







🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
当图 1-1中首次介绍从数据到结果的路径时,可能还不清楚未来的发展方向。在本书中,我们重点介绍了使用玩具模型和干净、简单的数据集进行特征工程的基本原理。这些示例旨在说明和启发。
机器学习示例通常显示最佳情况和结果。这掩盖了我们迄今为止在书中描述的路径。既然基础已经打好了,我们就要离开简单的玩具数据世界,进入使用真实世界的结构化数据集进行特征工程的过程。在我们完成每个步骤时,我们将检查形成每个特征的原始数据、转换后的特征,以及我们在此过程中做出的权衡。
需要明确的是,我们此示例的目标不是为该数据集构建最佳模型。相反,它是为了展示我们的一些技术的实际应用,以及如何更深入地检查和理解每种技术是否为正在构建的模型提供价值。
基于项目的协同过滤
我们的任务是使用 Microsoft Academic Graph 数据集的子样本为学术论文构建推荐系统。这个应该来对于所有正在搜索引文但尚未发现 Google 学术搜索的人来说非常方便。以下是有关数据集的一些相关统计数据:
MICROSOFT ACADEMIC GRAPH 数据集
- 它包含 166,192,182 篇独特的论文,可通过Open Academic Graph获取。它旨在仅用于研究目的。
- 数据集的总大小为 104 GB。
- 每个观察有 18 个变量来标识每篇论文,包括论文的标题、摘要、作者、关键词和研究领域。
数据集旨在易于在数据库中存储和访问。开箱即用的机器学习模型并不整洁,但需要一些初步的争论。有些老师喜欢让你省去这一步,通过直接接触模型和结果来提升你的自我。这里没有。我们从一开始就在一起。
我们最初的方法是将一些变量整理成正确的形状,以推动基于项目的协作过滤器。我们将看看是否能及时有效地找到合理相似的论文。
基于项目的协同过滤根据项目之间的相似性提供推荐。这分两个阶段进行:首先找到项目之间的相似性分数,然后对所有分数进行排序以找到前N个相似项目推荐。
构建基于项目的推荐系统
基于项目的推荐系统执行三个任务:
1.概括有关“事物”或项目的信息。
2. 给所有其他项目打分,找出“喜欢”这一项的项目。
3.返回排名分数+项目。
第一关:数据导入、清洗和特征解析
像所有好的科学实验一样,我们将从一个假设开始。在这种情况下,我们假设几乎同时发表在相似研究领域的论文对用户最有用。我们将采用一种简单的方法从整个数据集的子样本中解析出这些字段。生成简单的稀疏数组后,我们将通过基于项目的协作过滤器运行整个项目数组,看看我们是否能得到好的结果。
基于项目的协作过滤器取决于相似度分数来比较项目。在这种情况下,余弦相似度提供了两个非零向量之间的合理比较。下面的例子实际上使用了余弦距离,它是正空间中余弦相似度的补集,或者:

其中D C是余弦距离,S C是余弦相似度。
我们旅程的第一步是导入和检查数据集。在示例 9-1中,我们确定了实验的范围通过限制初始导入后可用的字段。这些字段是可能性还是很丰富的,如图9-1所示。
示例 9-1。导入+过滤数据
>>> import pandas as pd
>>> model_df = pd.read_json('data/mag_papers_0/mag_subset20K.txt', lines=True)
>>> model_df.shape
(20000, 19)
>>> model_df.columns
Index(['abstract', 'authors', 'doc_type', 'doi', 'fos', 'id', 'issue',
'keywords', 'lang', 'n_citation', 'page_end', 'page_start', 'publisher',
'references', 'title', 'url', 'venue', 'volume', 'year'],
dtype='object')
# filter out non-English articles and focus on a few variables
>>> model_df = model_df[model_df.lang == 'en']
... .drop_duplicates(subset='title', keep='first')
... .drop(['doc_type', 'doi', 'id', 'issue', 'lang', 'n_citation',
... 'page_end', 'page_start', 'publisher', 'references',
... 'url', 'venue', 'volume'],
... axis=1)
>>> model_df.shape
(10399, 6)
图 9-1。Microsoft Academic Graph 数据集的前两行
表 9-1最好地总结了如何将原始数据转化为更好的模型形状。列表和字典适用于数据存储,但不整洁或不适合不进行一些拆包的机器学习(Wickham,2014)。
| Field name | Description | Field type | # NaN |
|---|---|---|---|
| abstract | paper abstract | string | 4393 |
