_model.describeTopics().collect()
# for k, topic in enumerate(topics):
# print('Topic', k)
# for ix, wt in zip(topic['termIndices'], topic['termWeights']):
# print(ix, tf_model.vocabulary[ix], wt)
# print('#' * 50)恭喜!你已经使用 Spark NLP 构建了你的第一个完整的 Spark 管道。















 6434
6434











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