| authors | author names and affiliations | list of dict, keys = name, org | 1 |
| fos | fields of study | list of strings | 1733 |
| keywords | keywords | list of strings | 4294 |
| title | paper title | string | 0 |
| year | published year | int | 0 |
我们首先关注示例 9-2中的两个字段,将它们从列表和整数转换为特征数组,如图9-2所示。
示例 9-2。协同过滤第一阶段:构建物品特征矩阵
>>> unique_fos = sorted(list({feature
... for paper_row in model_df.fos.fillna('0')
... for feature in paper_row }))
>>> unique_year = sorted(model_df['year'].astype('str').unique())
>>> def feature_array(x, var, unique_array):
... row_dict = {}
... for i in x.index:
... var_dict = {}
... for j in range(len(unique_array)):
... if type(x[i]) is list:
... if unique_array[j] in x[i]:
... var_dict.update({var + '_' + unique_array[j]: 1})
... else:
... var_dict.update({var + '_' + unique_array[j]: 0})
... else:
... if unique_array[j] == str(x[i]):
... var_dict.update({var + '_' + unique_array[j]: 1})
... else:
... var_dict.update({var + '_' + unique_array[j]: 0})
... row_dict.update({i : var_dict})
... feature_df = pd.DataFrame.from_dict(row_dict, dtype='str').T
... return feature_df
>>> year_features = feature_array(model_df['year'], unique_year)
>>> fos_features = feature_array(model_df['fos'], unique_fos)
>>> first_features = fos_features.join(year_features).T
>>> from sys import getsizeof
>>> print('Size of first feature array: ', getsizeof(first_features))
Size of first feature array: 2583077234
图 9-2。head of first_features——来自原始数据集的观察(论文)索引是列,特征是行
我们现在已经成功地将一个相对较小的数据集(约 1 万行原始数据)转换为 2.5 GB 的特征。但这条路径对于快速、迭代的探索来说太慢了。我们需要更快的方法,并产生消耗更少计算资源和实验时间的特征。
不过现在,让我们看看我们当前的特征如何在下一阶段为我们提供良好的推荐(例 9-3)。我们将“好”推荐定义为与输入看起来相似的论文。
示例 9-3。协同过滤第 2 阶段:搜索相似项
>>> from scipy.spatial.distance import cosine
>>> def item_collab_filter(features_df):
... item_similarities = pd.DataFrame(index = features_df.columns,
... columns = features_df.columns)
... for i in features_df.columns:
... for j in features_df.columns:
... item_similarities.loc[i][j] = 1 - cosine(features_df[i],
... features_df[j])
... return item_similarities
>>> first_items = item_collab_filter(first_features.loc[:, 0:1000])为什么我们只使用两个特征来计算项目相似度需要这么长时间?我们使用嵌套for循环对 10,399 × 1,000 矩阵进行点积。随着我们增加添加到模型中的观察数量,每个循环的时间也会增加。请记住,这是全部可用数据集的一个子集,已针对纯英文论文进行过滤。当我们越来越接近“好”结果时,我们需要返回并在更大的集合上进行测试以获得最佳结果。
我们怎样才能让它更快?因为我们一次只需要一个结果,我们可以改变我们的函数,这样我们一次只计算一个项目,指定我们想要的最高结果的数量。我们稍后会在继续进行实验时执行此操作。目前,查看完整的特征空间对于了解迭代工作对暴力破解真实世界数据集的影响很有用。
我们需要更好地了解这些功能将如何转化为我们获得好的推荐。我们是否有足够的观察结果继续前进?让我们绘制一个热图(示例 9-4),看看我们是否有任何彼此相似的论文。图 9-3显示了结果。
示例 9-4。论文推荐的热图
>>> import matplotlib.pyplot as plt
>>> import seaborn as sns
>>> import numpy as np
>>> %matplotlib inline
>>> sns.set()
>>> ax = sns.heatmap(first_items.fillna(0),
... vmin=0, vmax=1,
... cmap="YlGnBu",
... xticklabels=250, yticklabels=250)
>>> ax.tick_params(labelsize=12)较暗的像素表示彼此相似的项目。深色对角线表明余弦相似度正确地表明每篇论文与其自身最相似。然而,因为我们的一个特征有很多 NaN,所以这条线沿着对角线断开了。我们可以看到,虽然大多数项目彼此不相似——即,我们的数据集相当多样化——但还有一些其他的高分候选项目。这些可能是也可能不是定性的好建议,但至少我们可以看到我们的方法没有那么疯狂。
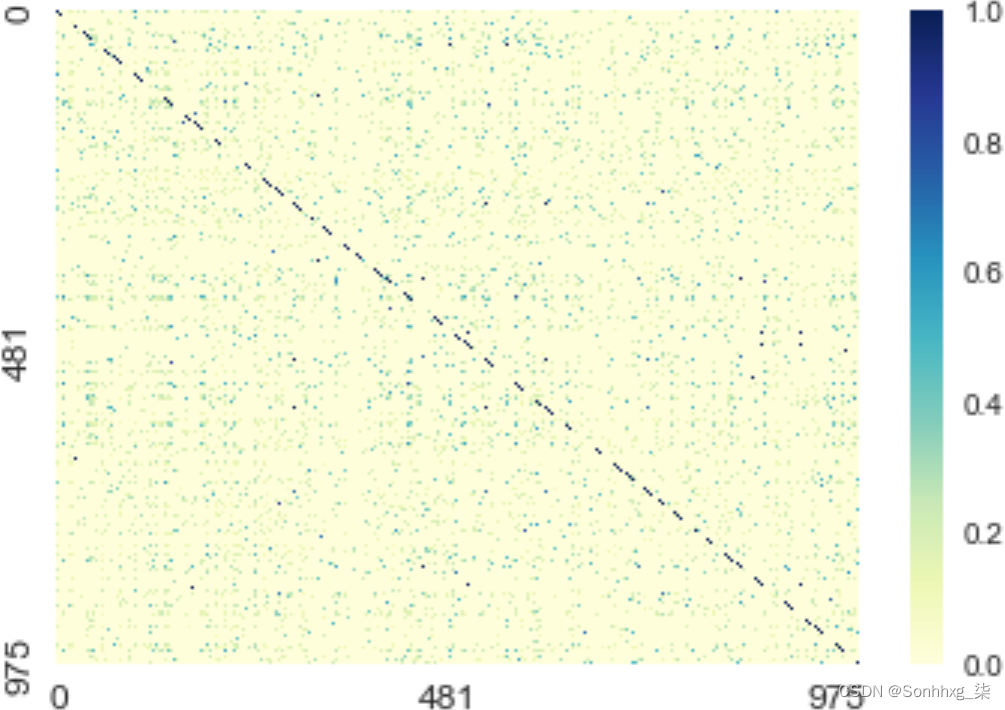
图 9-3。基于两个原始特征的相似论文的热图:年份和研究领域
示例 9-5显示了如何将这些项目相似性转化为推荐。好消息是,我们仍然有大量可用的功能,还有很大的改进空间。
示例 9-5。基于物品的协同过滤推荐
>>> def paper_recommender(paper_ix, items_df):
... print('Based on the paper: \nindex = ', paper_ix)
... print(model_df.iloc[paper_ix])
... top_results = items_df.loc[paper_ix].sort_values(ascending=False).head(4)
... print('\nTop three results: ')
... order = 1
... for i in top_results.index.tolist()[-3:]:
... print(order,'. Paper index = ', i)
... print('Similarity score: ', top_results[i])
... print(model_df.iloc[i], '\n')
... if order < 5: order += 1
>>> paper_recommender(2, first_items)
Based on the paper:
index = 2
abstract NaN
authors [{'name': 'Jovana P. Lekovich', 'org': 'Weill ...
fos NaN
keywords NaN
title Should endometriosis be an indication for intr...
year 2015
Name: 2, dtype: object
Top three results:
1 . Paper index = 2
Similarity score: 1.0
abstract NaN
authors [{'name': 'Jovana P. Lekovich', 'org': 'Weill ...
fos NaN
keywords NaN
title Should endometriosis be an indication for intr...
year 2015
Name: 2, dtype: object
2 . Paper index = 292
Similarity score: 1.0
abstract NaN
authors [{'name': 'John C. Newton'}, {'name': 'Beers M...
fos [Wide area multilateration, Maneuvering speed,...
keywords NaN
title Automatic speed control for aircraft
year 1955
Name: 561, dtype: object
3 . Paper index = 593
Similarity score: 1.0
abstract This paper demonstrates that on‐site greywater...
authors [{'name': 'Eran Friedler', 'org': 'Division of...
fos [Public opinion, Environmental Engineering, Wa...
keywords [economic analysis, tratamiento desperdicios, ...
title The water saving potential and the socio-econo...
year 2008
Name: 1152, dtype: object哎呀。好消息是返回的最相似的论文就是我们正在寻找的论文。坏消息是接下来的两篇论文似乎与我们最初的搜索不太接近,即使对于我们选择的特征也是如此。
“是的,是的,”你可能会说,“但这是大数据时代!那将解决我们的问题!难道我们不能通过推送更多数据来获得更好的结果吗?” 潜在的。但即使是大数据也无法弥补糟糕的数据和工程选择。

图 9-4。机器学习 ( https://xkcd.com/1838/ )
我们目前的蛮力方法对于智能迭代工程来说太慢了。让我们尝试一些新的特征工程技巧,看看我们是否可以加快计算时间并找到更好的特征和搜索结果的更好方法。
第二关:更多的工程和更智能的模型
创建一个大型稀疏数组并将其通过过滤器推送的初始方法可以通过多种方式进行改进。接下来的步骤将特别关注将更好的技术应用于两个初始特征,并改变基于项目的协同过滤方法以加快迭代速度。
首先,是时候为我们假设中的两个变量尝试一些很棒的特征工程技巧了。深入研究已经开发的功能,我们可以选择解决每种类型变量的技术,并将其转换为推荐系统的“更好”功能。
让我们首先关注这一年。在“Quantization or Binning”中,我们回顾了对于使用相似性度量的方法,如何使用特征的原始计数可能会出现问题。示例 9-6(和图 9-5)将检查我们如何转换'year'以更好地适应我们选择的模型。
示例 9-6。固定宽度合并 + 虚拟编码(第 1 部分)
>>> print("Year spread: ", model_df['year'].min()," - ", model_df['year'].max())
>>> print("Quantile spread:\n", model_df['year'].quantile([0.25, 0.5, 0.75]))
Year spread: 1831 - 2017
Quantile spread:
0.25 1990.0
0.50 2005.0
0.75 2012.0
Name: year, dtype: float64
# plot years to see the distribution
>>> fig, ax = plt.subplots()
>>> model_df['year'].hist(ax=ax,
... bins= model_df['year'].max() - model_df['year'].min())
>>> ax.tick_params(labelsize=12)
>>> ax.set_xlabel('Year Count', fontsize=12)
>>> ax.set_ylabel('Occurrence', fontsize=12)我们可以从偏态分布(图 9-5)中看出这是分箱的绝佳候选。
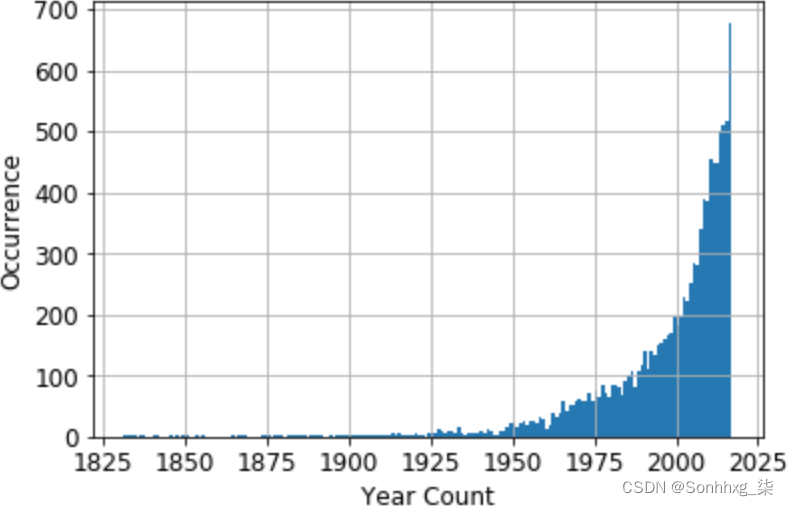
图 9-5。数据集中 10K+ 学术论文的原始年份分布
箱子将基于变量内的范围,而不是特征的唯一数量。为了进一步减少特征空间,我们将对生成的 bin 进行虚拟编码(参见示例 9-7)。Pandas 可以使用内置函数来完成这两项工作。这些方法将使我们的结果易于解释,因此我们可以在继续之前快速检查转换后的特征(参见图 9-6)。
示例 9-7。固定宽度分箱 + 虚拟编码(第 2 部分)
# binning here (by 10 years) reduces the year feature space from 156 to 19
>>> bins = int(round((model_df['year'].max() - model_df['year'].min()) / 10))
>>> temp_df = pd.DataFrame(index = model_df.index)
>>> temp_df['yearBinned'] = pd.cut(model_df['year'].tolist(), bins, precision = 0)
>>> X_yrs = pd.get_dummies(temp_df['yearBinned'])
>>> X_yrs.columns.categories
IntervalIndex([(1831.0, 1841.0], (1841.0, 1851.0], (1851.0, 1860.0],
(1860.0, 1870.0], (1870.0, 1880.0] ... (1968.0, 1978.0],
(1978.0, 1988.0], (1988.0, 1997.0], (1997.0, 2007.0],
(2007.0, 2017.0]]
closed='right',
dtype='interval[float64]')
# plot the new distribution
>>> fig, ax = plt.subplots()
>>> X_yrs.sum().plot.bar(ax = ax)
>>> ax.tick_params(labelsize=8)
>>> ax.set_xlabel('Binned Years', fontsize=12)
>>> ax.set_ylabel('Counts', fontsize=12)几十年来,我们通过分箱保留了原始变量的基本分布。如果我们希望使用一种可以从不同分布中获益的方法,我们可以改变我们的分箱选择来改变这个变量如何呈现给模型。因为我们使用的是余弦相似度,所以这很好。让我们继续讨论我们最初包含在模型中的下一个特征。
研究领域特征空间对原始模型的大小和处理时间有显着影响。
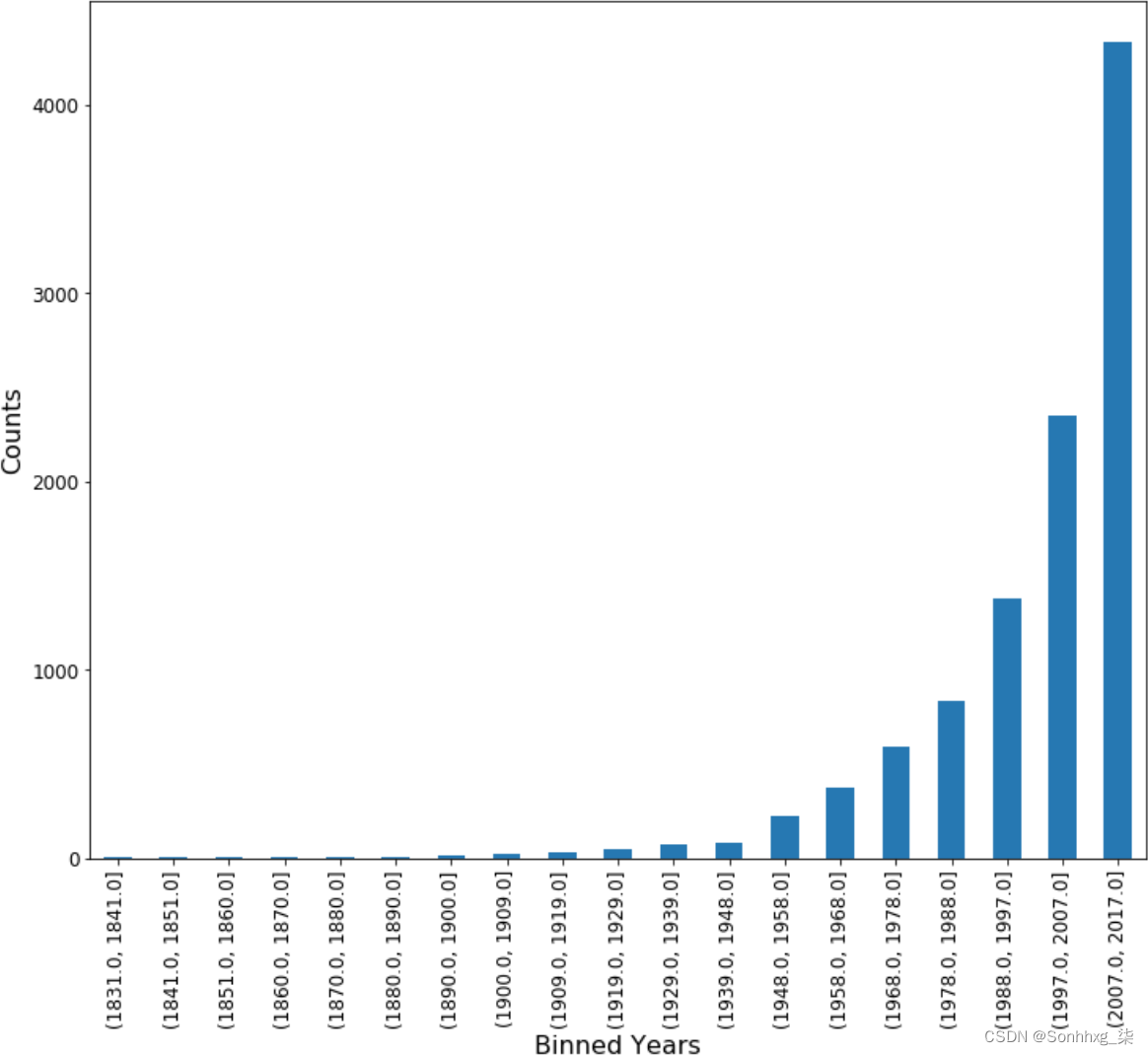
图 9-6。新分箱 X_yrs 特征的分布
让我们检查一下我们已经完成的工作。通过解析字符串列表,我们在第一遍中创建了一个“短语袋”。由于我们已经有了一个有用的稀疏数组,我们可以专注于使用更高效的数据类型。示例 9-8说明了从 Pandas DataFrame 转换为 NumPy 稀疏数组如何影响计算时间。
示例 9-8。将短语包 pd.Series 转换为 NumPy 稀疏数组
>>> X_fos = fos_features.values
# We can see how this will make a difference in the future by looking
# at the size of each
>>> print('Our pandas Series, in bytes: ', getsizeof(fos_features))
>>> print('Our hashed numpy array, in bytes: ', getsizeof(X_fos))
Our pandas Series, in bytes: 2530632380
Our hashed numpy array, in bytes: 112好多了!将其放回原处,我们将把我们的特征组合在一起(例 9-9)并重新运行我们的推荐器(例 9-10)以查看我们是否有改进的结果,利用 scikit-learn 的余弦相似度函数。我们还将通过一次只关注一个项目来减少计算时间。
示例 9-9。协同过滤阶段1+2:构建物品特征矩阵,搜索相似物品
>>> second_features = np.append(X_fos, X_yrs, axis = 1)
>>> print("The power of feature engineering saves us, in bytes: ",
... getsizeof(first_features) - getsizeof(second_features))
The power of feature engineering saves us, in bytes: 168066769
>>> from sklearn.metrics.pairwise import cosine_similarity
>>> def piped_collab_filter(features_matrix, index, top_n):
... item_similarities = \
... 1 - cosine_similarity(features_matrix[index:index+1],
... features_matrix).flatten()
... related_indices = \
... [i for i in item_similarities.argsort()[::-1] if i != index]
... return [(index, item_similarities[index])
... for index in related_indices
... ][0:top_n]示例 9-10。基于项目的协同过滤推荐:Take 2
>>> def paper_recommender(items_df, paper_ix, top_n):
... if paper_ix in model_df.index:
... print('Based on the paper:')
... print('Paper index = ', model_df.loc[paper_ix].name)
... print('Title :', model_df.loc[paper_ix]['title'])
... print('FOS :', model_df.loc[paper_ix]['fos'])
... print('Year :', model_df.loc[paper_ix]['year'])
... print('Abstract :', model_df.loc[paper_ix]['abstract'])
... print('Authors :', model_df.loc[paper_ix]['authors'], '\n')
... # define the location index for the DataFrame index requested
... array_ix = model_df.index.get_loc(paper_ix)
... top_results = piped_collab_filter(items_df, array_ix, top_n)
... print('\nTop',top_n,'results: ')
... order = 1
... for i in range(len(top_results)):
... print(order,'. Paper index = ',
... model_df.iloc[top_results[i][0]].name)
... print('Similarity score: ', top_results[i][1])
... print('Title :', model_df.iloc[top_results[i][0]]['title'])
... print('FOS :', model_df.iloc[top_results[i][0]]['fos'])
... print('Year :', model_df.iloc[top_results[i][0]]['year'])
... print('Abstract :', model_df.iloc[top_results[i][0]]['abstract'])
... print('Authors :', model_df.iloc[top_results[i][0]]['authors'],
... '\n')
... if order < top_n: order += 1
... else:
... print('Whoops! Choose another paper. Try something from here: \n',
... model_df.index[100:200])
>>> paper_recommender(second_features, 2, 3)
Based on the paper:
Paper index = 2
Title : Should endometriosis be an indication for intracytoplasmic sperm inject ...
FOS : nan
Year : 2015
Abstract : nan
Authors : [{'name': 'Jovana P. Lekovich', 'org': 'Weill Cornell Medical College, ...
Top 3 results:
1 . Paper index = 10055
Similarity score: 1.0
Title : [Diagnosis of cerebral tumors; comparative studies on arteriography, ...
FOS : ['Radiology', 'Pathology', 'Surgery']
Year : 1953
Abstract : nan
Authors : [{'name': 'Antoine'}, {'name': 'Lepoire'}, {'name': 'Schoumacker'}]
2 . Paper index = 11771
Similarity score: 1.0
Title : A Study of Special Functions in the Theory of Eclipsing Binary Systems
FOS : ['Contact binary']
Year : 1981
Abstract : nan
Authors : [{'name': 'Filaretti Zafiropoulos', 'org': 'University of Manchester'}]
3 . Paper index = 11773
Similarity score: 1.0
Title : Studies of powder flow using a recording powder flowmeter and measure ...
FOS : nan
Year : 1985
Abstract : This paper describes the utility of the dynamic measurement of the ...
Authors : [{'name': 'Ramachandra P. Hegde', 'org': 'Department of Pharmacy, ...
老实说,我认为我们的功能选择效果不太好。这些字段中有很多缺失的数据。让我们继续看看我们是否可以选择具有更多信息的更丰富的功能。
找到你的位置
在 Pandas DataFrames 和 NumPy 矩阵之间转换可以制作索引棘手——我们有相同大小的索引,但索引分配不一样。正如我们在示例 9-11.iloc中所示,Pandas 使用、.loc和来协助完成此操作:.get_loc
-
.loc返回基于原始 Pandas DataFrame 的索引,允许我们参考特定的论文。 -
.iloc使用整数位置,它与我们的 NumPy 数组具有相同的索引。 -
.get_loc当我们知道 DataFrame 索引时,帮助我们找到整数位置。
示例 9-11。在转换期间维护索引分配
>>> model_df.loc[21]
abstract A microprocessor includes hardware registers t...
authors [{'name': 'Mark John Ebersole'}]
fos [Embedded system, Parallel computing, Computer...
keywords NaN
title Microprocessor that enables ARM ISA program to...
year 2013
Name: 21, dtype: object
>>> model_df.iloc[21]
abstract NaN
authors [{'name': 'Nicola M. Heller'}, {'name': 'Steph...
fos [Biology, Medicine, Post-transcriptional regul...
keywords [glucocorticoids, post transcriptional regulat...
title Post-transcriptional regulation of eotaxin by ...
year 2002
Name: 30, dtype: object
>>> model_df.index.get_loc(30)
21第三遍:更多功能=更多信息
到目前为止,我们的实验不支持最初的假设那一年_ 和研究领域足以推荐类似的论文。此时,我们有几个选择:
- 上传更多的原始数据集,看看我们是否能得到更好的结果。
- 花更多时间探索数据以检查我们是否有足够密集的数据集来提供好的建议。
- 通过添加更多功能来迭代当前模型。
第一个选项假设问题出在我们的数据抽样中。可能是这种情况,但类似于图 9-4中搅拌数据堆以获得更好结果的类比。
第二种选择可以更好地了解底层原始数据。这应该根据您在探索过程中对特征和模型选择的决定如何变化不断地重新审视。此处选择的初始子样本反映了此步骤。由于我们在数据集中有更多可用变量,因此我们不会返回此处。
这留下了第三个选项,通过添加更多功能来推进我们当前的模型。提供有关每个项目的更多信息可以提高相似性分数并产生更好的推荐。
基于我们初步的探索,接下来的步骤将集中在信息、摘要和作者最多的领域。
回顾第 4 章,我们可以看到abstract是 tf-idf 过滤噪声并找到显着关联词的一个很好的候选者。我们在示例 9-12中这样做。
示例 9-12。Stopwords + tf-idf
# need to fill in NaN for sklearn use in future
>>> filled_df = model_df.fillna('None')
>>> from sklearn.feature_extraction.text import TfidfVectorizer
>>> vectorizer = TfidfVectorizer(sublinear_tf=True, max_df=0.5,
... stop_words='english')
>>> X_abstract = vectorizer.fit_transform(filled_df['abstract'])
>>> third_features = np.append(second_features, X_abstract.toarray(), axis = 1)我们可以通过争吵成字典来减少杂乱无章的作者的计算量然后运行它通过一个单热编码器,如示例 9-13所示。
示例 9-13。使用 scikit-learn 的 DictVectorizer 进行一次性编码
>>> authors_list = []
>>> for row in filled_df.authors.itertuples():
... # create a dictionary from each Series index
... if type(row.authors) is str:
... y = {'None': row.Index}
... if type(row.authors) is list:
... # add these keys + values to our running dictionary
... y = dict.fromkeys(row.authors[0].values(), row.Index)
... authors_list.append(y)
>>> authors_list[0:5]
[{'None': 0},
{'Ahmed M. Alluwaimi': 1},
{'Jovana P. Lekovich': 2, 'Weill Cornell Medical College, New York, NY': 2},
{'George C. Sponsler': 5},
{'M. T. Richards': 7}]
>>> from sklearn.feature_extraction import DictVectorizer
>>> v = DictVectorizer(sparse=False)
>>> D = authors_list
>>> X_authors = v.fit_transform(D)
>>> fourth_features = np.append(third_features, X_authors, axis = 1)是时候与推荐人核对了看看这些新功能是如何运作的。示例 9-14显示了结果。
示例 9-14。基于项目的协同过滤推荐:Take 3
>>> paper_recommender(fourth_features, 2, 3)
Based on the paper:
Paper index = 2
Title : Should endometriosis be an indication for intracytoplasmic sperm inject ...
FOS : nan
Year : 2015
Abstract : nan
Authors : [{'name': 'Jovana P. Lekovich', 'org': 'Weill Cornell Medical College, ...
Top 3 results:
1 . Paper index = 10055
Similarity score: 1.0
Title : [Diagnosis of cerebral tumors; comparative studies on arteriography, ...
FOS : ['Radiology', 'Pathology', 'Surgery']
Year : 1953
Abstract : nan
Authors : [{'name': 'Antoine'}, {'name': 'Lepoire'}, {'name': 'Schoumacker'}]
2 . Paper index = 5601
Similarity score: 1.0
Title : 633 Survival after coronary revascularization, with and without mitral ...
FOS : ['Cardiology']
Year : 2005
Abstract : nan
Authors : [{'name': 'J.B. Le Polain De Waroux'}, {'name': 'Anne-Catherine ...
3 . Paper index = 12256
Similarity score: 1.0
Title : Nucleotide Sequence and Analysis of an Insertion Sequence from Bacillus ...
FOS : ['Biology', 'Molecular biology', 'Insertion sequence', 'Nucleic acid ...
Year : 1994
Abstract : A 5.8-kb DNA fragment encoding the cryIC gene from Bacillus thur...
Authors : [{'name': 'Geoffrey P. Smith'}, {'name': 'David J. Ellar'}, {'name': ...即使考虑到某些领域的缺失数据,上一轮特征工程的前三名结果也将我们引向了医学领域的其他论文。
该数据集中代表的论文范围很广;例如,随机抽取的论文样本涉及研究领域,例如“耦合常数”、“蒸散”、“散列函数”、“IVMS”、“冥想”、“帕累托分析”、“第二代小波变换”、“滑”和“螺旋星系”。鉴于 10K+ 论文列出了 7,604 个独特的研究领域,这些最后的结果似乎在朝着正确的方向发展。我们可以确信我们的工作正在朝着有用的模型发展。
对更多文本变量进行持续迭代,例如查找论文标题的名词短语或词干关键词,可以使我们更接近“最佳”推荐。
这里应该注意的是,“最佳”的定义是所有推荐系统和搜索引擎的圣杯。我们正在搜索用户会觉得最有帮助的内容,这些内容可能会或可能不会直接由数据表示。特征工程允许我们将显着特征抽象为表示,这样算法就可以公开其中包含的显式和隐式信息。
概括
如您所见,为机器学习构建模型很容易。为有用的结果建立好的模型需要时间和工作。我们在这里逐步完成了检查可能变量的集合并尝试使用不同的特征工程方法以获得更好结果的混乱过程。我们在这里定义“更好”不仅是根据我们的训练和测试的良好结果,还包括减少模型的大小和我们迭代不同实验所花费的时间。

















 2010
2010











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











